
Apr 28
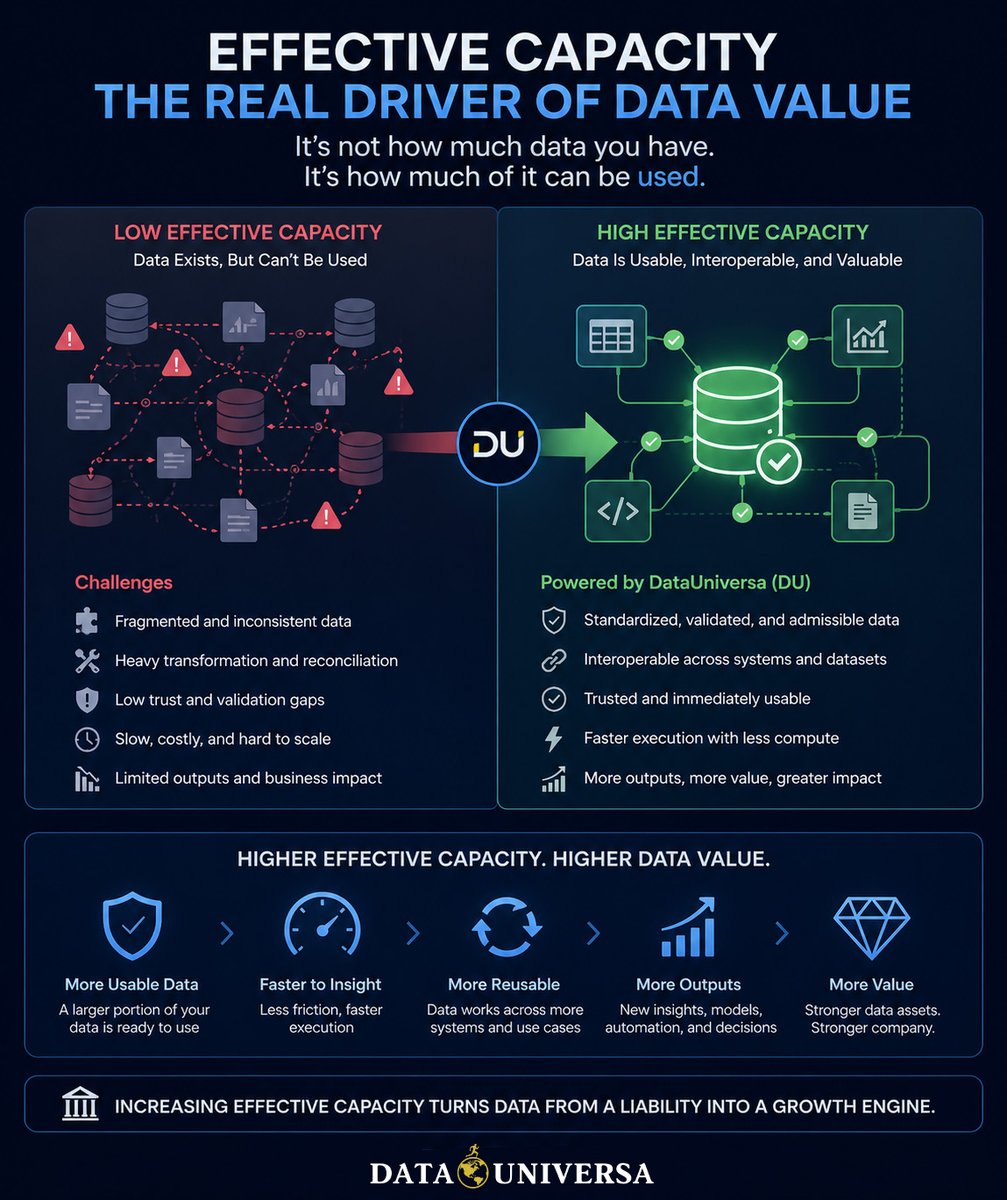
Data value is not driven by volume. It’s driven by usability.
The percentage of your data that can actually be used, your effective capacity, is what determines output, scalability, and ultimately valuation.
Most organizations are operating far below it. Large portions of their data exist, but can’t be reliably combined, executed, or reused without significant effort.
That gap is where value is lost.
Increase effective capacity, and you don’t just improve efficiency, you expand what your data is capable of doing, how often it can be used, and how much value it can generate.
Here’s why that matters: lnkd.in/eujSrqWq
#dataeconomy #effectivecapacity #ML #Datflash
1
9
Apr 14
The quality of decisions will always depend on the quality of what those decisions are based on.
Right now, dataset decisions are still made with limited context.
Teams rely on vendor claims, one-off deals, and internal assumptions, with very little ability to compare across sources. The result is inconsistent pricing, unclear benchmarks, and outcomes that vary more than they should.
Before governance or optimization, there’s a more basic requirement: data needs to be observable.
That’s where DatFlash fits. Not as a complete solution, but as a first usable layer that begins to surface how data actually moves. And once that layer exists, everything built on top of it has a much stronger foundation.
See full article on datflash.com
#dataopacity #datagovernance #dataeconomy

