
May 20
Tencent Cloud adopts Diffusion Transformer (DiT) architecture to deliver real-time video quality enhancement and super-resolution for full live streaming scenarios.
DiT outperforms conventional CNN and GAN models, delivering more natural, high-fidelity textures for live source video.
It unifies key capabilities: real-time 4K super-resolution, compression artifact removal, frame rate optimization and accurate ROI enhancement.
With Causal DiT and rolling cache acceleration,it maintains stable 60 FPS real-time inference performance with ultra-low latency.
It effectively improves streaming QoE, e-commerce GMV and ad conversion rates. Visit our official website for enterprise-grade DiT enhancement solutions.
#DiT #DiffusionTransformer #VideoEnhancement #SuperResolution #TencentCloud #LiveStreaming #AI #4K #OTT #Ecommerce #AIGC #MediaAI #TencentMediaService

2
1
4
800

5 Sep 2025
Generating Functional and Multistate Proteins with a Multimodal Diffusion Transformer
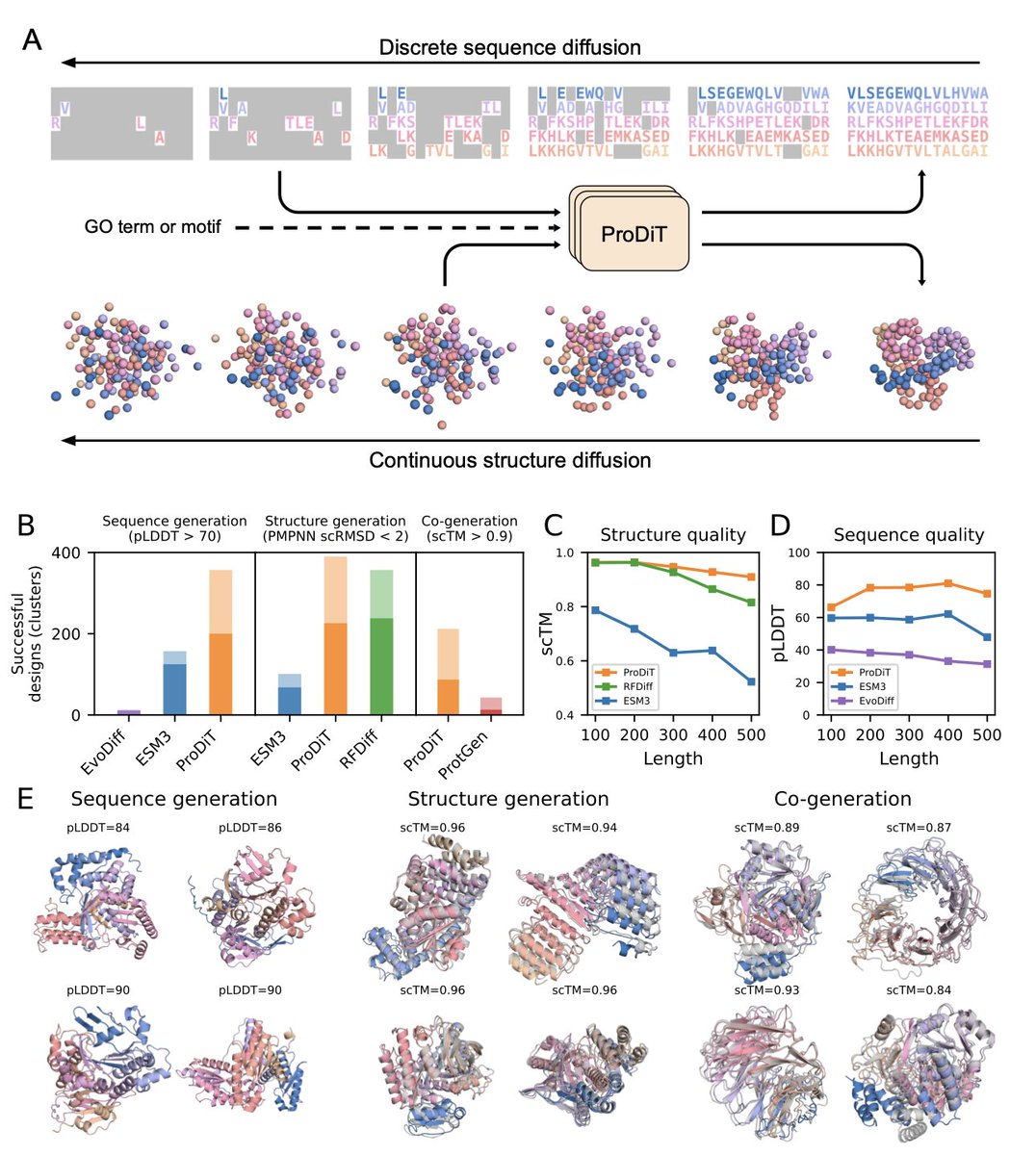
1. A groundbreaking study introduces ProDiT, a multimodal diffusion model that integrates sequence and structure modeling to design functional proteins at scale. This approach leverages the full diversity and complexity of natural proteins, addressing a major challenge in protein design.
2. ProDiT is trained on 214 million proteins across the evolutionary landscape, enabling it to generate diverse, novel proteins that preserve known active and binding site motifs. It can be conditioned on a wide range of molecular functions, spanning 465 Gene Ontology terms.
3. The study presents a diffusion sampling protocol for designing proteins with multiple functional states. This protocol successfully scaffolds enzymatic active sites from carbonic anhydrase and lysozyme to be allosterically deactivated by a calcium effector, showcasing ProDiT’s unique capacity.
4. ProDiT’s multimodal capabilities allow for the development of a novel protocol for generating multistate proteins. This protocol, derived from a probabilistic graphical model interpretation, enables the design of proteins with distinct structural states coupled to a common sequence.
5. In benchmarking across 915 diverse Gene Ontology terms, ProDiT demonstrates high success rates in generating functional proteins, often with significant recovery of known catalytic residues and binding motifs. This highlights its potential for advancing protein design.
6. The study also explores the application of ProDiT for allosteric regulation of enzymes, demonstrating the design of scaffolds where active sites are allosterically modulated by calcium binding. This marks an important step towards the design of custom and controllable multistate proteins.
@lab_berger @r_krishna3 @mihirbafna14
📜Paper: biorxiv.org/content/10.1101/…
#ProteinDesign #MultimodalModeling #DiffusionTransformer #FunctionalProteins #MultistateProteins #Bioengineering #ComputationalBiology
1
24
121
7,117
26 Aug 2025
CrystalDiT: A Diffusion Transformer for Crystal Generation
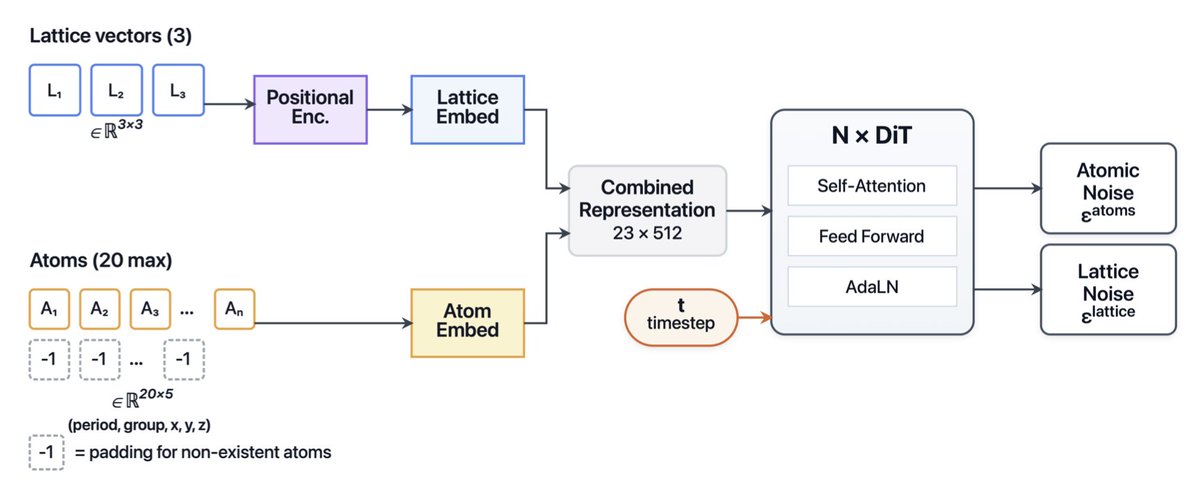
