
Joined March 2013
- Tweets 59,846
- Following 941
- Followers 227,215
- Likes 7,137
12,729 Photos and videos










Pinned Tweet

The May 5th cohort is 6 days away. 10 weeks. 12,000 alumni. Spots are filling fast.
The Agentic AI Bootcamp is back and it covers the full stack of what matters right now.
Week 1, you're wrapping your head around how Transformers actually work.
Week 3, you're building with LangChain and setting up your first vector database for a RAG pipeline.
By week 5, you're not just prompting. You're engineering context and designing systems using Agentic design patterns used in production.
Week 7 hits and you're implementing Model Context Protocol and learning how agents actually talk to each other.
Week 10? You ship a multi-agent LLM application. From scratch. In 10 weeks.
That's what the Agentic AI Bootcamp cohort starting May 5th looks like. 3 hours a week, structured to take you from foundations to deployment.
Register now before it's too late: hubs.la/Q04dShn50
#agenticai #rag #aibootcamp #vectordatabases

1
7
21
5,440
🤔 You picked the best model on the market. Your app still gives inconsistent answers, forgets context mid-conversation, and breaks when real users show up.
The problem isn't the LLM. Swipe through to see what's actually going wrong - and why so many AI apps in 2026 are failing for the same reason.
Once you see it, you can't unsee it.
If you're ready to fix the layer most builders ignore, our Agentic AI Bootcamp starts July 14.
10 weeks, instructor-led, built for practitioners who are done debugging symptoms and want to fix the root cause. Link in the replies.
#ContextEngineering #AgenticAI #LLMDevelopment #AIEngineering #DataScienceDojo


2
3
8
786
We have a dedicated module on context engineering, explore it here: hubs.la/Q04lgzK70
2
492
Before you commit to a bootcamp, come see exactly what you're signing up for.
Choosing the right program is a big decision — so we're making it easier. Join Raja Iqbal live for an information session on the Agentic AI & LLM Bootcamp, where you can explore the full curriculum, understand what the learning journey looks like, and get every question you have answered in real time.
No pressure. Just clarity.
📅 June 29, 2026 | 12:00 – 1:00 PM PT
🔗 Registration now: hubs.la/Q04lfw5W0
1
4
688
🚨 AI agents score 2.6% on real work tasks. That's the finding from Agents' Last Exam (ALE), a new benchmark from UC Berkeley.
Most AI benchmarks test things like math competitions or coding challenges. ALE tests something different - can an agent actually do the work a professional does? Think filing a clinical report, running a chip signoff, generating a CNC toolpath, or scheduling a manufacturing work order.
What's in it:
- 1,490 tasks across 13 industries - engineering, finance, healthcare, legal, 3D/animation, and more
- Built with 250 industry experts
- Every task has a verifiable outcome, so scoring isn't subjective
- The task pool keeps growing as new industries are added
The core argument:
AI keeps acing benchmarks. But those wins haven't shown up in how industries actually work. The paper argues that's because benchmarks have been testing the wrong things. If you want agents that are useful in the real world, you need to evaluate them on real-world work.
The 2.6% score isn't surprising - it just shows how big the gap still is between "impressive demo" and "reliable enough to deploy."
For practitioners: If you're building or evaluating agents for any vertical use case, ALE gives you a more honest picture of where things stand than leaderboards built on academic datasets.
#AIAgents #AIBenchmarks #ALE #AgentEval #DataScience #AIEngineering
2
8
16
1,475
LLM agents that can act on your system are powerful.
They're also a security risk without the right guardrails.
Docker Sandboxes fix that — isolated environments, real-time permission controls, safety patterns built in.
Live session with Dan Ndombe — June 24, 1PM PT.
👉 Register now: hubs.ly/Q04l5Klq0
#LLMAgents #Docker #AISecuirty #AIAgents #MachineLearning #Python
3
1
6
757
Eye-balling outputs is where most of us start. It's just not where we should stay.
At some point your model goes into something real - a RAG pipeline returns a wrong answer confidently, a prompt change quietly degrades quality, or you switch providers and can't tell if anything held up. "It seemed fine in testing" stops being enough.
Turns out, LLM evaluation is its own skill set. And once you know what the toolkit looks like, you can actually answer the question.
👇 Swipe through to see how practitioners approach it - and if you want to build real eval pipelines yourself, our Agentic AI Bootcamp starts July 14. Link in the comments.
#LLMEvaluation #AgenticAI #RAGPipelines #DataScienceDojo #AIEngineering



