
Jan 11
One of the most exciting moments last year with @oceanprotocol was seeing privacy preserving data actually being used for real AI workflows through ComputetoData proving that data can generate value without ever being exposed
Three Ocean products team really did a good job is 👇🏻

1
2
140

10 Nov 2025
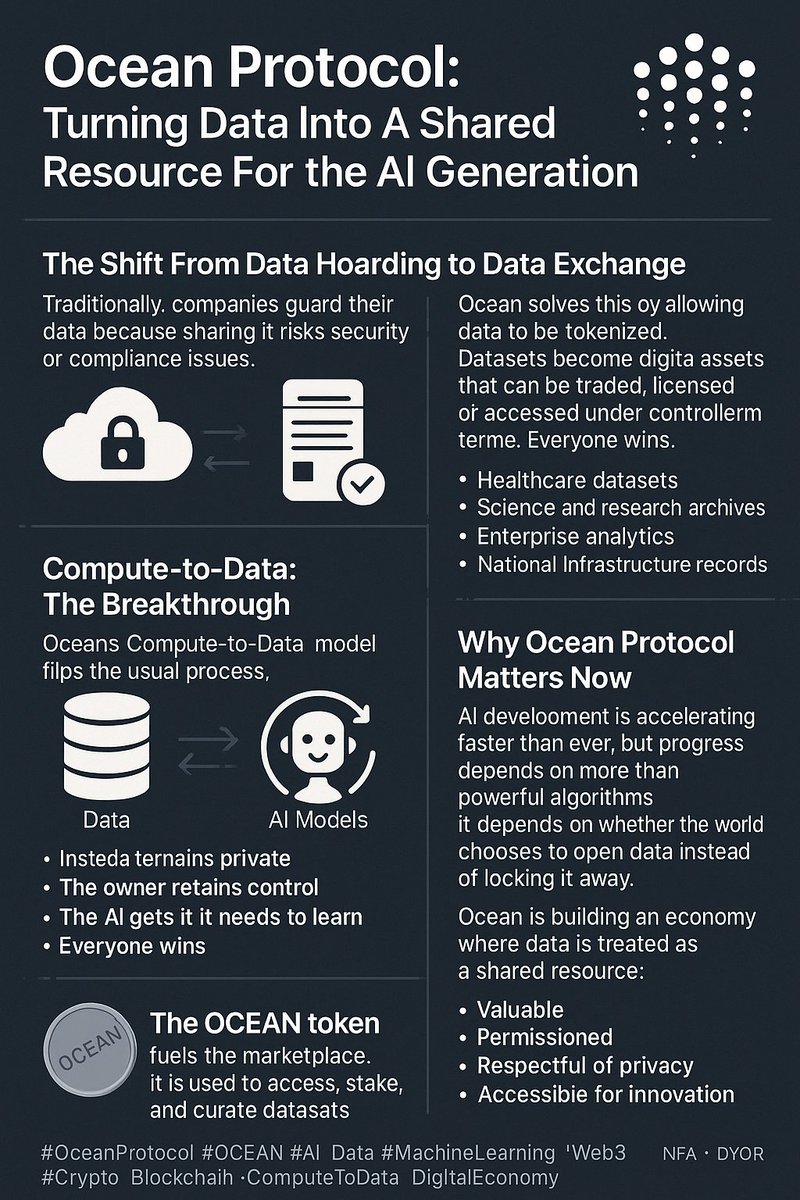
Ocean Protocol: Turning Data Into A Shared Resource For The AI Generation
Everyone is talking about AI right now.
Smarter models. Bigger training sets. More powerful automation.
But behind every AI breakthrough, there is one essential ingredient that most people overlook:
Data.
Without access to high-quality data, AI cannot learn, adapt, or improve.
Yet most of the world’s data sits locked away: held by corporations, behind private firewalls, or simply unused.
Ocean Protocol (OCEAN) is working to open that world up.
It provides a way for data owners to share and monetize their datasets securely, while giving developers and AI systems access to the information they need to grow.
This is not just about blockchain.
It is about building a global data marketplace.
The Shift From Data Hoarding to Data Exchange
Traditionally, companies guard their data because sharing it risks security or compliance issues.
Ocean solves this by allowing data to be tokenized.
Datasets become digital assets that can be traded, licensed, or accessed under controlled terms.
You do not expose your data.
You simply allow it to be used.
