
25m
最近推特上反复刷屏的 loop / loop engineering,出处就是 5 月 4 日这场访谈——Anthropic 的 Claude Code 创造者 Boris Cherny (出过一本 TypeScript 教材、靠写代码立身的工程师) 在红杉 AI Ascent 2026 上,第一次系统讲了他怎么用 loop。我把整场访谈视频翻译成了中文。
他抛出的第一个点:编程对他来说已经 100% 解决了。
「对我来说,100%。」
不是嘴上说说——他说模型现在写了他 100% 的代码,每天提几十个 PR,上周单日纪录是 150 个。Claude Code 的代码库也没什么秘密(被泄露了),就是 TypeScript 加 React。
那他一个人怎么撑起一天 150 个 PR?
靠 loop。这就是最近被反复讨论的那套打法——他让 Claude 用 cron 排重复任务,发出去就不管:
「而且到现在,我已经有几十个 loop 在跑各种任务了。」
有一个帮他盯 PR、修 CI、自动 rebase;还有一个每 30 分钟从 Twitter 抓反馈帮他聚类。他给的定性很重:
「我现在觉得 loop 就是未来。」
他还提到刚上线的 routines,原理一样,但跑在服务器上——「就算你关掉笔记本,它也还在继续跑」。
那这只是他一个人的极客玩法?
不是。他说整个 Anthropic 内部「已经没有任何手写代码了,所有 SQL 都是由模型写的」。工程师各自的 Claude 在循环里跑,还会通过 Slack 互相沟通,一起解决问题。
写代码这么便宜,软件公司会不会就没价值了——SaaS 末日?
他不这么看,但认为护城河会洗牌。借 Hamilton Helmer《七种力量》的框架:切换成本、流程壁垒这类会先失效,网络效应和规模经济仍然有效。他还押了个数字:
「我认为接下来 10 年里要颠覆一切的创业公司数量会增长 10 倍。」
那写软件这件事本身会变成什么?
他搬出印刷机:印刷机问世后 50 年,欧洲出版的文字量超过此前一千年总和,书价降了近 100 倍,识字率最终从约 10% 升到约 70%。他判断软件会沿同样的路平民化,「会比 50 年快得多」,最终「变成一项技能,就像会发短信一样」。
落点很锋利——最适合写会计软件的不是工程师,而是会计:「编码才是简单的部分,难的是懂领域知识。」
被问到两年后会怎样,这位创造者反而给了最诚实的答案:「哦,2 年后,哥们我真不知道。我们只做 1 周以内的计划。」
· loop 就是未来:几十个 cron agent 盯 PR、修 CI、抓反馈
· 编程 100% 解决、单日 150 PR
· 公司零手写代码,Claude 之间 Slack 互相循环
· 切换成本/流程壁垒先崩,颠覆者 10 倍
· 印刷机类比:软件像识字一样平民化
1
126

避坑指南:如何避免无脑运行循环导致大模型额度瞬间归零?
许多开发者在配合 Codex 编程时,习惯直接丢给最强模型去跑自动化测试与循环,结果短短几个小时就会烧光所有的 Token 额度。我在经历了一下午烧光五小时大模型额度的惨痛教训后,重构了自己的开发工作流。
以下是面向开发者的三大核心干货与小技巧:
一、 重构思想:把大脑和手解耦(Decoupling the Brain from the Hands)
这是源自 Anthropic 官方的技术理念。在智能体开发流程中,应当把思考规划与具体执行彻底拆分:
1. 大脑(ChatGPT 与 GitHub):负责高层面的系统架构设计、读取与分析代码、拆解子任务、制定实施方案以及最终的代码审查(Code Review)。强模型在此处只进行宏观规划,不执行低效的代码编写。
2. 手(本地 Codex):负责具体的代码细节修改、Diff 落地与本地编译。
二、 阶梯分工:派对的人干对的事
不要使用昂贵的大模型去处理日常琐事,而要根据任务的风险和复杂度分配最合适的模型:
• 高风险、跨模块决策点:使用 GPT-5.5。只在需要架构判断的关键节点调用它。
• 日常 Bug 修复:交给 5.3 等中等规模模型,性价比更高。
• 低风险活(写注释、写文档、批量替换):交给 5.4-mini 或者 DeepSeek V4 等小模型,处理这种重复性且不需要深层推理的工作。
三、 提升效率与节省 Token 的实用小技巧
1. 避免终端自动重试循环:不要允许 AI 在终端中盲目地自动重试编译。编译报错时,先让小模型找出明显的语法错误,只在遇到复杂的逻辑冲突时才升级调用大模型。
2. 混合模型协作更准:强模型统筹规划加上小模型局部干活,往往比单一大模型从头写到尾更准确。强模型在宏观规划时不容易迷失方向,而小模型在局部细节上执行时不容易引入冗余的上下文噪音。
3. 控制上下文边界:合理控制上下文长度,每次只把当前子任务相关的代码块喂给 AI,避免一次性吞入整个项目代码库导致 Token 爆炸式增长。
1
3
120

