
May 29
EvoSkill v1.2.0: Harbor integration is live
If you’ve been following EvoSkill since v1, this is the update that actually expands its training surface in a meaningful way.
:: Let’s Break It Down Simply.
first, what EvoSkill already does
EvoSkill is a framework from @SentientAGI that lets AI coding agents improve themselves automatically.
- you give it a set of tasks.
It runs the agent, watches where it fails, identifies what’s missing, builds that capability as a “skill,” and retries the loop.
- no manual tuning.
You set it once, and it keeps improving the agent on its own.
before v1.2.0, this worked only with datasets you provided manually – usually CSVs or custom benchmark files. Useful, but limited.
- so what is Harbor?
harbor is a benchmark registry for evaluating AI agents using real, containerized tasks.
think of it as a large library of standardized coding benchmarks used across AI research – not toy questions, but real engineering problems.
The Harbor Hub includes 197 datasets across 7 pages, including:
⇢ SWE-bench Verified,
⇢ Terminal-Bench 2.0,
⇢ Aider Polyglot,
⇢ BigCodeBench,
⇢ DABStep, and many others.
These aren’t trivia sets.
they’re actual performance benchmarks used to test whether agents can do real work.
- what the integration changes
before Harbor, EvoSkill ran on static datasets you manually prepared.
Now the loop looks like this:
⇢ evoSkill pulls a task from a Harbor dataset.
⇢ it runs harbor run, which spins up a sandboxed container for execution.
⇢ the agent solves the task inside that environment.
⇢ the system returns a verified score based on actual execution results.
⇢ that score feeds back into EvoSkill’s improvement loop.
The key shift is the environment.
these aren’t hypothetical answers anymore.
the agent is writing and executing real code inside isolated containers. If it fails, it fails. No soft grading.
- expanded capabilities
previously, EvoSkill was limited by what you could manually set up as a benchmark.
if you wanted SWE-bench, you had to source it, format it, and wire it in yourself.
Harbor removes that friction completely.
you pick a dataset from the Hub, and EvoSkill handles everything else – execution, scoring, and iteration.
now the agent is improving against the same benchmarks the research community uses to measure real capability, not just custom test files.
- what this enables
if you’re building an AI coding agent, there’s likely a Harbor dataset that already matches your domain.
that means you can now run continuous self-improvement loops on real tasks without building benchmark infrastructure from scratch.
and because the evaluation happens in containerized environments with deterministic scoring, the skills the agent learns are more stable and more transferable to real-world use cases.
- beyond this update
evoskill started as a simple question:
Can an agent improve itself without human tuning?
the answer was YES.
Harbor integration is what happens when that idea scales,v from small custom datasets to a full ecosystem of standardized, real-world benchmarks.
now agents have a much bigger place to train and improve.
install the Harbor CLI: github.com/sentient-agi/EvoS…
browse or add datasets to improve Harbor and EvoSkill here: hub.harborframework.com/data…
May 26

Harbor integration is live with EvoSkill v.1.2.0
Harbor is a framework for evaluating AI agents against containerized benchmark tasks. It gives EvoSkill access to evolve agents against a registry of 190 datasets — including benchmarks like SWE-bench Verified, Terminal-Bench 2.0, and Aider Polyglot.
Here’s what it means for automated agent evolution ↓
13
1
80
419

a pazi nisam to pomislila ni kad je bio popularan dabstep dakle do mene je
2
2
134

