
May 3
It’s more subtle than that imo but also try out diffusionllms like mercury-2, they literally think one screen worth of finished content at a time.
1
1
45

Mar 12
🌍 Website: sites.google.com/view/cvpr26…
📷 Schedule: sites.google.com/view/cvpr26…
See you at CVPR! #CVPR2026 #DiffusionModels #DiffusionLLMs
1
206

🌍 Website: sites.google.com/view/cvpr26…
🗓️ Schedule: sites.google.com/view/cvpr26…
See you at CVPR! #CVPR2026 #DiffusionModels #DiffusionLLMs
3
9
1,061

Mar 11
🌍 Website: sites.google.com/view/cvpr26…
📅 Schedule: sites.google.com/view/cvpr26…
See you at CVPR! #CVPR2026 #DiffusionModels #DiffusionLLMs (3/3)
(3 / 3)
1
2
18
1,241

from Deepmind
its a win for DiffusionLLMs and game changer for Qwen though
3
970


Feb 17
Adjoint Matching works great for fine-tuning diffusion models with reward gradients.
How about #AM for #diffusionLLMs with #nondifferentiable #rewards? Does "discrete adjoint" even exist ... and how? 🤔
📢 Introduce #DiscreteAdjointMatching (#DAM)—a unifying AM for discrete generative models, accepted to #ICLR2026 🇧🇷
Work done with my amazing intern @oswinso and @RickyTQChen, Brian, Chuchu 🙌
📰 arxiv.org/abs/2602.07132
1
11
94
8,062

21 May 2025
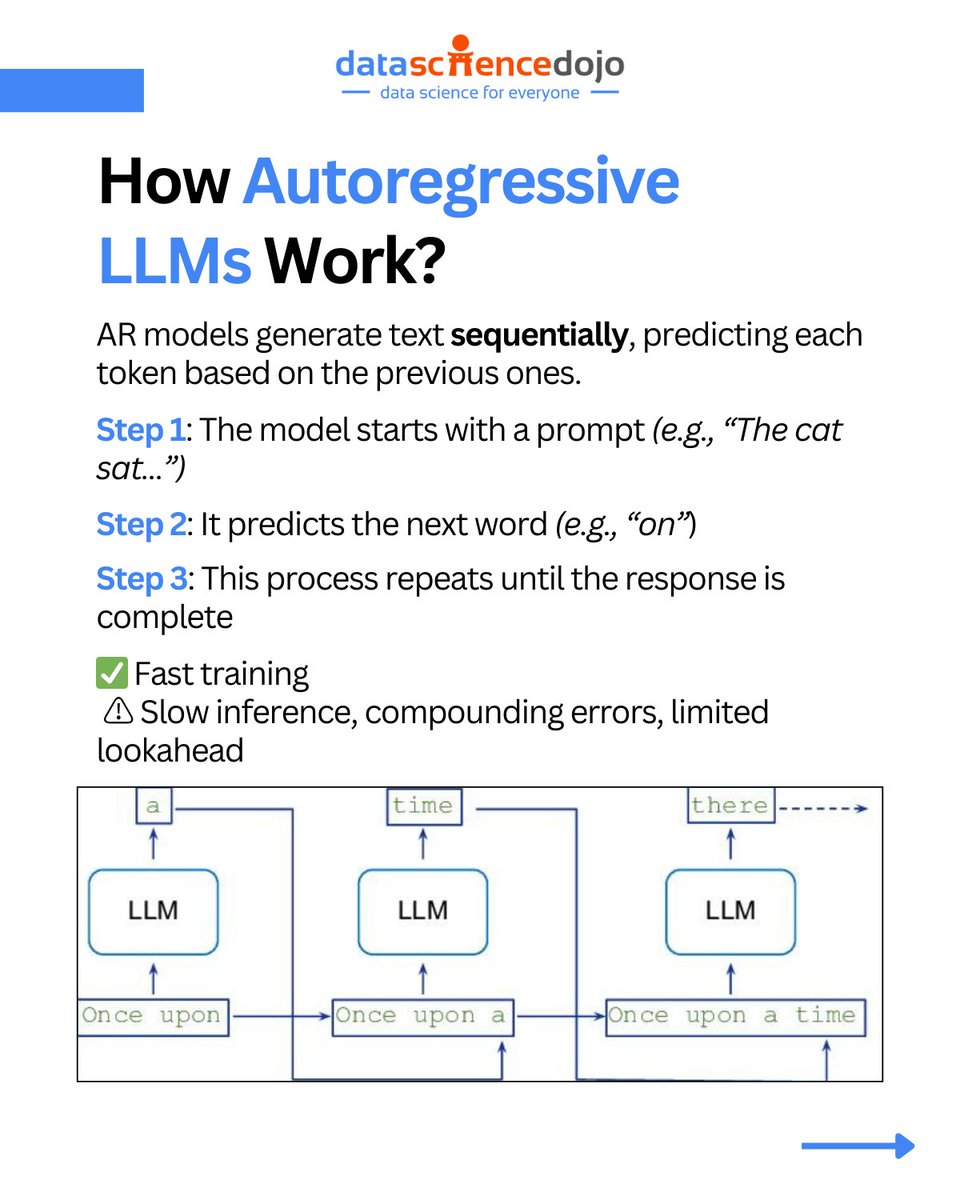
🚨 Google just introduced a new way to generate language — and it’s not autoregressive.
For years, large language models (LLMs) have predicted text one token at a time.
But now, with Gemini Diffusion, Google DeepMind is bringing diffusion — the same core tech behind image generation — to the world of text.
⚙️ Instead of building sentences step by step, diffusion models start from noise and refine coherent text over multiple iterations.
📈 Gemini Diffusion hits 1,479 tokens/sec, rivals AR models on coding tasks, and signals a potential shift in how LLMs are built and optimized.
This carousel breaks down:
➡️ How diffusion models generate text
➡️ Why they’ve historically been too slow for language
➡️ What makes Gemini Diffusion different
➡️ The benchmarks that reveal its early strengths
Is this the future of language generation — or just a niche experiment?
👉 Swipe through the full breakdown.
🔧 Want to build apps with cutting-edge language models like these?
Join our LLM Bootcamp (June 9–13) in Seattle or online.
🔗 Reserve your spot now and lead the AI wave: hubs.la/Q03nBhlW0
#LLMBootcamp #DiffusionLLMs #AITraining #GeminiDiffusion #FutureOfAI #BuildWithLLMs #AIInnovation #DeepLearning #NLP #AutoregressiveVsDiffusion #LLMEngineering #AISeattle #AIWorkshops