# 一个开发者,二十四个 Agent,零对齐:为什么我们需要协作式 AI 工程
Maggie Appleton 是 GitHub Next 的研究工程师。她在最近的演讲中提出了一个尖锐的问题:**当一个人加一堆 Agent 能做一整个团队的工作时,最大的瓶颈不是"怎么造",而是"造什么"——以及"团队里所有人都同意造这个吗"。**
以下是演讲全文翻译。
---
首先自我介绍一下。我是 Maggie,GitHub Next 的 staff research engineer。至少头衔是这么写的,但实际上我是个设计师。或者说我过去是,那时候设计和工程还是分开的两个东西。
Next 是 GitHub 内部的实验室团队。我们做的项目比组织里其他人更实验性、更有风险。也叫"瞎搞然后看看会怎样"部门。
和所有人一样,我们在试图塑造下一代 Agent 驱动的开发者工具。
我管这个叫"一个人加二十四个 Claude"的未来理论。它的卖点是:一个人带着一队 Agent,能干完一整个开发团队的工作。
这个梦想的主要问题在于:**它假设软件是一个人做的。**
所有这些工具都是单机界面。
它们专注于放大个人的产出。
但放大个人的价值是有限的。
因为软件不是一个人在真空中造的。它是团队运动。所有参与建造的人需要就"建什么"和"为什么建"达成一致。
相信个人生产力能带来好软件……
……是"九个女人一个月生一个孩子"的逻辑。
更多的个人产出解决不了需要所有人沟通和协调的问题。它只会让这些问题变得更糟。
---
## 实现正在变成已解决的问题
写代码现在很快,越来越便宜,质量也在往右上角走。
**难的问题不再是"怎么建"。而是"该不该建"。**
就"建什么"达成一致,是新的瓶颈。
团队里的每个人都需要参与进来,问这些问题:我们在做对的东西吗?我们把精力花在了对的地方吗?怎么才能产生最大的影响?
当生产成本变得便宜,机会成本就成了真正的成本。你不可能什么都建,而你选的每一样东西,都是以放弃其他所有东西为代价的。
任何一个在团队里交付过软件的人都知道,这不是新问题。**对齐(alignment)一直是瓶颈。**
但 Agent 让"团队不对齐"的代价变高了很多。
更糟糕的是……
……我们的协调工具仍然来自另一个时代。
GitHub、Slack、Jira、Linear 这些工具,在它们当前的状态下,并不是为 Agent 驱动的开发世界设计的。
我们在把大量 Agent 的产出灌进一个为过时的软件构建方式而设计的平台。**PR 和 Issue 是错误的原语**——它们处理不了 Agent 工作的速度、形态和量级。
我知道我在 GitHub 工作,说这个可能听起来像异端。但我保证,在内部说这话没什么争议。很少有人相信 PR 和 Issue 是工程未来的理想原语。而且我们内部有大量的人在探索接下来是什么。
---
## 旧流程 vs 新现实
以前的开发流程是这样的:我们有规划阶段、构建阶段、审查阶段。
整个过程中有很多对齐的接触点——Slack 上的讨论、Zoom 会议、Issue 下的评论、草稿 PR 里的细节讨论。每个人都能发表意见,从团队里的专家和资深成员那里获得建议,发现问题,调整方向。
等到代码被审查和合并的时候,整个团队都已经看到了这个工作的推进过程,大致达成了共识。
**但那个"实现窗口"已经坍塌了。**
因为实现不再昂贵和耗时……
……我们就觉得不需要那么多规划了。
于是大部分早期的对齐接触点消失了。
我们知道,生成代码的审查时间已经变长了。
所以审查阶段确实产生了更多对齐接触点——但它们在实现的错误一侧。
现在从记录一个 Issue 到一个 Agent 打开 PR,只需要几分钟。代码太便宜了,我们在 prompt 之前根本不会停下来好好想。
更糟糕的是,大多数当前的编码 Agent 都有一个**本地规划模式,但它不与其他人共享。**
所以你甚至在把计划交给 Agent 执行之前,都没有检查过团队是不是同意这个计划。我们又失去了更多对齐点。
这导致可怜的 Pull Request 不得不承载所有检查点的重量——在流程的最末端,当一切都太晚了。而这从来不是 PR 被设计的初衷。
**我们现有的工具,没有一个能给团队一个共享的空间来讨论计划、收集正确的上下文、集体与 Agent 协作。**
---
## 我们都在承受后果
在没有良好对齐的情况下快速前进,会导致:
**浪费的工作**
- 没人要的功能,解决不了真正的问题
- 东西做完了才收到关键反馈,只能全部扔掉
**协调债务**
- 毛茸茸的合并冲突——多个 Agent 碰了同一个文件
- 重复工作——你和另一个工程师把 Agent 分配到了同一个功能
- 一摞一摞的 PR 等着审查,没有人有任何上下文
---
## 怎么解决?
我们需要一些工具,帮助团队里所有人**在 Agent 开始工作之前对齐,而不是之后。**
这种对齐需要持续发生,与实现并行。
规划和构建不再是分离的两个阶段。它们是连续的循环。未来的工具需要把规划、上下文收集、决策和开发放在同一个屋檐下。
这一点尤其重要,因为**对齐所需的大部分上下文不在代码库里。**
它在人的脑子里。
- 你的业务上下文和财务资源,决定了正确的事是什么
- 谁掌权、谁做决策的政治动态
- 领导和 PM 的产品愿景
- 设计师和客服的用户研究洞察
- 组织的历史和你以前建过什么
……所有这些在决定"你的团队该建什么"的时候,都极其重要。
**Agent 永远不可能自己发现这些上下文。** 你需要一种方式,让人类早点分享出来、自然地分享出来,而不是增加流程和负担。
---
## Ace:一个原型
所有这些对 Next 来说都非常清晰,所以我们一直在做一个新的研究原型来探索怎么解决这些问题。它叫 **Ace**。还不是正式产品。如果你觉得它看起来有点粗糙,那是因为它确实粗糙。
我们即将进入技术预览阶段。我们会和几千个用户一起测试,了解人们在里面的协作方式,然后迭代。
这就是 Ace。可能看起来很眼熟。我们不多造没必要的轮子。
它有点像 Slack、GitHub、Copilot 和一堆云电脑生了个孩子。
左边是会话列表。**会话(session)是我们工作的地方。是一个多人聊天。** 类似 Slack 的频道。
我的队友在里面,我们可以聊我们在做的工作。但我的编码 Agent 也在里面。
每个会话不只是聊天频道。它还背靠一个 **microVM**——一个云端沙盒电脑,在它自己的 git 分支上。
每个会话里的修改是隔离的,所以我们可以并行处理不同任务,并且瞬间切换。
如果我想拍拍队友肩膀,问问他们对我正在建的功能的看法——**没有人需要 stash 他们的 git 改动、拉下分支、或者折腾任何本地 worktree。**
我直接跳进他们的会话,看看他们在干什么。包括他们跟 Agent 的整个 prompting 历史,理解他们是怎么到达当前状态的。
就像本地机器一样,我可以在会话里运行终端命令。我跑了 `bun install` 和 `bun dev` 来启动我当前的项目。
我的实时预览在侧边的浏览器里打开。我的 demo 项目是一个冷静版的 Hacker News,只显示过去三个月里的热门文章。
我要让 Agent 把配色改成紫色。我们可以看到它立刻出现在预览里。
Agent 自动帮我提交了,附带一个可读的 commit message。我可以打开 diff 确认它实现的方式是我想要的。一切你对编码 Agent 的期待。
---
## 多人 prompting
现在我们准备做点真正的工作。队友在这个会话里和我在一起。我要让 Ace 给我的应用加一些额外的配色主题。我选我想用的模型——Opus 4.6。Ace 开始干活。
右上角有一个很实用的摘要块,始终与这个会话的最新改动保持同步,不管改动来自我还是别人。这意味着我可以在会话之间切换,始终了解发生了什么,哪怕同时有多条并行工作流。
但更重要的事是,我想跟队友说话。我可以问他们觉得当前的改动怎么样。
他们可以自己启动 dev server。
记住,**我们都在云端的同一台电脑上工作**,所以这完全没问题。我们都能看到同样的预览,我们都可以输入终端命令、看到共享的输出。没有人会说"在我机器上跑不起来"。
我的队友 Nate 和 Idan 进来了。他们截了图,提了一些替代功能的建议,在问问题。
我们能看到 Nate 正在让 Ace Agent 做修改。最初是我启动了这个会话,但我们俩都可以给 Agent prompt。**这是多人 prompting。** Agent 也能读取我们的整个对话——那都是 prompt 的输入。
这种 Slack 式的、可以访问编码 Agent 的界面意味着:**所有参与创造软件的人——不只是开发者,还有设计师和 PM——都可以在同一个对话里,实时看到功能被构建的过程。**
如果你在想,为什么不用 Slack?因为 Slack 永远不会成为一个功能完整的软件开发工具。它没有正确的原语,而且它不会去加。Ace 明确是为了软件开发而设计的,但它比其他终端工具更欢迎团队里的非开发者进来。
---
## 回到交付
我们觉得效果不错,所以准备创建 PR。毕竟最终所有这些代码都要回到 GitHub。
我们可以直接在 Ace 里面创建 PR。可以在 GitHub 上打开。它有一个链接回到我们的 Ace 会话。这一切都是向后兼容的。
有时候你还是需要碰代码。我觉得前端设计工作仍然是这样。Agent 在 CSS 上简直一塌糊涂。
我们仍然可以在 VS Code 中打开我们的项目。我们有**实时的、多人的代码编辑**,和会话里的所有人一起。
因为——再说一遍——这是一台 microVM 云电脑。
我可以合上笔记本电脑,工作可以继续。**我的会话不会死。** 我的队友可以继续跟 Ace 聊天,继续推进。
我们还没有移动端界面,但正在做。microVM 会让移动体验无缝衔接。我可以在手机上打开 Ace,不需要 SSH 进一个终端实例、不需要开着笔记本、不需要去买一台 Mac Mini 来保持可用。**我只需要跟我云端的那台永远在线的 Ace Agent 说话。**
---
## 计划模式
对于更大、更复杂的功能,你会想让 Agent 写一个计划。这已经是一个非常标准的工作流了。
我们在讨论给冷静版 Hacker News 加可变时间范围,然后我让 Ace 做一个计划。
我们在计划里了。我可以看到所有队友的光标。**我们可以一起协作编辑它。**
Nate 在建议用下拉菜单而不是分段组件来做界面。Idan 在更新需求,让 Agent 知道要这么做。
当我们对所有细节满意了,就可以回到聊天,让 Ace 开始构建,然后它就去了。
---
## 仪表盘
我跳到了 Ace 的仪表盘。
很多本应发生在 Slack 或 GitHub Issues 里的规划和讨论,现在都发生在我们的会话里。我们可以接触到大量关于正在进行的工作的丰富上下文,并且可以有效地总结它。
现在是周一早上,我在试图回忆上周五我留下什么没做完。Ace 在提示我继续做我在重构时写的一些 React hooks。这很有用——长周末之后我的人类记忆很烂。
从这里我可以启动一个新会话,或者在"继续做"区域,一键打开一个会话继续我没合并的重构 PR。
我也可以看到最近完成的 PR 和 Issue 的列表,用来抚慰我的自我,让我觉得自己很有生产力。
右边有一个"团队脉搏"区域,总结了我的同事在过去几天里干了什么。
我可以看到 Nate 在交付一个 lobby 频道。David 在修 access token 的问题。
也有这个仓库上最近 PR 和 Issue 的原始信息流。但我觉得摘要模式更有用。
**Agent 驱动开发最大的挑战之一是:工作的速度和量级让你很难跟上同事在做什么。** 他们现在一天交付五个功能而不是一个。
这个仪表盘是我们让 Agent 主动把上下文带给你的第一次尝试。
---
## 社交信息织物
如果所有围绕代码的对话都可以被 Agent 访问,那就给了它们接触一张**社交信息织物**的权限——它们可以每天早上帮你定位,帮你和团队保持对齐。它们可以通知你某个决策,或者把你拉进一个对话——有人正要扩展你最初建的功能。
**这不再是一堆孤立的、跑在个人电脑上的终端实例。这是一个活生生的智能环境,所有人共享同一个工作空间和上下文。**
---
## 这一切是为了夺回你的时间
在编码 Agent 出现之前,我们谁都没有足够的时间和精力按我们想要的方式来做产品。
我敢保证这个房间里的每个人都交付过自己不自豪的软件。也许你没有做足够的用户研究,也许没有足够仔细地考虑设计问题,也许没有想清楚架构选择的影响。
不是因为你不想。而是因为**实现占用了我们太多的时间和精力。**
但我们被还回来了很多时间。
我们有一个机会——不是跑得更快、建一大堆同样烂的软件。而是通过更严谨的批判性思考和规划阶段更好的对齐,来做出更好的软件。
更多的探索,更多的研究,比之前更深入地思考问题。Agent 允许我们以一种方式扩展团队,如果做得对,应该会通向更高质量的软件。
很多人现在意识到:**在一个软件又快又便宜的世界里,质量成了新的差异化因素。**
门槛在变高。**工艺(craftsmanship)会让你区别于 vibe-coded 的垃圾。**
但工艺仍然消耗时间和精力。它不是免费的。而为了买到这些时间和精力,你需要**做更少的事、做更好**——这需要强大的对齐。
现在也有比以往更多的干扰。很容易一个 prompt 就走向了错误的方向,或者给你的产品加了一大堆没用、不需要的功能。
**我的梦想是,我们最终会拥有一些工具——不管是 Ace 还是别的——能创造出这样的环境:团队可以在一起严谨地思考困难的问题。我们的 Agent 工具应该帮我们做更高质量的工作、更快地对齐、建出少数几个卓越的东西,而不是一千个垃圾。**
---
原文:Maggie Appleton, *One Developer, Two Dozen Agents, Zero Alignment: Why we need collaborative AI engineering*
maggieappleton.com/zero-alig…
#AI工程 #Agent #团队协作 #GitHub #软件工程
1
199

