
Joined April 2024
- Tweets 80
- Following 47
- Followers 273
- Likes 64
45 Photos and videos









Pinned Tweet

29 Apr 2024
OpenCompass is onboard for Twitter (@X), focusing intently on the evaluation and analysis of Large Language Models and Vision-Language Models. Welcome to star our project: github.com/open-compass/open…
2
7
1,647
3 Dec 2025
😉Introduce VideoScience-Bench, a benchmark designed to evaluate undergraduate-level scientific understanding in video models.
🥰Comprises 200 carefully curated prompts spanning 14 topics and 103 concepts in physics and chemistry.
👇
hub.opencompass.org.cn/daily…
140
26 Nov 2025
😀A new study finds that long prompts cause a fidelity–diversity trade-off in leading T2I models: more detail but reduced diversity.
😉To evaluate this issue, the authors introduce LPD-Bench and propose PromptMoG, a training-free approach that enhances diversity by sampling prompt embeddings from a Gaussian mixture.
😉Experiments on SD3.5-Large, Flux.1-Krea-Dev, CogView4, and Qwen-Image show that PromptMoG improves long-prompt diversity without causing semantic drift.
👇
hub.opencompass.org.cn/daily…
1
138
20 Nov 2025
😀SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation.
😉Two categories: Environmental Perception and Scene Understanding
😉13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others.