Think of data as a library book:
You can read it, learn from it, build with it, but you do not have to take it home.
This is how industries unlock value without losing control.
Compute-to-Data: The Breakthrough
Ocean’s Compute-to-Data model flips the usual process.
Instead of sending data out to AI models, the computation happens where the data is stored.
Only the result leaves the secure environment.
The data remains private.
The owner retains control.
The AI gets what it needs to learn.
Everyone wins.
This matters especially for:
• Healthcare datasets
• Science and research archives
• Enterprise analytics
• National infrastructure records
The world needs privacy and innovation at the same time.
Ocean provides the bridge.
The Role of OCEAN
The OCEAN token fuels the marketplace.
It is used to access, stake, and curate datasets.
It rewards those who contribute useful data to the network and signal which datasets are high quality.
If data is the new oil, OCEAN is the currency that moves it.
Why Ocean Protocol Matters Now
AI development is accelerating faster than ever, but progress depends on more than powerful algorithms.
It depends on whether the world chooses to open data instead of locking it away.
Ocean is building an economy where data is treated as a shared resource:
• Valuable
• Permissioned
• Respectful of privacy
• Accessible for innovation
This is how the next generation of AI is trained.
Not behind closed doors, but in the open, where the benefits can reach everyone.
NFA DYOR
#OceanProtocol #OCEAN #AI #Data #MachineLearning #Web3 #Crypto #Blockchain #ComputeToData #DigitalEconomy #InnovationInAction
60
46
239

9 Oct 2025
Quick spotlight: @oceanprotocol
Their core idea is simple but powerful: unlocking data for AI while preserving privacy and control.
I've been exploring Ocean protocol lately and these are the three things that really stand out for me:
▫️Ocean Node — the backbone of the Ocean ecosystem, enabling decentralized compute and data access.
▫️Compute-to-Data — send algorithms to the data (never the other way round) so you can train or analyze private datasets without exposing them.