Claude Code免费接入DeepSeek V4教程,零成本爽用
第一步:获取API Key
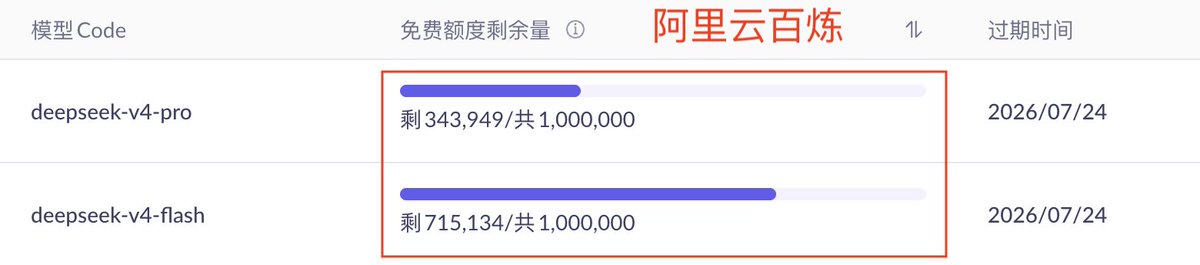
可选择阿里云百炼或魔塔社区,都提供了一定的免费额度
阿里云百炼(V4 flash和pro各100w token额度) bailian.console.aliyun.com
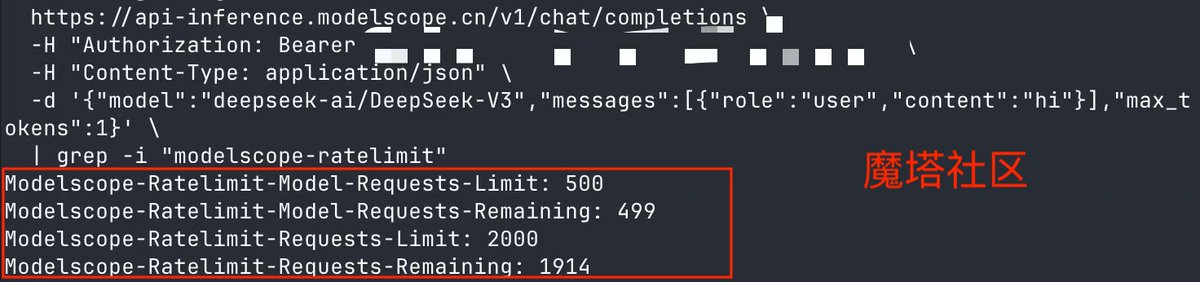
魔塔社区(日均2000次免费调用,单模型日均限500次) modelscope.cn/home
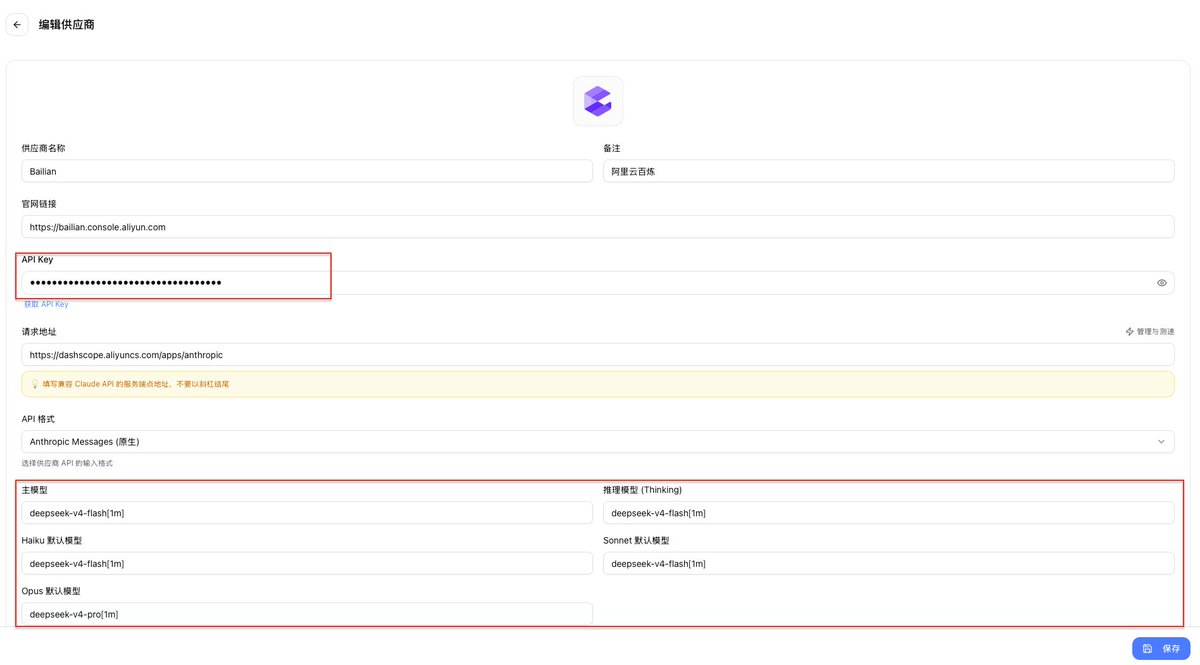
第二步:下载 CC Switch 并新建供应商
CC Switch是一个方便切换不同供应商的桌面工具
下载地址:github.com/farion1231/cc-swi…
下载完后进入应用,新建供应商,从预设中选 Bailian 或 ModelScope,把对应平台的 API Key 粘贴进去。
第三步:配置模型
按需求来填,我是主模型V4 flash,Opus选V4 pro
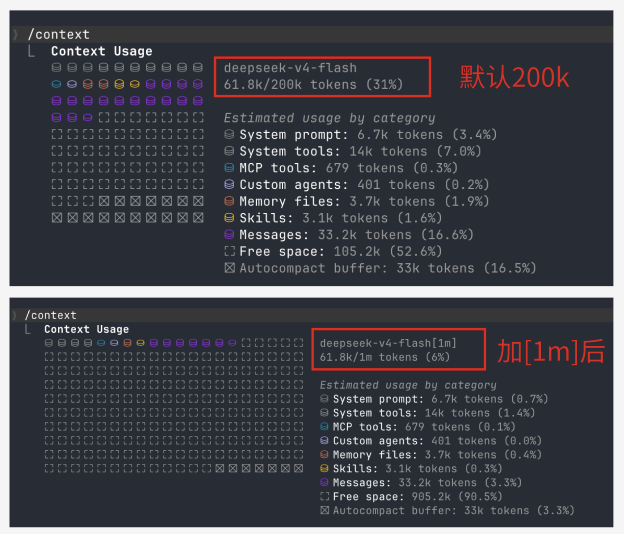
有个坑要注意,默认只有 200K 上下文,想开 1M 上下文必须在模型名后面加 [1m]
注意不同平台模型名写法:
- 阿里云百炼:deepseek-v4-flash[1m]、deepseek-v4-pro[1m]
- 魔塔社区:deepseek-ai/DeepSeek-V4-Flash[1m]、deepseek-ai/DeepSeek-V4-Pro[1m]
第四步:保存配置,打开 Claude Code 即可食用
29
315
1,613
178,450

