
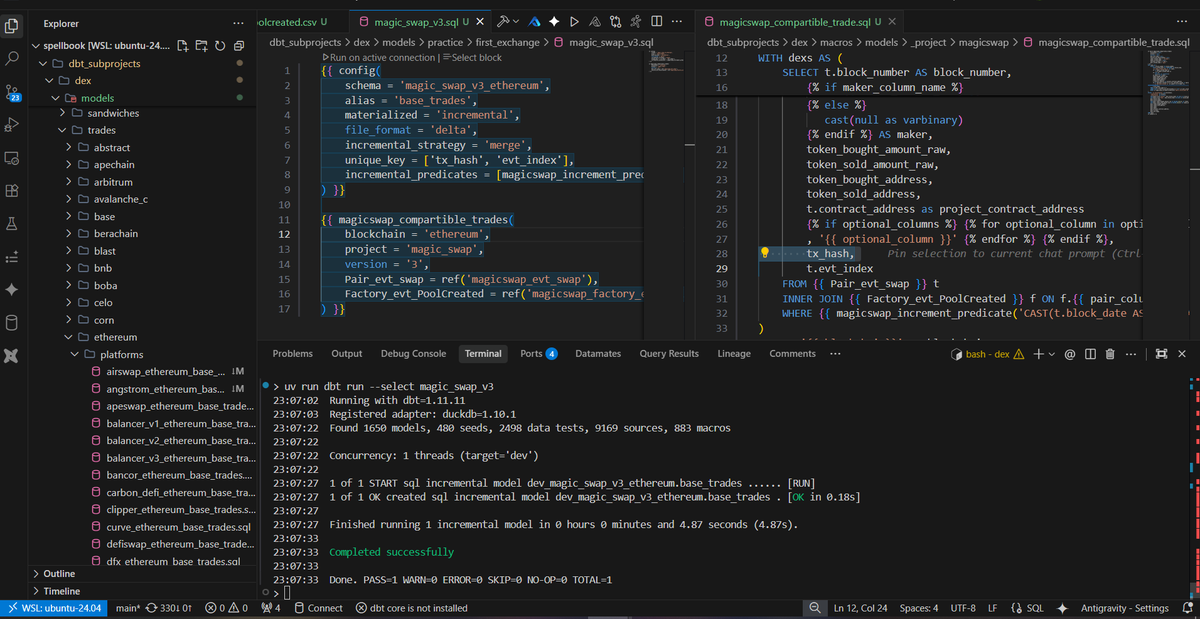
Currently diving into the @Dune Spellbook repo! This is the underlying foundation for the tables you query on the Dune web UI.
Every table is meticulously designed with one goal in mind: providing users with clean, easy-to-integrate datasets. #DataEngineering
1
1

Ever get confused by the different "Data" job titles? This infographic is for you.
The field of data is vast, and the roles within it are often misunderstood. While a Data Engineer, a Data Scientist, and a Data Analyst all work with the same raw materials, their educational discipline and focus are different:
🛠 The Data Engineer: Builds the infrastructure. They create and maintain the pipelines that gather, process, and store the raw data, ensuring its reliable and high-quality for everyone else. Think "Data Architecture".
🧠 The Data Scientist: Analyzes data to make predictions and uncover deep insights. They use advanced statistics and machine learning to build models that can forecast trends and automate decisions. Think "Predictive Modeling."
📊 The Data Analyst: Interprets historical data to inform business decisions. They create reports and dashboards to visualize what has already happened and identify why. Think "Business Intelligence."
Understanding these differences is crucial for:
Businesses trying to build the right team.
Job seekers deciding which path to pursue.
Anyone working in a modern, data-driven organization.
Check out the full infographic below for details on their focus, tools, and deliverables! 👇
#DataScience #DataEngineering #DataAnalytics #CareersInData #TechIndustry #BigData #BusinessIntelligence

25

We optimized AI models for years.
Now we're starting to optimize the documents AI reads.
That's the idea behind AI-native documents like DocLang.
The next AI advantage may not be better models.
It may be better data structures. 👀
#AI #DataEngineering #AIAgents