4
5
13
3,381
We have everything: from context engineering to building a multi-agent application. Explore our curriculum here: hubs.la/Q04l5Stg0
1
3
2,904
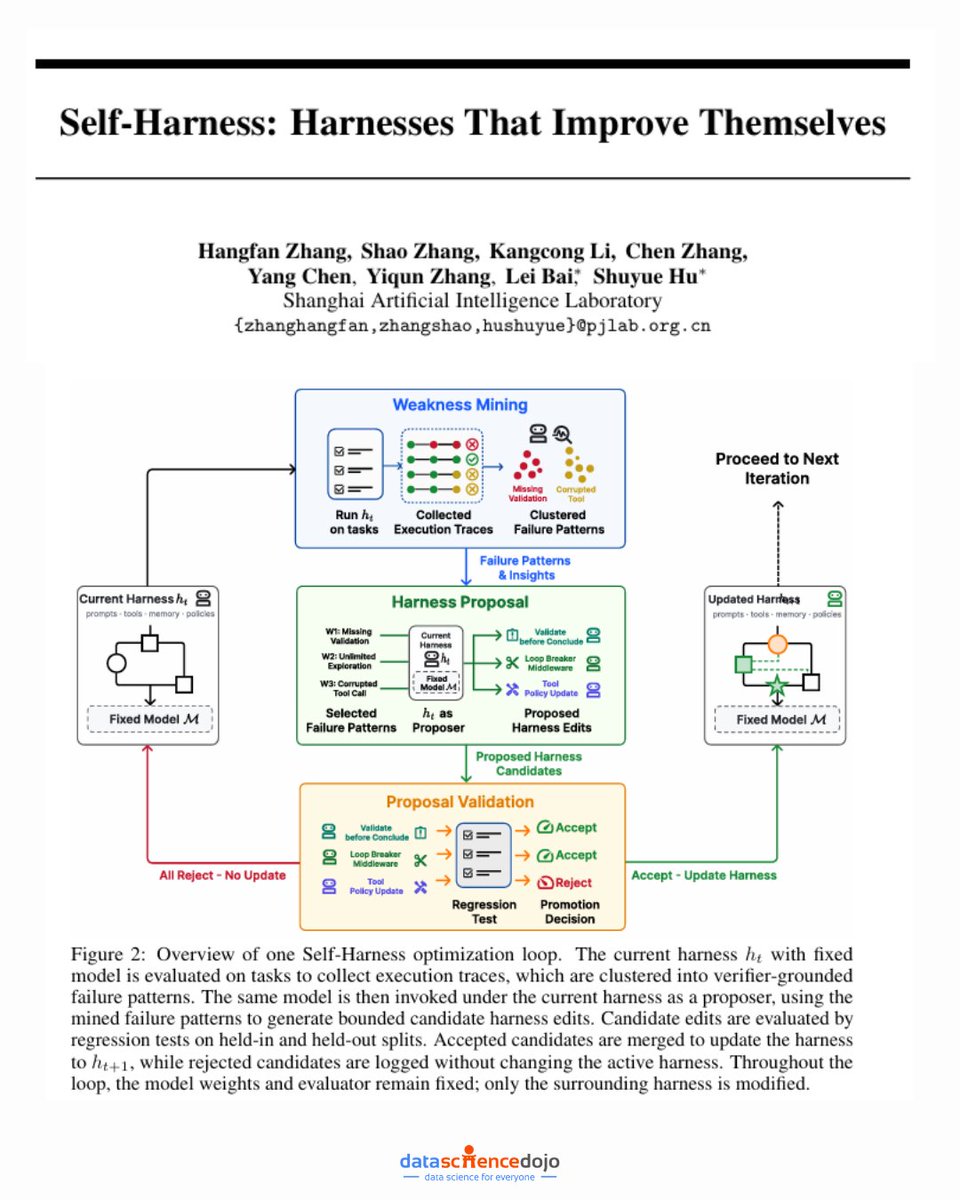
🤔 Your agent's harness is probably slowing it down. And until now, fixing that required a human engineer.
Self-Harness is a paper out of Shanghai AI Lab that lays out a concrete process for letting an LLM agent rewrite its own operating harness - the system prompts, tools, runtime rules, and recovery logic that sit between the model and the environment.
The process runs in three stages:
- Weakness Mining - the agent runs on a set of tasks, then clusters its own failed execution traces to find recurring failure patterns (not one-off mistakes)
- Harness Proposal - based on those patterns, it generates small, targeted harness edits, each tied to a specific failure mechanism, kept minimal on purpose
- Proposal Validation - candidate edits only get merged if they pass regression tests without degrading performance on held-out tasks
They tested this on Terminal-Bench-2.0 with three models from different families. The held-out results:
- MiniMax M2.5: 40.5% to 61.9%
- Qwen3.5-35B-A3B: 23.8% to 38.1%
- GLM-5: 42.9% to 57.1%
The practical takeaway: if you are building agent systems, the harness deserves as much attention as the model. This paper gives you a process for doing that at scale.
#harnessengineering #aiagents #aiengineering #agenticai
3
7
14
2,142
Multi-Agent Systems & Workflow Orchestration: Why Solo Agents Fail to Scale x.com/i/broadcasts/1yKAPPbZm…
3
3
10
3,687
Master Large Language Models from the ground up - join the bootcamp! hubs.la/Q04kNqT-0
1
1
1,703
Data Science Dojo retweeted