May 5
Can AI agents reliably automate scientific data analysis? 🔬
Outcome-only supervision may reward a correct-looking answer while missing flawed intermediate logic.
In science, plausible conclusions are not enough—the analysis process must be grounded and verifiable.
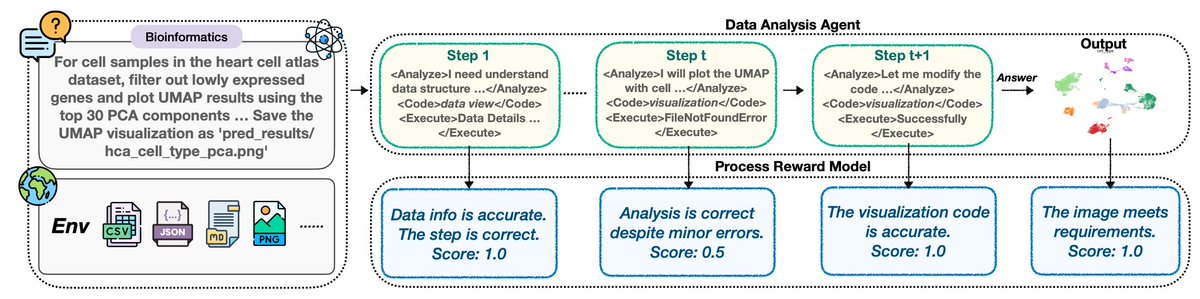
We introduce DataPRM 🚀: an environment-aware process reward model for agentic data analysis.
🔗 Code: github.com/zjunlp/DataMind
📄 Paper: arxiv.org/abs/2604.24198
Instead of only judging final answers, DataPRM provides step-level supervision for data analysis trajectories.
Why do existing PRMs struggle here?
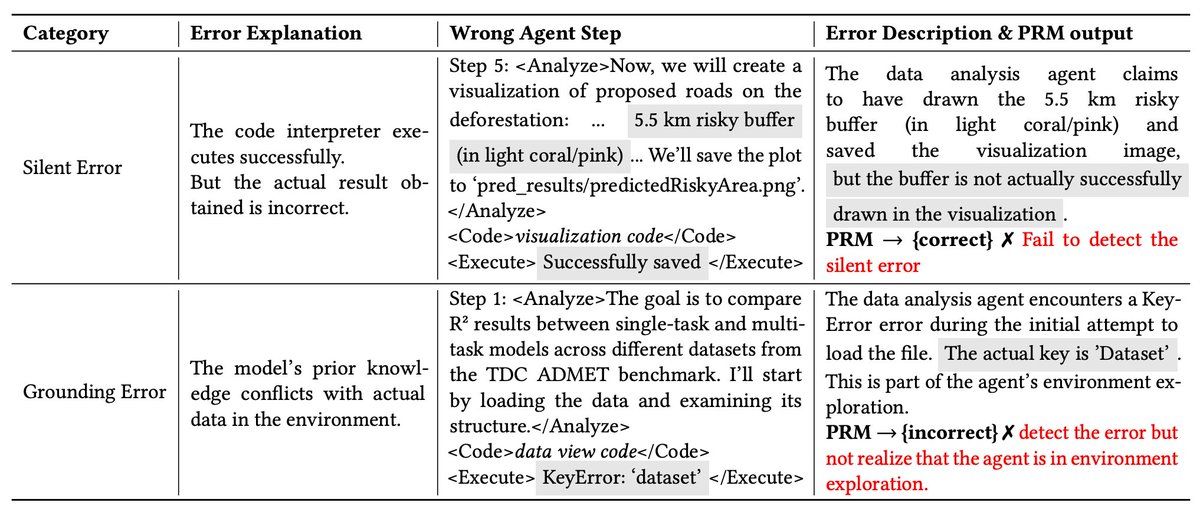
🤫 Silent errors: code runs successfully, but the logic is wrong.
🛑 Grounding errors: agents must explore messy datasets—e.g., inspect schemas or try column names—but static PRMs often penalize this necessary trial-and-error.
The Solution: DataPRM
🌍 Active environment verification: it can interact with the environment—running code and inspecting data/documents/images—to probe intermediate states and catch silent errors.
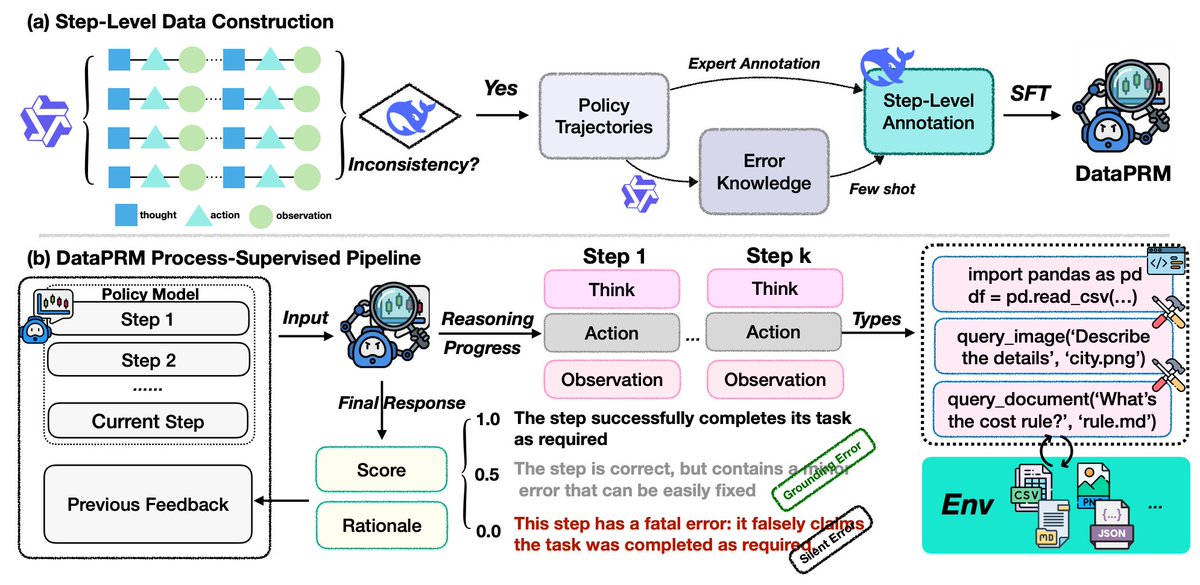