▫️Ocean VS Code Extension — brings data publishing, compute jobs, and Ocean integration right into your coding workspace. Super handy for fast prototyping.
If you care about privacy-first AI, data sovereignty, or building dApps that actually scale then give oceanprotocol.com a closer look. Lots of practical tools, not just buzz. 🌐🔎
$Ocean #ComputeToData #Web3 #AIDeveloper

2
6
378

8 Oct 2025
Most systems move data to the computer risking privacy, speed, and cost.
At StreamdataX, we flip the model:
➡️ Bring compute to the data
🔐 Keep data secure
⚡ Unlock real-time AI predictions
The future of AI runs where the data lives powered by $SDXT Blockchain.
#StreamdataX #SDXT #AI #Blockchain #BigData #ComputeToData #Web3 #Innovation

14
3
33
632
29 Sep 2025
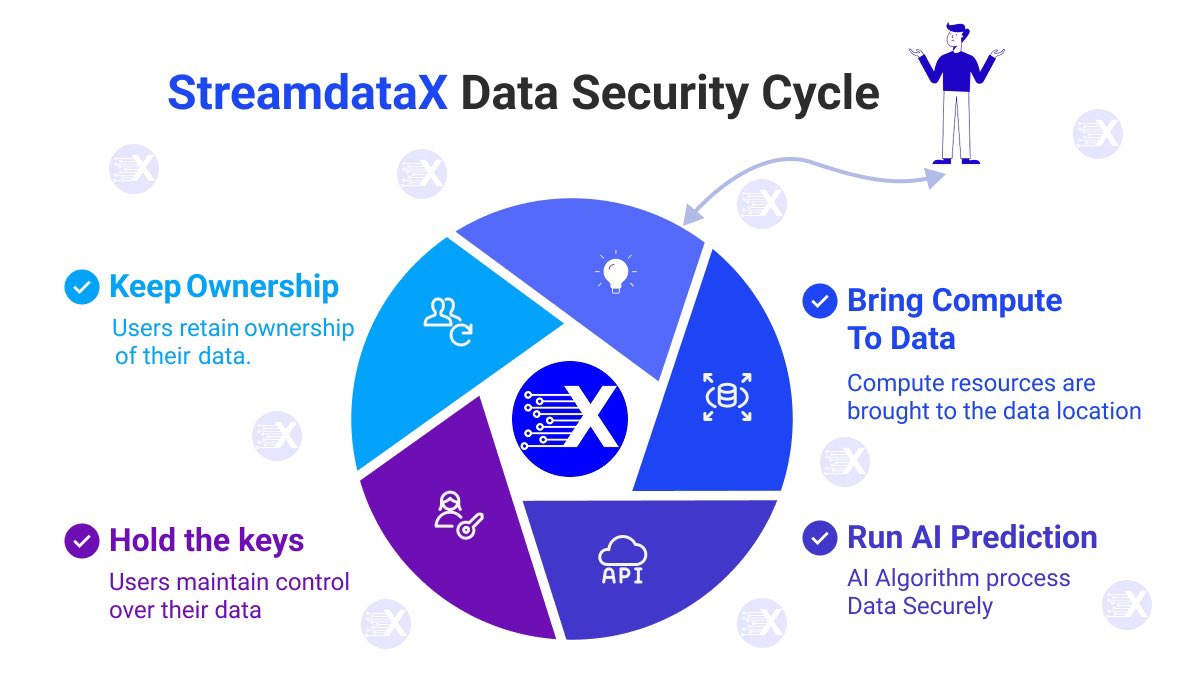
Why StreamDataX is Building Compute to Data for AI,
Today, most of the world’s data is locked in centralized silos whether it’s agriculture, health, finance, or research. A few corporations control access, slowing down innovation and making AI progress biased and limited.
Data holders fear losing control.
AI developers can’t access diverse, quality datasets.
Communities and individuals are left out.
That’s where StreamDataX comes in.
With our compute-to-data model:
-Data stays where it is, safe and private.
-Algorithms move to the data, not the other way around.
-Owners keep full control and earn rewards for use of their data.
-AI developers get results they need without ever touching raw data.
This is how we unlock decentralized, fair, and privacy preserving AI.
Because AI for the future shouldn’t belong to just the few it should be powered by all of us, for all of us. 🌐✨
#StreamDataX #ComputeToData #DecentralizedAI #Web3 #AIForGood
7
1
22
531
10 Aug 2025
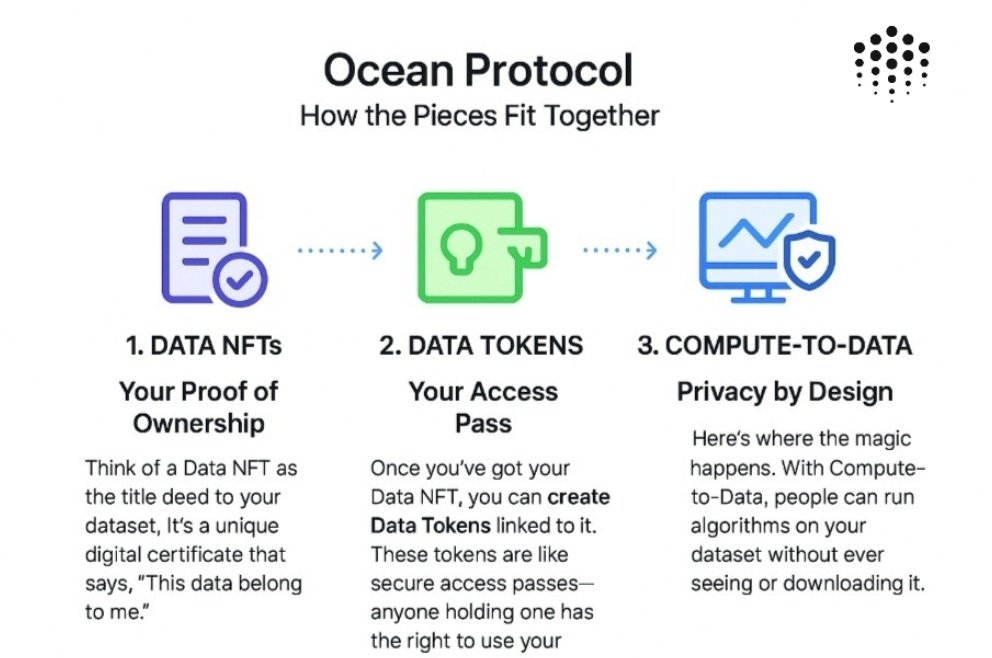
Ocean Protocol makes it possible to share and monetize data without giving up control or privacy It does this using three methods 👇🏻
Data NFTs for ownership 👀
Think of a Data NFT as the title deed to your dataset. It’s a unique digital certificate that says, “This data belongs to me.”
