
Jun 1
🚨TenArmor Security Alert🚨
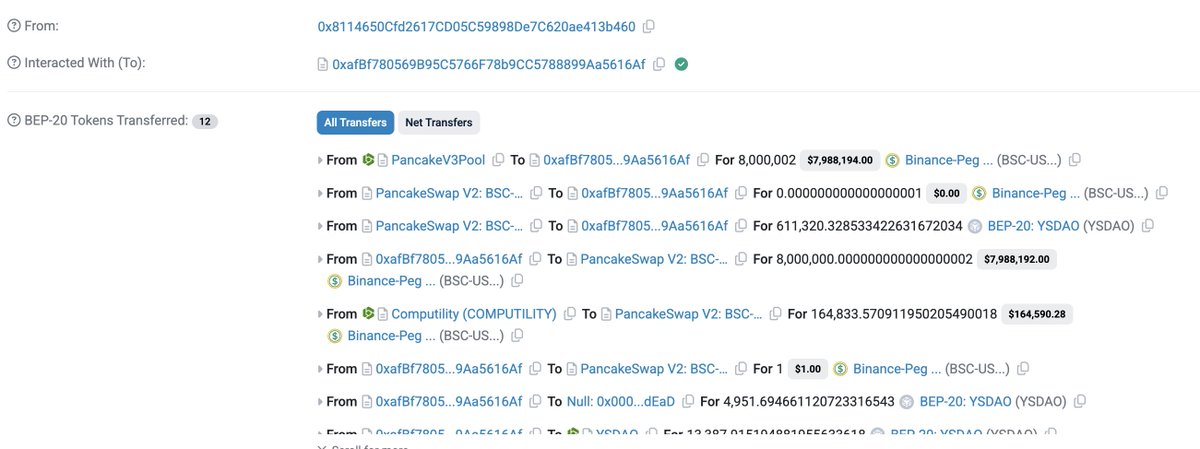
Our system has detected a suspicious attack involving #Computility #YSDAO on #BSC, resulting in an approximately loss of $19.5K.
Attack transaction: bscscan.com/tx/0x91f26d96373…
With TenArmor’s TenMonitor, you get early detection and automated response to on-chain attacks.
Need protection? Reach out anytime!
#TenArmorAlert #TenArmor
1
1
4,571

🌍 New Issue Out Now: IEEE Energy Sustainability Magazine
The latest issue of IEEE Energy Sustainability Magazine explores the critical intersection of AI, computing, and sustainable power systems.
📖 Read the FREE open article: bit.ly/3OSsKNa
...
As AI-driven energy demand accelerates, aligning computing, electricity, and carbon strategy is no longer optional — it’s essential.
⚡ Inside this issue:
• Computility–Electricity–Carbon Coordination
• AI & Power System Synergies
• Learning-Augmented Control for Sustainable Data Centers
🔗 Access the full issue: bit.ly/3WpS6me
If you're working across energy, AI, grid modernization, or climate tech — this issue is worth your attention.
#IEEEPES #EnergySustainability #AI #PowerSystems #Decarbonization #ClimateTech

5
10
340

Apr 20
What AI ultimately demands is not just computility—it’s electricity.
Daily token consumption of large language models has skyrocketed by 1,400 times in just two years. As computing power surges ahead, the power grid bears the strain. China’s answer? Electricity-computing synergy.
311
201,475
🌍 New Issue Out Now: IEEE Energy Sustainability Magazine
The latest issue of IEEE Energy Sustainability Magazine explores the powerful intersection of AI, computing, and sustainable power systems.
🔗 Read here: bit.ly/3WpS6me
⚡ Highlights:
• Computility–Electricity–Carbon Coordination
• AI & Power System Synergies
• Learning-Augmented Control for Sustainable Data Centers
As AI-driven demand surges, aligning computing, electricity, and carbon strategy is mission-critical.
If you're in energy, AI, grid modernization, or climate tech - this one’s worth a read.
#ieeepes #EnergySustainability #AI #PowerSystems #Decarbonization #ClimateTech

1
10
361

Apr 7
🚨 Exploit Alert: TGAI / Computility on BSC
A reserve-manipulation attack has been detected involving the TGAI liquidity pool on BSC.
What happened:
• The attacker used a ~2.4M USDT flash loan
• Deployed 25 CREATE2 helper contracts to buy TGAI tokens
• Manipulated the LP reserves using the sync() function, injecting ~17.5K USDT into the pair
• Then executed swapTGToUSDT, extracting profits
💰 Estimated profit: ~$11.94K
🔍 Transaction details:
bscscan.com/tx/0x6031c73c264…
Stay vigilant — reserve manipulation remains a persistent threat across DeFi protocols.
#DeFiSecurity #ExploitAlert #Web3Security ⚠️ #Audit

3
10
9,574

🚨 Exploit Alert: TGAI/Computility reserve-manipulation on #BSC
Attacker flash loaned ~2.4M USDT, deployed 25 CREATE2 helpers to buy TGAI, then abused `sync()` to push ~17.5K USDT into the LP pair before calling `swapTGToUSDT` — netting ~$11.94K profit.
🔍 bscscan.com/tx/0x6031c73c264…
#DeFiSecurity #ExploitAlert #Web3Security
3
18
2,642

Apr 3
Nobody will.
We’re seeing a big surge in AI spending, but a mismatch here, about 80% of the money is invested into computility or something, while only 20% goes to actually reconstructing business. That’s why we haven't seen a universal AI prosperity yet.
3
26
🌍 New Issue Out Now: IEEE Energy Sustainability Magazine
The latest issue of IEEE Energy Sustainability Magazine explores the critical intersection of AI, computing, and sustainable power systems.
📖 Read the FREE open article: bit.ly/3OSsKNa
...
As AI-driven energy demand accelerates, aligning computing, electricity, and carbon strategy is no longer optional — it’s essential.
⚡ Inside this issue:
• Computility–Electricity–Carbon Coordination
• AI & Power System Synergies
• Learning-Augmented Control for Sustainable Data Centers
🔗 Access the full issue: bit.ly/3WpS6me
If you're working across energy, AI, grid modernization, or climate tech — this issue is worth your attention.
#IEEEPES #EnergySustainability #AI #PowerSystems #Decarbonization #ClimateTech

1
4
258
🌍 New Issue Out Now: IEEE Energy Sustainability Magazine
The latest issue of IEEE Energy Sustainability Magazine explores the powerful intersection of AI, computing, and sustainable power systems.
🔗 Read here: bit.ly/3WpS6me
⚡ Highlights:
• Computility–Electricity–Carbon Coordination
• AI & Power System Synergies
• Learning-Augmented Control for Sustainable Data Centers
As AI-driven demand surges, aligning computing, electricity, and carbon strategy is mission-critical.
If you're in energy, AI, grid modernization, or climate tech - this one’s worth a read.
#ieeepes #EnergySustainability #AI #PowerSystems #Decarbonization #ClimateTech