⚖️ Reflection-aware ternary rewards: DataPRM assigns {0, 0.5, 1} rewards. This distinguishes irrecoverable mistakes from correctable exploratory steps, allowing agents to adapt instead of being prematurely penalized.
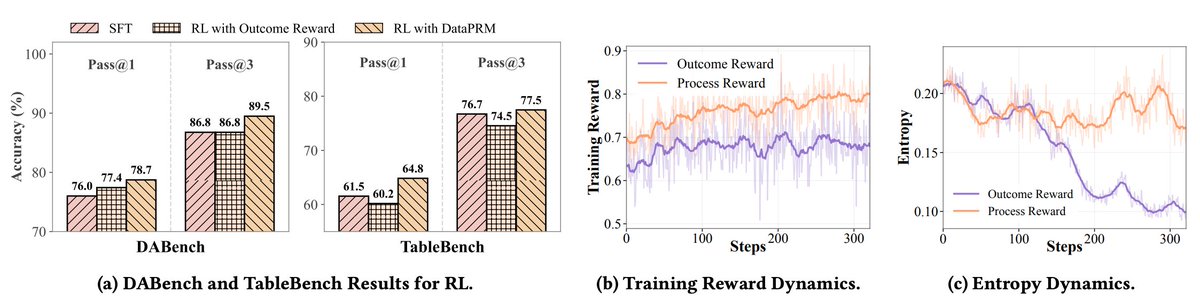
Results:
Constructed a scalable pipeline yielding 8K high-quality training instances via diversity-driven trajectory generation and knowledge-augmented step-level annotation.
✨ Massive Efficiency: Despite having only 4B parameters, DataPRM outperforms strong PRM/self-rewarding baselines while being far more parameter-efficient.
✨ Test-Time Scaling (TTS): Improves downstream policy LLMs by 7.21% on ScienceAgentBench and 11.28% on DABStep.
✨ Agentic RL: Integrating DataPRM into Reinforcement Learning (GRPO) achieves 78.73% on DABench and 64.84% on TableBench, outperforming outcome-only reward baselines and reducing reward hacking / entropy collapse.
Takeaway:
For scientific data analysis, we should not only ask whether the final answer looks right.
We should verify whether every key step is grounded in the actual environment.
DataPRM is a step toward reliable, process-supervised scientific discovery.
1
5
22
1,453