2

youtube.com/watch?v=AMKlYx4d…
Everyone wants to become an AI Engineer.
Very few understand how it differs from an ML Engineer.
The internet has made it look like learning a few prompts or using an LLM API automatically makes someone an AI Engineer.
Reality is very different.
Here's how I see it after 18 years in software architecture and engineering:
👉 ML Engineers build models.
👉 AI Engineers build intelligent systems.
An ML Engineer typically focuses on:
✓ Data Preparation
✓ Feature Engineering
✓ Model Training
✓ Evaluation
✓ Accuracy Optimization
✓ MLOps
The journey often looks like:
Data → Model → Prediction
An AI Engineer goes several layers beyond the model.
They build systems that combine:
✓ Documents
✓ Databases
✓ APIs
✓ Vector Databases
✓ RAG
✓ AI Agents
✓ Tool Calling
✓ Business Workflows
✓ Cloud Infrastructure
The journey looks like:
Data → Knowledge → Action
The biggest misconception today is that AI starts with models.
It doesn't.
Enterprise AI starts with data.
Before RAG...
Before Agents...
Before LLMs...
You need:
✓ Document Processing
✓ Data Quality
✓ Knowledge Extraction
✓ AI-Ready Data
That's why I believe most engineers learn AI backwards.
They start with prompts and models.
Enterprise AI starts with data, moves through intelligence, and ends with production systems.
For those asking how to become an AI Engineer, this is the roadmap I recommend:
🟢 Foundation Layer
Document Processing & AI-Ready Data
🟣 AI Application Layer
RAG, Agents & Intelligent Systems
🔵 Production Layer
MLOps, AWS & Kubernetes
I have been teaching this exact journey through:
📘 Getting Started with Document Intelligence (Free)
📘 AI Document Intelligence: RAG, Agents & ML Data
📘 AI System Design & MLOps: From Raw Data to AWS Kubernetes
One question:
Do you think the future belongs more to:
A) ML Engineers
B) AI Engineers
C) AI Architects
Curious to hear your thoughts.
#AIEngineer #MLEngineer #ArtificialIntelligence #MachineLearning #RAG #AIAgents #MLOps #SystemDesign #SoftwareArchitecture #AIArchitecture #GenerativeAI #DataEngineering #CloudArchitecture #ArchitectMindset
2
39

There are a lot of freaking data quality and data observability vendors (55... no, now 54) converged on capabilities, but almost all are too expensive.
hubs.ly/Q04kxTft0
#dataengineering #dataquality #dataobservability

3

There are a lot of freaking data quality and data observability vendors (55... no, now 54) converged on capabilities, but almost all are too expensive.
hubs.ly/Q04kxw7B0
#dataengineering #dataquality #dataobservability

9

There are a lot of freaking data quality and data observability vendors (55... no, now 54) converged on capabilities, but almost all are too expensive.
hubs.ly/Q04kxsBK0
#dataengineering #dataquality #dataobservability

6

🚀 Hiring software engineers now 👇
Twitch — Software Engineer, Creator Sponsorships (SF)
dailyjobpost.online/jobs/twi…
Airtable — Software Engineer, Data (SF / Austin / NY)
dailyjobpost.online/jobs/air…
#SoftwareEngineer #DataEngineering #Hiring #USJobs
18

The more I learn Databricks, the more I realize that progress is not about covering more topics. It is about understanding the fundamentals.
A few weeks ago, I was focused on advanced concepts like Delta Lake, data pipelines, and optimization. But recently, some of my biggest learning moments have come from working with simple CSV files, DataFrames, and schemas.
What surprised me most is how much depth exists in the basics. A simple question like "How does Spark identify data types?" can lead to a much deeper understanding of how everything works behind the scenes.
While learning, I have been spending time with Databricks notes from BricksNotes. They have helped me stay focused on understanding one concept at a time instead of jumping between dozens of resources.
One lesson has become very clear:
Understanding a concept is far more valuable than simply recognizing its name.
What basic Databricks concept turned out to be more important than you expected?
#Databricks #DataEngineering #PySpark #BigData #LearningInPublic #DataCommunity #BricksNotes

24

Posizione: Data Architect
Ente/Azienda: Centrico (Gruppo Sella)
Sede di lavoro: Torino
Contratto: Tempo indeterminato, full-time
Candidati qui: lavoroit.it/offerte/data-arc…
#DataArchitect #DataEngineering #CloudData #BigData #GruppoSella
17


valkey's api compatibility with redis matters less than understanding your caching strategy. lazy loading patterns, data structure selection, eviction policies... these drive real performance gains. design for access patterns first.
#DataStrategy #DataEngineering #PerformanceArchitecture #Redis
4

