おばば retweeted

Jun 10
いきなりDiffusionLMがオープンソースに
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
5
6
2,113

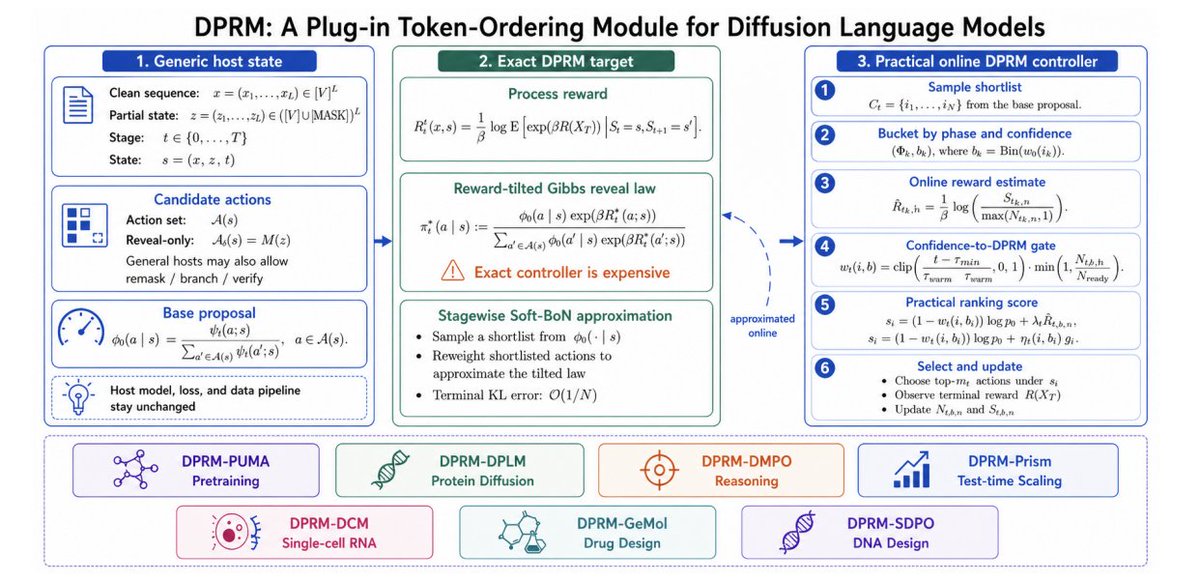
DPRM: A Plug-in Token-Ordering Module for Diffusion Language Models
1 Token ordering is treated as a first-class control variable in diffusion language models (DLMs): DPRM is a plug-in module that changes only the ordering policy, while keeping the host architecture, denoising objective, supervision, and data pipeline unchanged.
2 Core idea: start from confidence-driven progressive ordering (efficient and aligned with inference), then gradually shift toward reward-aware ordering using online estimates of process reward; the goal is to reduce the myopia of confidence-only ordering (quality–exploration dilemma).
3 Formal target policy: DPRM derives an exact controller via a Doob h-transform of the host Markov chain, yielding a reward-tilted Gibbs “reveal law” over candidate token updates: base proposal q0(a|s) is reweighted by exp(β R*t(a;s)), where R*t is a log-moment of future terminal reward given taking action a.
4 Practical controller: exact Doob guidance is expensive, so DPRM uses (i) shortlist sampling from the base proposal, (ii) Soft-BoN reweighting within the shortlist, and (iii) an online bucketized estimator of process reward indexed by coarse phase (early/mid/late) and confidence bins; a gate interpolates between pure confidence and reward-tilted scores based on warmup time and bucket “readiness” counts.
5 Theory highlights: (a) stagewise Soft-BoN approximation converges to the exact DPRM target at O(1/N) in terminal KL (N = shortlist size); (b) online bucketized estimates track the exact DPRM score at empirical-Bernstein-type rates, up to bias from coarsening/warmup/nonstationarity; (c) under tractable stagewise optimization assumptions, DPRM has a sample-complexity advantage over both random ordering and confidence-only progressive ordering.
6 Natural-language results as matched interventions across the pipeline: DPRM-PUMA improves GSM8K validation mean from 29.34 to 34.27 in diffusion pretraining; DPRM-DMPO improves harder reasoning subsets (e.g., MATH Hard 44.3→47.9, Countdown Hard 29.6→33.4) in post-training; DPRM-Prism improves GSM8K test-time scaling voted accuracy 82.41→83.85, with higher inference cost (more NFE) but unchanged verification-call count.