1
2
5
245

Jan 2
Your old phone = AI Era "Miner" 📱
No need for a $30,000 H100 GPU. Aiverse's lightweight protocol fragments idle computility into usable power.
Open your browser, run silently, and watch your AICOIN balance jump with AiHash computing power.
#AIAssets #IdleCompute #CryptoRevolution #AiverseTech #AiVerse #Crypto #AiHash #AiVerseWeb3

6
384

12 Aug 2025
Syukur Alhamdulillah, saya berpeluang mengiringi YAB Dato’ Sri Haji Fadillah bin Haji Yusof, Timbalan Perdana Menteri merangkap Menteri Peralihan Tenaga dan Transformasi Air Malaysia, dalam lawatan kerja ke Johor.
Lawatan dimulakan di Loji Rawatan Kumbahan Awam di Taman Pelangi Indah, diikuti tinjauan ke tapak cadangan Water Reclamation Plant (WRP) di Desa Cemerlang, Ulu Tiram. Kedua-dua fasiliti ini penting dalam memperkukuh pengurusan air lestari di negeri Johor.
Loji Rawatan Kumbahan Awam di Taman Pelangi Indah berperanan memproses air kumbahan sebelum dihantar untuk rawatan lanjut. Efluen terawat ini digunakan sebagai asas penghasilan air tebus guna untuk pelbagai keperluan industri. Pendekatan ini bukan sahaja mengurangkan kebergantungan terhadap air mentah, tetapi juga membantu memastikan sumber air bersih untuk rakyat terus terjamin.
Tapak WRP Desa Cemerlang pula menjadi projek pertama seumpamanya di Johor, menggunakan teknologi Membrane Bioreactor (MBR) dan Reverse Osmosis (RO) untuk menukar air buangan kepada air alternatif berkualiti tinggi bagi penyejukan pusat data. Inovasi ini membuktikan bahawa teknologi moden dan kelestarian alam sekitar boleh bergerak seiring, tanpa menjejaskan bekalan air untuk kegunaan harian rakyat.
Seterusnya, kami menghadiri Majlis Pengiktirafan Penggunaan Air Alternatif bagi Industri Pusat Data Negeri Johor, satu langkah penting dalam menyokong penggunaan sumber air secara lestari, sekali gus memastikan pembangunan pesat industri pusat data di negeri ini kekal berdaya saing, mampan dan berterusan.
Menerusi majlis tersebut, kerjasama strategik telah dimeterai antara Indah Water Konsortium, Johor Special Water (JSW), Bridge Data Centres (BDC), Computility (ZDATA) dan Dayone Data Centres, merangkumi pembekalan air terawat dan air mentah untuk diproses semula sebagai air guna semula. Usaha ini mampu meningkatkan nilai pelaburan, mengukuhkan ekosistem digital Johor, dan mewujudkan lebih banyak peluang pekerjaan berkemahiran tinggi.
Kerajaan Negeri kekal komited memacu kelestarian air melalui inovasi berimpak tinggi selari dengan Agenda Maju Johor 2030. Semoga Johor akan terus maju sebagai hab digital dan teknologi serantau yang lestari dan berdaya saing. Insya-Allah.
Allah Peliharakan Sultan
Allah Berkati Johor
#BangsaJohor #MajuJohor #JohorBersih #JohorSelamat #XtifJohor




1
5
20
1,557

11 Aug 2025
Johor Bahru | 11 Ogos 2025 | Isnin
Kementerian Peralihan Tenaga dan Transformasi Air (PETRA) dengan kerjasama Kerajaan Negeri Johor hari ini melakar sejarah apabila melaksanakan inisiatif air dipulih guna khusus bagi sektor pusat data.
Melalui program ini, Indah Water Konsortium (IWK) Sdn Bhd agensi di bawah PETRA akan membekalkan sehingga 12 juta liter sehari air kumbahan terawat kepada loji air pulih guna yang menyokong operasi dua pusat data utama di Johor.
Usaha ini mencerminkan komitmen bersama Kerajaan Persekutuan dan Negeri dalam memastikan kestabilan bekalan air, di samping menggalakkan amalan industri teknologi yang lebih mampan dan berdaya tahan.
PETRA melalui agensinya, syarikat pembetungan nasional Indah Water Konsortium (IWK) Sdn Bhd dan Kerajaan Negeri melalui Johor Special Water (JSW) iaitu anak syarikat kepada Permodalan Darul Ta’zim (PDT) akan bekerjasama membekalkan sumber air kumbahan terawat melalui sistem pengagihan bersepadu kepada Loji Air Pulih Guna di Bridge Data Centres (BDC) dan Computility Technology (Malaysia).
Di samping itu, JSW juga membekalkan sumber air alternatif lain kepada Dayone Data Centre Malaysia II Sdn Bhd (Dayone). Dalam konteks ini, Indah Water Konsortium Sdn. Bhd. (IWK) akan membekalkan sehingga 12 juta liter sehari air kumbahan terawat daripada proses rawatan air kumbahan kepada Loji-Loji Air Pulih Guna yang dibina Bridge Data Centres (BDC) dan Computility Technology (Malaysia). Sementara itu, syarikat Dayone pula akan menggunakan sumber air alternatif yang lain.
Sebanyak 3 pusat data di Johor hari ini telah mendapat pengiktirafan daripada Kerajaan dalam penggunaan air alternatif bagi kegunaan pusat data masing-masing. Tahniah YAB Menteri Besar Johor, Dato’ Onn Hafiz bin Ghazi dan Kerajaan Negeri Johor atas usaha mempercepatkan pelaburan pusat data serta penggunaan sumber air alternatif bagi industri.
Ia adalah langkah strategik dalam menjamin kelestrian sumber air negara. Negeri Johor mempunyai potensi besar sebagai hab pusat data serantau dengan sokongan infrastruktur dan dasar pelaburan yang kondusif.
RMK13 menggariskan transformasi sektor air sebagai salah satu teras utama pembangunan negara. PETRA komited memacu pelaksanaan NRW, penggunaan semula air (recycle) dan inovasi teknologi.
Kerjasama erat antara Kerajaan Persekutuan, Negeri dan Industri amat penting dalam memastikan kejayaan agenda transformasi ini.
Usahasama Indah IWK dan JSW menjadi contoh terbaik pengurusan air alternatif. Sepanjang 6.5km paip bawah tanah telah dibina dari Loji IWK Taman Pelangi Indah ke BDC menunjukkan pelaksanaan teknikal yang berjaya.
Penggunaan air alternatif penting bagi industri pusat data yang memerlukan banyak air, terutama untuk sistem penyejukan. Komitmen syarikat pusat data hari ini selari dengan prinsip ESG mengurangkan jejak karbon dan menggalakkan amalan industri bertanggungjawab.
Saya menyeru lebih banyak syarikat bekerjasama dengan IWK dan SPAN bagi meneroka penyelesaian lestari dan tahan iklim. Kerajaan akan terus menyokong melalui peraturan jelas, insentif dan kerjasama strategik, demi menjadikan Malaysia sebagai hab data serantau yang mampan.
Semoga negeri-negeri lain mencontohi Johor dalam memanfaatkan air dan tenaga alternatif demi kelangsungan sumber serta kesejahteraan rakyat.
#TPMFY
#PETRA
#MalaysiaMADANI
#MADANIbekerja