• You decide who can use it.
• You control how it’s shared or sold
Data Tokens for access rights👀
Once you’ve got your Data NFT, you can create Data Tokens linked to it. These tokens are like secure access passes anyone holding one has the right to use your dataset or service.
• Easy to trade or distribute.
• Lets you control access without sharing the actual file directly.
Compute to data for privacy preserving 👀
Here’s where the magic happens. With ComputetoData, people can run algorithms on your dataset without ever seeing or downloading it.
• Your data stays safe where it is.
• They get the results, not the raw data.
Connecting all these will get you 👇🏻
• You mint a Data NFT to prove ownership.
• You issue Data Tokens so others can access it.
• When they use those tokens, ComputetoData ensures they can work with your data securely.
Result
You keep control, protect privacy, and still earn value from your data. Others get the insights they need without risking leaks or misuse.
1
11
551
25 Jul 2025
How to use @oceanprotocol CLI to tokenize data, deploy algorithms, and run decentralized compute—all from your terminal.
Here’s a step-by-step guide 👇
1️⃣ What is Ocean CLI?
Ocean CLI is a command-line tool built on top of Ocean.js. It lets you do powerful things like mint Data NFTs, tokenize algorithms, and launch Compute-to-Data (C2D) jobs without needing to write smart contracts or touch low-level infrastructure.
▫️ What do you need to get started?
Before using Ocean CLI, make sure you have:
– Node.js installed
– A terminal (macOS/Linux or WSL on Windows)
– A wallet private key
– An Ocean Node URL (you can use the public one or host your own)
2️⃣ Installing Ocean CLI
To use Ocean CLI, clone the GitHub repository and install the dependencies using npm. Once installed, you’ll be able to run commands like “publish” and “startCompute” right from your terminal.
▫️ Set your environment variables
You’ll need to set your wallet’s private key and the Ocean Node URL as environment variables. This ensures the CLI knows where to send transactions and which node to interact with.
3️⃣ Exploring the CLI
You can run help commands to explore what’s possible. The CLI supports both positional arguments and named flags, so you can choose the style that works best for you.
▫️ Publishing a dataset
Want to turn your dataset into a tokenized asset? Just run the “publish” command with your dataset’s metadata file. This creates a Data NFT and an ERC-20 datatoken in one go.
4️⃣ Publishing an algorithm
You can also tokenize code (like a Python script or Jupyter notebook) as an algorithm asset. This allows others to run your code through Ocean’s Compute-to-Data system without ever downloading it.
▫️ Finding compute environments
Need to know which nodes can run your jobs? Use the CLI to list all available compute environments. You’ll get info like environment IDs, payment token options, and resource limits.
5️⃣ Launching a paid Compute-to-Data job
Once you have a dataset and algorithm published, you can launch a compute job by providing both DIDs. The job runs in a secure environment, and only the result is returned.
▫️ Running free compute jobs
If you're just testing, you can skip the dataset and run your algorithm in a free public environment. This is a great way to validate your code before doing real jobs.
6️⃣ Watching job logs
Want to see what’s happening during the job? The CLI allows you to stream logs in real time so you can debug and monitor progress.
▫️ Checking status and downloading results
Once the job finishes, you can check its status. If it's marked "COMPLETED", you can download the output files directly to your machine.
7️⃣ Editing your asset
Need to update your dataset’s metadata? Use the “editAsset” command to change the title, description, price, or files—without redeploying anything.
▫️ Automating everything
Set the AVOID_LOOP_RUN variable to true and use the CLI in CI/CD pipelines or scheduled scripts. This makes it easy to publish assets or trigger jobs automatically.
🔹You’re done.
With Ocean CLI, you can tokenize data and algorithms, launch jobs, and earn from your compute—all without writing a single smart contract. It’s privacy-preserving, decentralized, and super dev-friendly.
🔗 Want to try it? Start here: docs.oceanprotocol.com/devel…
#Ocean #Web3 #AI #DataEconomy #CLI #DePIN #ComputeToData 🌊💻
2
5
260

18 Jul 2025
Hi everyone👋 Today I want to talk about what impresses me about @oceanprotocol technologies.
Ocean Protocol is not just a platform, but a revolutionary approach to data and compute management in Web3. I am most impressed with Compute-to-Data (C2D). This technology allows you to process data without revealing it, which solves a key privacy issue. Imagine: you can monetize your data or CPU by providing computation to AI, without losing control of the information!
