
#BuildWithLLMs day 3
1. Write a clear, very specific prompt, always pointing to the part you are editing.
2. Put the prompt first, then paste the logs.
3. Ask for focused edits only.
4. When the LLM suggests changes, read them carefully; it often tweaks sections that don’t need it.
4. Keep functions in separate files. Stay modular; one giant file breaks easily.
5. Before any edits, have the LLM draft a Plan and a TODO list.
6. Ask the LLM to add code comments for everything.
7
531
#BuildWithLLMs day 2
1. Prep every doc for what you need, like SDKs, especially if you plan to use @thirdweb, @privy_io, or any newer web3 SDKs.
Give that full context to the LLM; most models struggle with web3 SDK details.
2. Read the docs yourself so when the LLM hallucinates, you can spot and fix it.
3. Create a rule file with naming and structure standards:
• camelCase for xx, PascalCase for yy
• Put functions in the zz folder
• always use clear, descriptive names
• Anything else that matters
(Comment if you want the complete rule file.)
4. Use official docs or the LLM to spin up your base folder structure. Keep it clear: frontend and backend in separate roots, then organize each layer and log every rule in the rule file.
5. Add a guides folder. Drop all text docs there. Tell the LLM to read them and, after finishing each part of the app, have it generate a doc for that part. e.g., when an API endpoint is done, get the LLM to write the doc, then feed that back to wire the API into the frontend.
6. Learn git: small commits, cherry-pick, revert.
Commit every step so you can roll back fast when the LLM breaks something.
1
9
833

14 Jul 2025
what if your personality looked like a glowing double helix
and pulsed with music you love
your taste. your world.
distilled into a strand
i’m building it.
coming soon.
@Qloo #Qloo #LLMHackathon #Qloo #AI #TasteAI #BuildWithLLMs
3
53
#BuildWithLLMs day 1:
Prep before code a single line:
1. Draft a PRD in depth. Take your regular spec and pack it with every extra detail.
2. Slice it up. I aim for at least 5 chunks; some builds hit 20 in the first run, and can get to 100 or more at the end.
3. Go deep on each chunk: stack calls, SDK picks, tiny code snippets, every note, and smaller details in your mind.
4. Add all possible changes, connections, add-ons, or comments.
5. Map the flow. Mermaid diagrams are super LLM-friendly and let you see how every piece clicks together.
6. Iterate until you're satisfied it's a good starting point.
7. Pass every chunk to an LLM and ask it to polish the wording for dev use. Then read every line yourself to be sure nothing vital got lost or invented.
This will take a good amount of time, but it saves tons of time when coding.
1
13
987

The Qloo LLM Hackathon is in full swing!
Now through Aug 1 → Build w/ LLM of Choice Qloo’s Taste AI™
• $10K Grand Prize
• $5K Runner-Ups
• Judges: @JasonChatbox, @todd_boehly, @CedEntertainer, Nicole Segliman more
Still time to join → qloo-hackathon.devpost.com/
#LLMHackathon #Qloo #AI #TasteAI #BuildWithLLMs
1
2
629

16 Jun 2025
This is your trend radar for AI building in 2025.
No noise. All signal.
Whether you’re fine-tuning agents or forecasting the next breakout—
Notice faster. Build smarter.
#AItrendtools #solysian #buildwithLLMs #modelwatch #huggingfaceleaderboards #openweights #founderstack
22