Every week there is a new headline:
“AI will replace software engineers.”
“New AI model beats previous benchmarks.”
“Companies are reducing hiring due to AI.”
But one thing I’ve noticed is that while AI is changing how we work, it is also creating new opportunities for those willing to adapt.
A few years ago, Cloud Computing transformed the industry.
Engineers who learned AWS, Azure, and GCP stayed relevant.
Today, AI is creating a similar shift.
The question is no longer:
“Will AI affect my job?”
The better question is:
“How can I use AI to become more productive?”
For Data Engineers, AI still needs:
✅ High-quality data
✅ Reliable pipelines
✅ Data governance
✅ Scalable infrastructure
✅ Cloud platforms
Without these foundations, even the most advanced AI model cannot deliver business value.
Technology has always evolved.
The winners are usually not the people who resist change.
They are the people who learn, adapt, and grow with it.
The future belongs to engineers who combine domain expertise with AI, not those who see them as competing forces.
#AI #DataEngineering #CloudComputing #AWS #Databricks #Technology #CareerGrowth
17

Why Data Products Need Stable Interfaces
Applications need stable interfaces. Not direct access to tables, schemas, and query logic.
That is what separates a data product from raw data.
#dataengineering #analyticsengineering #dataproducts #analyticsbackend #ai

ALT Applications should depend on interfaces. Not queries, tables, or schemas. The moment consumers depend on implementation details, every change becomes a breaking change. Gaur Data provides stable analytical interfaces between analytical data and the applications that consume it.
2
5

📊 Hiring: Data Platform Lead - Jump
📍 Remote (US) | 💼 Full-time | 🧑💻 Data Platform / AI / Snowflake | 💰 Competitive equity | 🕐 4 hours ago - June 14, 2026
Jump is transforming live sports fan engagement. The company's data platform is evolving into a scalable multi-tenant product powering analytics and AI decisions for sports teams.
📋 Responsibilities include:
- Own end-to-end data platform strategy: ingestion, multi-tenant infra, pipelines, BI layer.
- Drive AI-on-data layer with semantic models and LLM/agent access patterns.
- Productize integrations from diverse sources into repeatable patterns.
- Lead & grow data engineering team, set technical direction and standards.
- Hands-on with warehouse/transformation layer.
🔑 Requirements:
- 8 years data engineering 2 years leadership.
- Strong people management and talent development skills.
- Modern cloud DW/transform stack (Snowflake dbt preferred).
- Experience building AI on structured data.
- Scalable ingestion and multi-tenant data product experience.
- Strong engineering fundamentals.
💡 Perks:
- Remote-first, competitive salary equity, flex PTO, 401k, great health benefits, parental leave, WFH stipend.
📩 To apply: Apply directly via the original job link below.
🔗 Original post: jobs.ashbyhq.com/jump/e1ee92…
⚠️ DYOR! I don’t verify every job. If someone asks to run files (even from GitHub) or ask for payment 🚩 likely a scam.
❗️ I'm not hiring myself! I just sharing fresh web3/crypto/blockchain roles DAILY for all levels!
💡 For Interns & juniors → t.me/crypto_vazima_english
💼 Mid/senior jobs → t.me/web3_jobs_crypto_vazima
#DataEngineering #DataPlatform #Hiring #RemoteJobs #Snowflake #dbt #AI #Leadership #Web3 #Crypto #Blockchain #SportsTech #TechJobs #Engineering