4
7
550

11 Aug 2025
#NSTnation Deputy Prime Minister Datuk Seri Fadillah Yusof said the initiative, driven by Indah Water Konsortium Sdn Bhd (IWK) in partnership with Johor Special Water (JSW), will supply up to 12 million litres a day of treated effluent to two data centres, namely Bridge Data Centres (BDC) and Computility Technology Malaysia.
nst.com.my/news/nation/2025/…
603

after the AI application war, people will notice the importance of decentralized computility, MCP service, and incentives for data and API providers.
17 Mar 2025

AI needs decentralization and verifiability.
In a recent tweet, the founder of Curve Finance, @newmichwill, said that the main purpose of crypto is DeFi and that AI doesn’t need crypto at all. While I agree that DeFi is an important sector in crypto, I don’t agree that AI doesn’t need crypto.
As AI agents are booming right now, where there’s usually a token attached to each agent, people have a false perception that the intersection of crypto and AI is effectively AI agents. The other topic people seem to miss is decentralized AI itself, which is related to training AI models themselves.
The thing that I don’t like about narratives is that the majority of users blindly assume that something is important and useful enough while it’s popular, or even worse, assume that the only goal of the narrative is to extract as much value as possible and that’s it (make some money).
One of the first questions in decentralized AI that we should ask ourselves is why it needs to be decentralized and what consequences we face because of that.
It turns out that the idea of decentralization almost every time inevitably leads to the idea of incentive alignment.
There are multiple fundamental problems in AI that can be fixed with crypto, moreover, there are some mechanisms that add more trust to AI, and not only fix existing problems.
So, why does AI need crypto?
1. Expensive computations reduce participation and innovation.
Fortunately or not, big AI models require a lot of computational resources, which naturally limits many potential users from participating. Most of the time, AI models need a lot of data resources as well as actual compute that is basically too much to handle for a single individual.
This problem is particularly seen in open-source development where contributors, besides investing their time to train the model, must also invest computational resources, which doesn’t lead to effective open-source development.
The thing is that, yes, an individual can allocate a lot of resources to run an AI model, just as a user can allocate these computational resources to running their own node on their own blockchain.
However, this doesn’t fix the problem as a whole, where computational power is simply not enough to perform relevant tasks.
Independent developers or researchers cannot participate in contributing to big AI models like LLaMA, simply because they cannot afford the compute required to train the model: there are thousands of GPUs, data centers, and additional infrastructure needed.
To provide a sense of scale:
→ Elon Musk stated that the latest Grok 3 model was trained using 100k Nvidia H100 GPUs.
→ Each chip is valued at approximately $30,000.
→ The total cost of the AI chips used to train Grok 3 is around $3 billion.
This problem is actually similar to startup building in some sense, where individuals have time, technical ability, and an execution plan, but not enough resources at first to build their vision.
As noted by @dbarabander, while a conventional open-source software project only requires contributors to donate their time, an open-source AI project demands both time and substantial resources, such as computational power and data.
Depending solely on goodwill and volunteer efforts is insufficient to encourage enough individuals or groups to supply these costly resources. Additional incentives are necessary to drive participation.
2. Crypto is the best tool for incentive alignment.
Incentive alignment is when rules are in place to encourage participants to act in ways that help the system, even if they also benefit themselves.
There are countless examples of when crypto helped different systems with incentive alignment, but I’d say the most notable one is the DePIN industry, where it was a perfect fit.
Projects such as @helium and @rendernetwork are great examples where incentive alignment was achieved with a distributed network of nodes and GPUs acting as network participants.
Why can’t we take this model as an example and use it in the AI field to make the ecosystem more open and accessible?
Well, it turns out we can.
What drives web3 and crypto in general is ownership.
You own your data, you own your incentives, and even if you hold some tokens, you still own a piece of a network. Granting ownership serves as motivation for resource providers to offer their assets to the project, with the prospect of gaining benefits from the network's success.
To make AI more accessible, crypto is the best solution that could be possible. Developers could freely share model designs among themselves and projects, as compute and data providers would supply resources for ownership stakes (incentives).