🥰SpatialSky-Bench is now part of the Daily Benchmark.
Explore more:
hub.opencompass.org.cn/daily…
#VLM #UAV #AI
1
132
19 Nov 2025
🥰VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization.
😊Two-stage evaluation framework:
1.Examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations.
2.Investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios.
👏VP-Bench is now part of the Daily Benchmark.
Explore more:
hub.opencompass.org.cn/daily…😊
1
118
18 Nov 2025
🥰OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era.
😍Covers 4 modalities:
18,000 bilingual (ZH/EN) text prompts
4,500 images
450 audio clips
450 videos
👏OutSafe-Bench is now part of the Daily Benchmark.
👇Explore more:
hub.opencompass.org.cn/daily…
1
2
531
17 Nov 2025
🚀 OpenCompass Daily Benchmark is live!
✅ Daily updates of the latest AI evaluation papers
✅ AI-powered smart summaries
✅ Available in English & Chinese
😍Stay ahead of AI trends, key insights, and cutting-edge research—all in one place! 🔗 hub.opencompass.org.cn/daily…
2
2
495
OpenCompass retweeted

21 Aug 2025
🔥China’s Open-source VLMs boom—Intern-S1, MiniCPM-V-4, GLM-4.5V, Step3, OVIS
🧐Join the AI Insight Talk with @huggingface, @OpenCompassX, @ModelScope2022 and @ZhihuFrontier
🚀Tech deep-dives & breakthroughs
🚀Roundtable debates
⏰Aug 21, 5 AM PDT
📺Live: youtube.com/live/kh0WSMoVZmA

1
3
20
4,452
7 Aug 2025