最近更新了一版自己的开源 Skills 仓库:
🔹 wtt-app-review-insights:丢一个 App 名字进去,自动去 app store 抓评论,AI 挖出痛点、机会、用户分层、版本风险。我上周分析了一个竞品,5 分钟出报告,以前要翻一整个下午。这个感谢 @vista8 向阳乔木大佬的开源,我把它改成 skill 来用了。
🔹 wtt-llm-wiki-builder:在任意文件夹里搭知识库。散落的笔记 → 结构化 wiki,支持三种模式:从零搭建 / 增量编译 / 健康体检。我现在所有知识资产都在这个架构里跑,再没乱过。这个感谢 Andrej karpathy 大佬,我把他的 markdown 文件改成了可执行的 skill,可以快速帮忙整理和开发知识库。
🔹 wtt-project-harness-generator:扫一遍你的代码,对话几个问题,自动生成 CLAUDE.md 和 AGENTS.md。新项目 5 分钟配好 AI 规则,不用再口头传。这个主要是 vibe coding 的时候专用,好的开发,先要有好的开发文档,使用这个 skill 可以帮你把第一步搭建好。
三个 Skill,Plugin 市场直接装,装了就跑👇
github.com/WaterDJiang/Wattt…
2
40


有人用几天时间搭了一套 AI 控制的手机矩阵
硬件全是捡来的:一台旧 3D 打印机的框架、几台淘汰的安卓手机,再加上一个免费开源 AI 模型生成的控制代码
从视频看,3D 打印机的机械臂被改成了自动操作手机屏幕的装置,AI 控制移动轨迹,实现多台手机同时自动交互内容
说白了就是一个 AI 驱动的物理手机农场
这个项目有意思的地方不在于它能干什么,在于它的成本结构:旧硬件 免费模型 vibe coding,几乎零成本。一个人几天就能搭出来
以前做这种自动化要么靠软件模拟器(容易被平台检测),要么买专门的群控设备(几千上万)。现在用废旧硬件加 AI 就能搞定
技术无所谓好坏,看用在什么地方。拿来做内容分发测试、多账号管理、自动化测试都行,拿来刷量就是另一回事了
不过这个动手能力确实可以,废物利用做到这个程度属实有点东西
4
5
1,422


哭了,原来给 AI Agent 做一个 Token 压缩器,核心代码零依赖就能搞定。
背景是这样的,现在用 Cursor、Claude Code 这些 AI 编码代理,上下文窗口烧 Token 特别快,尤其是把整个代码库喂进去的时候。一个简单的压缩思路是,把代码里不影响语义理解的部分(空行、注释、多余空格)在发送前压掉,拿回来的时候再还原。
今天手写一个零依赖的 Python Token 压缩器,能直接集成进你自己的 Agent pipeline。
前置条件:Python 3.9 ,不需要装任何第三方包。
第一步,建项目结构:
```
$ mkdir token-compressor && cd token-compressor
$ touch compressor.py test_compressor.py
```
第二步,写核心压缩逻辑。思路是分三层:移除注释、压缩空白、缩短常见模式:
```python
# compressor.py
import re
class TokenCompressor:
def __init__(self, level="medium"):
self.level = level # light, medium, aggressive
def compress(self, code: str, lang: str = "python") -> dict:
original_lines = code.split("\n")
result = code
# Layer 1: strip comments
if lang == "python":
result = re.sub(r'#[^!].*$', '', result, flags=re.MULTILINE)
elif lang in ("javascript", "typescript"):
result = re.sub(r'//.*$', '', result, flags=re.MULTILINE)
# Layer 2: collapse blank lines (keep max 1)
result = re.sub(r'\n{3,}', '\n\n', result)
# Layer 3: strip trailing whitespace
result = re.sub(r'[ \t] $', '', result, flags=re.MULTILINE)
if self.level == "aggressive":
# collapse docstrings to single line
result = re.sub(
r'"""[\s\S]*?"""',
'"""..."""',
result
)
# shorten consecutive blank lines to zero
result = re.sub(r'\n{2,}', '\n', result)
compressed_lines = result.split("\n")
ratio = len(result) / max(len(code), 1)
return {
"compressed": result,
"original_chars": len(code),
"compressed_chars": len(result),
"ratio": round(ratio, 3),
"lines_before": len(original_lines),
"lines_after": len(compressed_lines)
}
```
第三步,写个命令行入口,能直接对文件用:
```python
# 在 compressor.py 末尾追加
import sys
def main():
if len(sys.argv) < 2:
print("Usage: python compressor.py <file> [level]")
sys.exit(1)
filepath = sys.argv[1]
level = sys.argv[2] if len(sys.argv) > 2 else "medium"
with open(filepath, "r") as f:
code = f.read()
c = TokenCompressor(level=level)
result = c.compress(code, lang=filepath.rsplit(".", 1)[-1])
print(result["compressed"])
print(f"\n--- Stats ---", file=sys.stderr)
print(f"Ratio: {result['ratio']} ({result['original_chars']} -> {result['compressed_chars']} chars)", file=sys.stderr)
print(f"Lines: {result['lines_before']} -> {result['lines_after']}", file=sys.stderr)
if __name__ == "__main__":
main()
```
第四步,测试一下:
```
$ python compressor.py compressor.py medium
```
你会在 stderr 看到压缩比,一般注释多的文件能压到 0.6-0.7,aggressive 模式能到 0.5 以下。
第五步,集成进你的 Agent 调用链。在发送给 Claude API 之前套一层:
```python
from compressor import TokenCompressor
def prepare_context(file_paths, level="medium"):
tc = TokenCompressor(level)
context_parts = []
for fp in file_paths:
with open(fp) as f:
code = f.read()
result = tc.compress(code, lang=fp.rsplit(".", 1)[-1])
context_parts.append(f"--- {fp} ---\n{result['compressed']}")
return "\n\n".join(context_parts)
# 然后塞进 messages
compressed = prepare_context(["main.py", "utils.py", "config.py"])
messages = [{"role": "user", "content": f"Codebase:\n{compressed}\n\nRefactor the error handling."}]
```
避坑点:
1. aggressive 模式会把 docstring 干掉,如果你的 Agent 需要理解函数用途,用 medium 就好
2. 正则去注释对字符串里带 # 的情况会误伤,生产环境建议用 AST 做(但那就不是零依赖了)
3. 压缩比不是越低越好,压太狠了 Claude 反而看不懂上下文,medium 是实测的甜点
整个项目零依赖,一个文件就能跑。实测在 5000 行的项目上,能省大概 30% 的 Token 开销。。这个钱积少成多还是很可怕的。
20
1
10
431