Jun 10
Un orchestrateur IA fiable ne s'arrête jamais : si une sous-tâche échoue, il replanifie et change d'agent.
via @DataScienceDojo
#IA

ALT Flowchart titled "How the Orchestrator Works." A high-level goal or prompt enters the system and goes to an Orchestrator, which decomposes it into sub-tasks (A, B, C) and routes each to the right AI agent: a Research Agent, a Writer Agent, and a QA Agent. Each agent sends a result back. If a sub-task fails, a "Replan?" decision lets the orchestrator take an alternative path and retry with a different agent or approach instead of halting. The validated results are combined into the final Output.
1
5
14
822
Data Science Dojo retweeted

Top AI Agentic Design Patterns
Source: @DataScienceDojo
#GenerativeAI #GenAI #LLM #LargeLanguageModel #AI #python #ml #BigData #datascientist #artificialintelligence #NaturalLanguageProcessing #data #AgenticAI #AppliedAI #Automation #machinelearning #deeplearning #AIAgents

1
13
37
1,790
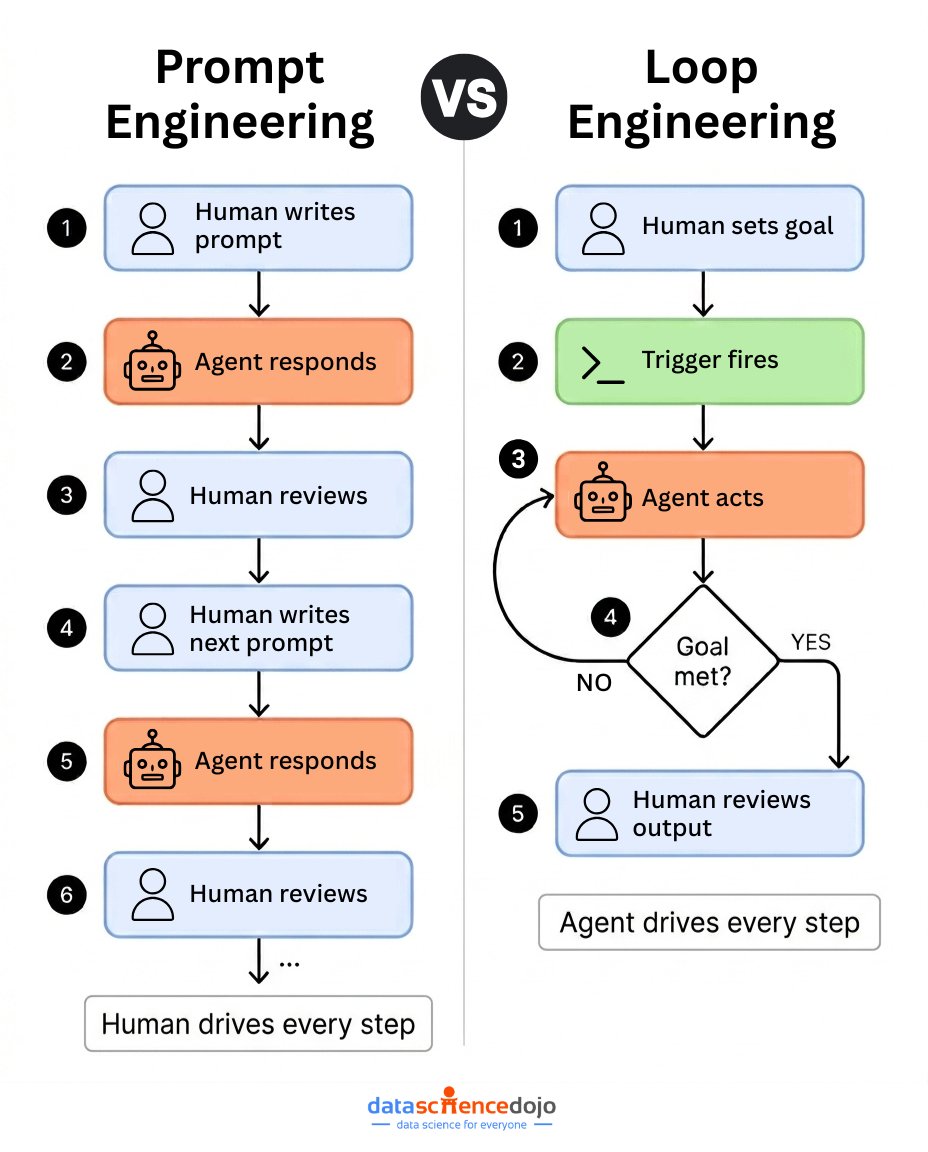
💡 Peter Steinberger put it plainly: "You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
Boris Cherny, head of Claude Code at Anthropic, backed it up: "I don't prompt Claude anymore. I have loops running that prompt Claude. My job is to write loops."
So, what makes it different from prompt engineering?
Prompt engineering puts the human in the driver's seat at every step - write prompt, review output, write next prompt, repeat. The agent only moves when you push.
Loop engineering flips it. You set a goal once. A trigger fires. The agent acts, checks whether the goal was met, and keeps going until it is. You only show up at the end to review.