3. Incentive alignment correlates with verifiability.
If we envision a decentralized AI system with proper incentive alignment, it should inherit the same features as classic blockchain mechanisms:
1. Network effects.
2. Lower initial requirements with nodes earning on future earnings.
3. Slashing mechanisms to penalize actors that act maliciously.
For slashing in particular, we need verifiability, otherwise, if it’s not verifiable who acted maliciously, then we cannot penalize the intended actor, and it will be really easy to cheat the system, especially when working cross-collaboratively.
In a decentralized AI system, verifiability is needed because we don’t have a centralized point of trust. Instead, we aim for a trustless yet verifiable system. There are multiple components that might need verifiability:
• Benchmark phase (the system is better than another system based on x, y, z)
• Inference phase (the system is running correctly, essentially the “thinking” phase of AI)
• Training phase (the system is trained correctly or adjusted correctly)
• Data phase (the system is collecting the data)
There are 100s of different teams that build something on @eigencloud, but what I noticed recently is the shift into AI more than it was before, and I was wondering if it aligned with the original vision of restaking.
Any AI system that wants to have incentive alignment has to be verified.
In that case, slashing equals verifiability: if a decentralized system can slash malicious actors, then it’s capable of identifying and verifying that a malicious action was made.
If the system is verifiable, then AI can use crypto to tap into global compute and data to craft even bigger and better models, because more resources (compute data) lead to better models (at least in the current world).
@hyperbolic_labs is already showing what’s possible with collaborative computing resources, where any user can rent GPUs and use them for training much heavier AI models than they would be able to do at home, at a much cheaper cost.
→ How to make AI validation efficient and verifiable?
Someone might say that there are a lot of cloud solutions available to rent GPUs, so it fixes the compute problem.
Unfortunately, cloud solutions like AWS or Google Cloud are pretty centralized and create what is known as a waitlist strategy, where they create fictional high demand and raise costs due to the field being an oligopoly.
There are a lot of GPUs in data centers, mining farms, or just with other individuals sitting idle that could potentially contribute to the compute for AI model training, but they’re just sitting idle.
You might have used @getgrass_io, which sells your unused bandwidth to corporations, so you don’t waste your bandwidth for no reason and get some rewards in return.
I’m not saying that there is an unlimited amount of compute, but the thing is, any system can be optimized, creating a win-win scenario for someone who needs more resources for AI model training in a more open market and someone who can get rewards for contributing these resources.
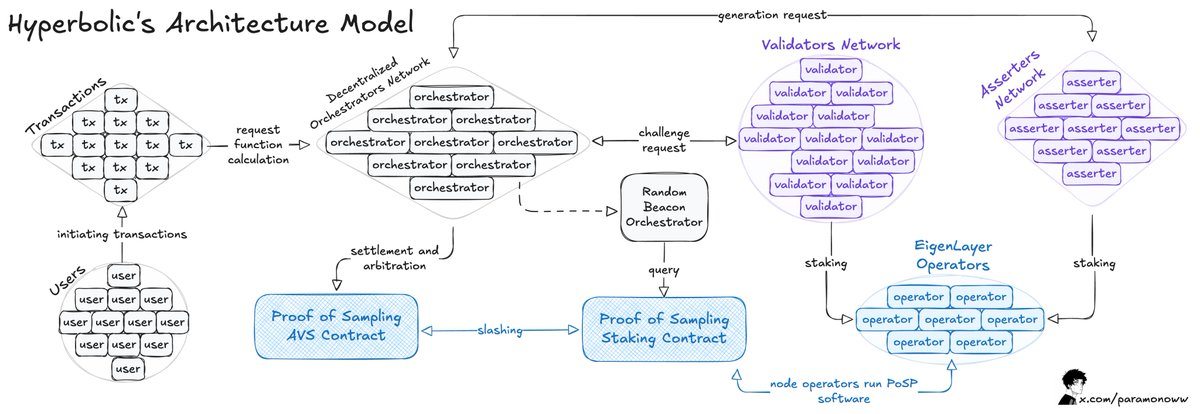
The team from Hyperbolic created an open GPU marketplace, where users who need compute for AI model training can rent a GPU and save up to 75%, while renters can monetize their idle resources.
Here is an overview of how it works:
Hyperbolic organizes connected GPUs into clusters and nodes to allow compute to scale based on demand.
The main part of this architecture model is the Proof of Sampling model, where transactions are sampled together: they’re randomly selected and verified to reduce the workload and computational demand.
The main problem lies in the AI inference process, where every inference run on the network needs to be verified, preferably without the significant computational overhead of other mechanisms.
As I said before, if something can be verified, it has to be slashed if the verified action is against the rules.
When Hyperbolic adapted the AVS model, it allowed them to add more verifiability to the system, where validators are selected randomly to verify outputs and make the system incentive-aligned, where dishonesty is unprofitable.
There are two main resources that are needed to train an AI model and make it better: compute and data. Renting out compute is one solution, but we still need to get data from somewhere, and different data to exclude potential bias in the model.
→ Verifying data from different sources for AI
The more data you have, the better model you’ll have; the thing is, you often need diverse data. This is one of the problems with AI models.
Data protocols have been around for decades. Regardless of whether the data is public or private, data brokers gather it one way or another, pay for it or not, then sell it for profit.
The problems we face with getting proper data for AI models are a single point of failure, censorship, and the lack of a trustless way to provide authentic data for “feeding” an AI model.
Who needs this?
Well, first of all, it’s AI researchers and developers who are looking to train and infer their models with real, proper inputs.