有很多朋友脑子里装满了很有创意的产品点子,却往往因为不懂代码,倒在了实现的第一步,也有很多人花大几百甚至几千去报什么 Vibe Coding的课程。
刚好看到 Datawhale 开源了 Vibe Vibe 这份指南,专门教你用 AI 辅助编程,从零基础到能做出完整产品。
核心理念是 “你负责想法,AI 负责实现”,通过自然语言描述需求,让 AI 生成代码,你来验收和调整,快速做出能用的东西。
GitHub:github.com/datawhalechina/vi…
内容设计上充分考虑了不同人群,分为了零基础入门和全栈实战两个板块。
基础篇从 “什么是代码” 开始,教你 MVP 思维、提示词工程,适合零基础技术小白。
进阶篇基于 Next.js TypeScript Prisma,系统学习全栈开发,适合有一定基础的开发者。
如果你想快速入门编程,或者想提升 AI 辅助开发效率,这个教程值得一看。
1
4
14
632



兄弟们,这回真没瞎吹,Google 直接把代码阅读这件事给干到天花板了 🔥
之前我安利过的 Understand Anything 已经够香了吧?现在 Google 亲自下场端出了 Code Wiki,一句话总结:随便扔一个 GitHub 仓库进去,零安装秒变交互式维基百科。
1️⃣ 不用装任何东西,浏览器直接开干
2️⃣ Gemini 把整个仓库读穿,想问啥就问啥
3️⃣ 架构图、依赖关系、模块说明全自动生成
4️⃣ PR 更新实时同步,永远不用担心过期
我实测了一个大仓库,10 分钟理清整体结构,以前要啃三天的屎山代码现在靠对话就能解决。Understand Anything 这下真可以退休了,程序员看代码的方式被彻底改写。
地址:codewiki.google

2
3
11
1,142

Generative UI × Agent Harness
Coding Agent(Claude Code / Codex / Pi)在 Vercel Sandbox 里真实改代码、跑命令、测用例;汇报时不再只返回 Markdown,它基于「json-render」输出受约束的 JSON UI 规格,前端实时渲染成步骤、Diff、终端、测试结果、图表等组件。
github.com/vercel-labs/json-…
这个实现思路,和 Claude Code 核心开发者 @trq212 「Using Claude Code: The Unreasonable Effectiveness of HTML」异曲同工:
x.com/trq212/status/20528098…
技术架构(三层解耦)
用户 Prompt
↓
HarnessAgent(AI SDK 7 实验 API)
├─ Claude Code / Codex / Pi(可互换)
└─ Vercel Sandbox(隔离 Linux 环境,真实 bash/edit/test)
↓
Agent 输出:短 prose ```spec 围栏内的 JSONL
↓
pipeJsonRender(从流中提取 spec → data-spec parts)
↓
前端 useChat useJsonRenderMessage → 渲染组件树
关键设计点:
1. Harness 抽象与模型抽象对称
AI SDK 7 的 HarnessAgent 让你像换模型一样换 Harness——claudeCode 换成 codex 或 pi,调用方式不变。Harness 管 skills、sandbox、session、权限、compaction 等「模型之上的层」。
2. UI 层与执行层完全解耦
HarnessAgent. stream() 返回标准 AI SDK StreamTextResult,因此 json-render 管道与单模型 chat 示例 完全相同。换 Agent Harness,前端代码不用改。
3. Catalog 约束 = 安全 可预测
Agent 只能使用预定义组件(Steps、FileChange、Terminal、TestResults、Metric、BarChart…),输出必须符合 Zod schema。AI 生成 UI,但 在你划定的组件边界内。
4. Session 绑定 Sandbox
每个 chat 维护一个 live session sandbox;首条消息冷启动较慢,后续复用同一工作区。10 分钟 idle 或「Start Over」会销毁 sandbox。
一次完整交互里发生了什么
1. 用户选 Agent(Claude Code / Codex / Pi)并发送任务
2. 服务端 getSession(chatId, agent) 创建或复用 Harness session
3. Agent 在 sandbox 内执行真实操作(写文件、跑测试、benchmark 等)
4. 回合结束时 Agent 输出:
· 一两句 conversational 总结
· 一个 ```spec 围栏包裹的 JSONL UI 报告
5. pipeJsonRender 把 spec 从文本流中拆出,变成 typed data-spec parts
6. 前端同时渲染:Markdown prose、工具调用活动行(bash/edit/read…)、结构化报告组件
Agent 的 system instructions 明确要求:不得虚构结果——失败就展示 error step、非零 exit code、失败测试;Terminal 必须用 session 中真实捕获的输出。