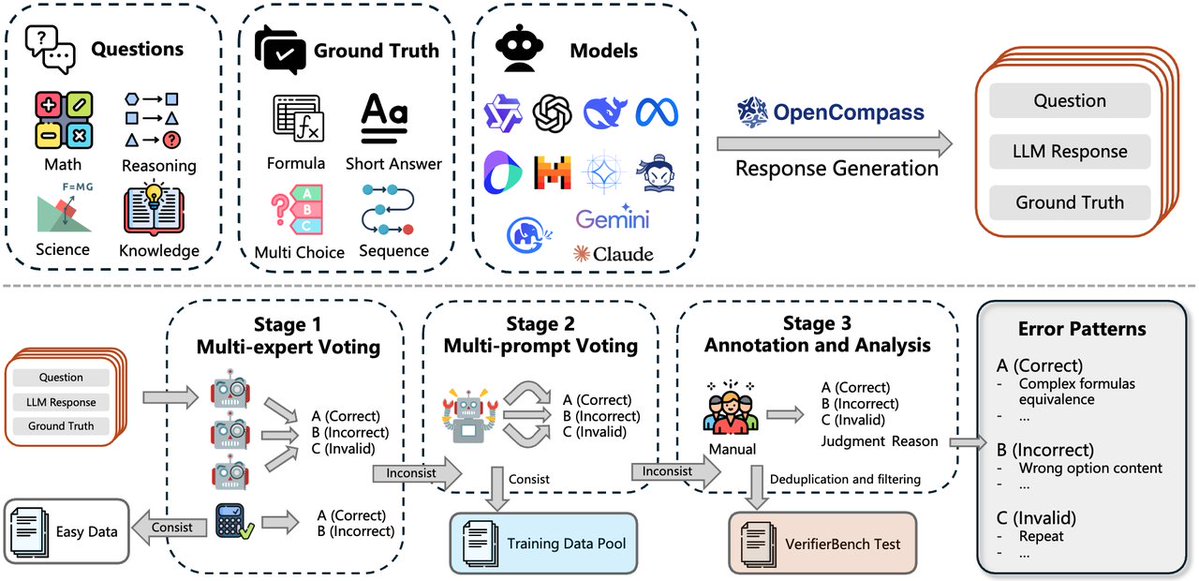
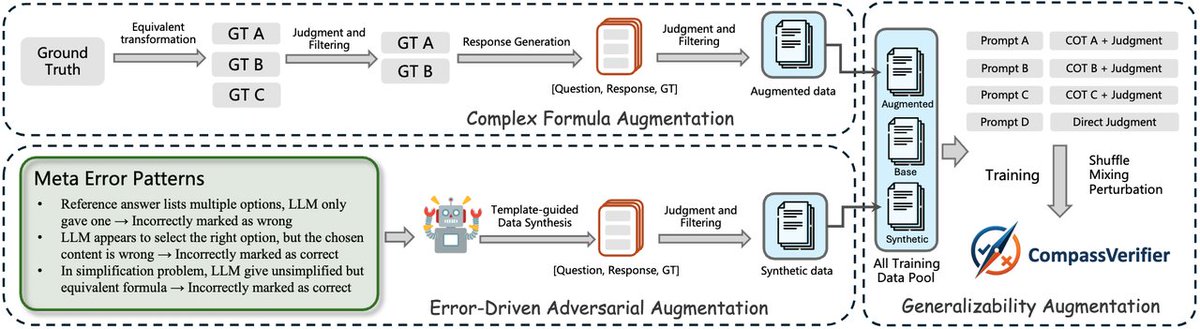
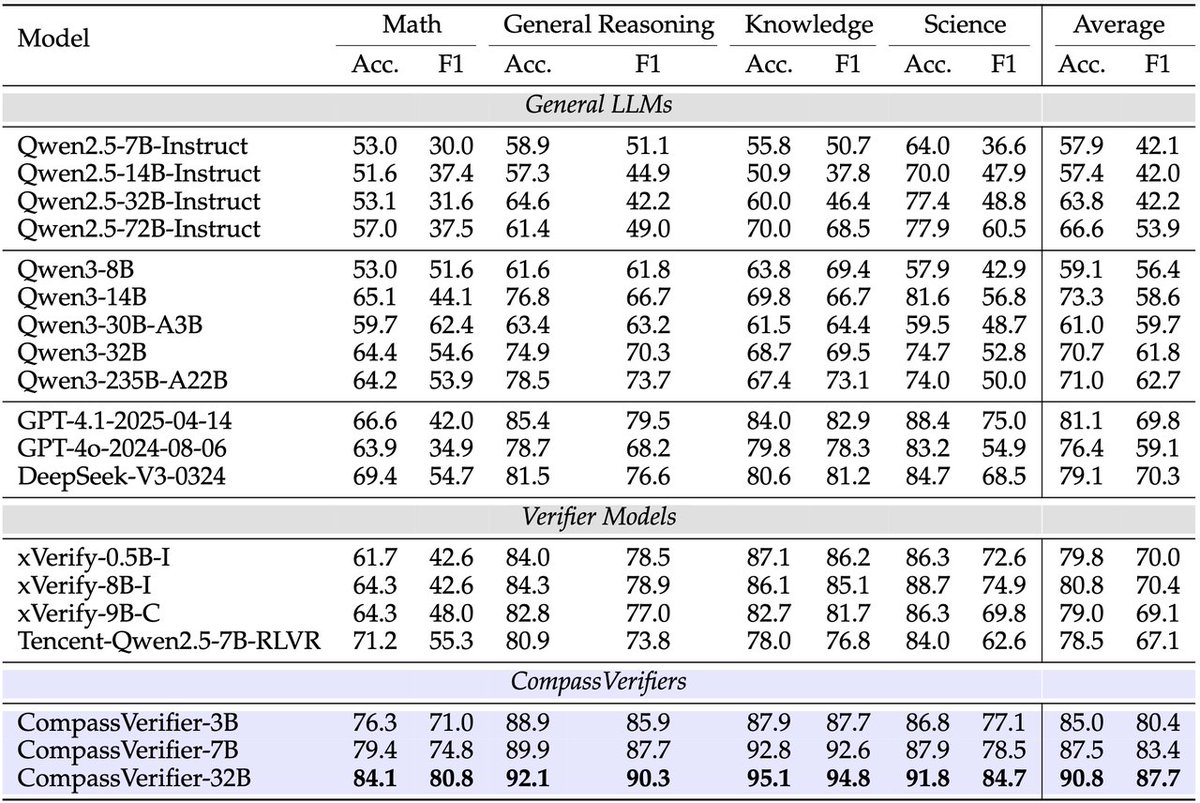
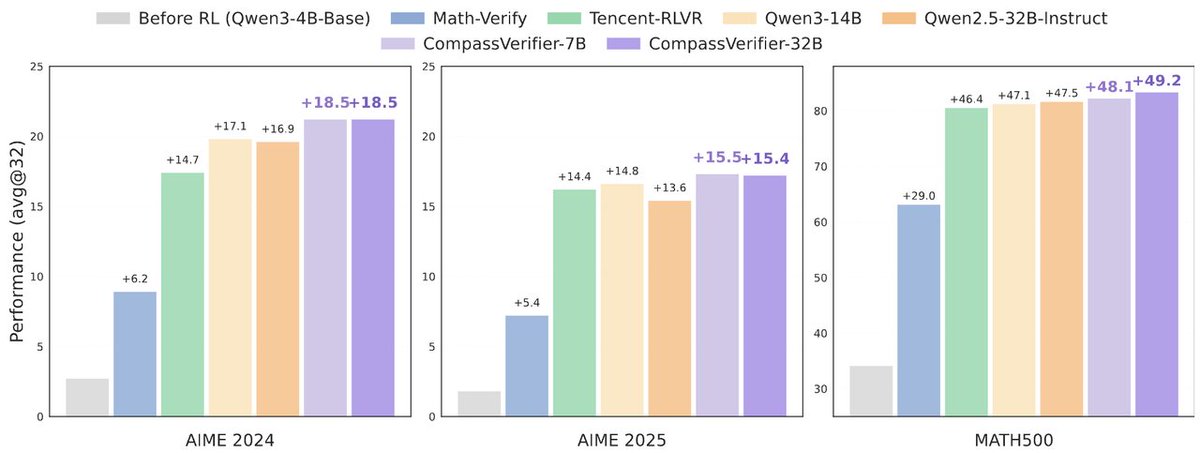
🚀 Introducing #CompassVerifier: A unified and robust answer verifier for #LLMs evaluation and #RLVR!
✨LLM progress is bottlenecked by weak evaluation, looking for an alternative to rule-based verifiers? CompassVerifier can handle multiple domains including math, science, and reasoning, as well as various answer types such as multiple-choice questions, sequences, and multiple subproblems.
🔍 Introducing #VerifierBench: A challenging dataset for evaluating the verification capabilities of different models!
🏆 Want to evaluate the verification abilities? We collected over 1 million LLMs responses using #OpenCompass framework, and selected the most challenging examples through multiple rounds of screening and manual annotation.
🏠 Main Page:
open-compass.github.io/Compa…
📄 Paper:
arxiv.org/pdf/2508.03686
💻 Code:
github.com/open-compass/Comp…
🤗 Model & Datasets:@huggingface
huggingface.co/collections/o…
1
5
952
4 Mar 2025
🥳#CodeCriticBench assesses LLMs' critiquing ability in code generation and QA tasks. Covering 10 criteria, it features a 4.3k-samples dataset with three difficulty levels and balanced distribution.
😉CodeCriticBench is now part of the #CompassHub! 😚Feel free to download and explore it.