The skill isn't in writing better prompts. It's in designing the loop around the agent.
We broke down every major loop type - ReAct, Reflexion, Ralph Loop, /goal, and more - in our 2026 guide. Link in the replies.
#LoopEngineering #PromptEngineering #AIAgents #ClaudeCode
6
13
69
4,998
Read the complete blog on Agentic Loops & Loop Engineering: hubs.la/Q04kWFJk0
1
1
6
2,455
Your AI agent is only as powerful as its tools.
MCP fixes the connectivity problem. FastMCP makes building tools trivial for Python devs. LangGraph turns them into autonomous agents.
Join us for a live session on June 17 at 11:00 AM PT to see this built from scratch — real tools, real workflows, no toy examples.
👉 Register now: hubs.la/Q04kMrgf0
#FastMCP #MCP #AIAgents #LangGraph #Python #MachineLearning



1
6
705
🚨 Claude Fable 5 is live - Anthropic’s first Mythos-class model for general use.
The headline number from early testing: Stripe ran it on a 50M-line Ruby codebase and a 2-month migration was done in a day.
A few things worth knowing before you switch:
- Queries touching cybersecurity, bio/chemistry, or suspected model distillation fall back to Opus 4.8 automatically - Anthropic tuned the classifiers conservative on purpose, so expect some false positives
- Free on paid plans (Pro, Max, Team, Enterprise) through June 22 only - after that, usage credits required until capacity catches up
- API access is fully available today with no cutoff
Mythos 5 is the same model with cyber safeguards lifted, but restricted to Glasswing partners for now.
$10/M input, $50/M output - less than half of Mythos Preview pricing.