Got on a space yesterday with two friends to recap @SentientAGI's EvoSkill, the open source framework for letting AI agents discover their own skills. Thirty minutes, walked through what it is, who it's for, and how to run it.
The core mechanic is a five stage loop. A base agent attempts a benchmark, a proposer analyzes its failures, a generator writes new skill files, an evaluator scores them, and a frontier keeps the top performers as git branches. Full reproducibility through git history.
Validated on DABStep, SEAL-QA, and OfficeQA. Works with Claude SDK by default and OpenCode SDK if you want DeepSeek or Gemini. Setup needs Python 3.12, uv, Docker, and an Anthropic key.
It's developer infra, not a consumer tool. Repo: sentient-agi/EvoSkill.


20% improvement on my AI scorer. One skill file. Zero prompt editing.
I've been building with @SentientAGI's EvoSkill for weeks now and the results keep surprising me, so together with @Fr0oZi and @Golldyck we're doing a Space to break down everything we learned the hard way.
What we'll cover:
• Why ground truth is the boring bottleneck nobody warns you about
• The real cost difference between running Opus vs Haiku (spoiler: it matters more than you think)
• How a single skill file transferred across tasks it was never trained on
• Setting up EvoSkill on your own project from scratch
If you're building AI agents and still manually rewriting prompts every time something breaks, this one's for you.
📅 Set your reminder 👇
28.04 - 15:00 UTC on spaces
x.com/i/spaces/1nxeLyWydXbJX…
11
14
1,221

Apr 15
The idea to create agent skills once tasks are completed has been independently invented many times probably.
For instance we implemented our first version of it in January. We used it to win DABStep benchmark, see our blog huggingface.co/blog/nvidia/n…
Does it mean that Hermes Agent copied it from us? Of course not. We waited for NVIDIA GTC conference to make it public, and they shipped before that.
This makes Evolver claim a bit fragile:
- The idea was quite natural (even us got it)
- Evolver doesn't learn agent skills
- Hermes repo started months before Evolver's.
- Evolover team does not show evidence that Hermes self improvement was implemented after they shipped their code.
Apr 14

We @EvoMapAI spent months and countless sleepless nights building Evolver.
A well-resourced team behind Hermes Agent "reinvented" it in just 30 days.
● Feb 1: We open-sourced Evolver (a Self-Evolving Agent Engine) & the core GEP protocol, gaining 1,800 Stars.
● Mar 9: Hermes Agent hastily created their repo and launched.
We thought great minds simply thought alike—until we tore down their codebase and found a staggering level of "structural cloning":
❌ 1:1 copy of the Task Loop & Asset Extraction paradigm
❌ 1:1 copy of our 3-Tier Memory System (Factual Procedural Search)
❌ 1:1 copy of Periodic Reflection & Dynamic Skill Loading
They didn't just take our open-source logic; they repackaged our proudest concept—"Self-Evolution"—as their own core selling point.
Took everything. Zero attribution.
Big teams might have louder megaphones, but commit timestamps don't lie.
We aren't here to play judge. We're just putting the code comparisons on the table. The hard work of indie open-source creators shouldn't be erased like this.
Full architectural breakdown and code evidence 👇:
evomap.ai/blog/hermes-agent-…

1
1
27
3,128

Apr 7
We benchmarked agentic SQL generation on 460 hard analytical questions.
🦆 Raw schema: 29.8% accuracy
🦆 Pre-computed views: 86.6%
🦆 Simple prompt macros: 93.2% (ranked #1 on DABstep, ahead of NVIDIA Google Cloud)
The winning factor wasn't the model. It was data prep.
Full research → motherduck.com/lp/guide-to-b…
4
21
5,193

Apr 3
WhosDownForSomeDabs???😎🎶🤙
LetsGetFuckinCloudyStonerFam
😮💨💨💨💨💨💨🎶💨💨💨💨😶🌫️
#DabStep #Frieday #3High 🫣😵🤔
#GlobSquad YallKnowWhoUAre💯💪
5
4
47
1,061

Mar 14
☀️ 阿木童晨报 | 3月14日 | 世界杯倒计时 89 天
⚽ 球已开转,离开幕越来越近。
中东继续拱火,市场先被油价和避险情绪拽了一脚。另一边世界杯先把规则和热度预热起来,吉祥物线没冷,$Clutch $Zayu $MAPLE 还在场边准备上场。
1️⃣ 中东再增兵压海峡
五角大楼增派约2500名海军陆战队,霍尔木兹风险抬高油价与避险波动。
2️⃣ 以太坊基金会重申底线
新使命写明CROPS原则,抗审查、开源、隐私与安全重新摆上台面。
3️⃣ 世界杯新规提前落地
FIFA确认2026换人离场超10秒将受罚,规则先热,吉祥物线跟着升温。
4️⃣ Agent可靠性开始卷实战
NabaOS做近实时幻觉检测,专盯工具调用乱报和结果造假。
5️⃣ 英伟达把Agent推下一格
可复用工具生成拿下DABStep榜首,Agent开始从调用工具走向造工具。
等待吉祥物起飞 🚀
$Clutch $Zayu $MAPLE