4
Apr 10
AI governance is being treated like a policy problem. But it’s also an infrastructure problem.
Right now, there’s no consistent way to observe how datasets actually move through the ecosystem.
Acquisition, licensing, aggregation, resale, most of it happens out of view.
That lack of visibility creates a bottleneck. Not just for governance, but for interoperability, because interoperability depends on comparability, and comparability depends on shared reference points.
Without them, every dataset is evaluated in isolation. Every decision is context-limited. Every system builds on incomplete signals.
You can’t standardize what you can’t see.
From our perspective, transparency isn’t a byproduct of governance, it’s a prerequisite.
Before frameworks, audits, or policy layers can be effective, there needs to be a baseline understanding of:
>How data is sourced
>How it changes hands
>How value is expressed across different types of datasets
That’s the gap DatFlash is focused on.
We’re building a visibility layer around real dataset transactions, structured in a way that allows patterns to emerge over time. Not as a marketplace. Not as a pricing authority. But as a reference system.
Because once transaction activity becomes observable, it becomes possible to compare. Once it’s comparable, it becomes possible to standardize.
That’s where interoperability begins, where governance can start to operate with real footing.
Is transparency being treated as infrastructure yet, or still as an afterthought?

123
Apr 8
Most conversations about data interoperability start in the wrong place.
They focus on standards. Schemas. Infrastructure.
But there’s a more fundamental issue:
We don’t have visibility into how data is actually acquired and licensed.
Right now, dataset transactions are largely opaque.
-Pricing is inconsistent.
-Terms are unclear.
- Comparisons are difficult.
And without comparability, interoperability stalls.
Because interoperability isn’t just a technical problem, it’s an economic one.
If datasets can’t be evaluated against each other, in terms of cost, rights, scope, and context,they can’t be reliably combined, substituted, or integrated.
Transparency changes that.
When acquisition and licensing signals become visible:
-Patterns begin to emerge
-Benchmarks become possible
-Data assets become comparable
That comparability is what enables interoperability.
Not perfectly. Not immediately. But structurally.
This is one of the reasons we built DatFlash.
Not as a solution—but as a starting point:
A growing set of publicly traceable dataset transactions, including buyers, sellers, sources, and observed pricing signals.
Because before data can interoperate, it needs to be understood.
And before it can be understood, it needs to be visible.
Curious how others are thinking about this.
#dataeconomy #datatransparency #datagovernance

