
4 Mar 2025
🥳#CodeCriticBench assesses LLMs' critiquing ability in code generation and QA tasks. Covering 10 criteria, it features a 4.3k-samples dataset with three difficulty levels and balanced distribution.
😉CodeCriticBench is now part of the #CompassHub! 😚Feel free to download and explore it.
🤗hub.opencompass.org.cn/datas…

3
312
28 Feb 2025
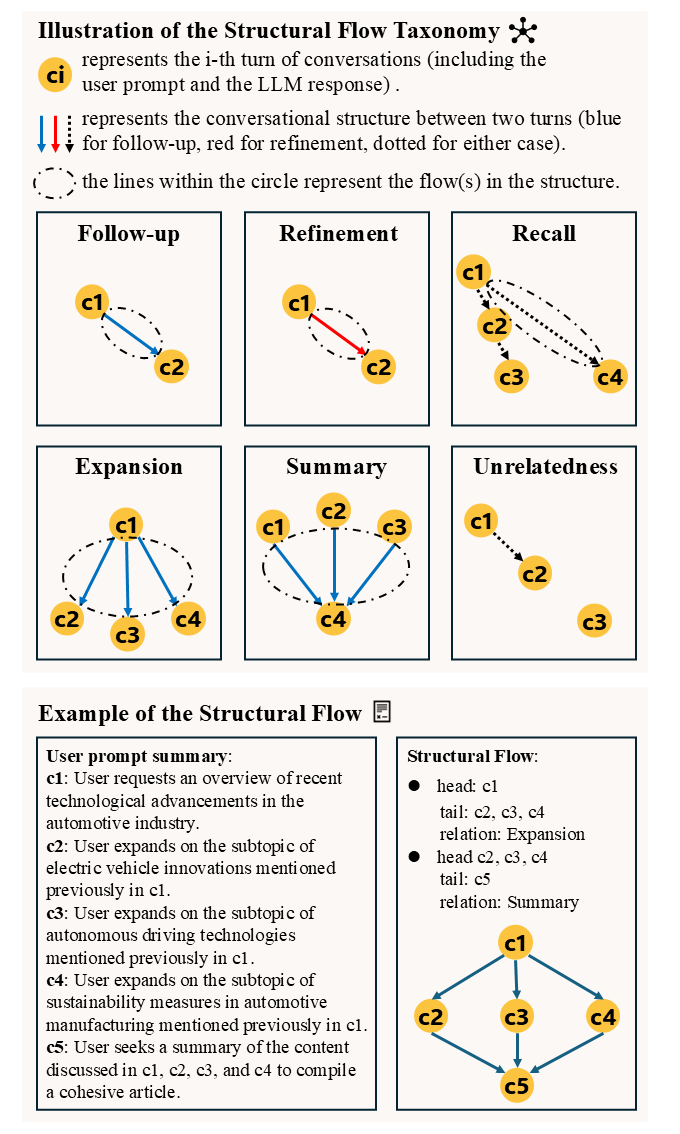
🥳#StructFlowBench is a structurally annotated multi-turn benchmark that leverages a structure-driven generation paradigm to enhance the simulation of complex dialogue scenarios.
🥳StructFlowBench is now part of the #CompassHub! 😉Feel free to download and explore it—available for public use.
🤗hub.opencompass.org.cn/datas…

