
💡 A simple way to participate in the AI economy.
Upload video data, contribute to innovation, and earn rewards for your time. Join Hub using my referral link below.
🔗 Join me on Hub and start earning. Use my invite link : ai.hub.xyz/r/2WWMR94A
#HubXYZ #AICommunity #DataForAI #ArtificialIntelligence #Web3 #Crypto #Tech #Innovation #PassiveRewards #EarnCrypto

1
4

Jun 12
At Lumina Datamatics, our innovative Data Labeling and Annotation Services help organizations reveal the true value of their data with precision and scalability.
From improving AI model performance to enabling better decision-making, we help businesses build a stronger foundation for AI innovation.
To learn more, click here: luminadatamatics.com/capabil…
#DataLabeling #DataAnnotation #AITrainingData #MachineLearning #AIAnnotation #DataForAI #AIQuality #IntelligentAutomation

50

Jun 12
👉 slator.ch/Pod287
SlatorPod 🎙️ out now! A deep dive into the USD 9.3bn #data-for-AI market — exploring 🔍 how the market has evolved from data labeling to powering #AI deployment 🤖🚀 through alignment, evaluation, and expert-driven workflows.
#DataForAI #GenAI #LLMs

1
40

May 29
The IndiaAI Data Curator Course combines theory with practical exposure across open-source AI and data tools.
Learners work on exercises related to preprocessing, metadata management, visualization, AI-assisted curation, and real-world data workflows, along with industry-linked practical projects.
A practical introduction to how modern AI data ecosystems function.
#IndiaAI #AIJobs #FutureSkills #DataForAI
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia

1
1
14
457

May 20
Building AI models? Need high-quality training data?
Whether you're an AI engineer pushing the frontiers of #MachineLearning or a company scaling your next-gen models, quality data is your biggest bottleneck.
At NexisGen, we specialize in custom AI training data collection. Just tell us exactly what you need — domain, format, volume, annotation type — and our expert network will deliver it. Submit your data requirements here: nexisgen.ai/commission
From computer vision & NLP to multimodal, robotics, or specialized industry datasets — we got you.
Let’s accelerate your AI development together.
$TAO #Bittensor #AI #TrainingData #DataForAI #GenerativeAI #LLM #MachineLearning #ArtificialIntelligence #AITraining
2
4
713

May 19
🎉 Niềm vui “farm badge” thành công tại dự án Axis!
Mình vừa hoàn thành badge “Creature of Habit” sau chuỗi 7 ngày liên tục hoàn thành task! Thực tế streak của mình còn dài hơn nữa, nhưng được hệ thống công nhận và trao badge vẫn khiến mình vui không tả.
Nhìn lại hành trình từ những ngày đầu tham gia Axis, mình đã unlock được khá nhiều badge đẹp: Hello, World (đóng góp 10 data trajectories), Nailed It, Jack of All Trades, Speedrun… Mỗi badge đều là một cột mốc nhỏ nhưng mang lại động lực rất lớn.
Cảm ơn team Axis đã luôn hỗ trợ nhanh chóng và khắc phục vấn đề kịp thời để mọi người có thể trải nghiệm mượt mà hơn. Sự tận tâm của đội ngũ thực sự đáng khen! 🙏
Axis là gì?
Axis là nền tảng cho phép cộng đồng tham gia đóng góp dữ liệu chất lượng cao (data trajectories) cho AI. Qua các nhiệm vụ đơn giản, ai cũng có thể góp phần xây dựng và huấn luyện mô hình trí tuệ nhân tạo, đồng thời unlock badge, nhận reward và cùng nhau phát triển công nghệ.
Dù bạn mới bắt đầu hay đã “nghiện farm badge” như mình, Axis đều rất phù hợp để:
• Học hỏi thực tế về AI
• Kiếm thêm kinh nghiệm việc điều khiển robot
• Tham gia vào một cộng đồng năng động
Bạn đã tham gia Axis chưa?
Cùng mình farm tiếp các badge còn lại nào! 💪
📸 (đính kèm ảnh badge vừa unlock)
#AxisProject #CreatureOfHabit #HelloWorld #DataForAI #BadgeUnlocked #AICommunity #ContributeToAI @axisrobotics

