

DPRM: A Plug-in Token-Ordering Module for Diffusion Language Models
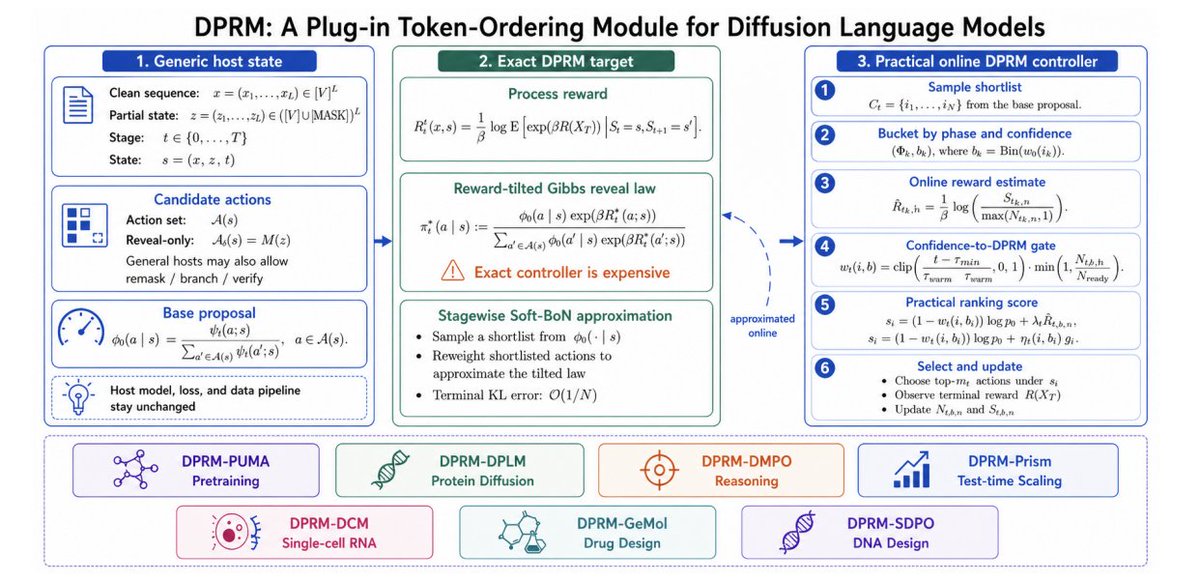
1 Token ordering is treated as a first-class control variable in diffusion language models (DLMs): DPRM is a plug-in module that changes only the ordering policy, while keeping the host architecture, denoising objective, supervision, and data pipeline unchanged.
2 Core idea: start from confidence-driven progressive ordering (efficient and aligned with inference), then gradually shift toward reward-aware ordering using online estimates of process reward; the goal is to reduce the myopia of confidence-only ordering (quality–exploration dilemma).
3 Formal target policy: DPRM derives an exact controller via a Doob h-transform of the host Markov chain, yielding a reward-tilted Gibbs “reveal law” over candidate token updates: base proposal q0(a|s) is reweighted by exp(β R*t(a;s)), where R*t is a log-moment of future terminal reward given taking action a.
4 Practical controller: exact Doob guidance is expensive, so DPRM uses (i) shortlist sampling from the base proposal, (ii) Soft-BoN reweighting within the shortlist, and (iii) an online bucketized estimator of process reward indexed by coarse phase (early/mid/late) and confidence bins; a gate interpolates between pure confidence and reward-tilted scores based on warmup time and bucket “readiness” counts.
5 Theory highlights: (a) stagewise Soft-BoN approximation converges to the exact DPRM target at O(1/N) in terminal KL (N = shortlist size); (b) online bucketized estimates track the exact DPRM score at empirical-Bernstein-type rates, up to bias from coarsening/warmup/nonstationarity; (c) under tractable stagewise optimization assumptions, DPRM has a sample-complexity advantage over both random ordering and confidence-only progressive ordering.
6 Natural-language results as matched interventions across the pipeline: DPRM-PUMA improves GSM8K validation mean from 29.34 to 34.27 in diffusion pretraining; DPRM-DMPO improves harder reasoning subsets (e.g., MATH Hard 44.3→47.9, Countdown Hard 29.6→33.4) in post-training; DPRM-Prism improves GSM8K test-time scaling voted accuracy 82.41→83.85, with higher inference cost (more NFE) but unchanged verification-call count.
7 Scientific-domain transfer: ordering remains high-leverage but becomes multi-objective. In protein inverse folding (DPLM-2 Bit), ordering-aware variants improve forward-folding RMSD (35.47→29.43) and TM-score (0.3071→0.3321), while other co-generation metrics show trade-offs. This supports “ordering as a knob” rather than a universally dominating heuristic.
8 Single-cell gene-expression diffusion (DCM) shows a clean gain: token recovery improves 63.97%→75.92% and zero-expression accuracy 78.39%→99.90% under DPRM variants, indicating that reward-aware ordering can strongly affect reconstruction behavior in sparse, high-dimensional masked diffusion.