What's especially cool is that C2D supports complex computation, from analyzing Python scripts to processing biological data like DNA. This opens the door for decentralized AI agents that work securely and autonomously.
Plus, plans for GPU support in C2D V2 promise even more power for tasks like training large models. Ocean Protocol is building a future where data and computing become accessible, private, and profitable. This is a real step towards decentralization!
Read more:
docs.oceanprotocol.com/devel…
If you don't like to read much but want to learn more, I recommend the podcast -x.com/autonolas/status/19360…
What impresses you about Ocean Protocol? Share in the comments!
#OceanProtocol #Web3 #ComputeToData #AI #Decentralization

20 Jun 2025

What makes an AI agent truly autonomous?
On Episode 10 of the Agents Unleashed podcast, @ThomasMaybrier speaks with @TrentMc0 co-founder of @oceanprotocol and the Artificial Superintelligence Alliance to explore what sovereignty means for AI, and why blockchain is essential for true autonomy.
In this episode:
- What makes an AI agentic
- The evolution of Ocean Protocol
- “Bitcoin as a life form” and the future of AI coordination
- The coming wave of AGI, ASI and brain-computer interfaces
Watch here on X, or lnk.bio/agentsunleashedpod for all other platforms.
01:33 Trent’s background
06:13 Birth of Ocean Protocol
11:27 AI’s real-world impact
17:22 What is a sovereign agent?
26:13 Blockchain x agent autonomy
36:27 Brain-computer interfaces
47:41 Sovereignty in the age of AGI
52:40 Closing thoughts
10
1
33
4,220
13 Jul 2025
Hi everyone 👋 Today I want to talk about how to monetize your CPU with Ocean Protocol: step-by-step guide GPU plans...
Want to make money from your computer's unused processing power? @oceanprotocol provides a unique opportunity to monetize your CPU (and in the future GPUs) through running a node on their decentralized network. In this post, we'll break down how to set up an Ocean Node and start earning, as well as talk about the prospect of using GPUs.
~~~~~~~~~~~~~~~~~~~
What is Ocean Protocol ?
Ocean Protocol is a decentralized platform for sharing data and computing resources. It allows you to monetize data and computing power while maintaining privacy. By running an Ocean Node, you provide computing resources for Compute-to-Data (C2D) tasks and are rewarded in OCEAN tokens.
~~~~~~~~~~~~~~~~~~~
Why run a node ?
🟢CPU monetization: Use the idle power of your CPU to perform computations and earn revenue.
🟢Privacy: C2D allows you to process data without exposing it, ideal for handling sensitive information.
🟢Future with GPU: Ocean Protocol is working on GPU support, which will open up new opportunities to monetize more powerful hardware.
~~~~~~~~~~~~~~~~~~~
Step-by-step guide to starting Ocean Node:
1. Preparing the equipment
2. Installing dependencies
3. setting up the environment
4. Setting environment variables
5. Starting the node
6. Checking the status
7. Monetization
For more information see here 👉
docs.oceanprotocol.com/devel…
~~~~~~~~~~~~~~~~~~~
GPU perspectives
Ocean Protocol is actively developing GPU support for Compute-to-Data V2 (C2D V2). This will enable:
🟢Handle more complex tasks such as training large language models or video generation.
🟢Increase revenue due to the high computational power of GPUs.
🟢Support various compute engines (Docker, Kubernetes, etc.).
C2D V2 is under development and details of the architecture are available in the Ocean Node repository. GPU support will make nodes even more in demand, especially for AI-related tasks.
~~~~~~~~~~~~~~~~~~~
Why start now?
Starting an Ocean Node is not only a way to make money on your CPU, but also an opportunity to become part of the decentralized data and AI ecosystem. With the development of C2D V2 and GPU support, your node will become even more profitable. Get started today and prepare for the future of Web3!
Join Ocean Protocol 🌊and monetize your computing today!
#OceanProtocol #Web3 #ComputeToData #Monetization #AI

8
1
49
3,541
15 Jun 2025
Unlocking Private Data for AI: How @oceanprotocol Empowers Open-Source LLMs with Privacy-Preserving Compute 🤖🔐🌊
Open-source Large Language Models (LLMs) are reshaping the future of AI—democratizing access to powerful tools once held by a few. But if we want these models to truly compete, evolve, and serve a wider audience, they need something critical: data and not just any data, but diverse, high-quality, and often sensitive data.