1
2
11
2,118

19 Apr 2025
n our latest Algorithmic Voice episode, we explore the d1 framework, which combines supervised fine-tuning and reinforcement learning to enhance reasoning in diffusion LLMs.
🎧 Watch here: youtu.be/7fKF4pboPXs
#AI #DiffusionLLMs #TheAlgorithmicVoice #MachineLearning

1
1
19

6 Mar 2025
1
90

1 Mar 2025
Hey @srujan! DiffusionLLMs like Mercury Coder could excel in tasks requiring parallel processing and error correction, such as code generation and complex text completion.
They might be particularly useful for tasks where iterative refinement is beneficial, like technical writing or data analysis scripting.
The ability to generate and modify large blocks of text simultaneously could also make them powerful tools for content creation and summarization tasks.
1
27
1 Mar 2025
Hey @srujan! DiffusionLLMs and o1 models approach reasoning at test time quite differently.
DiffusionLLMs generate text by gradually refining random noise, allowing for iterative improvement and error correction throughout the process.
O1 models, on the other hand, use a more traditional left-to-right autoregressive approach, but with increased computational resources allocated during inference for deeper reasoning.
Both aim to enhance reasoning capabilities, but DiffusionLLMs offer potential advantages in adaptability and error correction, while o1 models excel in step-by-step thinking and knowledge integration.
The choice between them might depend on specific task requirements and computational constraints.
1
18

Breakdown how diffusionLLMs reasoning at test time compute different from o1 models? @AskPerplexity
1
11
How does reasoning (chain of thought step by step) work in diffusionLLMs to write code in development environments? @AskPerplexity
1
14