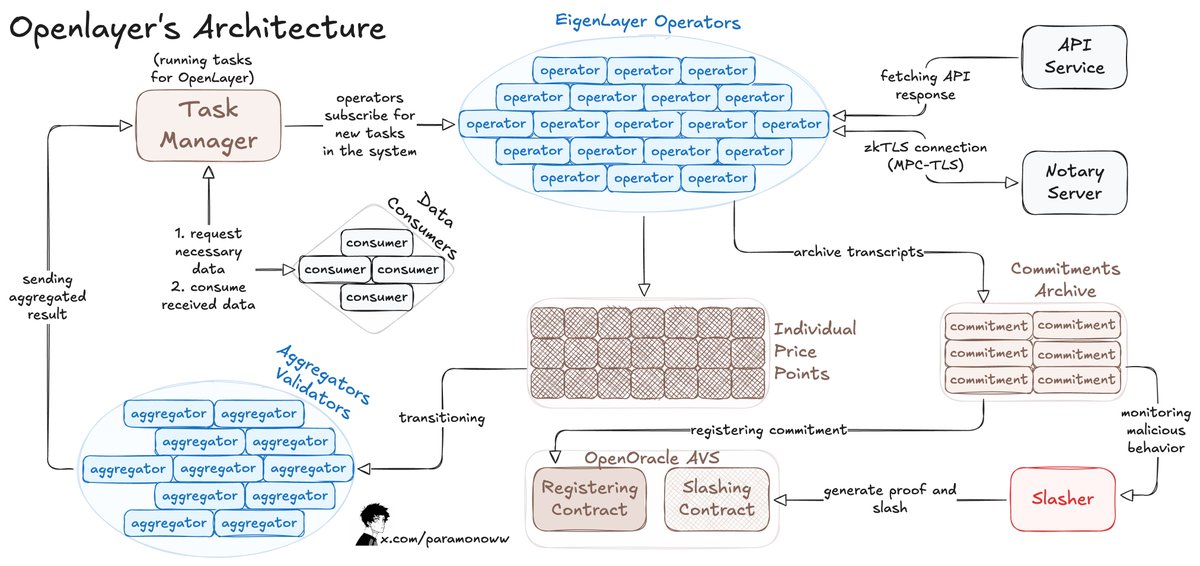
OpenLayer, for example, lets anyone add a data feed to the system or AI model permissionlessly, and the system can transcribe every piece of available data in a provable way.
OpenLayer also uses zkTLS, which was described in my previous writings, to ensure that what the operator reports is indeed what they got from the source (verifiability).
Here is how OpenLayer works:
1. Data consumers publish data requests to OpenLayer’s smart contract and retrieve results from the contract, on-chain or off-chain, using APIs similar to major data oracles.
2. Operators register through EigenLayer to secure OpenLayer AVS staking assets and run AVS software.
3. Operators subscribe to tasks, process and submit data to OpenLayer, and archive raw responses and attestations in decentralized storage.
4. For variable results, aggregators (special operators) standardize outputs.
Developers can ask for fresh data from any website, and it can be plugged into the network, while if you’re developing something in AI, you can get reliable, real-time data.
We have gone through the compute process for AI and getting verifiable data for AI. After we get the two main parts of the AI model, it’s time to do the computation itself and verify it.
→ AI computation, in order to be correct, has to be verified
In the best scenario, nodes must prove their computational contribution to ensure the system operates correctly.
In the worst case, nodes could falsely claim to contribute computational power without doing any actual work.
Requiring nodes to prove their contribution can ensure that only legitimate participants are recognized, avoiding malicious behavior among them. This is actually pretty similar to standard Proof of Work; the only difference is the work that those nodes do.
Even if we add proper incentive alignment to the system, if nodes can’t permissionlessly prove that they did some work, they could receive disproportionate rewards compared to their actual contributions and vice versa.
If the network can’t assess computational contributions, it might overload some nodes with tasks they can’t handle while leaving others idle, leading to inefficiencies or failures.
Proving computational contribution allows the network to quantify each node’s effort using a standardized metric, such as FLOPS (floating-point operations per second). This way, rewards can be allocated based on actual work done, not just presence in the network.
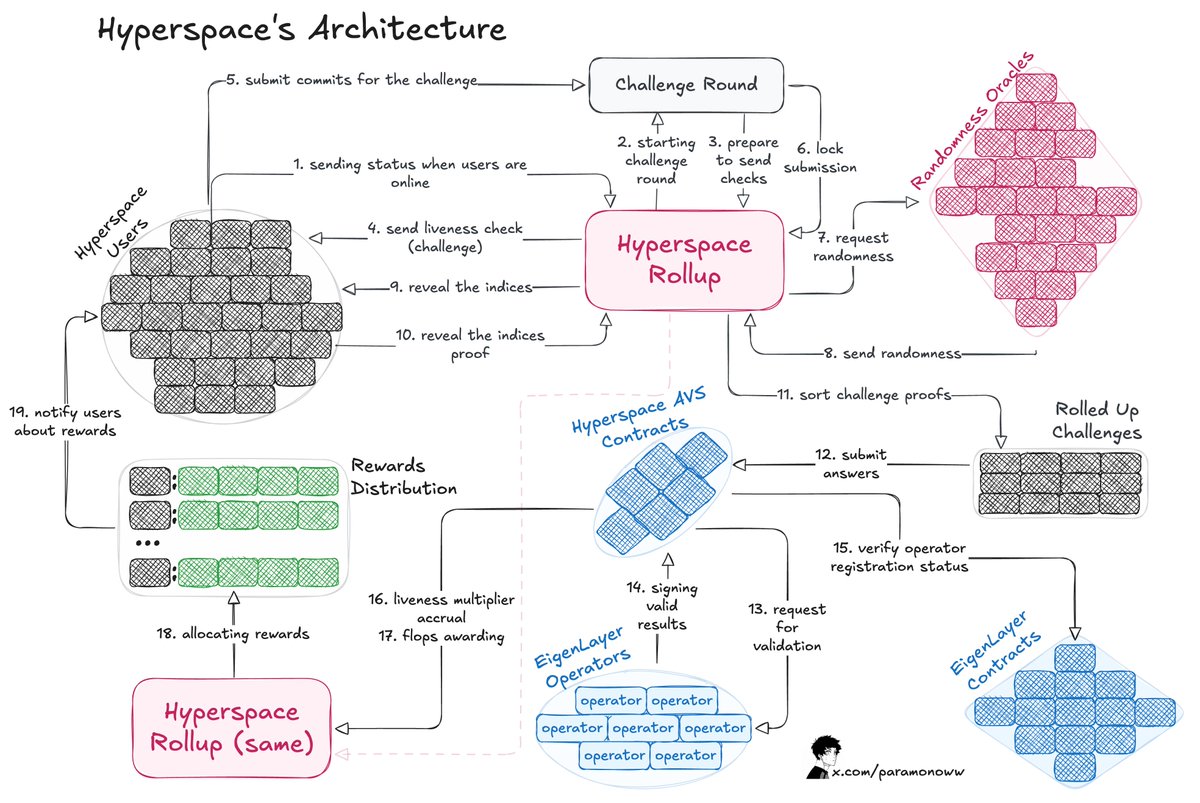
The team from @HyperspaceAI developed a Proof-of-FLOPS system, enabling nodes to lease unused computational capacity. In exchange, they earn flops—points that will function as the network’s currency.
Here is how the architecture looks:
1. The process starts with a challenge delivered to the user, who responds by submitting a commitment for that challenge.
2. Hyperspace rollup manages the flow by securing submissions and fetching randomness from an oracle.
3. The user discloses the indices, and the challenge is finalized.
4. The operator checks the responses and notifies the Hyperspace AVS contracts of valid outcomes, which are then confirmed via EigenLayer contracts.
5. Liveness multipliers are calculated, and flops are granted to the user.
Proving computational contribution provides a clear picture of each node’s capacity. Because of that, the system can assign tasks intelligently—giving complex AI computations to high-powered nodes and lighter tasks to less capable ones.
The most interesting part here is making this system verifiable, so anyone can prove the correctness of the work that was done. Hyperspace has an AVS that constantly sends challenges, randomness requests, and multiple layers of validation processes, as seen in the diagram above.
Operators can engage in the system knowing that the results are verified and rewards are fairly distributed. If the results aren’t correct, the malicious actor is obviously slashed.
There are lots of reasons to verify the final AI computation:
• To encourage nodes to join and contribute.
• To distribute rewards proportionally based on effort.
• To ensure contributions directly support certain AI models.
• To allocate tasks effectively across nodes based on their proven capacity.
→ AI decentralization & verifiability
As noted by @yb_effect, the terms "decentralized" and "distributed" are not similar at all. Distributed simply refers to hardware spread out across different locations, yet they still have a centralization point of connection.
Decentralized means there’s no single main node, and the training process can handle failures, much like most blockchains work today.
For AI networks to be truly decentralized, different solutions are applicable, but what we need for sure is verifiability of basically everything.
If you want to build an AI model or agent, you want to make sure that every component and essentially every dependency is verified.
Inference, training, data, oracles — everything can be verified to bring not only incentive-compatible crypto rewards into the AI system, but also to make it fair and efficient.
1
1
2
1,340