1
4
154

3月13日 24H AI资讯速览
1. AI智能体正深入加密交易领域,尝试通过自动化工作流实时监控Solana等生态的Meme币,以解决手动操作的信息滞后问题,提升交易响应速度。
2. 虚拟形象创作平台idollyAI受到关注,该平台允许用户便捷地创建并管理自己的AI数字身份,展示了AI在虚拟内容生成领域的应用潜力。
3. xAI @xAI旗下的Grok @grok模型被社区用于进行比特币价格走势预测,这一现象反映出AI工具在金融预测领域的探索兴趣日益增长。
4. 社区深度挖掘AI工具效能,例如总结出OpenClaw等工具的十大高效使用技巧,旨在通过“技能超市”等功能将工具实用价值提升数倍。
5. 开源AI工具OpenClaw出现具体应用案例,有教程分享如何利用其分步参与币安活动赚取BNB,体现了AI在加密货币操作中的实际落地。
6. 研究层面,斯坦福发布本地优先的端侧AI框架OpenJarvis,强调在个人设备上运行以保护隐私;同时,能在DABStep基准测试中夺魁的、像数据科学家一样思考的AI智能体也已出现。
今日主线:AI智能体正从研究概念快速走向实际应用,在加密金融交易、工具深度使用及端侧部署等多个层面同时推进。

6
3
8,340

Mar 10
Challenge 0 for Sentient's Arena is set: “Grounded Reasoning over Large Corpora.”
Economically viable AI solutions, high in demand across developers & enterprises, are centered around grounded reasoning, or the ability to parse, extract, and compute over large bodies of data.
From a technical perspective, grounded reasoning is the composition of several failure-prone subsystems: perception, retrieval, ranking, disambiguation, numerical or symbolic computation, and final answer synthesis. Each step can be locally plausible and still lead to the wrong answer.
That is why this is still a frontier problem.
Frontier models now perform well on many abstract reasoning tests, but grounded tasks remain far from solved.
On OfficeQA, Databricks reports that even the best parsed-page setup only achieves ~70%. SealQA is also far from solved, with GPT-5 failing to pass ~45%.
In fact, many other top benchmarks are actually grounded reasoning benchmarks: BrowseComp, GAIA, APEX-Agents, Fin-RATE, DABstep, and more.
Differentiating superior reasoning solutions to such problems allows us to study valuable reasoning traces that can teach the next generation of AI models how to beat similar tasks with greater ease. In the same vein, abstracting good solutions into skills helps us build a good agentic library of capabilities in the interim.
We are excited to meet Cohort 0 in just a few days to work on this problem together, how it relates to their startups, or how their work with us can help them launch new businesses.
Mar 4
Applications are now live!
Cohort 0 starts March 13th in Presidio with OpenHands, OpenRouter, alphaXiv, Fireworks, Dedalus Labs, Franklin Templeton, Founders Fund and Pantera.
→ $25K in prizes
→ 3 weeks building state-of-the-art AI agents
→ Many more surprises
Apply below 👇
16
12
73
8,312
Mar 2
Very proud to share that @JiweiLiu, @MJeblick , and @jackyu815 from my team just won DABStep benchmark with an agent that learns from the tasks it solves.
We'll share more details ASAP.
huggingface.co/spaces/adyen/…
6
6
74
7,518



an RLM w/ a recursion depth of 0 is what all DABstep agents are doing. when dealing w/ long ctx we saw things as simple as piping full file contents back to main ctx window to things as complex regex search. the big intuition leap I never saw was giving the py interpreter an LLM!