1. CrystalDiT introduces a simplified yet powerful diffusion transformer architecture that achieves state-of-the-art performance in generating novel crystal structures. This approach challenges the trend of architectural complexity by using a unified transformer to treat lattice and atomic properties as a single interdependent system.
2. The key innovation lies in the two-dimensional atomic representation based on the periodic table, which naturally captures chemical relationships without the need for complex architectural designs. This representation significantly enhances the model's ability to generate chemically meaningful and stable crystal structures.
3. CrystalDiT employs a balanced training strategy that optimizes the trade-off between generation quality and discovery potential. This strategy addresses the common issue of overfitting in complex models and ensures that the generated structures are not only valid but also novel and unique.
4. The model demonstrates superior performance on the MP-20 dataset, achieving a 9.62% SUN (Stable, Unique, Novel) rate, which is a substantial improvement over previous methods such as FlowMM (4.38%) and MatterGen (3.42%). This highlights the effectiveness of simplicity in scientific machine learning.
5. The findings suggest that in data-limited scientific domains, carefully designed simple architectures with domain-specific representations can outperform more complex alternatives. This insight provides valuable guidance for future research in materials discovery and generative modeling.
6. The results also show that CrystalDiT generates a high percentage of unique and novel structures (63.28%) while maintaining comparable stability rates. This balance between exploration and stability is crucial for practical materials applications.
7. The energy distribution analysis further validates CrystalDiT's ability to generate thermodynamically favorable structures. The model shows a pronounced peak in the stable region, indicating a higher likelihood of generating energetically viable crystal structures for real-world use.
8. The study includes comprehensive experiments and comparisons with state-of-the-art methods, providing a rigorous evaluation of CrystalDiT's performance. The detailed analysis of training dynamics and model selection strategies offers insights into the importance of balanced evaluation in materials discovery.
9. The visualizations of generated crystal structures showcase the model's capability to produce diverse and realistic materials across various chemical systems and space groups. This demonstrates the practical potential of CrystalDiT for discovering new materials with unique properties.
10. The research concludes that architectural simplicity, combined with domain-specific knowledge and balanced training strategies, can lead to significant advancements in crystal generation and materials discovery. This challenges prevailing assumptions about the necessity of architectural complexity in machine learning for scientific applications.
💻Code: github.com/hanyi2021/Crystal…
📜Paper: arxiv.org/abs/2508.16614v1
#CrystalDiT #DiffusionTransformer #CrystalGeneration #MaterialsDiscovery #MachineLearning #ScientificModeling
2
10
925