1
48

🚀 AIDIRAC PRISM AI – BUILDING INDIA'S NEXT AI POWERHOUSE
The AI Revolution is just beginning.
After 32 years of experience in Enterprise IT, Cloud Computing, Data Engineering, Healthcare Technology, Research, Artificial Intelligence, and Digital Transformation, I am launching an ambitious initiative to build the AIDIRAC Prism AI Innovation Campus in Chennai.
━━━━━━━━━━━━━━━━━━━━
🏢 CHENNAI AI INNOVATION CAMPUS
📍 Defence Colony, Ekkattuthangal, Chennai
📐 6000 Sq.ft Prime Property Under Evaluation
🏠 Existing Ground First Floor Building
💰 Estimated Acquisition Opportunity: ~₹6.5 Crore
Our goal is to transform this property into a world-class AI Innovation, Development, Training, and Enterprise Delivery Center.
━━━━━━━━━━━━━━━━━━━━
🤖 WHAT WE ARE BUILDING
✅ Agentic AI Platform
✅ Enterprise LLM Solutions
✅ AI Voice & Business Agents
✅ Cloud & Data Engineering Services
✅ AI Research & Development Labs
✅ AI Training & Certification Academy
✅ Startup Incubation & Innovation Hub
✅ Global AI Delivery Center
✅ AI Solutions for Healthcare, Education, Retail & Enterprises
━━━━━━━━━━━━━━━━━━━━
📈 OUR GROWING ECOSYSTEM
🎯 20,000 AI Users & Community Reach
🎯 Growing Demand for AI Solutions
🎯 Global Interest in AI Transformation
🎯 Strong Focus on India & International Markets
━━━━━━━━━━━━━━━━━━━━
👨💻 WE ARE LOOKING FOR
AI Engineers
Python Developers
Full Stack Developers
LLM Engineers
Cloud Architects
Data Engineers
DevOps Engineers
UI/UX Designers
Digital Marketing Professionals
Students & Fresh Graduates
Startup Founders
Research Partners
━━━━━━━━━━━━━━━━━━━━
🤝 WE ARE ALSO LOOKING FOR
Strategic Investors
Enterprise Customers
Technology Partners
Educational Institutions
Government & Industry Collaborators
Global Business Partners
━━━━━━━━━━━━━━━━━━━━
👨👩👧👦 OUR MISSION
Create High-Quality AI Jobs
Support Families Through Employment
Train the Next Generation of AI Professionals
Build Scalable AI Products from India
Empower Startups & Innovators
Create Long-Term Economic Impact
━━━━━━━━━━━━━━━━━━━━
👤 ABOUT THE FOUNDER
32 Years of Experience Across:
✔ Enterprise Architecture
✔ Cloud Platforms
✔ Data Engineering
✔ Artificial Intelligence
✔ Healthcare Technology
✔ Research & Innovation
✔ Global Delivery & Transformation Programs
━━━━━━━━━━━━━━━━━━━━
🌍 WHY NOW?
AI is transforming every industry.
The next generation of companies will be AI-first.
India has the talent, market, and opportunity to become a global AI leader.
AIDIRAC Prism AI aims to be part of that journey.
━━━━━━━━━━━━━━━━━━━━
📧 Email: find@ngosys.com
📱 WhatsApp: 31 6 20856275
📢 Telegram: t.me/ThriveTVai
🌐 AIDIRAC.com
━━━━━━━━━━━━━━━━━━━━
If you are an AI developer, student, customer, startup founder, technology partner, or investor who wants to help build the future of AI, connect with us today.
Together, let's build the next generation of AI innovation from Chennai to the world.
#AIDIRAC #PrismAI #AI #ArtificialIntelligence #AgenticAI #LLM #StartupIndia #InvestInAI #AIJobs #Hiring #CloudComputing #DataEngineering #Innovation #Chennai #FutureOfWork #DigitalTransformation #IndiaAI #AIStartup

1
1
2
68

Tell me about her using Data terms:
I will start..
She was my VLOOKUP. Always found what i needed, in any table, any sheet. Then one day - value not found 🤣🤣
#dataanalytics #datascience #datajokes #datavisualization #datareporting #dataengineering
2
Early in my Data Engineering career, I thought success meant making the pipeline run successfully.
If the job completed without errors, I considered the work done.
Then I started working on larger datasets and production environments.
That’s when I learned the real meaning of optimization.
Imagine two engineers building the same pipeline.
Engineer A processes 500 GB of data in 4 hours.
Engineer B processes the same 500 GB in 40 minutes.
Both produce the same output.
But one solution saves time, cloud costs, infrastructure resources, and helps meet business SLAs.
That’s optimization.
Optimization is not about writing clever code.
It’s about thinking differently.
Can we process less data?
Can we avoid unnecessary shuffles?
Can we partition data better?
Can we reduce cloud costs?
Can we make the pipeline scale when data grows 10x?
As Data Engineers, we’re not paid just to move data.
We’re paid to move data efficiently.
Because in the real world, business leaders don’t ask how many lines of code we wrote.
They care about:
✅ Performance
✅ Reliability
✅ Cost
✅ Scalability
A pipeline that works is good.
A pipeline that works efficiently is engineering.
#DataEngineering #PySpark #SparkOptimization #AWS #Databricks #BigData #CareerGrowth
13

Why Proxy Transparency Matters: What Businesses Should Look for in 2026 👇
#WebScraping #Automation #Proxy #SaaSProducts #DataEngineering #CompetitiveIntelligence #DataCollection #Founders #CEOs #StartUps

8
1
17

Migrating desktop GIS models to SQL is not a lift-and-shift.
It is a redesign.
The old model says:
run this tool
then this overlay
then this join
then this export
The SQL pipeline asks a different question:
can this workflow become repeatable, testable, and scalable?
That means breaking the model into atomic spatial operations:
select by location
spatial join
buffer
clip
dissolve
aggregate
validate
The future of GeoAI is not just smarter models.
It is reliable spatial infrastructure behind them.
#GeoAI #GIS #SpatialSQL #Geospatial #DataEngineering
10