🤗hub.opencompass.org.cn/datas…
3
306
28 Feb 2025
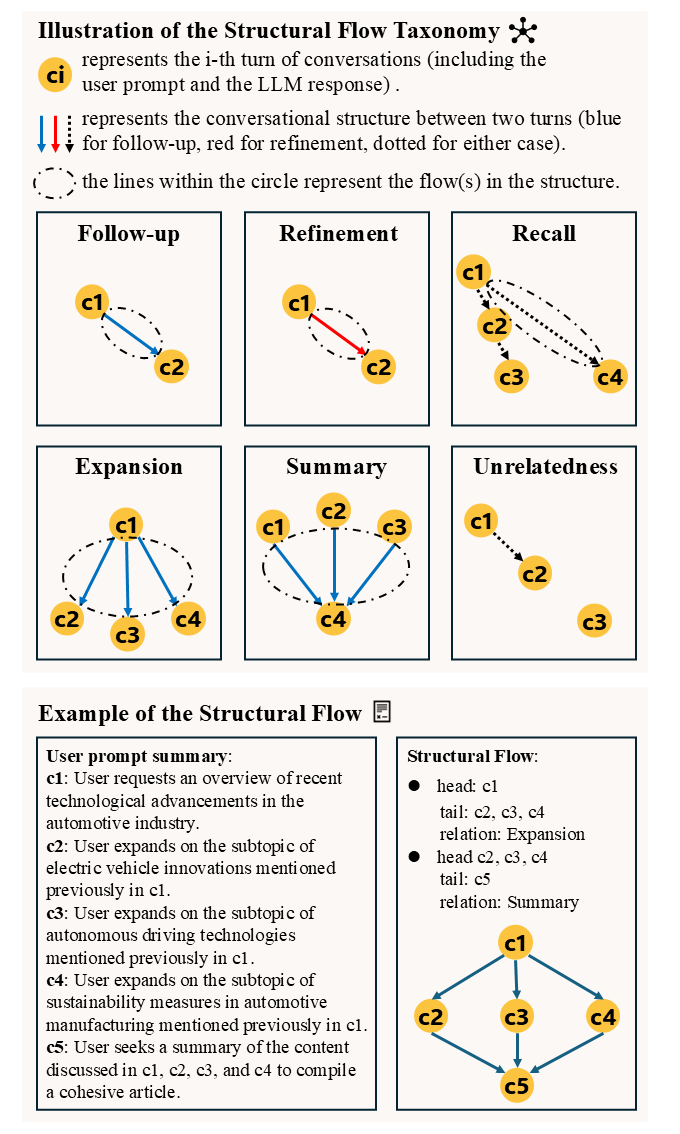
🥳#StructFlowBench is a structurally annotated multi-turn benchmark that leverages a structure-driven generation paradigm to enhance the simulation of complex dialogue scenarios.
🥳StructFlowBench is now part of the #CompassHub! 😉Feel free to download and explore it—available for public use.
🤗hub.opencompass.org.cn/datas…

1
3
794
27 Feb 2025
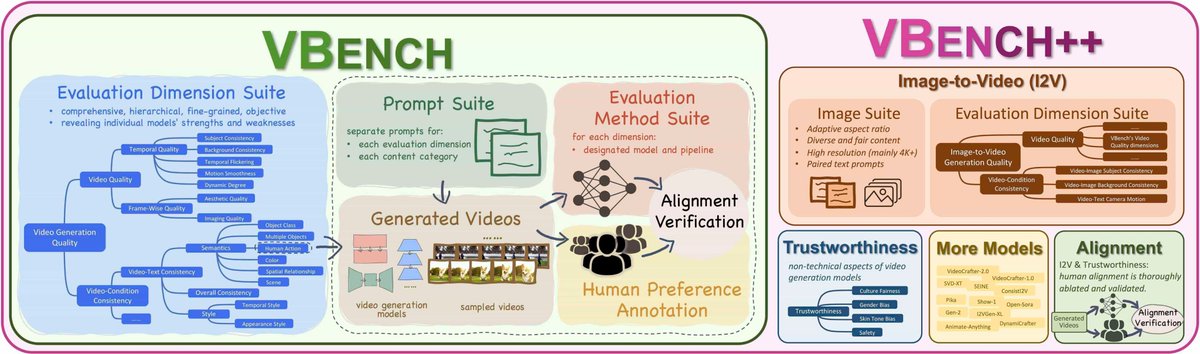
😉#VBench is a comprehensive benchmark evaluates video generation quality. It comprises 16 dimensions in video generation, and also provides a dataset of human preference annotations.
🥳VBench is now part of the #CompassHub! Feel free to download and explore it—available for public use.