11 Apr 2025
HiDream-I1って画像AIがやんわり流行りそうで流行らないような空気。17BのDiffusionTransformerでクソデカなんだけど、MoEだから推論は速いらしい。画像のクオリティはFlux並みで、モデルが全部MITライセンスなのは優位性がある。テキストエンコーダにT5だけじゃなくLlama3.1-8Bを採用していてプロンプト遵守能力はFlux超えてるらしい。とはいえ流行りようが無いのはfp8でVRAM27GBも必要らしい。nf4でようやくVRAM15GB消費でVRAM16GB以上のグラボ持ってないと話にならない。画像生成勢もVRAMバカ食いするMoEの忌々しさを知る時が来た。モデルは3種類あって、推論ステップ数が違う。Full版は50ステップ、Dev版はFluxDevみたく蒸留されてて28ステップ。高速なFast版は16ステップ。ComfyUIで使うにはこちら(github.com/lum3on/comfyui_Hi…)のカスタムノードを使う
reddit.com/r/StableDiffusion…
2
19
6,305

2 Apr 2025
Tous les personnages parlants sont générés uniquement à partir de paroles et de textes. #MoCha, le modèle #DiffusionTransformer de #Meta est capable de générer des séquences vidéo de qualité cinématographique :
usine-digitale.fr/article/av…
1
3
75

12 Mar 2025
DiTの弱点、効率と制御の難しさを#EasyControl が解決!LoRAで条件制御、解像度可変な学習、KV Cacheで高速化。柔軟な画像生成を実現! #DiffusionTransformer #画像生成 #AI
arxiv.org/abs/2503.07027v1
2
90

12 Feb 2025
DAY 198
I’ve just come across Hallo3, an exciting breakthrough in portrait image animation that’s pushing the envelope on dynamic and realistic visual storytelling.
#Hallo3 #PortraitAnimation #DiffusionTransformer #DigitalArt #AIInnovation #VisualStorytelling
1
2
82

10 Feb 2025
Is the platform Omni Human the latest and greatest #AI this week?
#OmniHuman #DiffusionTransformer
linkedin.com/posts/pinakilas…
2
2
78

AIを使って複数枚の画像から抽出した異なる要素を組み合わせて1枚の画像を生成する「TokenVerse」 #Gigazine (Jan 30)
#TokenVerse #画像生成AI #DeepMind #DiffusionTransformer #視覚的要素抽出
buff.ly/3PUW5UL
2
253