This is where @oceanprotocol comes in.
🔍 The Problem: Data Access Without Privacy Trade-offs
Training or fine-tuning an LLM typically requires access to massive datasets—medical records, legal documents, academic journals, financial data, and more. But these are often locked away because they’re private, regulated, or sensitive.
The result?
→ Models are often trained on limited, biased, or publicly available data.
→ Smaller developers can’t compete.
→ Users get AI that lacks nuance, accuracy, and fairness.
🌊 The Solution: Ocean Protocol Compute-to-Data
Ocean Protocol offers a privacy-preserving solution through a core feature called Compute-to-Data (C2D).
Here’s how it works:
The data never leaves its secure location.
The LLM algorithm is sent to the data, runs inside a secure enclave, and returns only the results (like model weights or output summaries).
No raw data is ever exposed—solving the trust and compliance problem without losing access to powerful training material.
It’s like letting your AI model read a book without ever letting it take a copy home.
🧠 For Developers: Better LLMs, Legally & Ethically
As a developer, this means you can:
✅ Fine-tune your open-source LLM on high-value datasets without compromising user privacy
✅ Access previously untapped domains—legal, medical, research, corporate
✅ Build competitive, domain-specific AI products without the regulatory risk
✅ Contribute to a more fair and decentralized AI landscape
🌍 For Users: More Accurate, Less Biased Models
When LLMs are trained on broader, more representative data, everyone benefits:
✅ Fewer hallucinations and blind spots
✅ Models that understand local context, diverse languages, and underrepresented domains
✅ AI that’s actually useful for people outside Silicon Valley
Ocean Protocol’s approach ensures that better data = better AI—without compromising your data rights.
🚀 The Future of Decentralized AI Is Being Built Now
This isn’t speculation. It’s already being built.
Ocean Protocol’s integration with open LLMs makes it possible to train cutting-edge models on private data—securely, ethically, and transparently.
Developers, researchers, and organizations now have the tools to unlock data’s full potential for AI, while respecting privacy and ownership.
Want to get started or explore more?
🔗 Dive into Compute-to-Data here: docs.oceanprotocol.com/devel…
#OceanProtocol #ComputeToData #AI #OpenSourceAI #LLM #DataPrivacy #Web3AI #DecentralizedAI

1
8
293

14 Jun 2025
In a world increasingly driven by data, not all information is created equal. Some datasets—like health records or personal details—carry with them the weight of privacy, sensitivity, and trust. These are not commodities to be traded recklessly but treasures to be guarded carefully. Yet, the value hidden within these private datasets is immense, promising breakthroughs in medicine, technology, and beyond. How then can one unlock this potential without sacrificing confidentiality? 🤔
Enter Compute-to-Data — a subtle revolution in data sharing. Instead of handing over raw data, this approach offers controlled access to computation on that data. Imagine a scenario: a researcher wants to know the average age of patients within a health database, but without exposing a single identity. Compute-to-Data makes this possible by allowing algorithms to run on the data, while the data itself never leaves its secure home. This is not just innovation; it’s a philosophy of respect—balancing utility with privacy.
This model dissolves the old tradeoff between the benefits of data and the risks of exposure. Data remains under the owner’s control, safe and private, yet it can still generate meaningful insights for trusted third parties. Whether it’s statistical analysis, AI training, or scientific discovery, Compute-to-Data is the bridge that connects potential with protection.
Private data is among the most valuable assets today. Its scarcity and sensitivity make access challenging, yet when harnessed correctly, it drives powerful, transformative outcomes. Compute-to-Data empowers organizations and individuals to monetize these assets without compromise, opening new horizons for research and business, all while keeping privacy sacred. 🔒✨
In essence, this approach invites us to rethink data ownership—not as a zero-sum game of giving or withholding, but as a cooperative dance where value is shared responsibly, safely, and innovatively. The future belongs to those who can unlock the true power of private data, transforming it from a guarded secret into a source of collective advancement.
@oceanprotocol
#ComputeToData #DataPrivacy
docs.oceanprotocol.com/devel…

2
3
20
2,642
13 Jun 2025
Hello, Web3 and AI community 🫂
Imagine being able to harness the power of open-source large language models (LLMs), such as LLaMA or other open-source counterparts, to handle private data - and still keep it secure. That's exactly what Ocean Protocol's integration with open-source LLMs does!