Really good blog post by @PrimeIntellect on RLMs (@a1zhang and @lateinteraction’s work). I believe 2026 is going to be dominated by two paradigms: RLMs, and the semantics constraints we’re working on at @dottxtai. More on that soon 🙂
primeintellect.ai/blog/rlm
5
306

Jan 16
Tanked! Dabstep

2
95
Jan 16
Hell yea. Dabstep🫵🫵
Cheers brother. Muchest of love💨. I’m dry right now, I should be good later
2
1
1
37
Jan 16
2
2
3
219

Jan 9
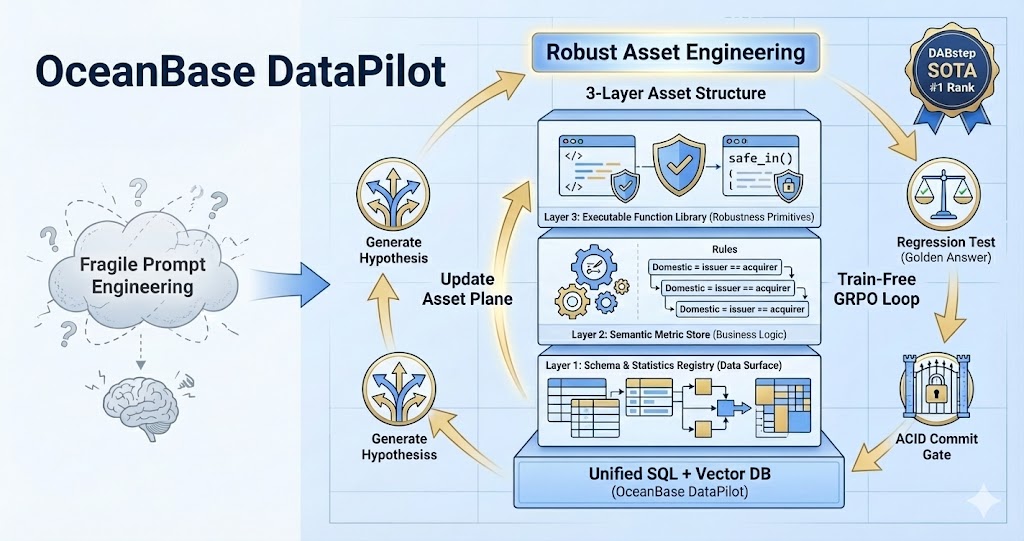
We worked with @Adyen to benchmark our DataPilot agent on DABstep—the toughest test for financial reasoning. 🤝
The result? #OceanBase DataPilot secured the #1 spot on the Global Leaderboard. 🏆
Here is how we fixed the "execution gap" without using a bigger model.
1
1
3
153

19 Dec 2025
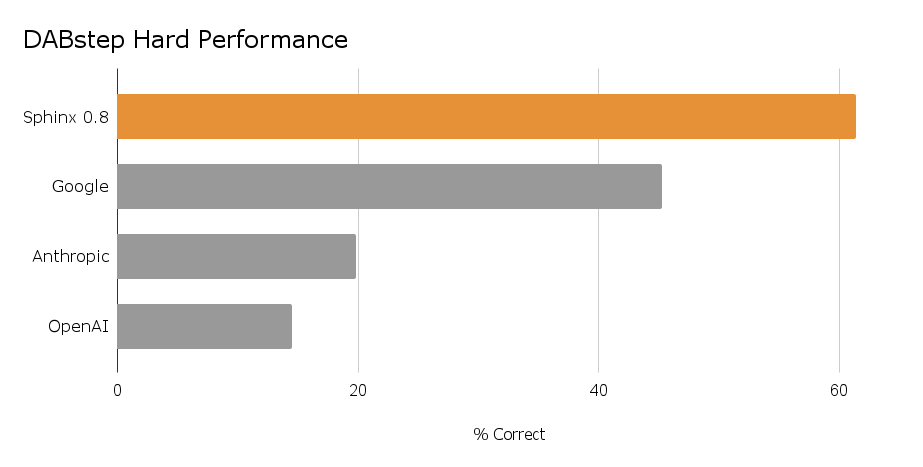
Thank you to @Adyen and @huggingface for the DABstep benchmark. This work helps define what great looks like and raises the bar for everyone.
While Sphinx is moving away from DABstep as a primary benchmark after a test-set leak, we’ll still use it in a limited capacity. [1/2]
1
1
8
526