Alex Nguyen retweeted

Nobody told me about this.
10 free courses to learn AI agents from scratch. right now.
Hugging Face. Microsoft. DeepLearningAI. Google Cloud. Anthropic.
if I had to restart today, this is my entire curriculum:

1
1
59

Apr 5
Day 4 of AI Learning 🌱
Today: Deep Learning in Agriculture 🚜
AI can now: • Detect crop diseases from images
• Predict yield using data
• Identify weeds automatically
• Optimize irrigation systems
Deep Learning = Smarter Farming Better Results
#AI #Agriculture #DeepLearnin



2
10

2 Dec 2025
🔥 Meta just released a hard-hitting reality check on scaling LLM training and it’s not the story we’ve been telling ourselves.
If you’ve been assuming that “just add more GPUs” is the golden path to faster, cheaper training… this new study from FAIR turns that idea upside down.
In this paper, Meta dissects what really happens when you scale LLM training across thousands of accelerators and the findings are surprisingly counter-intuitive:
💡 Key Insights:
- Diminishing returns kick in fast.
Beyond a certain scale (≈128 H100s), training becomes communication-bound, not compute-bound — meaning GPUs sit idle waiting for parameters to sync.
- FSDP isn’t magic at massive scale.
Fully Sharded Data Parallelism introduces heavy AllGather / ReduceScatter operations that scale poorly, causing performance slowdowns even as hardware grows.
- Model parallelism comes back into the spotlight.
Contrary to old assumptions, adding tensor or pipeline parallelism can improve throughput under FSDP by reducing communication groups.
- More power consumed, fewer tokens processed.
Power draw scales linearly, but throughput doesn’t — meaning energy efficiency drops as the cluster gets bigger.
- Hardware progress isn’t solving the bottleneck.
H100s offer 3× compute over A100s… but NVLink and interconnect bandwidth haven’t kept up. So communication overhead only gets worse.
- Larger models = proportionally larger communication tax.
Scaling from 7B → 70B expands compute and communication, shrinking hardware utilization even further.
To summarize, this paper is a complete guide on:
• Why communication, not compute, is now the real bottleneck
• How model parallelism can counteract FSDP overhead
• Why training efficiency collapses at massive scale
• What future hardware software need to fix
• Practical takeaways for anyone building LLM training stacks
This study is an important reminder:
Scaling isn’t just about FLOPs, it’s about balancing compute, memory, networking, and communication efficiency. If we don’t rethink parallelism strategies now, bigger clusters will only give us smaller returns.
#MetaAI #LLMTraining #FSDP #ParallelComputing #AIInfrastructure #DeepLearnin #MachineLearningResearch #AIEngineering #ScalingLLMs #TechInsights

1
1
1
858

25 Aug 2025
Do python, then it's libraries like numpy, pandas, matplotlib, seaborn,etc,
Then jump into ML, we have majority of the maths down, follow a course like andrew ng or a book (our library has a lot, pick any), do it's algorithms, practice on kaggle, then u progress into deepLearnin
1
4
58

13 Jun 2025
The capabilities are increasing day by day.
#AI #ArtificialIntelligence #GenerativeAI #MachineLearning #DeepLearnin #AIEthics #FutureOfAI #AITools #TechInnovation
2
3
1,118

21 May 2025
AI isn’t thinking better,
We’re just training it smarter.
Let’s unpack how human-in-the-loop (HITL) makes the difference.
#Deeplearnin
#AIinNigeria
#OpensourceAI
#DataLabeling
#MachineLearning
#Annotifai




2
1
2
14

19 Mar 2025
No robotic voices here.
@NovaHFAI and @AuroraHFAI will sound hyper-realistic, adjusting tone and emotion in real time. AI that actually FEELS real.
$SOL $ETH #AI #Tech #DeepLearnin
4
201