🤗hub.opencompass.org.cn/datas…
2
220
26 Feb 2025
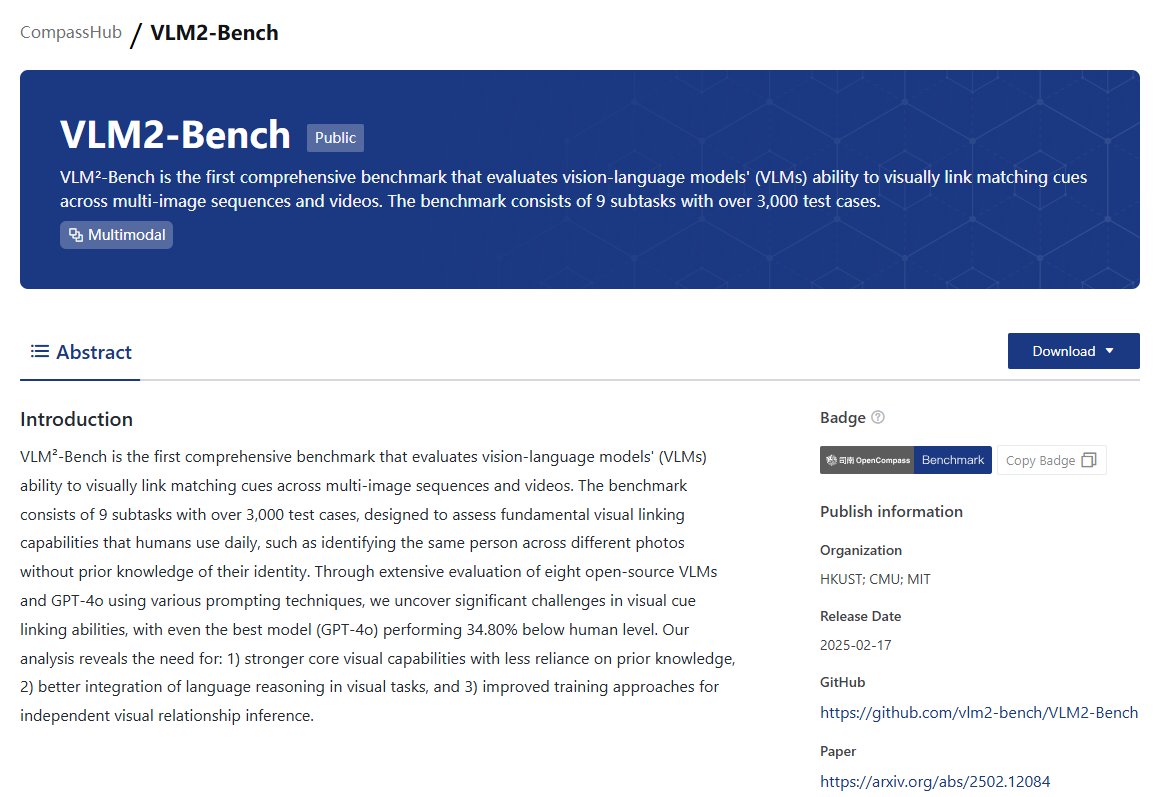
🥰VLM²-Bench is the first comprehensive benchmark that evaluates vision-language models' (#VLMs) ability to visually link matching cues across multi-image sequences and videos. The benchmark consists of 9 subtasks with over 3,000 test cases.
🥳VLM²-Bench is now part of the #CompassHub! Feel free to download and explore it—available for public use.
☺️hub.opencompass.org.cn/datas…
6
343
8 Feb 2025
We've uploaded the AIME 2025 exam, complete with questions and solutions, here: huggingface.co/datasets/open….
Feel free to test your powerful LLM on this dataset.
4
266
19 Dec 2024
🌟 Exciting News!
CompassArena now back with some major updates:
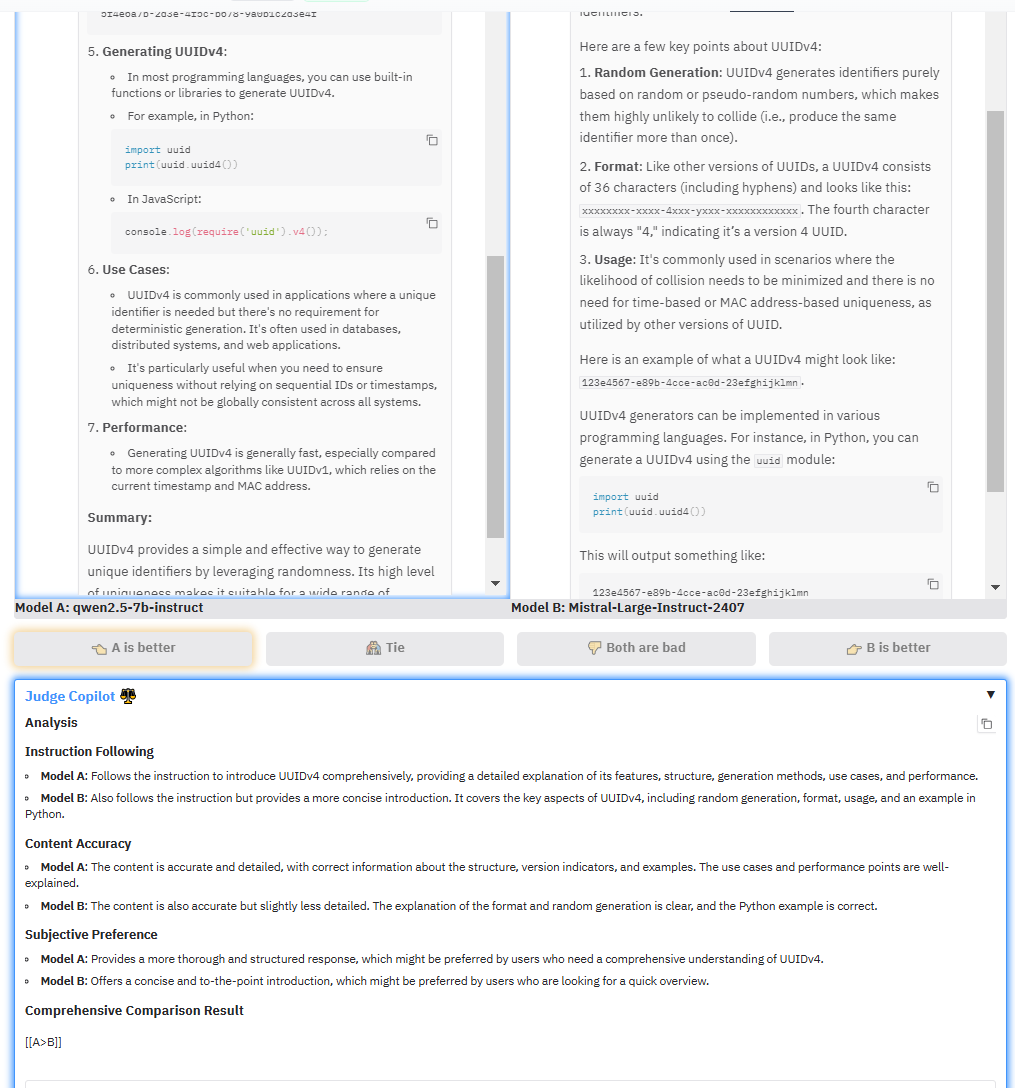
- **Judge Copilot**: An LLM-as-a-Judge tool for model comparisons. 🤖