23 Jan 2025
Exploring the Intelligent Future of Autonomous Driving: Insights from NVIDIA's Recent Release
During CES 2025, NVIDIA announced the latest progress in the NVIDIA DRIVE family of automotive businesses, unveiled the NVIDIA DRIVE Hyperion self-driving platform based on the new NVIDIA AGX Thor system-on-chip (SoC), and announced that it will collaborate with Toyota to develop the next generation of “self-driving cars” using the NVIDIA DRIVE AGX on-board computing platform.
According to Jen-Hsun Huang, Founder and CEO of NVIDIA, “The evolution of AI has moved from perceptual AI, which is about understanding images, text and sound, to generative AI, which is about creating text, images and sound. Currently entering a new era of physical AI, NVIDIA GPUs and platforms are at the center of driving change in the current era, bringing breakthroughs to multiple industries including robotics and self-driving cars.” He also said, “The transformation of self-driving cars has arrived, and automobiles are poised to become one of the largest AI robotics industries. NVIDIA is leveraging two decades of expertise in automotive computing, safety, and the CUDA AV platform to transform the multi-trillion dollar automotive industry.”
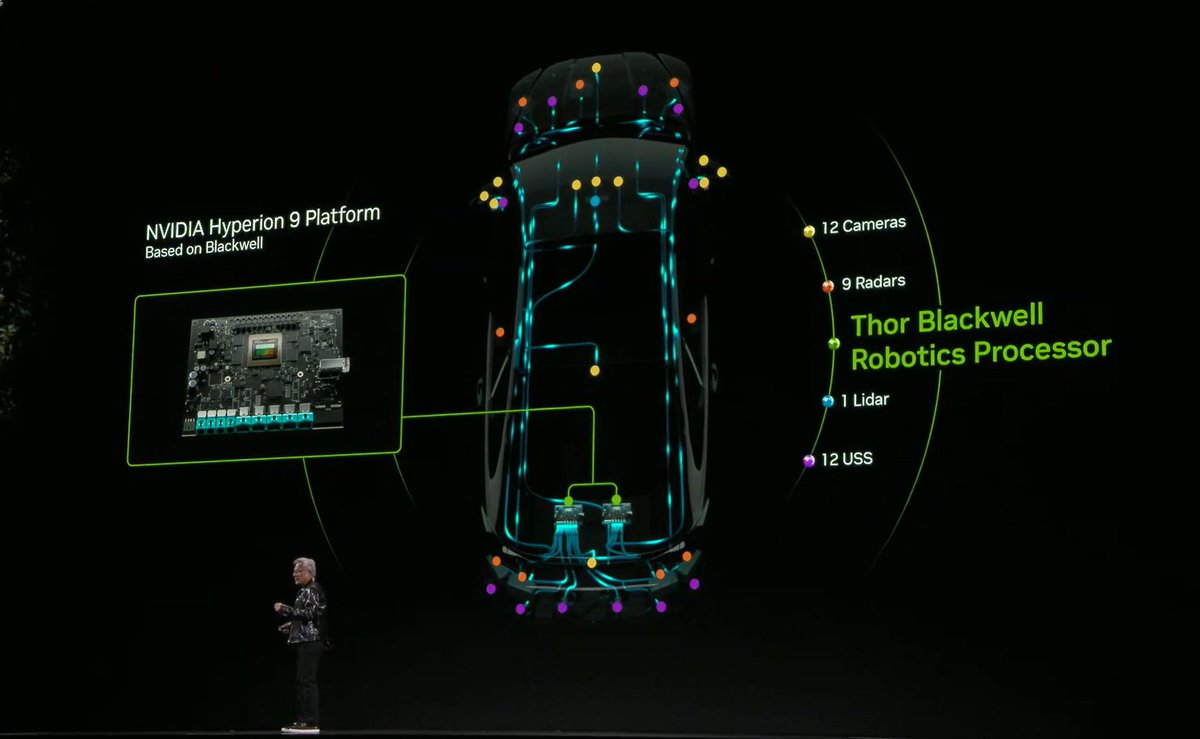
From a hardware level, NVIDIA DRIVE Hyperion is the first end-to-end autonomous driving platform that integrates an advanced system-on-chip, NVIDIA AGX Thor, sensors and safety systems designed for next-generation vehicles. Equipped with a suite of sensors as well as active safety and L2 driving stacks, the platform has been adopted by global leaders in automotive safety such as Mercedes-Benz, Jaguar Land Rover and Volvo. Among them, NVIDIA AGX Thor, an upgraded version of Orin, has 20 times the computing power of its predecessor chip. At the system level, “DRIVE OS” is the first automotive operating system certified to meet the highest standards of functional safety.
Source:NVIDIA CES 2025 Keynote
NVIDIA said that almost all mainstream car companies around the world cooperate with NVIDIA, including Waymo, ZOOX, Tesla, Toyota, the world's largest electric car company BYD, and upcoming innovative models of Mercedes, LUCID, RIVIAN, Xiaomi and Volvo.
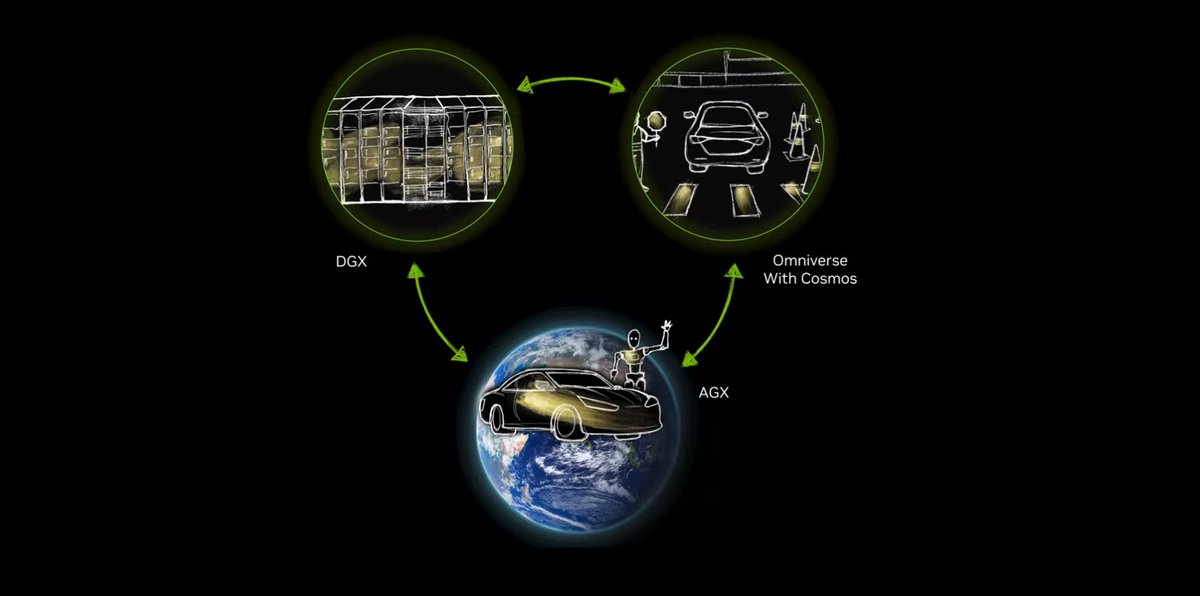
The era of autonomous driving has arrived, and the automotive industry needs a large amount of computility to train autonomous driving capabilities and even utilize AI to transform traditional automotive production lines. In this context, NVIDIA provides three types of computing systems for the automotive industry to realize intelligent development: NVIDIA DGX for AI model training, Omniverse, a system for test driving and generating synthetic data, and DRIVE AGX, an in-vehicle supercomputer.
Source:NVIDIA CES 2025 Keynote
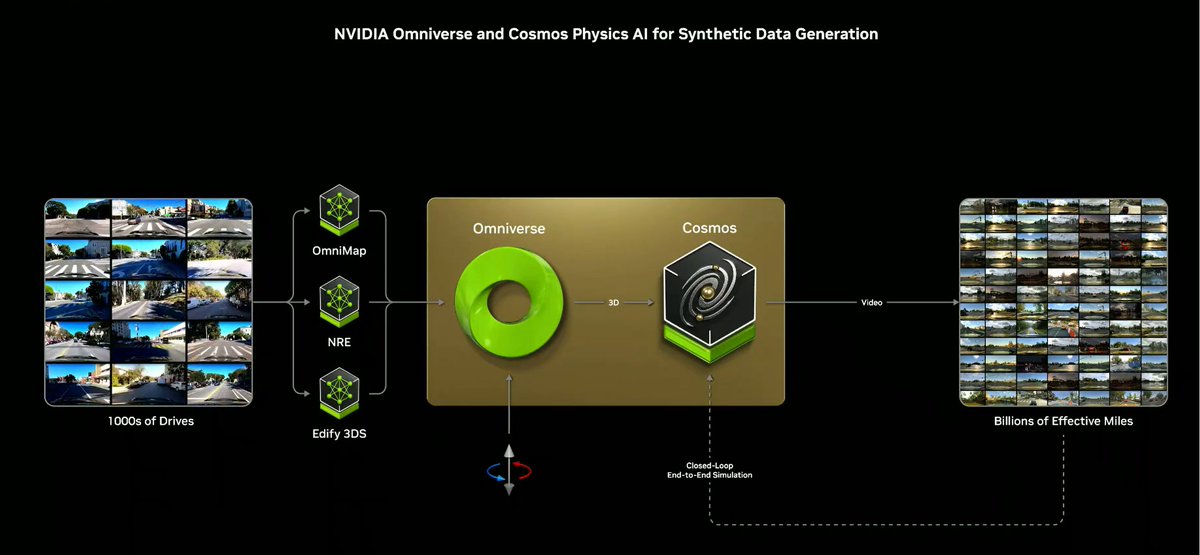
NVIDIA is showcasing“AI Data Factories”at CES 2025 that utilize Omniverse and Cosmos to dramatically expand training data by synthesizing driving scenarios. These include OmniMap, fusing map and geospatial data to build a 3D environment that can be driven; NRE, utilizing sensor logs to generate high-fidelity 4D simulation environments and generating scenario changes for training data; and Edify 3DS, searching for or generating new assets from an asset repository to create scenarios for simulation. Through related technologies, NVIDIA scales hundreds of driving scenarios into billions of active miles, dramatically increasing the size of the dataset needed to enable safe and advanced autonomous driving features.
Source:NVIDIA CES 2025 Keynote
NVIDIA's "Autonomous Driving Brain" offers exceptional performance, guiding the automotive industry toward a more intelligent future
As the NVIDIA DRIVE Hyperion autonomous driving platform equipped with the new NVIDIA AGX Thor, which was announced at this year's CES, it is necessary to introduce its features and functional characteristics.
DRIVE Hyperion is the first end-to-end autonomous driving platform featuring DRIVE AGX Thor, a high-performance system-on-chip built on NVIDIA's Blackwell architecture, the NVIDIA DriveOS automotive operating system, a suite of sensors, and an active safety and L2 driving stack designed for the next-generation vehicles.
NVIDIA DRIVE Thor is the core system-on-chip that powers the DRIVE Hyperion autonomous driving platform. As the successor to NVIDIA DRIVE Orin, it delivers up to 1,000 TFLOPS of performance and can accelerate inference tasks to help self-driving cars recognize pedestrians, adapt to inclement weather and more. In addition, DRIVE Thor delivers rich cockpit functionality, safe and reliable highly automated driving and driverless features, all integrated on the same centralized platform.
DRIVE Thor chips based on the NVIDIA Blackwell architecture are optimized for the most demanding processing workloads, involving generative AI, visual language models, and large language model workloads. The simplified architecture leverages NVIDIA's accelerated compute capabilities to run an end-to-end self-driving car stack and a proven safety stack in parallel, increasing the chips’ versatility, reducing latency and improving the safety of vehicle operations.
From the passenger car landing situation, the world's largest electric car company, BYD, launched the next generation of electric models to be equipped with NVIDIA DRIVE Thor. New energy car brand GAC EAN's high-end luxury brand Hao Platinum's next generation of electric cars will use the DRIVE Thor platform, and the new model will be mass-produced in 2025, which can realize L4-level autonomous driving. Xiaopeng will use the NVIDIA DRIVE Thor platform as the “AI brain” of its next-generation electric vehicle, and the new-generation on-board computing platform will empower the XNGP intelligent assisted driving system to realize automatic driving and parking, driver and passenger monitoring and other functions.