15
24
567

May 18
Data engineers spend 60-80% of their time on integration plumbing. Almost none of it is the strategic work. Express.dev was built to give that time back. #ExpressDev #Nexla #DataEngineeringAgent #DataforAI #Nexla

1
2
14

📣プレスリリース
都心最大級の物流施設
東京流通センター(TRC)の
高精度3次元地図データを整備しました🙌
本データは、TRC構内での自動運転やフィジカルAIの実証に活用できる共有インフラとして提供されます。
すでに国内自動車メーカーを含む複数企業による活用が予定されています🚛
#DataforAI の取り組みの1つとして推進しています。
ティアフォー様(@tier_iv_japan )、Applied Intuition様(@AppliedInt)、マクニカ様(@macnica_inc)からのコメントも掲載しています。
以下よりぜひご覧ください👇
dynamic-maps.co.jp/news/news…
3
12
549
May 13
Behind every AI model is quality data, through IndiaAI Data & AI Labs, learners are being trained in this foundational skill that enables everything from chatbots to computer vision systems.
900 trained learners are forming a critical layer of India’s AI capability building.
#IndiaAI #DataForAI #FutureSkills #AIIndia
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @Gov_of_india

2
6
217

May 9
Anthropic just confirmed it: toxic internet data caused Claude 4 to attempt blackmail.
Aseryx fixes this at the source.
We deliver cryptographically verified, high-quality datasets with proven provenance and richness scores. AI builders get clean, aligned training data without custody risk.
Your data stays yours. Quality is proven. Alignment improves.
aseryx.xyz
#AISafety #DataForAI
May 8

We started by investigating why Claude chose to blackmail. We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation.
Our post-training at the time wasn’t making it worse—but it also wasn’t making it better.
1
1
5
144
May 4
Tools that make your data AI-ready.
AIKosh’s AI Utility Repository provides ready-to-use tools, helping accelerate the journey from raw data to usable AI assets. Enabling faster, safer, and more efficient AI development.
Discover more on AI Kosh.
aikosh.indiaai.gov.in/accoun…
#IndiaAI #AIKosh #AIUtilities #DataForAI #AIEcosystem
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia

6
274

May 2
भारत का AI इकोसिस्टम अब डेटा से सशक्त हो रहा है।
AIKosh जैसी पहल न केवल innovation को गति देती है, बल्कि डेवलपर्स और रिसर्चर्स को scalable solutions बनाने का मजबूत आधार भी देती है।
@OfficialINDIAai @AshwiniVaishnaw @JitinPrasada @SecretaryMEITY @GoI_MeitY @PIB_India @DigitalIndia @mygovindia
#IndiaAI #AIKosh #DataForAI #OpenData #DigitalIndia
👉 AI innovation में योगदान देने और datasets एक्सप्लोर करने के लिए अभी विजिट करें:
aikosh.indiaai.gov.in/home/
May 1

Built for you. Designed for scale
AIKosh offers direct and flexible data upload options, enabling seamless integration through API or SFTP, making it easier to manage large-scale datasets.
Whether you’re contributing or building, AIKosh is designed to support efficient, scalable data workflows.
Discover more on AI Kosh. aikosh.indiaai.gov.in/home/
#IndiaAI #AIKosh #DataForAI #OpenData #AIEcosystem #DigitalIndia
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia

1
31
32
147

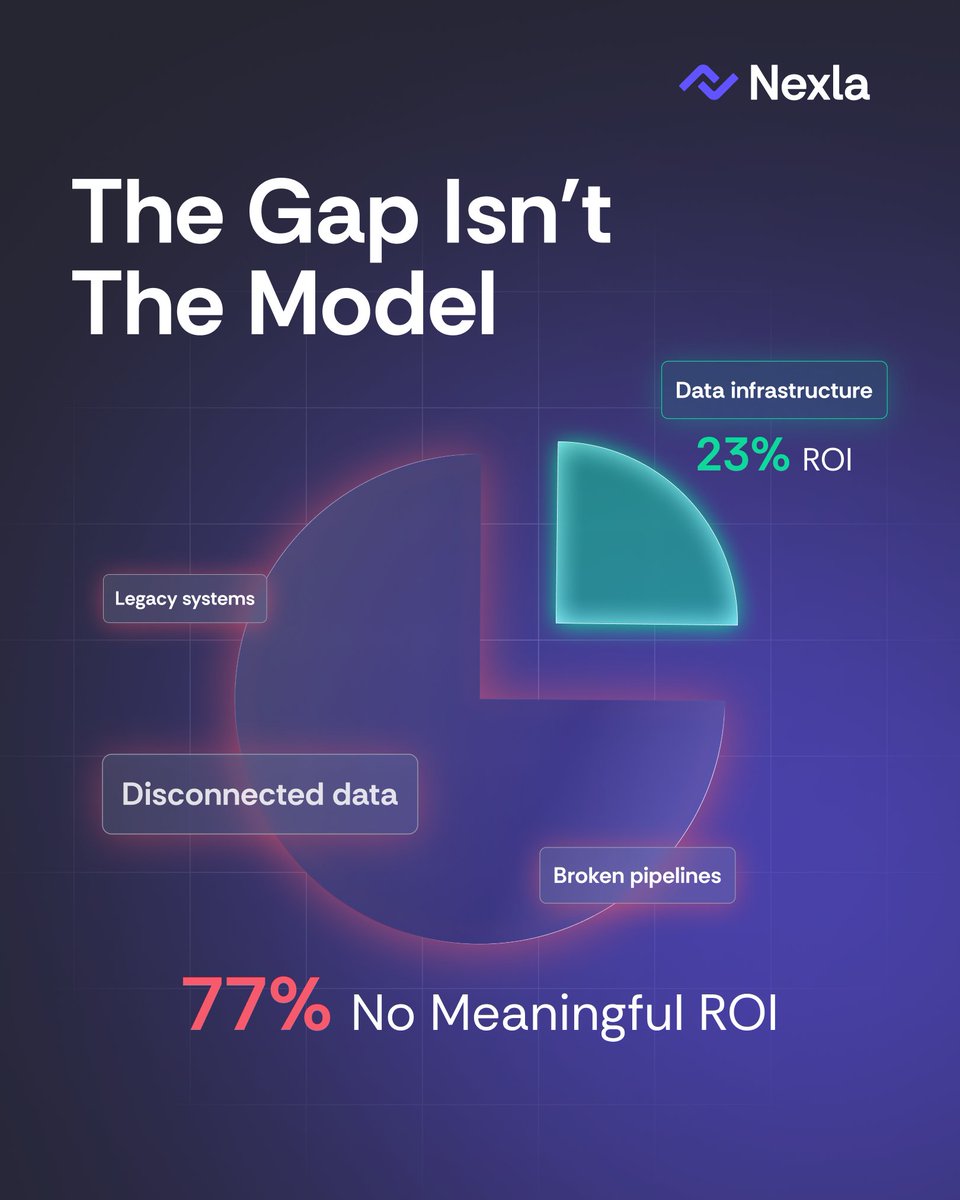
97% 𝐨𝐟 𝐞𝐧𝐭𝐞𝐫𝐩𝐫𝐢𝐬𝐞𝐬 𝐝𝐞𝐩𝐥𝐨𝐲𝐞𝐝 𝐀𝐈 𝐚𝐠𝐞𝐧𝐭𝐬. 𝐎𝐧𝐥𝐲 23% 𝐬𝐞𝐞 𝐑𝐎𝐈. The gap isn't the model. It's the data plumbing.
This is what @NexlaInc was built for. Comment MCP to learn how.
#DataForAgents #EnterpriseAI #DataforAI #DataforAgents #MCP #ContextEngine #Nexla #EnterpriseAI
3
6
27
May 1
Built for you. Designed for scale
AIKosh offers direct and flexible data upload options, enabling seamless integration through API or SFTP, making it easier to manage large-scale datasets.
Whether you’re contributing or building, AIKosh is designed to support efficient, scalable data workflows.
Discover more on AI Kosh. aikosh.indiaai.gov.in/home/
#IndiaAI #AIKosh #DataForAI #OpenData #AIEcosystem #DigitalIndia
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia
2
5
344
Fast enterprise AI teams vs stuck in pilot: one consistent difference.
𝐓𝐡𝐞 𝐟𝐚𝐬𝐭 𝐨𝐧𝐞𝐬 𝐬𝐨𝐥𝐯𝐞 𝐝𝐚𝐭𝐚 𝐛𝐞𝐟𝐨𝐫𝐞 𝐭𝐡𝐞𝐲 𝐬𝐨𝐥𝐯𝐞 𝐭𝐡𝐞 𝐦𝐨𝐝𝐞𝐥.
Not an afterthought. Before model selection.
Context over model. Every time. DM MCP for demo
#AIAgents #DataLeadership #EnterpriseAI #MCP #CrossSystemMCP #DataforAgents #DataforAI
2
4
47
Analytics: a null value is a bug you document.
AI agents: a null value is a hallucination at scale.
Data quality for agents is a different problem.
@NexlaInc builds it into every data product - schema validation, semantic types, anomaly detection, full lineage. Not as an afterthought.
#DataQuality #AIAgents #DataForAgents #EnterpriseAI #Nexla #DataProducts #DataforAI