162

Apr 8
Arrowverse was really a staple on Tuesday nights. Going from #DemBows to #DatFlash to #DemLegends. Just a beautiful time.
9
Apr 7
The entire Ai ecosystem needs to be changed so data is interoperable before you can really get good governance solutions. Its a big and difficult process, but, at least from our point of view, for a first step you have to have more visibility and transparency on dataset transactions, so we launched DatFlash very recently just as a start in this process
4
Apr 7
The entire Ai ecosystem needs to be changed so data is interoperable before you can really get good governance solutions. Its a big and difficult process, but, at least from our point of view, for a first step you have to have more visibility and transparency on dataset transactions, so we launched DatFlash very recently just as a start in this process
1
Apr 7
The entire Ai ecosystem needs to be changed so data is interoperable before you can really get good governance solutions. Its a big and difficult process, but, at least from our point of view, for a first step you have to have more visibility and transparency on dataset transactions, so we launched DatFlash very recently just as a start in this process
3
Apr 7
The entire Ai ecosystem needs to be changed so data is interoperable before you can really get good governance solutions. Its a big and difficult process, but, at least from our point of view, for a first step you have to have more visibility and transparency on dataset transactions, so we launched DatFlash very recently just as a start in this process
31
Apr 7
Everyone is talking about AI governance.
But governance assumes something we don’t yet have:
Interoperable, understandable data systems.
Right now, the AI ecosystem is still fragmented;
data is siloed, inconsistently structured, and difficult to compare across sources.
Until that changes, governance can only go so far.
From our point of view, improving AI systems requires a broader shift:
Data needs to become interoperable.
That’s a big and difficult process. But every system change has a starting point.
We believe one of the first steps is simple:
Visibility into how data actually moves.
Who is buying datasets. What types of data are being acquired. And what the real price signals look like.
So we launched DatFlash.
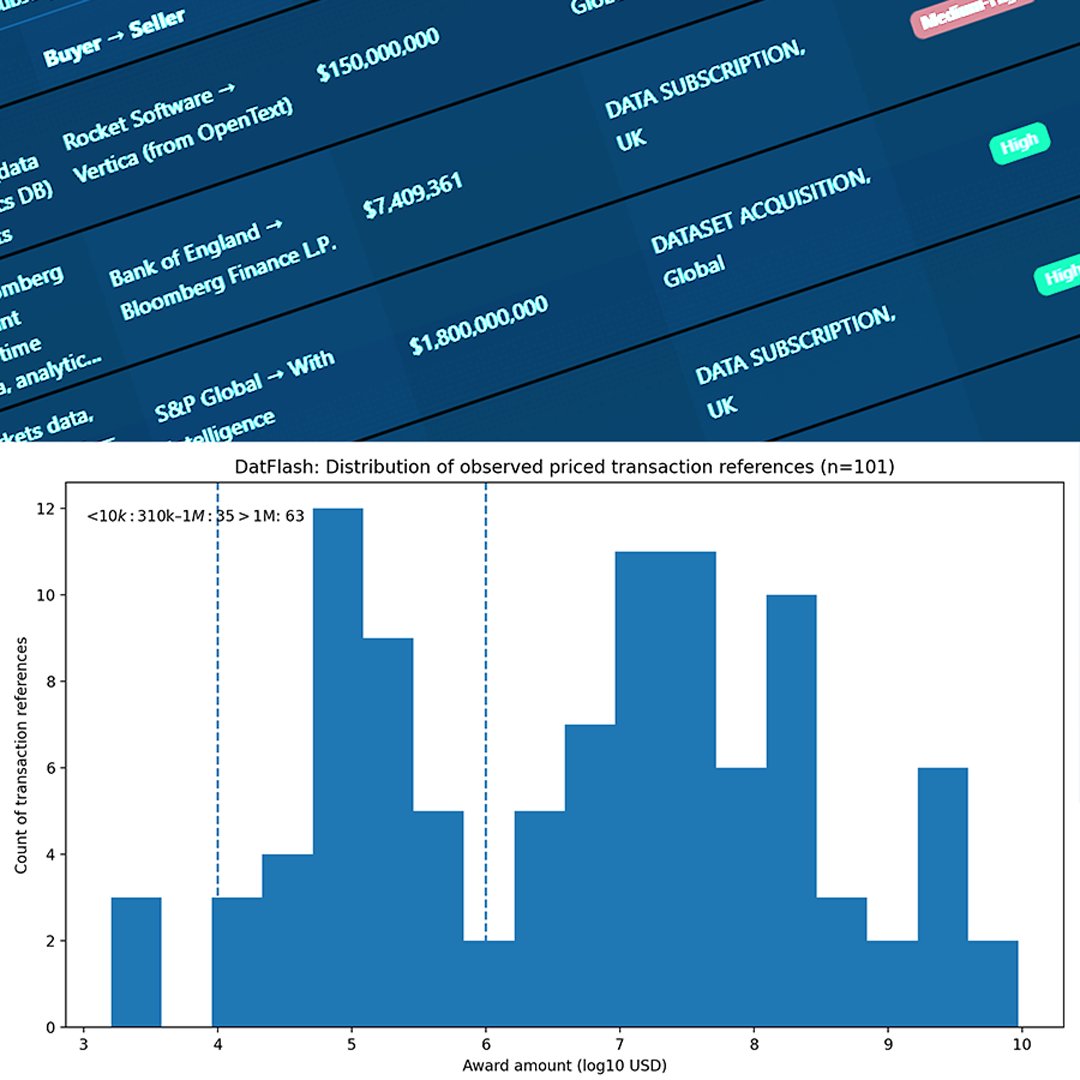
We’ve compiled 100 real AI dataset transactions, including buyers, sellers, sources, and observed pricing signals.
Not marketplace listings.
Not vendor claims.
But publicly traceable transaction references.
This isn’t the solution.
It’s a starting point.
Because before data can be governed, it needs to be comparable.
And before it can be comparable, it needs to be visible.
Curious how others are thinking about this, are you seeing more visibility into dataset transactions, or is it still opaque?
datflash.com
#aigovernance #AIdata #datalicensing #datatransparency
58
Apr 6
Financial and market data remain among the most consistently traded data assets.
Across DatFlash transaction references:
• Licensing dominates outright sales
• Multi-year agreements are common
• Pricing varies widely based on:
– Latency
– Coverage breadth
– Historical depth
– Redistribution rights
Observed transactions include:
• Benchmark/index licensing
• Alternative data feeds
• Historical market datasets
• Risk and analytics-linked data products
Financial datasets frequently exhibit:
• Higher price bands
• Complex rights structures
• Strong sensitivity to exclusivity and timeliness
More at Datflash.com