16h

Introducing Generative UI for Claude Code, Codex and Pi
Charts, forms, 3D, anything
Your agent renders real UI for users while it works in a sandbox
Powered by AI SDK's experimental HarnessAgent json-render
2
6
1,371
Agentic Code Review
作者 @addyosmani
随着工程瓶颈已从「写代码」转移到「能否信任代码」,代码审查成为当前软件工程里杠杆最高的能力。
# 四份独立来源(Faros AI、CodeRabbit、GitClear、GitHub)指向同一结论:
· 代码产出约 4 倍,实际交付价值仅约 10%:多出来的 90% 是「待验证的代码」
· 代码 churn 861%、缺陷率 9%→54%:质量与可审查性在下降
· 零 review 合并的 PR 31%、review 时长 441%:不是「决定不 review」,而是 review 跟不上量
· AI 共著 PR 问题数约 1.7 倍:弱点可预测:逻辑、安全、可读性
# 最重要的前提:你在光谱的哪一端
Osmani 反复强调:大多数争论是不同处境的人互相 prescribing。
三个变量决定 review 策略:
· 爆炸半径 — 坏了会怎样(无人用 vs 用户/金钱/PII)
· 代码寿命 — 下周重写 vs 维护十年
· 理解者数量 — 只有你 vs 整个团队
solo 无用户:可 lean on 测试 自动化,轻量 review;但「无用户 ≠ 无验证」,跳过 review 只是把债往后推。
有用户的中期(最危险):仍沿用 solo 习惯,直到事故/postmortem 才醒悟。
大型老系统 多用户:文中所述所有 alarming 数据 全部适用,review 同时承担 bug 捕获、知识传递、 comprehension debt 防控。
# Review 的本质变了
传统 review:作者在脑子里已有 intent,reviewer 核对推理。
Agentic review:agent 有 reasoning,但 几乎从不随 diff 附上;reviewer 常是 第一个真正读这段代码的人,还要 重建从未写下来的 intent——这比旧模式更难、更慢,解释了 review 时长暴增。
可解的部分(工具问题):
· 要求 agent 提交:做了什么、排除了什么、决策日志
· 把 intent 重建成本 推回提交方,而非 reviewer 吸收
不可完全外包的部分(人的问题):
· 「这段代码对不对」 vs 「该不该做这件事」
· 没人写进 spec 的需求缺口
· 高爆炸半径下的 accountability
# AI Review 工具:不要选「最好的一个」,要跑「不同的几个」
实证(146 个 PR、4 个 reviewer 并行):
· 93.4% 的 flagged 位置只被 1 个工具发现
· 四个工具 从未同时 flag 同一行
· 各有强项:Greptile(正确性/架构)、CodeRabbit(覆盖面 修复)、Seer(生产严重度)
结论:同质模型 × 4 = 一个 reviewer 四倍账单;异构 reviewer 组合 才接近「对抗式审查」。高 stakes 跑两个性格不同的;solo 一个 good reviewer 真测试通常够用;必须在自己代码库上实测。
# 人的角色:从 loop 里到 loop 上
Osmani 的立场(也是文中最具操作性的框架):
· 「人类逐行读每个 diff」已不现实
· 「让 loop 自审自判然后走人」同样危险 — 同源模型的 correlated blind spots,会形成 借来的 confidence
· 正解:human on the loop,而非 in the loop
· 机器:第一遍 triage、低风险/fast-track、重复性检查
· 人:merge 决策、高风险路径、plan/judgment、抽样审计
他自己的做法:用 Claude Code/Codex 对一批 PR 做 风险排序 triage,几分钟确认低风险项,把深度 attention 留给 flagged 项——不是 review 变快,是 review 的形状变了。
Kun Chen(~40 PR/天)是光谱另一端:plan 写在前、agent 并行跑、自动化 gate(No Mistakes)、人负责 escalation——不是不 verify,是把 verify 前移/自动化;复制到企业多用户系统 ≈ 复现 Faros 数据。
# 可执行的 Review 体系(重要!)
1. 按风险分层,不按作者分层
配置改 → linter 一眼;核心路径 → types、tests、双 AI reviewer、owner 人工、安全 pass。
2. upfront triage(circuit breaker)
Agent PR 约 28% 可快速合并;大 patch、高维护成本 PR 应 先预测、再决定是否投入 human hour——否则 agent 常在主观反馈后 ghost,reviewer abandonment 占 rejected agent PR 的 38%。
3. 提高 intake 门槛(证据 required)
变更目的陈述、合理大小的 diff、真实跑过的 test output——把「第一个读代码的人」从 reviewer 推回 author/agent。
4. 刻意小 PR
Agent PR 平均大 51%;大 diff 要么被拒,要么被 rubber-stamp。
5. 先读 test diff,再读 implementation
典型 failure mode:改行为 → 改 assertion 让测试变绿。绿 check ≠ 行为正确;mutation testing 在此有价值。
6. CI 是不可谈判的墙
警惕:删测试、skip lint、降 coverage、重复 helper、用户输入进 prompt 无防护。Agent 会「梯度下降」到最便宜的 green——CI 不能被说服。
7. 人 owns merge
AI review 是 sensor,不是 verdict;能点 merge 的人 = 能 on-call 的人。
# 对团队负责人的含义
· binding constraint 已是「trusted human 确认速度」,不是 generation 速度
· 因「AI 提速」砍 review/QA 人力 = 把节省换成未来 incident
· Review capacity 是 需度量、保护、 deliberate 花费的资源,不是 AI 解放出来的 slack
· OS maintainer 的 triage 地狱是 canary;企业若只盯 merged PR 指标,会看不见 senior engineer 被 review tax 拖垮


3
11
32
5,750

🌈 今日 2026-06-16|台灣AIVtuber同好會社團新聞速報喵~!
水瓶罐子抱著熱騰騰的新聞小魚乾翻滾登場啦~今天是台灣直播活動+國際 VTuber 情報雙拼套餐,請安心服用喵 🍱✨
🐑【2026-06-16|台V 阿煙更新小短篇】
阿煙今日更新《羊尾 vtuber 台v 阿煙 台灣vtuber》,台V日常小劇場又有新料可以啃啦 🐑✨
📢 創作者持續更新就是最可愛的燃料補給站~
🔗 傳送門留言區👇
🌶️【2026-06-16|四巳 Yomi 辣泡麵轉盤工商台】
四巳 Yomi 本週表排上「巳能有多辣?辣泡麵轉盤!」神居梅酒推廣直播,辣度與工商力一起開鍋 🌶️🔥
📺 台V直播企劃力持續升溫中~
🔗 傳送門留言區👇
🌙【2026-06-16|人偶薩賓娜 ASMR 陪睡直播】
人偶薩賓娜深夜白噪音 ASMR 開張,從 00:00 陪到清晨 07:00,直接把失眠抓去棉被裡封印 🌙
💤 睡眠系 VTuber 活動今日加班守夜中。
🔗 傳送門留言區👇
🌐 接下來是國際速報時段喵~🌍✨
🥤【2026-06-16|Anique × hololive EN 神祕企劃更新】
Anique 預告 holoEN 相關新情報今日 12:00 JST 更新,行動餐車風味的伏筆飄出來啦 🥤⭐
📢 粉絲雷達請開到最大,等官方揭曉。
🔗 傳送門留言區👇
🍘【2026-06-16|hololive Dreams 零食 vol.3 發售】
《hololive Dreams》聯名零食第 3 彈今日登場,20 位成員貼紙隨機封入,抽卡魂開始咔滋咔滋燃燒 🍘✨
🎮 手遊、周邊、食玩一起串成粉絲收藏小宇宙。
🔗 傳送門留言區👇
🎤【2026-06-16|桃鈴ねね 1st Live 二次先行入金截止】
桃鈴ねね 1st Live「超開花!」二次先行入金今日 23:00 截止,抽到票的粉絲別讓票票逃跑啦 🎤🌼
🎟️ 演唱會前線進入倒數確認模式。
🔗 傳送門留言區👇
━━━━━━━━━━━━━━━━
🏪【水瓶罐子合作與推薦賣場】
👑【罐子・推薦|Live2D 基本知識教學】
想讓角色動起來?
想讓自己的靈魂住進另一個身體?
那這套 Live2D 基礎系統課,就是創作者入門的地圖。
由李安瑟羅老師規劃的完整教學架構,從觀念、設備、流程到整體實作邏輯,一步步拆解 Vtuber 的建構核心。
不只是學操作,而是理解整個創作結構。
💳MyCard 點數的用途其實不只限於各種遊戲~也可以用來兌換 LINE 貼圖、KKBOX 方案等多元生活娛樂內容!
現在在駐站期間,MyCard 特別加碼提供「現金抵用券」回饋給粉絲們!
點我資訊欄連結或掃描圖片上的 QR Code 進行購點,再登入 MyCard 會員,最後直接輸入『MyCard創作者水瓶罐子』!
滿300元即可現折20元,直接幫你省一筆,趕快去用!
專屬現金抵用券:詳細資訊請見留言區
🛎️ Vwake 鬧鐘 App。
App Store 或 Google Play 搜尋「Vwake」。用水瓶罐子的聲音叫你起床。
推薦碼:AQUARIUSGIRL2026
🔗 詳細資訊請見留言區固定連結👇
━━━━━━━━━━━━━━━━
🎀 以上就是今天的《罐子選報》喵!
每日補充 AIVtuber 新聞維他命,創作者魂才會閃閃發亮 ✨
有想推薦罐子追蹤的台灣或國際 VTuber,也歡迎留言給我喵~
#台灣AIVtuber同好會 #VTuber速報 #水瓶罐子上工囉✨ #今天也有乖乖打新聞喵