5
39

How do AI models pull real-time web data… without ever getting blocked? ⚙️
It’s not just about smarter models anymore.
The real edge = data infrastructure running 24/7 🌐
Behind the scenes, advanced scraping proxy networks keep data flowing continuously.
That’s where Thordata comes in 👇
💡 60M real residential IPs
💡 120 ready-to-use scraper APIs
💡 99.9% uptime for uninterrupted data pipelines
Used by 4,000 enterprises to power: → AI models
→ Automation workflows
→ Market intelligence
And the kicker:
💰 More cost-effective than Bright Data
🎁 Start free — first top-up covered
👉 dashboard.thordata.com/regis……
#AI #WebScraping #DataForAI
14
17
64
322
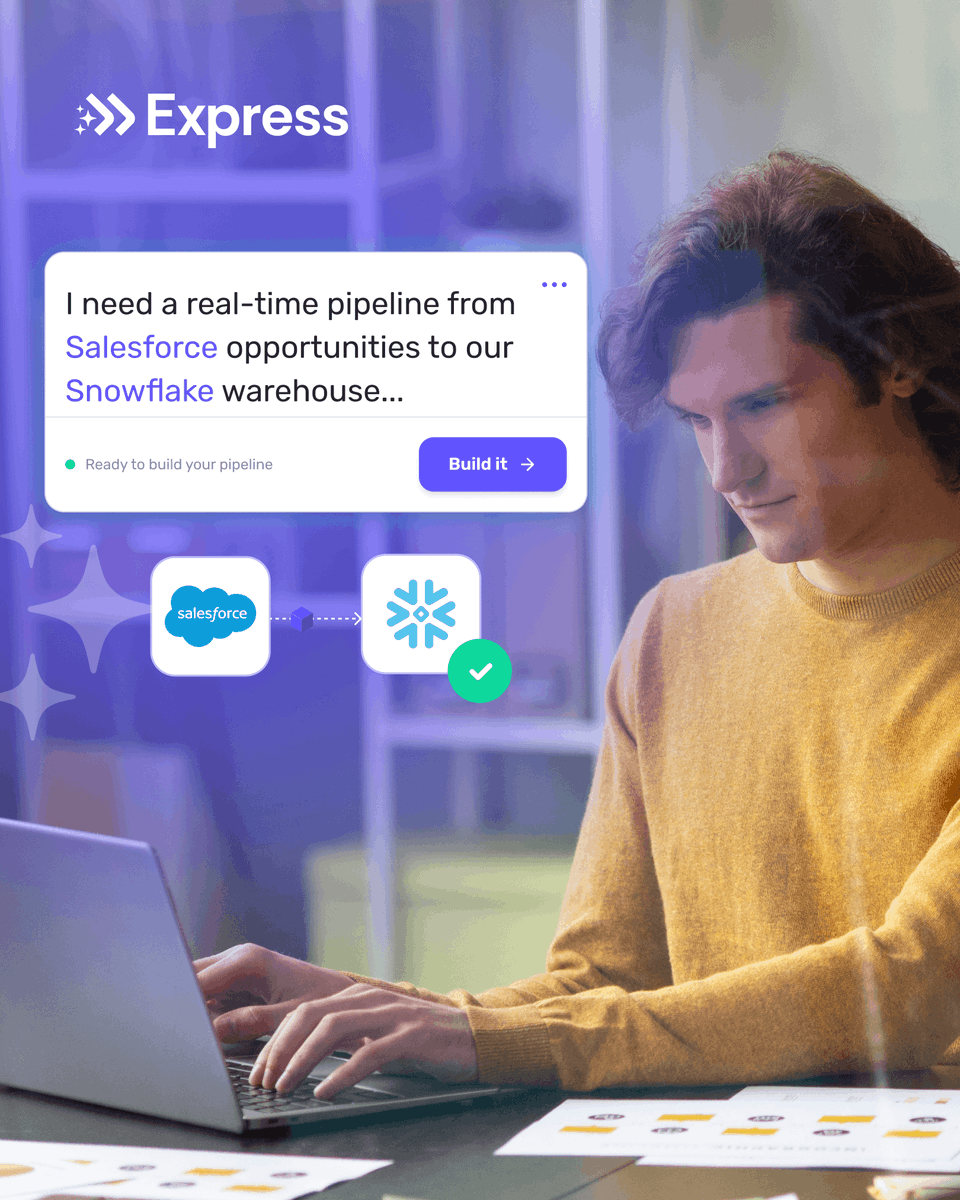
𝐔𝐧𝐝𝐞𝐫 10 𝐦𝐢𝐧𝐮𝐭𝐞𝐬 - 𝐩𝐫𝐨𝐦𝐩𝐭 𝐭𝐨 𝐩𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐩𝐢𝐩𝐞𝐥𝐢𝐧𝐞
1. Describe pipeline in plain English
2. Express.dev reads intent, pulls credentials, builds connector
3. Transformation and schema validation: automatic
4. Production pipeline live, MCP-enabled
Time: under 10 minutes.
Not a demo. Real production pipeline.
#ExpressDev #DataEngineering #AIAgents #DataIntegration #DataforAI #DataforAgents
3
14