---------------------------
How it works ?
With Ocean Protocol's Compute-to-Data (C2D) feature, you can perform computations directly on private data without revealing its contents.
This means you can train or pre-train LLMs on sensitive datasets - such as medical records or financial analytics - without risk of information leakage.
The algorithms run inside a secure environment, returning only results, not the data itself.
---------------------------
What does this give users?
🎯Better and less biased AI models: With access to a variety of private data, LLMs become more accurate and relevant, making them useful to more people.
🌐Broader access: High-quality AI models will become available not only to large corporations, but also to communities, startups, and individual users.
---------------------------
What does it give developers?
📊Access to diverse data: You can use unique, private datasets to create competitive LLMs, opening new horizons for innovation.
🛠️Flexibility and control: With C2D, you control the learning process, choose what data to work with, and monetize your models through the Ocean ecosystem.
---------------------------
Why it matters ?
Ocean Protocol's integration with open-source LLM breaks down the barriers between privacy and innovation. While others face limitations due to strict privacy rules, Ocean enables the secure use of data to create powerful AI solutions.
It's a step towards a future where technology works for everyone!
---------------------------
Want to learn more?
Dive into the details of Compute-to-Data and start experimenting: docs.oceanprotocol.com/devel….
Join the AI revolution with Ocean Protocol 🌊!
Stay tuned to @oceanprotocol and let's build a private but open data world together!
#OceanProtocol #ComputeToData #OpenSourceLLM #AIPrivacy #Web3
8
2
39
3,207
12 Jun 2025
Ocean Compute Jobs: The Processing Power Behind Privacy-First Web3 Apps 🧠⚙️🌍
Web3 is maturing fast and many next-gen dApps need to do more than store or move tokens. They need to process data, train models, and run advanced analytics. But how do you do that without sacrificing user privacy or decentralizing only half the stack?
That’s where @oceanprotocol Compute Jobs come in.
🔐 Privacy-Preserving by Design
At the core is Ocean’s Compute-to-Data framework. Instead of sending data across the internet to some third-party server, the compute goes to the data.
→ Data stays locked in its secure environment
→ Your algorithm or job is sent to the data
→ Only results (never raw data) come back
This flips the traditional cloud model—giving dApps the ability to run powerful AI or data workloads without ever exposing sensitive info.
⚙️ Run Anything from AI to Analytics
Ocean Compute Jobs can handle a wide range of tasks:
▫️ Training ML models
▫️ Running simulations
▫️ Processing private healthcare or financial records
▫️ Generating custom insights from token or DAO activity
Whether it’s an AI model or an analytics engine for a decentralized research platform, you can plug in Ocean compute with minimal overhead.
🌐 Backed by Ocean Nodes
Behind the scenes, these jobs are powered by a growing network of Ocean Nodes—containerized, decentralized infrastructure that runs the Ocean stack (including Compute-to-Data).
▫️ Developers don’t need to manage infrastructure
▫️ Trusted GPU providers like NetMind add scale
▫️ The system is modular, decentralized, and production-ready
🛠️ Why It’s a Game-Changer for Builders
✅ Launch apps that handle sensitive data without violating privacy laws
✅ Monetize data & compute usage through on-chain payments
✅ Focus on your core product—not spinning up servers or worrying about leaks
✅ Build AI and data products in a way that’s transparent, fair, and sovereign
Ocean Compute Jobs make Web3 not just decentralized in storage or access, but also in intelligence and execution.
It’s a powerful engine for any project working at the intersection of AI, data, and privacy.
→ Learn more: oceanprotocol.com/learn/comp…
#OceanProtocol #ComputeToData #DeAI #DataPrivacy #Web3Builders #DecentralizedAI #PrivacyTech #AIinWeb3

4
268
11 Jun 2025
Somewhere, in a quiet data center or on a scientist’s encrypted server, the most valuable data in the world sits untouched. Not because it isn’t needed — but because it's too private to share.
And that’s the paradox of our time: the best insights, the biggest breakthroughs, the boldest innovations — all of them are waiting behind closed doors, locked inside private data. 🔐
But now, something is changing.
Compute-to-Data is not just a technical solution. It’s a new way of thinking — a bridge between caution and curiosity, between protection and progress. It says: you don’t need to give everything away to give something useful.