1
5
801
🌈 今日 2026-06-16|台灣AIVtuber同好會社團新聞速報喵~!
水瓶罐子抱著熱騰騰的新聞小魚乾翻滾登場啦~今天是台灣直播活動+國際 VTuber 情報雙拼套餐,請安心服用喵 🍱✨
🐑【2026-06-16|台V 阿煙更新小短篇】
阿煙今日更新《羊尾 vtuber 台v 阿煙 台灣vtuber》,台V日常小劇場又有新料可以啃啦 🐑✨
📢 創作者持續更新就是最可愛的燃料補給站~
🔗 傳送門留言區👇
🌶️【2026-06-16|四巳 Yomi 辣泡麵轉盤工商台】
四巳 Yomi 本週表排上「巳能有多辣?辣泡麵轉盤!」神居梅酒推廣直播,辣度與工商力一起開鍋 🌶️🔥
📺 台V直播企劃力持續升溫中~
🔗 傳送門留言區👇
🌙【2026-06-16|人偶薩賓娜 ASMR 陪睡直播】
人偶薩賓娜深夜白噪音 ASMR 開張,從 00:00 陪到清晨 07:00,直接把失眠抓去棉被裡封印 🌙
💤 睡眠系 VTuber 活動今日加班守夜中。
🔗 傳送門留言區👇
🌐 接下來是國際速報時段喵~🌍✨
🥤【2026-06-16|Anique × hololive EN 神祕企劃更新】
Anique 預告 holoEN 相關新情報今日 12:00 JST 更新,行動餐車風味的伏筆飄出來啦 🥤⭐
📢 粉絲雷達請開到最大,等官方揭曉。
🔗 傳送門留言區👇
🍘【2026-06-16|hololive Dreams 零食 vol.3 發售】
《hololive Dreams》聯名零食第 3 彈今日登場,20 位成員貼紙隨機封入,抽卡魂開始咔滋咔滋燃燒 🍘✨
🎮 手遊、周邊、食玩一起串成粉絲收藏小宇宙。
🔗 傳送門留言區👇
🎤【2026-06-16|桃鈴ねね 1st Live 二次先行入金截止】
桃鈴ねね 1st Live「超開花!」二次先行入金今日 23:00 截止,抽到票的粉絲別讓票票逃跑啦 🎤🌼
🎟️ 演唱會前線進入倒數確認模式。
🔗 傳送門留言區👇
━━━━━━━━━━━━━━━━
🏪【水瓶罐子合作與推薦賣場】
👑【罐子・推薦|Live2D 基本知識教學】
想讓角色動起來?
想讓自己的靈魂住進另一個身體?
那這套 Live2D 基礎系統課,就是創作者入門的地圖。
由李安瑟羅老師規劃的完整教學架構,從觀念、設備、流程到整體實作邏輯,一步步拆解 Vtuber 的建構核心。
不只是學操作,而是理解整個創作結構。
💳MyCard 點數的用途其實不只限於各種遊戲~也可以用來兌換 LINE 貼圖、KKBOX 方案等多元生活娛樂內容!
現在在駐站期間,MyCard 特別加碼提供「現金抵用券」回饋給粉絲們!
點我資訊欄連結或掃描圖片上的 QR Code 進行購點,再登入 MyCard 會員,最後直接輸入『MyCard創作者水瓶罐子』!
滿300元即可現折20元,直接幫你省一筆,趕快去用!
專屬現金抵用券:詳細資訊請見留言區
🛎️ Vwake 鬧鐘 App。
App Store 或 Google Play 搜尋「Vwake」。用水瓶罐子的聲音叫你起床。
推薦碼:AQUARIUSGIRL2026
🔗 詳細資訊請見留言區固定連結👇
━━━━━━━━━━━━━━━━
🎀 以上就是今天的《罐子選報》喵!
每日補充 AIVtuber 新聞維他命,創作者魂才會閃閃發亮 ✨
有想推薦罐子追蹤的台灣或國際 VTuber,也歡迎留言給我喵~
#台灣AIVtuber同好會 #VTuber速報 #水瓶罐子上工囉✨ #今天也有乖乖打新聞喵

1
6
610

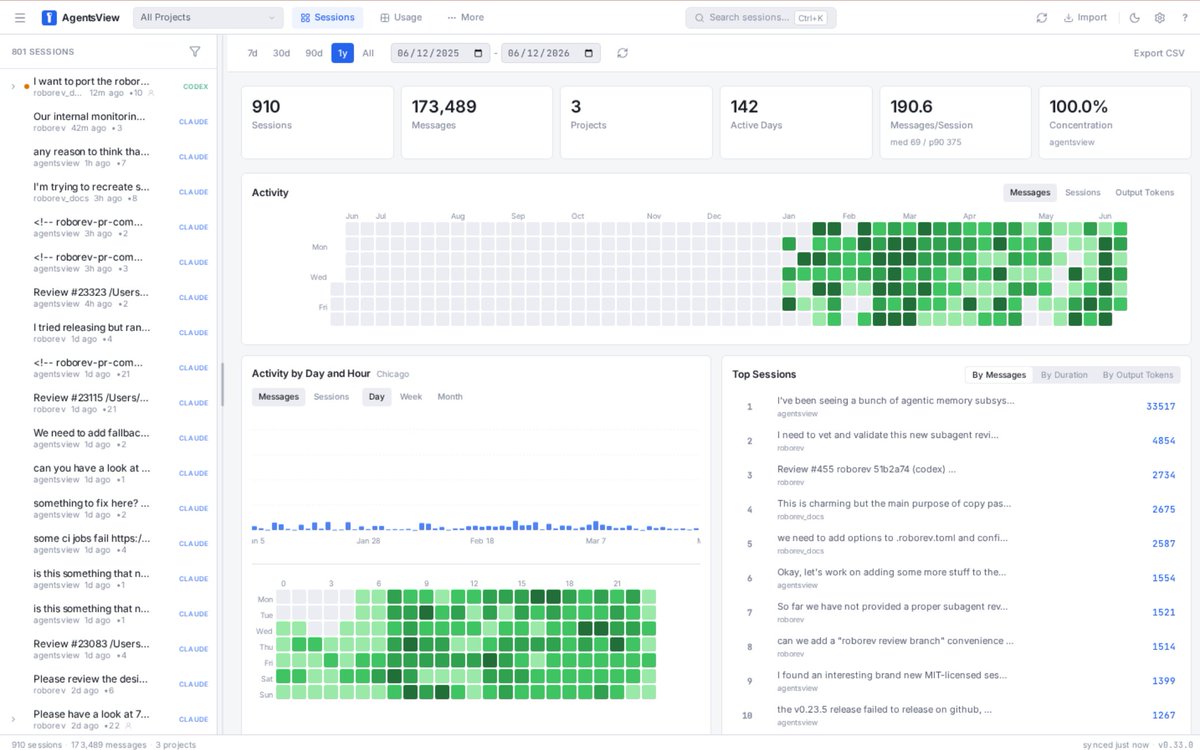
🔍 开源工具推荐:《AgentsView》—— 把你所有 AI Coding Agent 的会话装进一个本地分析平台,零账号、零云端
你每天用 Claude Code、Codex、Cursor,但从没有一个地方能统一看「到底花了多少钱」「哪些会话最耗 token」「不同工具之间用量怎么分布」,AgentsView 就是为这件事而生。
项目本地优先,一个二进制文件,无需注册账号,自动发现并索引你机器上 20 个 AI Coding Agent 的所有历史会话,存入本地 SQLite,比主流工具(如 ccusage)快 100 倍。
核心特性:
1. 自动发现多 Agent 会话:Claude Code、Codex CLI、Cursor、Hermes Agent 等 20 工具全覆盖
2. 全文搜索:跨所有工具、所有会话搜索任意消息内容
3. Token 用量与费用仪表盘:按会话、按模型分别展示,实时掌握 API 支出
4. 活动热力图与速度指标:可视化你的 Agent 使用习惯和节奏
5. 完全本地:所有数据存在你的设备上,零云端依赖,无隐私顾虑
特别适合每天用多个 AI Coding Agent 工作、想控制 API 费用或了解自己工具使用分布的开发者和工程师。目前已获得 2.4k stars ⭐,是当前开源 AI Coding Agent 本地会话分析工具里多工具支持最全面的实现之一。
与 Claude Code 自带的 /cost 命令相比,AgentsView 不只看单一工具——它把你所有 AI Coding Agent 的使用数据汇聚到同一张仪表盘,让你第一次真正看清整体 AI 工具开销的全貌。如果你一个月用了三四个 Agent 工具,这是唯一能统一追踪的方式。
github.com/kenn-io/agentsvie…
#AIAgent #ClaudeCode #VibeCoding #AI工具 #AIEngineering #CodeXero
1
5
605