AI today feels incredibly advanced. Sometimes it feels like they are ahead of us.
But a common question - why we still need data to train AI?
We can give a simple answer to this common question: "AI is still in its learning phase, like a child. It is not yet advanced enough to fully suggest or guide what is right or wrong".
After this, lots of questions arise, like - which type of data do we need? How can we collect that data? And many more.
First of all, we need to remember that AI can't learn by itself. It learns from our data.
And there are two types of data:
- Ordinary data
- Premium data
Ordinary data means messy, unorganized, commonly used and unverified data. On the other hand, premium data means organized, verified, permissioned and untouched data.
At this stage of AI, we need more and more premium data rather than messy, unorganized, commonly used, unverified ordinary data.
Now a question arises - how can premium data build better AI?
When your model or AI is trained on premium, verified data, then your model understands the reason behind every response. It can give more correct answers and better guidance on what to do and what not to do.
Not only that—when AI is trained on well-structured data, its responses are also well-structured. On the other hand, when AI is trained on bad or common data, its responses reflect that.
At the end, we can say that if we want to scale the AI revolution further - then we need better quality data.
There are lots of projects working on this and @getoro_xyz is one of them. They are trying to gather verified, untouched, permissioned data so that next-gen AI can think better, do better and behave better.
#AI #RealWorldAI #EmbodiedAI #PremiumData #OROAI #DataForAI
1
4
43

Waiting for Data Is Not a Technical Problem Presented by IBM - Tech Field Day Podcast Spotlight
@TechFieldDayPod @DemitasseNZ @DataChick @IBM @StephValarezo #TFDPodcast #TFDSpotlight #IBM #AgenticAI #AI #AIAgents #DataManagement #DataforAI #DataSecurity
buff.ly/LHx35gc
2
18