In addition to passenger cars, DRIVE Thor can meet the diverse needs of other segments such as trucks, self-driving cabs, and delivery vehicles. During CES 2025, Aurora, Continental and NVIDIA announced a long-term strategic partnership program aimed at the large-scale deployment of driverless trucks. NVIDIA DRIVE Thor and DriveOS will be integrated into Aurora Driver to enable L4 autonomous driving, and Continental plans to realize the full-scale deployment of related products by 2027.
With a focus on end-to-end autonomous driving and the emergence of robotaxis, the intelligence behind autonomous driving is reaching new heights
At present, “end-to-end automatic driving” has become the focus of industry attention. The industry generally believes that the automatic driving system is really moving towards a comprehensive landing based on the data closed-loop, with neural networks as the strategy carrier, to take the “end-to-end” automatic driving technology route.
The so-called “end-to-end automated driving” can generate vehicle control signals directly from sensor data, avoiding the complexity of interface design between modules, preserving the original data details to the greatest extent possible, and improving the overall performance of the system through global optimization. In short, unlike modularized autonomous driving (which is divided into perception layer, decision-making and planning layer and control layer), “end-to-end” means that one end of the sensor inputs information, and the other end directly outputs driving commands. The advantages are higher real-time and accuracy, elimination of information transfer errors between modules, and improved response time. The end-to-end model has stronger generalization ability and can be trained by large-scale data to adapt to the complex and changing road environment.
In recent years, the practical achievements of Tesla, XPENG, Li Auto and other enterprises in the field of end-to-end technology have further confirmed the potential and feasibility of the “end-to-end” technology path. Tesla has continuously optimized its end-to-end autopilot model, and Tesla's autopilot system performs well in complex city roads and highway scenarios, thanks to Tesla's self-developed Dojo supercomputer, which provides strong computility support for end-to-end model training. XPENG's XNGP full-scene intelligent assisted driving is a full-scene, high-grade autonomous driving system for mass production. Based on end-to-end deep learning models, XNGP realizes autonomous driving functions in a variety of scenarios, such as city roads, highways, parking lots, and so on. Li Auto proposes the dual system architecture of “end-to-end VLM” for automatic driving and combines it with the training and evaluation system based on the world model to complete the full-volume push from parking space to parking space, and realizes the AI capability of the automobile from “behavioral intelligence” to “spatial intelligence”by going from end-to-end VLM to VLA.
Robotaxi has become an important business model for future self-driving trips. Robotaxi, or self-driving cabs, are cabs that utilize artificial intelligence, sensors, communications, and other technologies to drive autonomously. Vehicles are usually equipped with sensors such as cameras and LIDAR, which can sense the surrounding environment and traffic conditions, and carry out path planning, obstacle avoidance, acceleration and deceleration, steering, and other operations through algorithms and control systems. Passengers book self-driving cabs through mobile apps or voice recognition and enter their destinations. The self-driving cab will deliver the passenger to the destination according to the optimal route and complete the process of payment and evaluation.
Tesla broke into the Robotaxi market in October 2024 with the Tesla Cybercab, a two-seat design that eliminates the steering wheel and pedals of a traditional car and adopts a purely visual solution, which is scheduled to begin production in 2026 and achieve large-scale mass production by 2027.The Tesla Cybercab is a two-seat design that eliminates the steering wheel and pedals of a traditional car and adopts a purely visual solution. In addition, Google Waymo has expanded its operations in San Francisco and Los Angeles in the U.S., providing more than 100,000 trips per week in Phoenix, San Francisco, and Los Angeles, with paid trips totaling more than 2 million trips, and vehicles driving more than 32 million kilometers in fully autonomous driving. In China, Baidu's “Apollo Go” has been open for manned testing in 11 cities across the country, including Beijing, Shanghai, Wuhan and Chongqing. In addition to operating in Guangzhou and Beijing, WeRide has also extended its reach to Abu Dhabi in the United Arab Emirates, where Uber users will have the opportunity to choose WeRide Robotaxi self-driving vehicles when using the service.
According to Mordor Intelligence forecast, the global self-driving car market size from $47.8 billion in 2025 to $133.3 billion in 2030, CAGR compound growth rate of 22.75%, the future of autonomous driving there is a vast market space.
In 2025, the global automotive industry will usher in a critical period of intelligent change. Accompanied by end-to-end autonomous driving and Robotaxi technology R&D and commercialization, it will continue to promote the continuous improvement of global autonomous driving technology and drive more models to use high-performance autonomous driving chips and high-level solutions, leading the automotive industry towards a new era of smart mobility. The breakthroughs made by the upstream and downstream manufacturers of the global automotive industry chain in technology research and development, commercialization applications, and ecological construction herald the imminent arrival of the era of fully automated driving.