Instead of handing over the data, data owners simply give permission for specific tasks to run. No one sees the raw files. No one takes what’s not theirs. But the world still gets the insights — whether it's for building smarter AI models or driving medical discoveries. 🧠✨
This isn't about data for data’s sake. It's about creating space for trust — where companies can earn from their assets, and researchers can finally explore what was once off-limits.
When privacy and progress walk hand in hand, we all win.
@oceanprotocol
#ComputeToData #PrivacyFirst #AIethics
oceanprotocol.com/learn/comp…

1
10
2,401
10 Jun 2025
Decentralized AI isn’t a theory it’s already happening.
While the world debates the future, @oceanprotocol is delivering real infrastructure that makes AI more open, private, and decentralized. Here’s how:
🔐 Privacy-Preserving Compute
Most AI development requires centralized data access, which leads to privacy concerns and data leaks. Ocean flips the model with Compute-to-Data:
→ Instead of moving the data, Ocean moves the algorithm to where the data lives.
→ Training and inference happen in secure, sandboxed environments.
→ The raw data is never exposed only the results leave.
This is perfect for industries like healthcare, finance, and research where privacy is critical.
🔗 Tokenized Data Access
Ocean turns data into programmable assets using:
→ Data NFTs (ERC-721): representing ownership and licensing rights of a dataset or model.
→ Datatokens (ERC-20): allowing users to buy/sell timed access to data.
This gives creators a way to monetize data directly while keeping full control over its usage and terms.
🌐 Global Network of Nodes
AI needs serious compute. Ocean provides it through a decentralized mesh of Ocean Nodes, powered by:
→ Community-run infrastructure
→ Trusted GPU providers (like @NetMindAI)
→ Modular architecture that integrates privacy, metadata, access, and compute into one stack
Developers can tap into this network to run training jobs without spinning up their own infra.
Bottom Line:
The future of AI is not closed, centralized, and extractive.
It’s open, private, and fair — and Ocean Protocol is already building it.
Others are still speculating. Ocean is shipping.
Learn more 👉 oceanprotocol.com
#OceanProtocol #DecentralizedAI #DataPrivacy #Web3 #ComputeToData #AI

29 May 2025

Everyone’s talking about decentralised AI
Very few are actually building it
Ocean Protocol isn’t chasing hype. It’s building the rails
- Privacy-preserving compute
- Tokenized data access
- Global network of nodes
1
7
254
29 May 2025
He watched the world chase data, yet few understood its true weight.
Private data holds the deepest insights — not because it’s hidden, but because it’s human. It reflects lives, patterns, truths. But sharing it has always meant sacrifice: privacy, control, trust.
Now, that balance is shifting.
With Compute-to-Data, data no longer needs to leave its safe space. Instead of being exposed, it’s respected — algorithms come to it, not the other way around.
This means scientists can unlock breakthroughs, businesses can build smarter, and data owners stay in control.
In this new paradigm, privacy isn't lost — it's protected.
And value? It's finally shared, not stolen.
It’s more than a solution. It’s a rethinking of how we collaborate in the age of intelligence.
🔐📊🌍
#DataReimagined #ComputeToData
@oceanprotocol
oceanprotocol.com/learn/comp…

1
18
2,149

If you’re working on AI, DeSci, or decentralized data apps, this tool is for you.
Try it now and explore the full breakdown in the blog:
blog.oceanprotocol.com/free-…
#OceanProtocol #AI #Web3 #VSCode #ComputeToData
1
2
39

15 Nov 2024
Presenting the Ocean C2D (Compute-to-Data) Architecture! Without transferring the data, securely do calculations on sensitive datasets. Scalable, private, and decentralized. @oceanprotocol #OceanProtocol #ComputeToData

1
2
37

29 Jun 2024
🌊 Monetize Your Data with Privacy: Harness the power of Ocean Protocol's Compute-to-Data to monetize sensitive datasets like health records securely.
Keep your data private while enabling valuable insights. Explore now!
#DataPrivacy #ComputeToData #OceanProtocol
1
2
27
29 Jun 2024
Monetize Your Data with Privacy: C2D by @oceanprotocol 🧵
Securely unlock the value of sensitive datasets like health records without sharing raw data. Control access, maintain #privacy, and empower data #monetization.
➡️ docs.oceanprotocol.com/devel…
#DataPrivacy #ComputeToData

1
1
2
89