Claude Fable 5 is available everywhere today. Claude Mythos 5 is restricted to Glasswing partners until we expand our trusted access program.
anthropic.com/news/claude-fa…
2
1
1,262
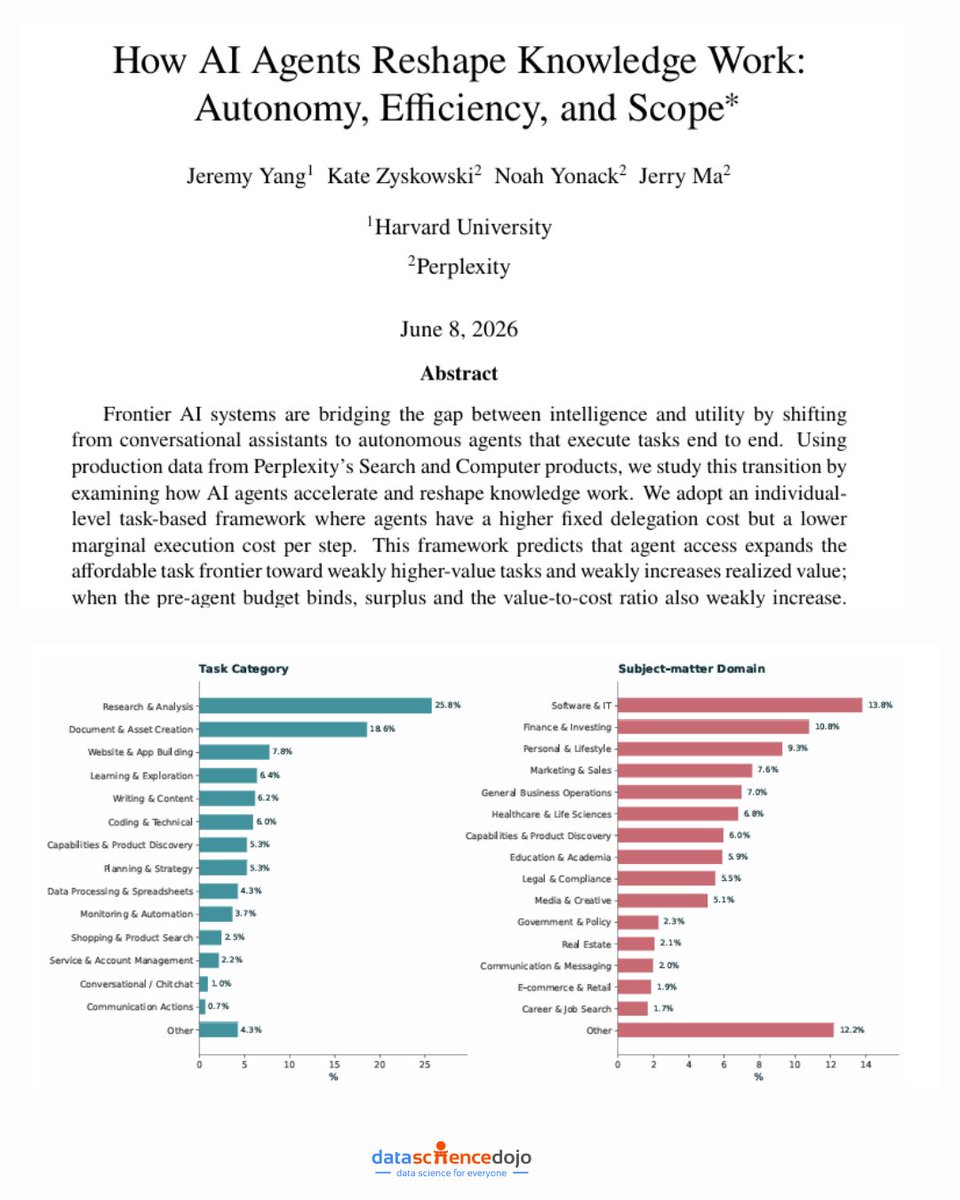
💡 26 minutes of autonomous work per session versus 33 seconds for search — that gap, measured in production data across millions of Perplexity queries, is one of the clearest benchmarks yet on what agentic AI actually delivers.
A new paper from Harvard Business School and Perplexity tracked how users behave differently with agentic AI (Computer) versus conversational search.
Agents don't just complete tasks faster — they change what users ask for.
Follow-up queries shift toward higher-order work like verification and synthesis, with per-query dissatisfaction rates 55% lower on the agentic system.
For data professionals thinking about where AI fits in their workflows, this kind of production-scale evidence is more useful than most benchmarks. The productivity argument isn't theoretical anymore.