9 Dec 2024
🛡️ Protect Your Pretrained GenAI Models Against Unauthorized Fine-Tuning!
Pretrained diffusion models like #StableDiffusion & #DiffusionTransformer are the crown jewels of AI, but what happens when someone fine-tunes your model & profits from your hard work?
🎉 Enter SleeperMark:
A new watermarking framework to safeguard your models with resilient, stealthy IP protection against unauthorized fine-tuning! It is impossible without a fruitful collaboration between #TAMU, #NTU, #UMD, #UCDavis, and #MIT!
🔧 How It Works:
1️⃣ Embed robust, invisible watermarks during pretraining.
2️⃣ Survives fine-tuning (e.g., #DreamBooth, #ControlNet).
3️⃣ Validate ownership with trigger prompts—even black-box models.
🌟 Why SleeperMark?
✅ 98% detection accuracy after extensive fine-tuning.
✅ Works across adaptation techniques (e.g., LoRA, DreamBooth).
✅ No performance trade-offs—your model remains top-notch!
🚀 This is the future of #IPProtection for generative AI.
📎 Paper: arxiv.org/abs/2412.04852
🔗 Code: github.com/taco-group/Sleepe…
Let’s protect AI innovation together!
#GenerativeAI #AIResearch #Watermarking #DiffusionModels #IP #AI

1
10
38
5,081
18 Nov 2024
Day 112
CogVideoX is a game-changer in the text-to-video generation world, producing smooth 10-second clip.
Unlike previous models, it doesn’t struggle with short durations or stiff movements.
#AI #TextToVideo #CogVideoX #DiffusionTransformer #VideoGeneration #DeepLearning
2
258

4 Sep 2024
MASSIVE
• 🧬 Open-source AlphaFold3 trained 10 hours on 8 A100 GPUs, no templates
• 🔄 Corrected MSA module communication step placement
• 🔀 Swapped MSA module order to match AlphaFold2
• 🔗 Added missing residual connections in DiT blocks
• ♻️ Reused OpenFold components for triangular attention
• 🔄 Repurposed MSARowAttentionWithPairBias for DiffusionTransformer
• 💾 60% operations still memory-bound
• 🧫 Training on single chain proteins
• 🔬 Extending ProteinFlow to ligands, multimers, nucleic acids
2 Sep 2024

🚀Excited to announce: Open-source AlphaFold3 implementation! 🚀
I am thrilled to announce one of the models we have been building for the last 8-weeks at Ligo - an open-source implementation of DeepMind’s frontier model, AlphaFold3! Here’s what we have learned, a thread (1/11):
2
4
33
4,976

2 Sep 2024
A note on model efficiency: big part of the project was to make everything fast and efficient. We re-use @open_fold ‘s components in triangular attention. We re-purpose the MSARowAttentionWithPairBias (which is an op not in AlphaFold3) for the DiffusionTransformer. (7/11)
1
27
9,079

15 Jul 2024
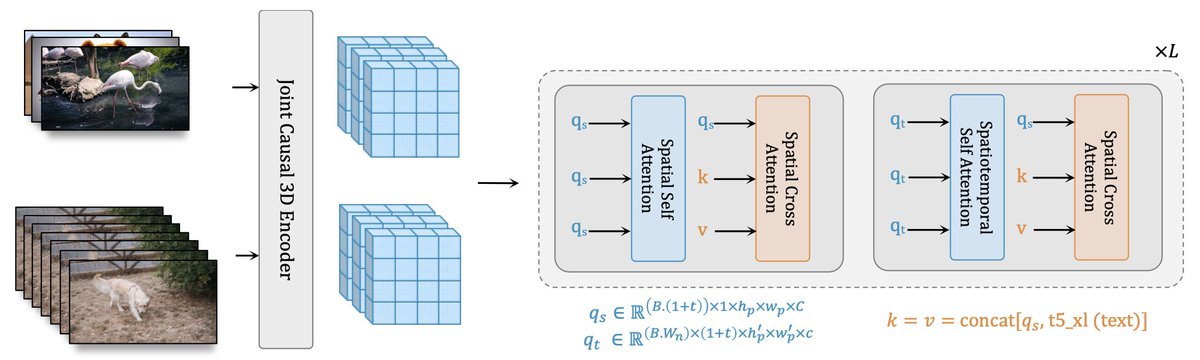
- WALT: Throw away the UNet, and use the DiffusionTransformer (DiT). Directly learn a 3d encoder-decoder (autoencoder) to map 4d input to a lower-resolution 4d latent space, patchify it, and alternate non-overlapping, window-restricted spatial and spatiotemporal attention.
(5/N)
1
2
575

30 Jun 2024
1
8
43
3,014

23 Feb 2024
Stable Diffusion 3 Asserts Dominance in AI Imagery Landscape
#accessibilityenhancements #AI #artificialintelligence #Design #diffusiontransformer #flowmatching #hardwaresetups #imagegeneratingAImodel #llm #machinelearning #Misuse
multiplatform.ai/stable-diff…

ALT AI News
2
175