14
Mar 30
Not to be outdone, Google has partnered with Tempus, an American health company that specializes in AI powered precision medicine and genomic testing. In 2024, Google paid $800,000,000 for a multi-year data partnership in order to use large clinical datasets for AI healthcare models. The future is right here on our doorstep.
See more huge transactions at datflash.com
#google #data #dataeconomy #healthdata #datflash

106
Mar 24
Pharmaceutical giant Roche acquired Flatiron Health in 2018 for $1,900,000,000. This was mainly due to Flatiron’s datasets in oncological research. The research data will be fed to AI for potential drug discovery.
Transactions like this are not so uncommon in the data economy. Datasets from the health domain wager huge price tags for the right buyers.
See more massive data acquisitions on DatFlash

13
Mar 18
The AI industry talks endlessly about models.
GPT models. Vision models. Foundation models. Multimodal models.
But far less attention is paid to the asset that enables all of them:
Training data.
Behind nearly every major AI deployment sits a vast and largely opaque market for datasets—where companies quietly license, acquire, and exchange data assets that can determine whether a model succeeds or fails.
At DatFlash, we track observable dataset transactions across industries to better understand how this market actually works.
What emerges is a very different picture than the one most people assume.
The AI Data Market Is Not a Commodity Market
One of the clearest patterns across observed dataset transactions is pricing dispersion.
Two datasets with similar formats, sizes, or modalities can sell for dramatically different prices.
This is because dataset value is rarely determined by volume alone.
Instead, pricing is driven by factors such as:
• Rights structure (exclusive vs non-exclusive licensing)
• Substitutability (how easily the dataset could be replaced)
• Contextual richness (metadata, labeling, longitudinal depth)
• Risk profile (privacy, regulatory, or reputational considerations)
• Strategic advantage (whether the data creates defensible model performance)
In other words:
10 TB of generic data may be worth less than 10 GB of irreplaceable data.
The Datasets That Drive AI Progress Are Often Invisible
Many of the highest-value datasets are rarely discussed publicly.
These include categories such as:
Moderation and safety corpora
Large collections of labeled harmful content, policy violations, and edge-case behaviors used to train safety systems and content moderation models.
Surveillance-adjacent datasets
Computer vision and sensor data used for security, anomaly detection, crowd analysis, and infrastructure monitoring.
Sensitive behavioral datasets
Data capturing human decision-making, attention, emotional signals, or behavioral patterns.
Workforce monitoring data
Operational telemetry from workplaces, logistics systems, manufacturing environments, and digital productivity platforms.
High-risk contextual datasets
Datasets where interpretation depends heavily on situational context—such as financial decision data, negotiation transcripts, or real-world operational events.
These assets are often difficult to replicate and frequently exist inside private organizations.
As a result, they rarely appear in public dataset repositories.
But they are actively traded.
Dataset Transactions Are Increasingly Strategic
As AI competition intensifies, organizations are beginning to treat datasets as strategic infrastructure rather than passive byproducts.
We increasingly observe dataset transactions that resemble:
• Acquisitions of proprietary training data
• Exclusive licensing agreements
• Long-term data supply contracts
• Structured data partnerships
In some cases, companies are not buying models at all.
They are buying the data advantage that will enable better models.
The Future of the AI Data Market
The dataset economy is still in its early stages.
Unlike financial markets or commodities markets, there is no widely accepted infrastructure for:
• dataset transaction transparency
• standardized dataset valuation
• structured discovery of data assets
• comparable pricing intelligence
This lack of visibility makes it difficult to understand how the market for data is evolving.
DatFlash exists to help illuminate that landscape.
By tracking observable dataset transactions across industries, DatFlash aims to make the emerging AI data economy more legible.
Because in the long run, understanding the flow of data assets may prove just as important as understanding the models trained on them.
#dataeconomy #datasets #datflash
15
Mar 17
Certain dataset categories generate substantial demand while remaining under-discussed in public channels.
These often include:
• Moderation & safety corpora
• Surveillance-adjacent datasets
• Sensitive behavioral datasets
• Workforce monitoring data
• High-risk contextual datasets
Observed characteristics:
• Limited disclosure
• Opaque pricing
• Restricted licensing
• Elevated legal/ethical sensitivity
These datasets highlight a core DatFlash insight:
Market activity does not guarantee visibility.
Buyer hesitation frequently reflects:
• Reputational risk
• Regulatory exposure
• Consent complexity
• Governance uncertainty
DatFlash records transaction and availability references without normalizing away discomfort.
Because real dataset markets are not frictionless.
More at DatFlash