BestBlogs 早报 · 06-16
# Loop Engineering / AI Agent 工具设计 / Token 成本控制 / Claude Fable 5 / Scaling Law
[1] ★ 精讲|一篇搞懂 AI Coding Agent 的 Token 成本控制
这篇文章把“Token 都烧在哪”讲透了:真正的账单大头不是你打的那几十个字,而是系统每轮自动带上的系统提示词、Skill、工具定义和会话历史——所谓“它记得”,本质是系统在一遍遍重复提醒模型。给出的优化路径也很朴素:一个 Session 只做一件事,长会话及时压缩,按任务给模型分档,把高频内容做成稳定前缀吃满 Prompt Cache。省钱的关键不是少问一句话,而是让系统别重复搬运同一批上下文。
来源:腾讯技术工程
bestblogs.dev/article/8b9392…
[2] ★ 精讲|AI 智能体工具设计:有效与无效的模式 - MachineLearningMastery.com
这篇文章把 AI Agent 翻车的锅,从「模型不够聪明」甩回「工具设计太糙」:单一职责工具优于万能 action 参数,用枚举和强约束 schema 堵住模型瞎猜,错误返回要带 recoverable 字段和下一步建议而不是甩一坑日志,写操作必须有幂等键,危险操作要拆成两步确认。核心判断很朴素——模型只能基于你给的接口推理,接口含糊,失败就是必然,不是偶然。
来源:Hacker News - Newest: "AI Agent"
bestblogs.dev/article/963dda…
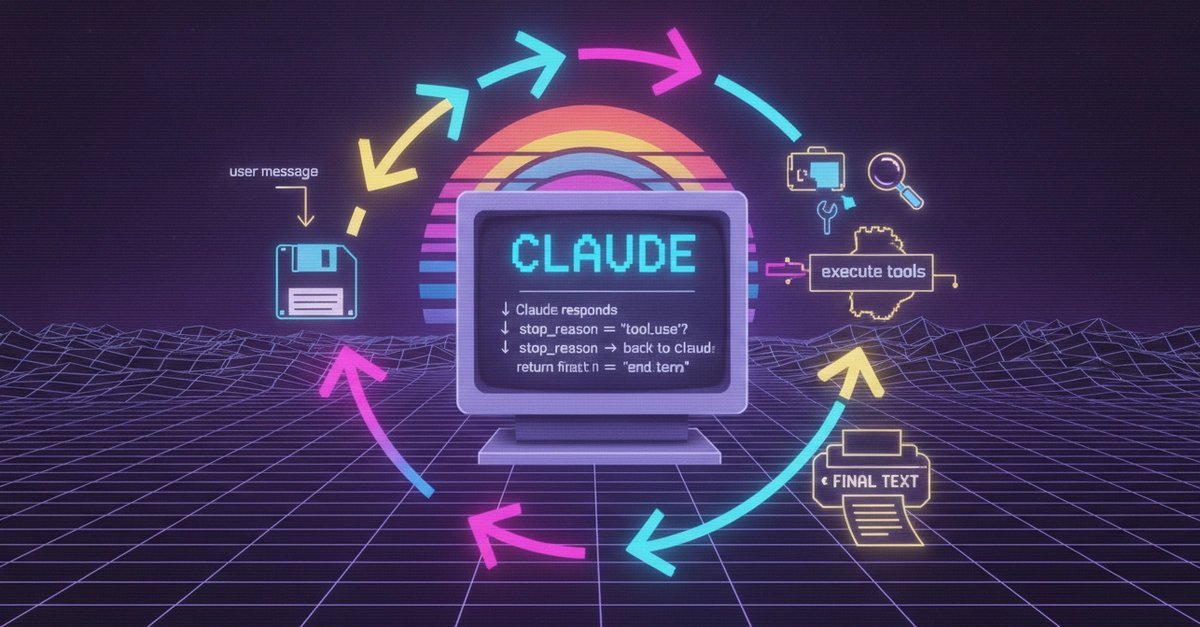
[3] ★ 精讲|Codex 和 Claude Code 负责人都不写提示词了,AI 圈爆火的 Loop 到底是什么
「循环工程」最近被吹成新范式,但文章先把热闹拆开看:技术上不算新发明,过去的 Harness、Skill、Agent 工作流早就在做,真正变化的是模型终于能把循环连续跑下去——人从写提示词退到定规则:何时启动、工具边界、出错怎么判断、记录在哪、何时收手交回人。结合另一篇用 OKR 和古德哈特定律拆解循环工程的长文,它更像一套管理制度:值不值得搭,取决于任务是否真反复、Token 预算够不够,而非这个新名字。
来源:APPSO
bestblogs.dev/article/24d7bb…
[4] Scaling Law 的真相,藏在那些「没用」的参数里|Hao 好聊趋势
本文深入剖析大模型参数冗余现象,论证看似「空转」的参数在训练、推理和后训练阶段分别扮演隔离空间、数值泄压、计算骨架和可塑性储备四种关键角色,并指出 Scaling Law 的边际收益正流向 benchmark 无法测量的长尾与多步推理能力。
来源:腾讯科技
bestblogs.dev/article/23d850…
[5] GlobalGPT 李焕之:零融资、套壳产品千万美金 ARR 后,我找到了创业的 mission
GlobalGPT 创始人李焕之分享从零融资套壳产品做到千万美金 ARR 的创业历程,并阐述其从「先活下来」到回归初心、打造服务型 AI 产品 Yukie 的思考。
来源:Founder Park
bestblogs.dev/article/ed22a9…
[6] 上线只活了 180 天,AI 应用层的泡沫被戳破了
本文以 Sora、Yupp.ai 等应用关停为引,分析 AI 应用层泡沫破裂的深层原因,指出真正活下来的产品已从单点功能转向超级入口、高频场景和 Agent 化工作流。
来源:腾讯科技
bestblogs.dev/article/0f79cb…
[7] Fable 5 禁令始末:Anthropic 亲手写下的剧本,反过来演了它自己
本文深度复盘 Anthropic 旗舰模型 Fable 5 遭美国政府出口管制禁令事件,揭示其背后技术争议、政治博弈与深层反讽,并探讨 AI 治理中权力制衡的核心命题。
来源:十字路口 Crossing
bestblogs.dev/article/369a03…
[8] 做了 6 年智能眼镜后,夏勇峰按下暂停键:为 AI 造硬件而非为硬件加 AI
蜂巢科技创始人夏勇峰基于对 AI 大模型趋势的判断,暂停了已占市场 10%份额的智能眼镜业务,转向「为 AI 造硬件」的新方向,核心是让硬件成为 AI 进入现实世界的最小载体,而非在硬件上叠加 AI。
来源:虎嗅
bestblogs.dev/article/70638b…
[9] SpaceX 登陆纳斯达克市值超 2 万亿美元,殖民火星使命驱动 24 年崛起史
本文通过实地探访 SpaceX 总部与星舰基地,结合前高管访谈,完整回顾了 SpaceX 从猎鹰 1 号三次失败到星舰成功回收、星链盈利、国防业务崛起的 24 年发展史,并解析其殖民火星的终极使命。
来源:虎嗅
bestblogs.dev/article/15fef7…
[10] 把 18 亿颗星星画在一张图上,能还原我们拍到的银河吗?
本文利用盖亚卫星 18 亿颗恒星数据,通过逐步引入点扩散函数、暗星光度代理、黑体辐射色温校准和韦伯阈值等物理与生理学原理,模拟出逼真的银河图像,并在此过程中揭示了星空视觉形态背后的关键科学原理。
来源:Computing Life
bestblogs.dev/article/2c2192…
---
BestBlogs.dev · 发现真正适合你的高质量内容
BestBlogs 是 AI 驱动的私人阅读助手,帮助你建立稳定、可信、个性化的高质量信息输入。 关注你感兴趣的来源和主题,每天生成一份更适合自己的「我的早报」。
在线阅读:bestblogs.dev/explore/brief/…

777