1
4
83



21 Nov 2024
Congratulations to Charina Hanum!2024 China-ASEAN Young Leaders Scholarship recipient from Indonesia, is participating in the International Symposium on Computility Technology Standards and Applications in Shanghai. We look forward to welcoming more Indonesian youth to China, fostering stronger people-to-people ties and shared growth in the digital age.




2
6
20
1,283

2 Nov 2024
🧳 The heavy workload has finally come to an end, so check out your earnings at #Grid now! 💰
🚀 Take advantage of every money-making opportunity and start sharing your computing resources to keep the earnings flowing! #Grid #Computility

11
17
86
17,645
24 Oct 2024
🔐 #Crypto economy some of the urgent help that can be provided to AI at the moment, such as computation, validation, data entitlement, and so on.
Blockchain is extremely important for #AI moving forward from the present day. 💡#DePIN #Grid #Computility

9
9
57
14,298
19 Oct 2024
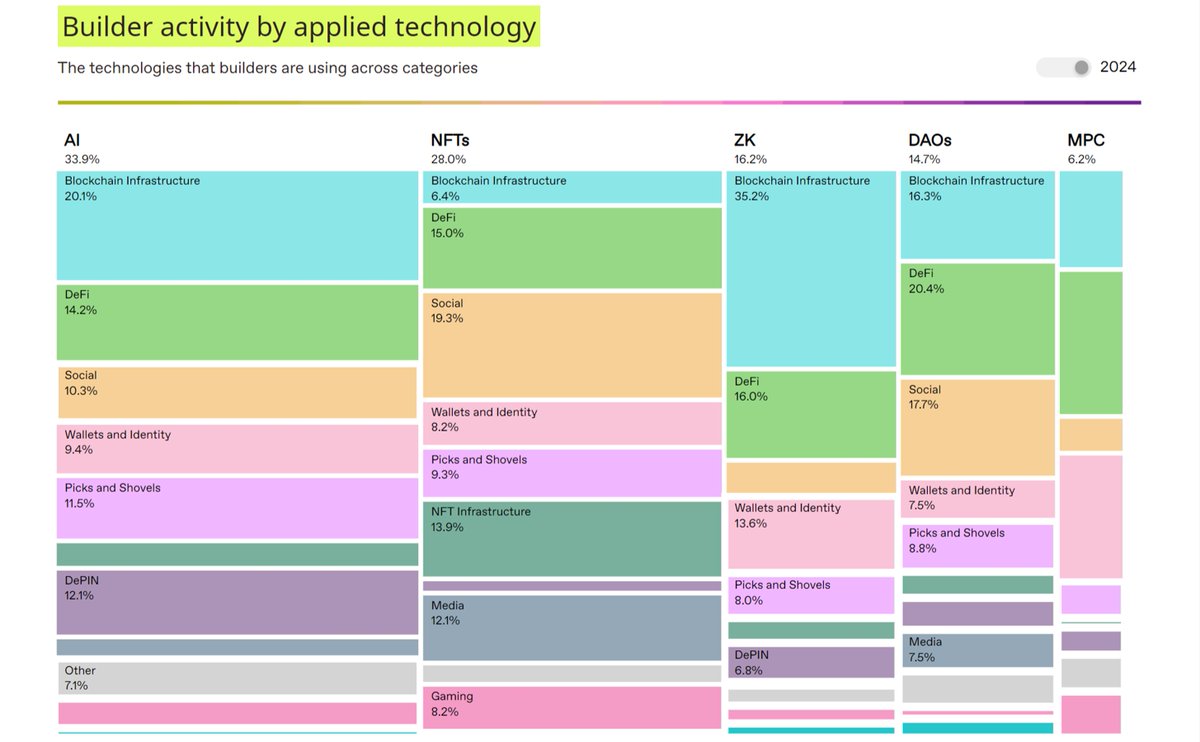
The data shows that 12.1% of DePIN's Projects are currently engaged in #AI research, while in 2023 this figure is only 5.2%.
#DePIN is the fastest growing segment in support for AI. #Grid #Crypto #Computility
10
11
48
16,118