11
Mar 12
Financial and market data remain among the most consistently traded data assets.
Across DatFlash transaction references:
• Licensing dominates outright sales
• Multi-year agreements are common
• Pricing varies widely based on:
– Latency
– Coverage breadth
– Historical depth
– Redistribution rights
Observed transactions include:
• Benchmark/index licensing
• Alternative data feeds
• Historical market datasets
• Risk and analytics-linked data products
Financial datasets frequently exhibit:
• Higher price bands
• Complex rights structures
• Strong sensitivity to exclusivity and timeliness
#dataeconomy #DataOwnership #datasales #sql

2
27
Mar 9
The OpenAI $200,000,000 contract with the US Department of War was a hot topic when news of it broke out.
There's no denying that data is a valuable asset. Your thoughts, your needs, your actions, your purchases are all part of a massive puzzle piece that help companies decide how best to cater to a potential market.
Much of the time, we agree to have our data handed over for third parties to sell to larger corporate entities. Sometimes we aren't aware of it being collected when we use a service or app. However, there's generally consent in allowing the harvesting of such data, so that the correct kinds of advertising are shown to you. Some may view it as a nuisance, but in the end, no real harm done.
However, when harvested data is being used to potentially increase the effectiveness of autonomous weapons, people will understandably draw a line. OpenAI isn't the first tech company to land a military contract. OpenAI is just landing a military contract because of all of the user input it's been receiving since its inception.
We're still very much in the wild west era of AI where legal enforcement is lacking, because frankly we just aren't entirely sure yet what really needs enforcing.
There's always a period of "well, we'll just figure it out as we go along", when introducing something radically new to the current era. As time moves on, it'll become more and more evident that consent will be the driving factor in what makes data truly valuable.
The real question will be how best to go about it. What's admissible? What's justifiable, and what isn't? Time will tell as information lines are drawn, both by legislation, and public opinion.
#SQL #Dataengineering #datamodeling #datflash

1
5
5
172
Mar 6
In January 2023, Microsoft reportedly spent $100,000,000 acquiring training data from OpenAI.
For decades, data was treated as a byproduct of digital systems.
Today, it is increasingly being treated as a strategic asset.
AI systems are ultimately shaped by the datasets they learn from. The scale, structure, and quality of training data can directly influence model capability, reliability, and competitive advantage.
Transactions like this suggest that access to high-quality datasets may become one of the defining economic factors in the development of advanced AI systems.
DatFlash tracks publicly referenced dataset transactions to help illuminate how data assets are beginning to trade in the emerging AI market.
#dataeconomy #DataAnalytics #DataScience

3
34
Mar 3
Pricing dispersion is extreme.
Across DatFlash references:
• Similar data, wildly different prices
• Size ≠ value
• Rights, scope, exclusivity & substitutability drive pricing
From <$10k to $1M .
Data markets aren’t commodities.
#Data
More at
datflash.com
1
3
25