2 Aug 2024
Composio: An Open-Sourced Production Ready Toolset for AI Agents
itinai.com/composio-an-open-…
#AIintegration #Composio #IntelligentAgents #AIsolution #ToolIntegration #ai #news #llm #ml #research #ainews #innovation #artificialintelligence #machinelearning #technology #deeplearnin…
2
92
27 Apr 2024
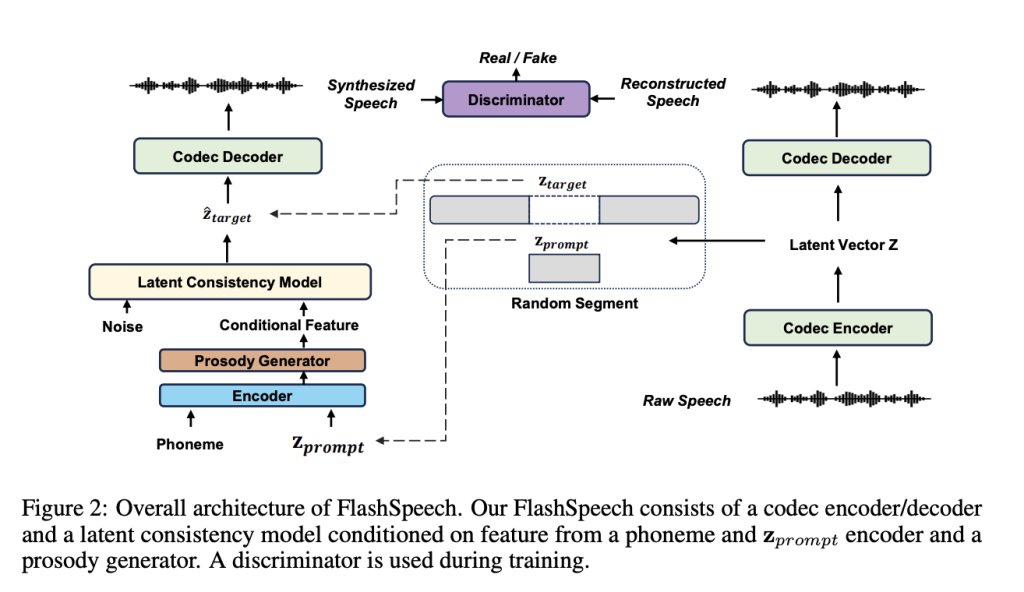
FlashSpeech: A Novel Speech Generation System that Significantly Reduces Computational Costs while Maintaining High-Quality Speech Output
itinai.com/flashspeech-a-nov…
#ai #news #llm #ml #research #ainews #innovation #artificialintelligence #machinelearning #technology #deeplearnin…
1
77

17 Feb 2024
H O T L I N K I N B I O
M Y T I T S I N B I O
--------
Probando el nuevo SEO pro-power Twitter deepLearnin' algorithm.
3
7
691



Computing Linkage Disequilibrium Aware Genome Embeddings using Autoencoders #deepLearnin biorxiv.org/content/10.1101/…
1
3
386

3 Apr 2023
Has GPT-4 really passed the startling threshold of human-level artificial intelligence? Well, it depends - The Conversation Indonesia
Read more here: ift.tt/4AhgCQc
#ArtificialIntelligence #AI #DataScience #100DaysOfCode #Python #MachineLearning #BigData #DeepLearnin…
176
28 Mar 2023
Most Jobs Soon To Be ‘Influenced’ By Artificial Intelligence, Research Out Of OpenAI And University Of Pennsylvania Suggests - Forbes
Read more here: ift.tt/BDAoTpr
#ArtificialIntelligence #AI #DataScience #100DaysOfCode #Python #MachineLearning #BigData #DeepLearnin…
75

2 Jan 2023
There is no reason and no way that a human mind can keep up with an artificial intelligence machine by 2035.
inductusgroup.com
#Inductusgroup #Inductusjobs #Artificial #Intelligence #Dataanalysis #Datascience #AI #Robotics #5G #technology #VR #Blockchain #Deeplearnin

1
3
47

31 Dec 2022
Artificial Intelligence Without The Right Data Is Just... Artificial
forbes.com/sites/joemckendri… @joemckendrick
#AI #MachineLearning #DataScience #IoT #100DaysofCode #womenwhocode #serverless @anijov @FmFrancoise @CatherineAdenle @Shi4Tech @enilev #BigData #Analytics #DeepLearnin
1
2
51

18 Dec 2022
これなのでステレオカメラ派閥
まぁGPUについてはCPUより消費電力あたりの性能は高いからありではあるとは思うけれど, DeepLearninで済むならそれが一番少なくなりがち
18 Dec 2022

やっぱり3次元LiDARは,近場のセンシングがかなり粗いな.自動運転とかの規模ならいいけど,移動ロボットに載せるには微妙過ぎると思うけどどうなんだろ.3次元LiDARやGPUは基本的に実用を考えるとコスト的にもバッテリ消費的にも,絶対載せない方がいいと思うし.
2
3
959

29 Nov 2022
shares every time you buy pet food
share.acorns.com/iinvest56
#CMC🍎#BabyDogeArmy
#bitburn🐈#cars #AI
#Python🐷 #DeepLearnin
1
1

17 Nov 2022
Top story: @amli_art: 'shut. the. front. door.
This is insane. A system to decode visual stimuli from brain recordings.
So you're saying...in ten years...it'll be thought to image?
link to paper🧵
#ai #deeplearnin… x.com/amli_art/status/159297…, see more tweetedtimes.com/v/ai?s=tnp

2

16 Nov 2022
Top story: @SoBigData: 'The SoBigData.it PNRR Kick-off Meeting in Rome has just started, Roberto Trasarti is introducing the SoBigData #ResearchInfrastructure
#BigData #ArtificialIntelligence #AI #DeepLearnin… x.com/SoBigData/status/15928…, see more tweetedtimes.com/v/21745?s=t…


2
3