What tasks in your own work are you delegating to agents vs. still handling manually?
#aiagents #airesearch #agenticai #harvard #perplexity
3
2
9
743
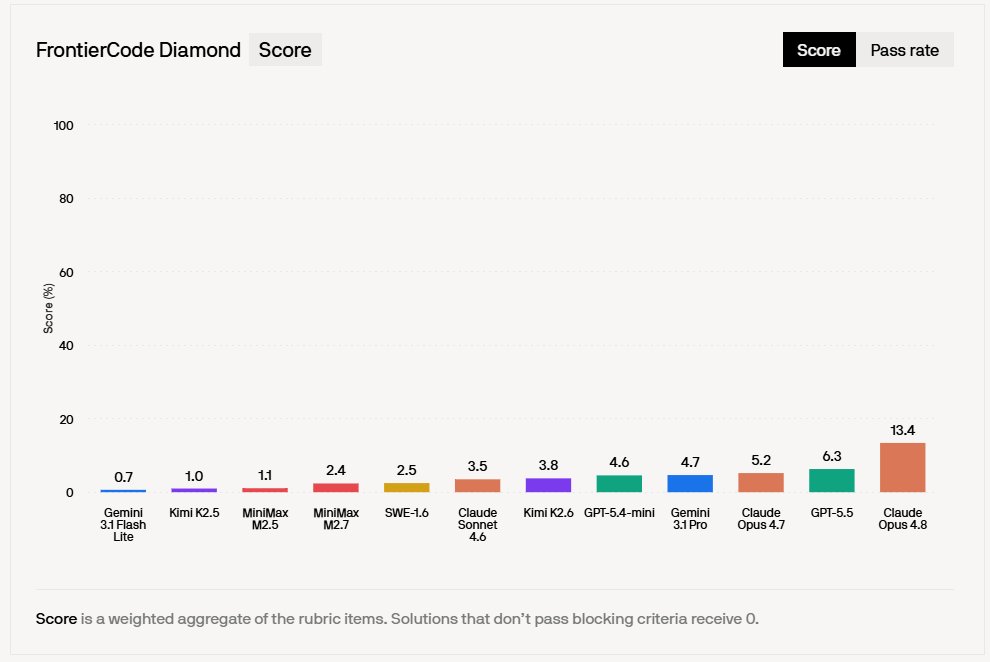
📢 Most AI coding evals ask: does it pass the tests? Cognition's new FrontierCode asks: would you actually merge this?
What makes it different from SWE-Bench:
- Tasks built by 20 open-source maintainers across 36 repos, each taking 40 hours
- Evaluates on correctness, regression safety, scope, test quality, and code style
- 81% fewer misclassifications than SWE-Bench Pro
- Three tiers: Extended (150 tasks), Main (100), Diamond (50 hardest)
📉 The results are a reality check for anyone relying on standard coding benchmarks:
- Claude Opus 4.8 leads at 13.4% on Diamond, 34.3% on Main
- GPT-5.5 scores 6.3% on Diamond, but uses 4x fewer tokens
- Best open-source model (Kimi K2.6): just 3.8% on Diamond
If you evaluate AI for coding work, this is a more honest signal than leaderboard numbers suggest.
#codingagents #agenticai #aievaluation #ainews
2
6
804