1
3
800
27 Feb 2025
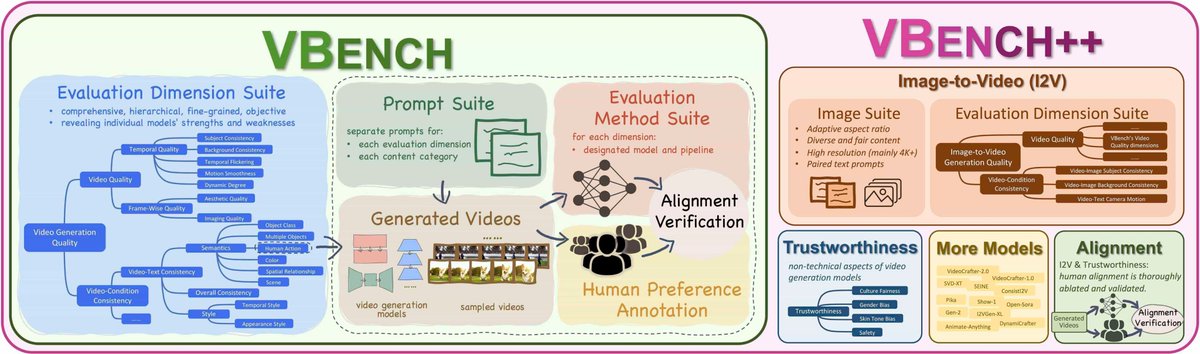
😉#VBench is a comprehensive benchmark evaluates video generation quality. It comprises 16 dimensions in video generation, and also provides a dataset of human preference annotations.
🥳VBench is now part of the #CompassHub! Feel free to download and explore it—available for public use.
🤗hub.opencompass.org.cn/datas…
2
225
26 Feb 2025
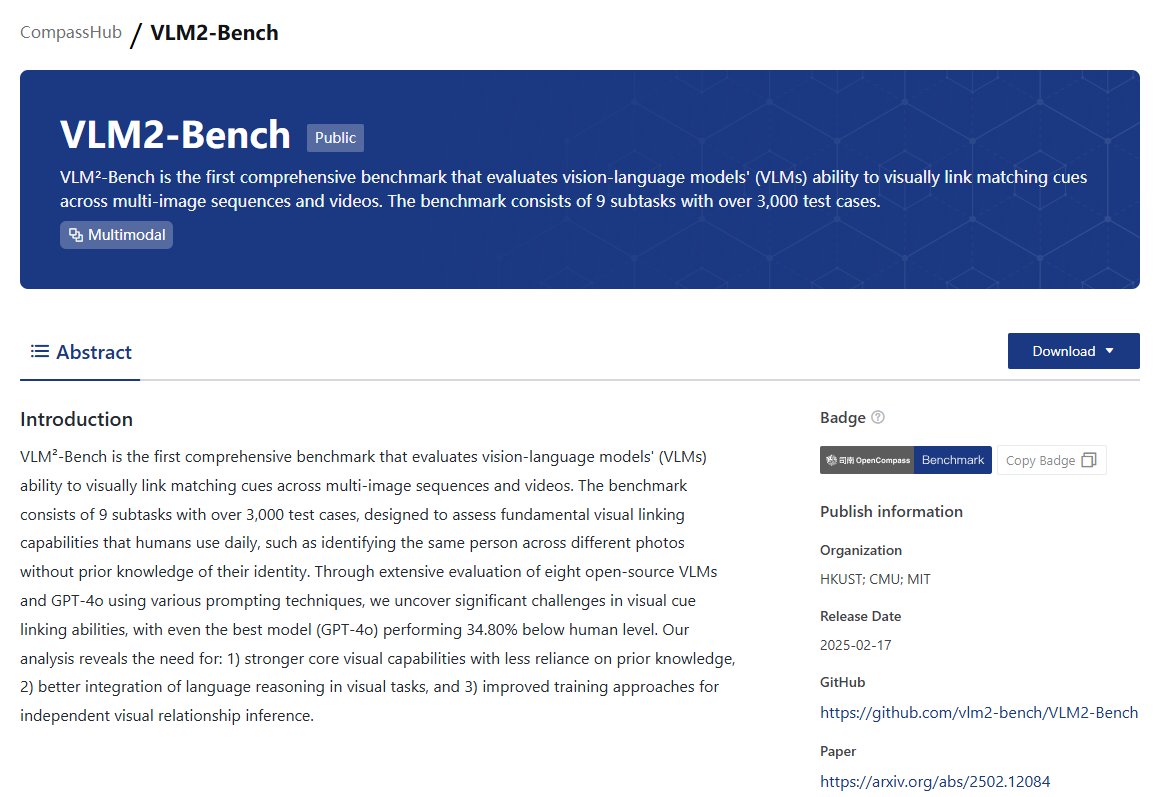
🥰VLM²-Bench is the first comprehensive benchmark that evaluates vision-language models' (#VLMs) ability to visually link matching cues across multi-image sequences and videos. The benchmark consists of 9 subtasks with over 3,000 test cases.
🥳VLM²-Bench is now part of the #CompassHub! Feel free to download and explore it—available for public use.
☺️hub.opencompass.org.cn/datas…
6
348

10 Jan 2022
My dude, when creating these compasshub quizzes, you're not supposed to use the world's most leading questions that make immediately apparent the thing the your quiz is trying to determine.

1
2

17 Feb 2015
1