21 May 2025
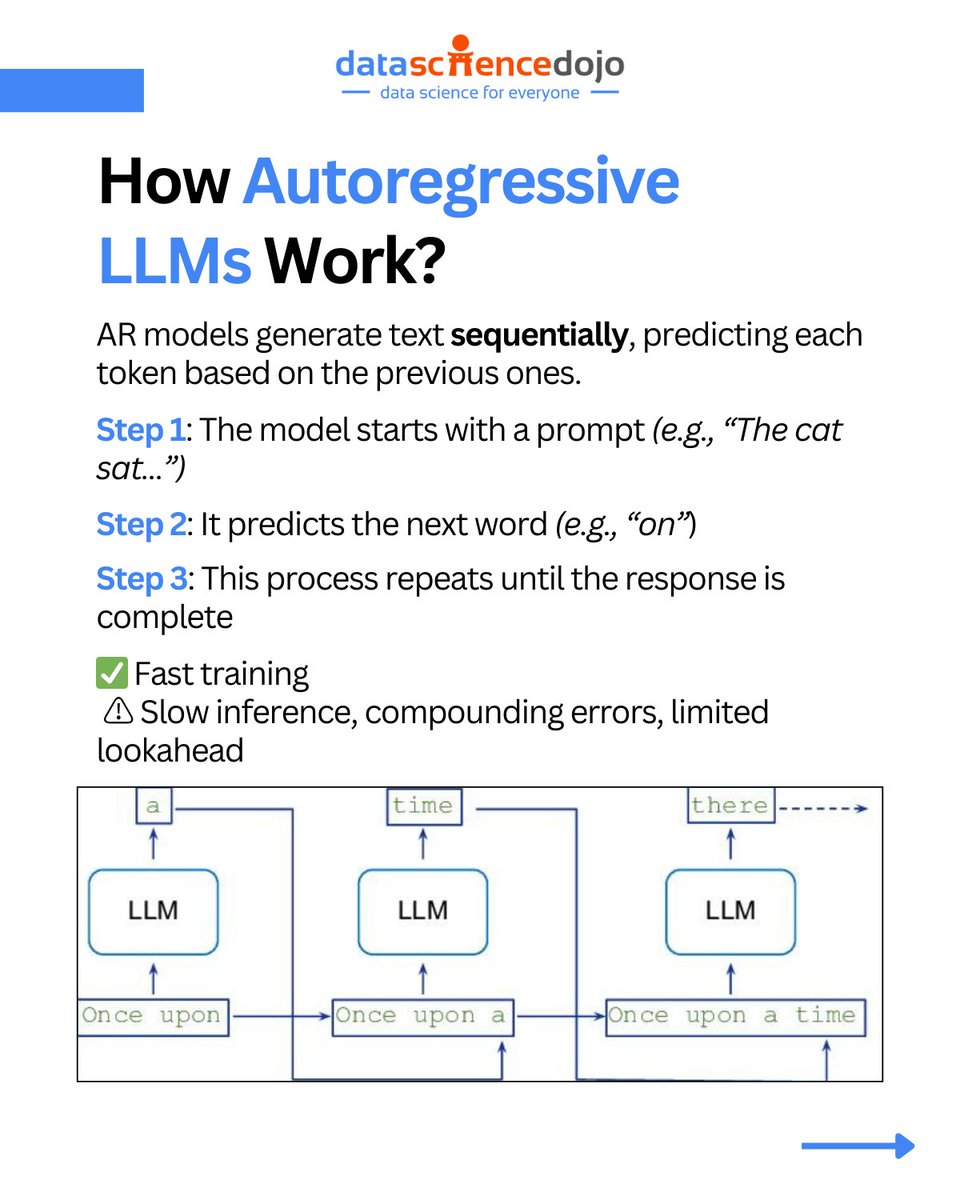
🚨 Google just introduced a new way to generate language — and it’s not autoregressive.
For years, large language models (LLMs) have predicted text one token at a time.
But now, with Gemini Diffusion, Google DeepMind is bringing diffusion — the same core tech behind image generation — to the world of text.
⚙️ Instead of building sentences step by step, diffusion models start from noise and refine coherent text over multiple iterations.
📈 Gemini Diffusion hits 1,479 tokens/sec, rivals AR models on coding tasks, and signals a potential shift in how LLMs are built and optimized.
This carousel breaks down:
➡️ How diffusion models generate text
➡️ Why they’ve historically been too slow for language
➡️ What makes Gemini Diffusion different
➡️ The benchmarks that reveal its early strengths
Is this the future of language generation — or just a niche experiment?
👉 Swipe through the full breakdown.
🔧 Want to build apps with cutting-edge language models like these?
Join our LLM Bootcamp (June 9–13) in Seattle or online.
🔗 Reserve your spot now and lead the AI wave: hubs.la/Q03nBhlW0
#LLMBootcamp #DiffusionLLMs #AITraining #GeminiDiffusion #FutureOfAI #BuildWithLLMs #AIInnovation #DeepLearning #NLP #AutoregressiveVsDiffusion #LLMEngineering #AISeattle #AIWorkshops



1
2
11
2,118

30 Dec 2024
🚀 Think Big, Start Small: Or, how I escape the builder’s paralysis: start small, solve one real problem, and scale up deliberately.💡
The key is to focus on value—for your users, your team, and your business. Don’t let flashy features overshadow solving a specific pain point. Iterate, validate, and let the solution grow naturally into something indispensable.
This is the mindset shift GenAI demands. Big breakthroughs often come from small, well-executed steps.
Here’s my breakdown for how I get to my small steps: foundit.substack.com/p/think…
#GenAI #NoCode #LLMs #BuildwithLLMs #BuildGenai #product #IDEAS #Productivity

1
77