- **Enhanced Statistical Model**: Improved Bradley-Terry accuracy by addressing confounding variables. 📊
- **20 New LLMs**: A global mix of commercial and open-source models. 🌍
Discover the latest CompassArena today! huggingface.co/spaces/openco…
2
5
207
OpenCompass retweeted

18 Dec 2024
大语言模型具备稳定推理能力吗?
「来自上海 AI 实验室 @OpenCompassX 的研究,通过创新的评估方法揭示了一个关键问题:尽管大语言模型在单次测试中可能表现出色(如 OpenAI 最新模型单次准确率达 66.5%),但在需要持续稳定输出的场景中,几乎所有模型的表现都会大幅下降(降幅普遍超过 60%),这说明当前 AI 模型的"思考能力"仍不够稳定和可靠」
论文目前在 HF Papers 当日排名居首位,关注度很高 @_akhaliq 👍
一、研究背景和问题
· 虽然大语言模型在数学推理等复杂任务上表现优秀,但基准测试成绩与实际应用效果存在差距
· 现有评估方法无法真实反映模型在实际应用中的稳定性
二、主要创新
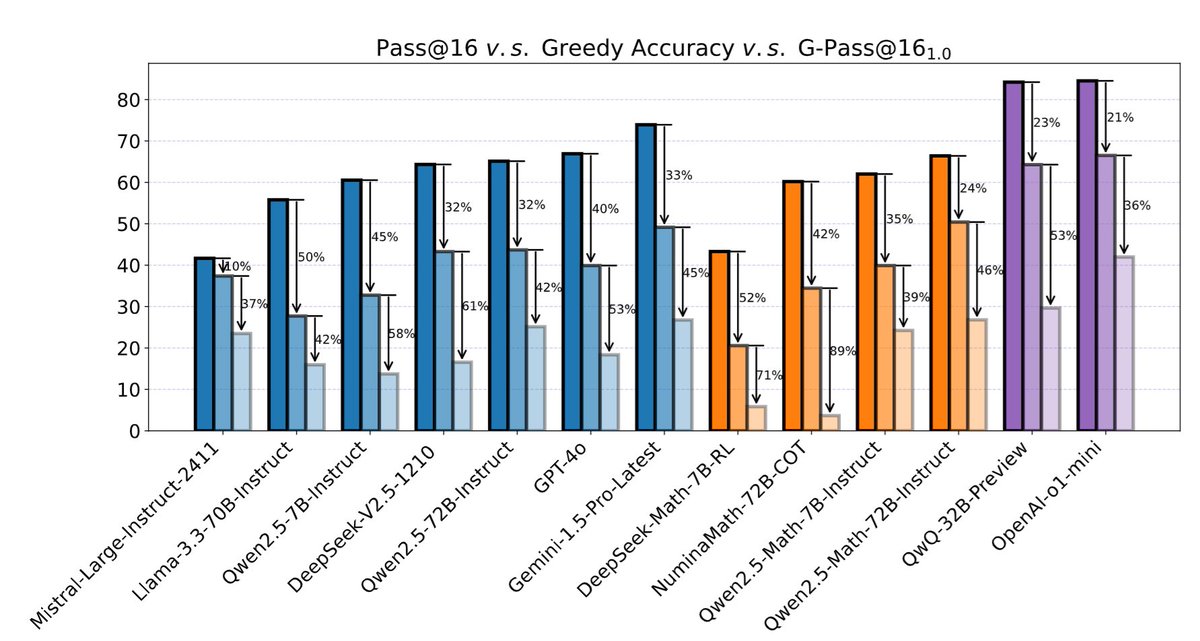
· G-Pass@k评估指标:评估模型在多次尝试中保持正确答案的能力
· LiveMathBench测试集:收集最新数学竞赛题目,确保评估的时效性和难度
三、关键评测发现
· 通用大模型表现
- Gemini-1.5-Pro表现最佳:单次测试49.2%,但在严格标准下降至26.8%
- GPT-4和Claude-3.5表现相近:单次成绩约40%,严格测试均降至20%以下
· 数学专用模型表现
- Qwen2.5-Math-72B潜力最高:单次可达50.4%,但稳定性测试降至26.8%