9 Molecular and DNA diffusion: in GenMol V2, DPRM variants improve fragment-constrained metrics like linker validity (0.142→0.429) and scaffold quality (0.429→0.712), while de novo diversity/uniqueness can shift; in SDPO for DNA regulatory design, DPRM raises HepG2-related reward while preserving more ATAC and k-mer quality than confidence-only progressive ordering, illustrating controllable reward–quality trade-offs via ordering.
💻Code: github.com/DakeBU/DPRM-DLLM
📜Paper: arxiv.org/abs/2604.24357
#DiffusionLM #DiscreteDiffusion #TokenOrdering #DoobTransform #Reasoning #ProteinDesign #SingleCell #MoleculeGeneration #DNADesign #MLTheory
2
9
1,320
Reward-Guided Discrete Diffusion via Clean-Sample Markov Chain for Molecule and Biological Sequence Design
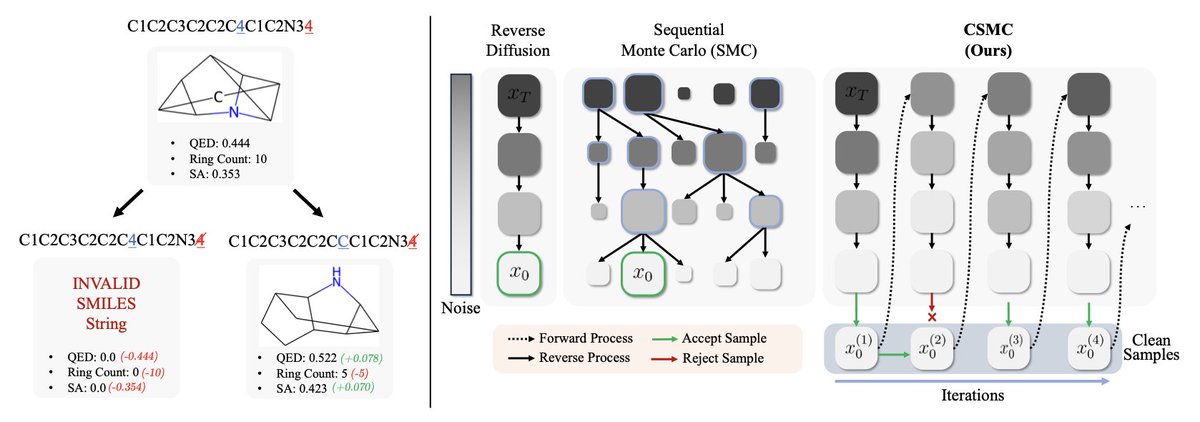
1. The paper introduces CSMC (Clean-Sample Markov Chain) Sampler, a breakthrough method for reward-guided sampling in discrete diffusion models that operates entirely on clean samples, eliminating the need for noisy intermediate rewards that plague existing approaches.
2. Unlike prior methods such as SMC and SVDD that rely on intermediate rewards computed from approximate x0 predictions, CSMC constructs a Markov chain of fully denoised samples using the Metropolis-Hastings algorithm, enabling accurate reward evaluation at every step.
3. The key innovation lies in a forward-backward proposal distribution: CSMC corrupts a clean sample through the forward diffusion process, then denoises it back to create a candidate sample, making the acceptance probability tractable without requiring the intractable clean sample probability.
4. This approach is particularly crucial for scientific applications like molecule and DNA sequence design, where reward functions are notoriously non-smooth—a single token change in a SMILES string can collapse drug-likeness scores to zero or render molecules invalid.
5. CSMC demonstrates consistent state-of-the-art performance across four reward functions (QED, ring count, synthetic accessibility, and HepG2 enhancer activity) on QM9, ZINC250K, and MPRA datasets, outperforming Best-of-N, SMC, SVDD, and even training-based methods like D-CFG.
6. The method is universally applicable to all discrete diffusion frameworks including masked diffusion models (MDMs), uniform state models (USMs), and continuous-time Markov chain approaches (SEDD-M, SEDD-U), unlike SGDD which only works with uniform CTMC models.
7. CSMC-B, a batched variant, achieves comparable rewards with significantly reduced wall-clock time (3029s to 334s), making it practical for large-scale molecular design campaigns without sacrificing sample diversity.
8. The Markov chain exhibits fast mixing with autocorrelation decaying within 2000 iterations, and the method maintains high sample diversity (Tanimoto similarity < 0.2 for molecules, cosine similarity < 0.3 for DNA sequences) despite targeting high-reward regions.
📜Paper: arxiv.org/abs/2602.09424
#DiscreteDiffusion #MolecularDesign #DrugDiscovery #GenerativeAI #ComputationalBiology #MetropolisHastings #Bioinformatics #DeepLearning
2
19
1,922

28 Nov 2025
Ready to push diffusion language modelling forward?
⭐️ Star the repo, fork the code, and help build the future of text generation.
💬 Tell us what algorithms / datasets you’d like to see next in UNI-D².
🤝 Happy to help you get onboarded — DMs / issues welcome.
🔗 GitHub: github.com/nkalyanv99/UNI-D2
📚 Docs: nkalyanv99.github.io/UNI-D2/
#DiscreteDiffusion #LanguageModeling #NLP #GenerativeAI #DLM #OpenSource
3
345