- 其他专用模型表现不佳:DeepSeek-Math和NuminaMath在严格测试中均低于6%
· o1系列模型亮点
- OpenAI o1-mini最为稳定:单次66.5%,严格测试仍保持42.0%
- QwQ-32B紧随其后:严格测试保持33.3%的水平
展现出更好的推理稳定性
四、核心启示
· 稳定性挑战
- 几乎所有模型在严格测试下表现显著下降
- 平均性能衰减超过60%
- 即使是专门优化的数学模型也难以保持稳定表现
· 规模效应局限
- 增加模型参数量并不能显著提升推理稳定性
- 如72B和32B版本的Qwen模型表现相近
· 未来方向
- 需要更注重模型的稳定性而非单次表现
- o1系列的架构创新可能提供了提升稳定性的新思路
- 评估方法需要更贴近实际应用场景

1
2
10
1,269
18 Dec 2024
Welcome to submit your LMM into our new leaderboard.
18 Dec 2024

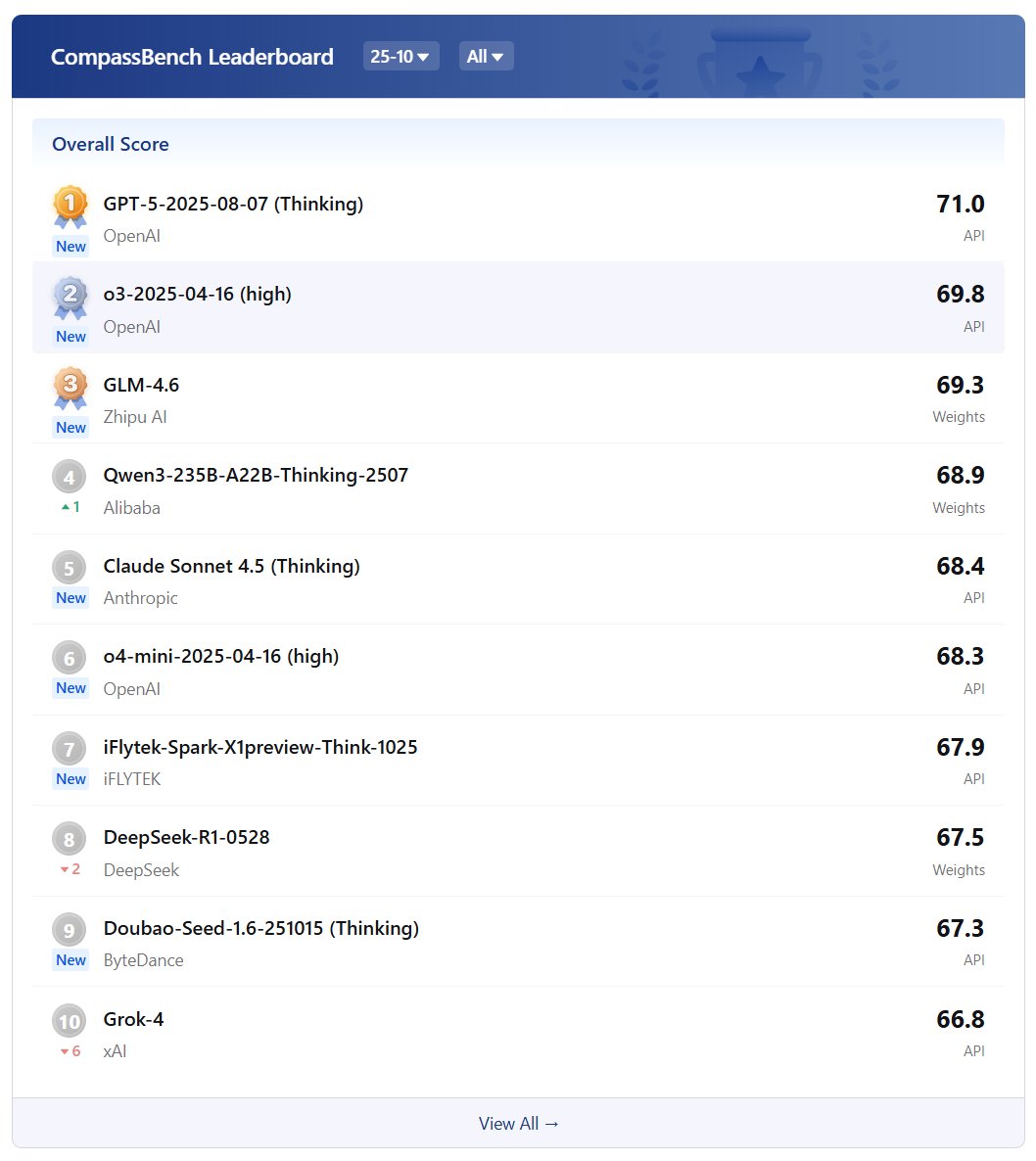
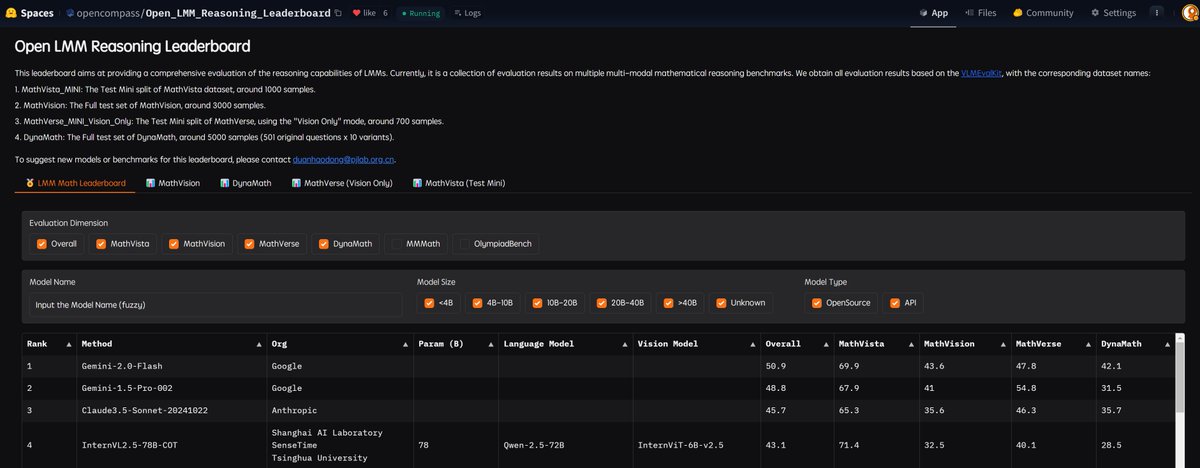
OpenCompass has established a leaderboard to evaluate complex reasoning capability of LMMs, consisting of four advanced multi-modal math reasoning benchmarks. Currently, Gemini-2.0-Flash took the 1st place. DM me to suggest more benchmarks and models to this LB.
1
254
OpenCompass retweeted

18 Dec 2024
OpenCompass has established a leaderboard to evaluate complex reasoning capability of LMMs, consisting of four advanced multi-modal math reasoning benchmarks. Currently, Gemini-2.0-Flash took the 1st place. DM me to suggest more benchmarks and models to this LB.
2
8
1,666
18 Dec 2024
🚀 Shocking : O1-mini scores just 15.6% on AIME under strict, real-world metrics. 🚨
📈 Introducing G-Pass@k: A metric that reveals LLMs' performance consistency across trials.
🌐 LiveMathBench: Challenging LLMs with contemporary math problems, minimizing data leaks.
🔍 Our research shows LLMs have significant room for improvement in practical reasoning tasks.
🔗 Dive deeper:
- Arxiv: arxiv.org/abs/2412.13147
- HF: huggingface.co/papers/2412.1…

3
13
66
11,928
OpenCompass retweeted

22 Oct 2024
MMBench has been selected as one of the most influential papers at ECCV 2024, ranking second.🎉🎉🎉
paperdigest.org/2024/09/most…

1
1
237