7 Scientific-domain transfer: ordering remains high-leverage but becomes multi-objective. In protein inverse folding (DPLM-2 Bit), ordering-aware variants improve forward-folding RMSD (35.47→29.43) and TM-score (0.3071→0.3321), while other co-generation metrics show trade-offs. This supports “ordering as a knob” rather than a universally dominating heuristic.
8 Single-cell gene-expression diffusion (DCM) shows a clean gain: token recovery improves 63.97%→75.92% and zero-expression accuracy 78.39%→99.90% under DPRM variants, indicating that reward-aware ordering can strongly affect reconstruction behavior in sparse, high-dimensional masked diffusion.
9 Molecular and DNA diffusion: in GenMol V2, DPRM variants improve fragment-constrained metrics like linker validity (0.142→0.429) and scaffold quality (0.429→0.712), while de novo diversity/uniqueness can shift; in SDPO for DNA regulatory design, DPRM raises HepG2-related reward while preserving more ATAC and k-mer quality than confidence-only progressive ordering, illustrating controllable reward–quality trade-offs via ordering.
💻Code: github.com/DakeBU/DPRM-DLLM
📜Paper: arxiv.org/abs/2604.24357
#DiffusionLM #DiscreteDiffusion #TokenOrdering #DoobTransform #Reasoning #ProteinDesign #SingleCell #MoleculeGeneration #DNADesign #MLTheory
2
9
1,320

> MDM-Prime-v2 is 21.8× more compute-efficient than autoregressive models
I may be humiliated extremely hard with my diffusionLM skepticism.
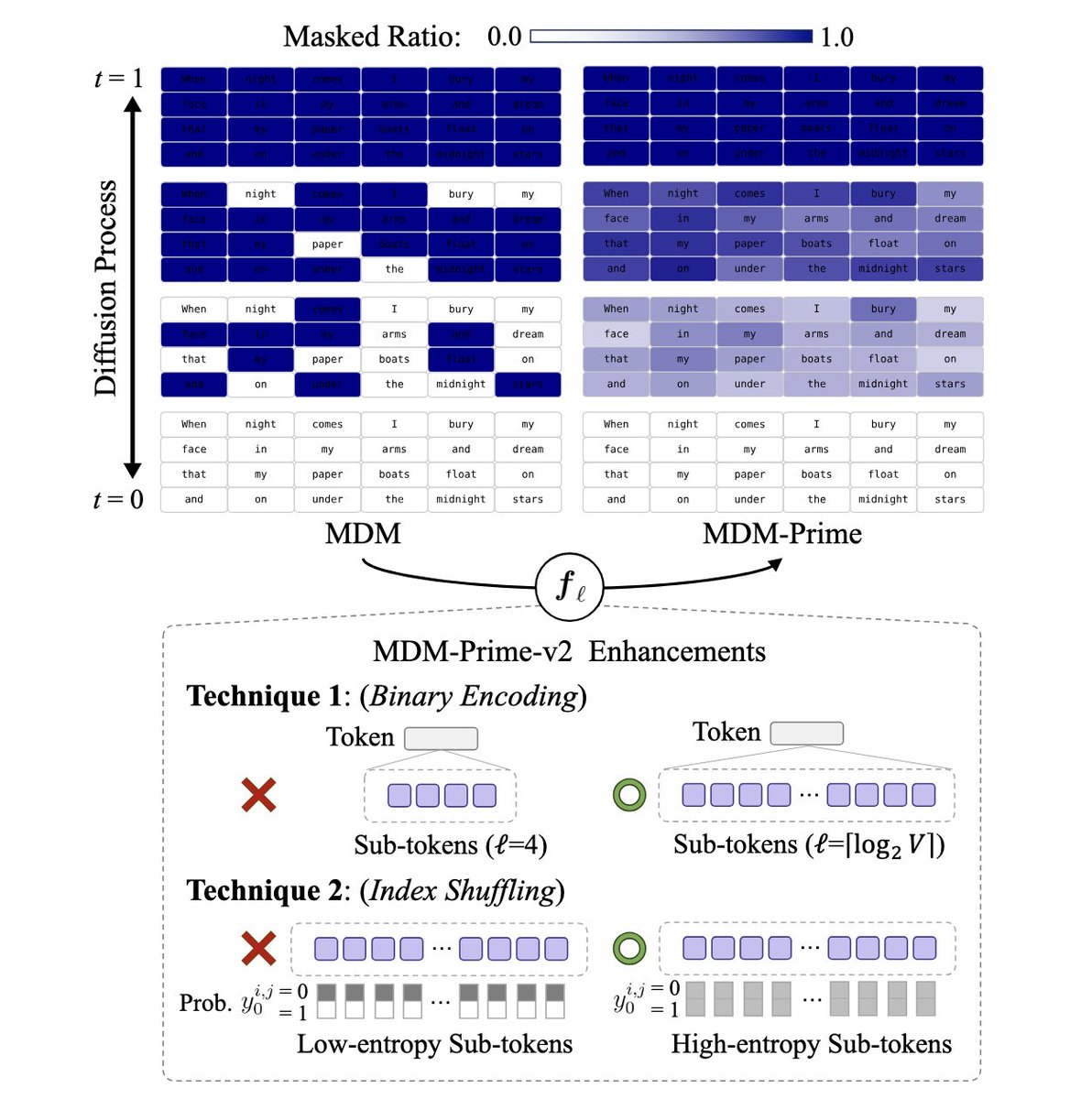
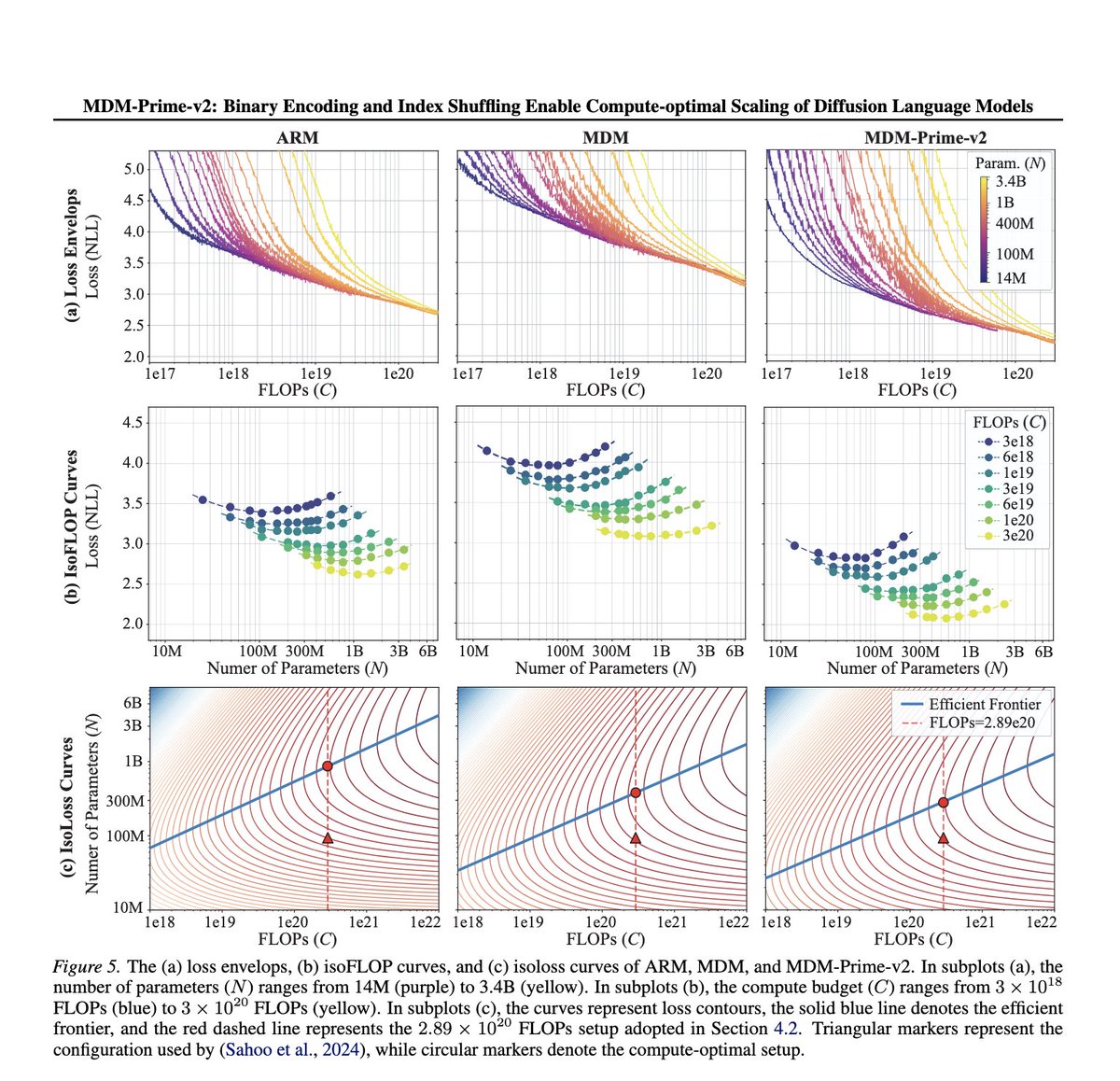
Mar 20

HUGE if true.
If true, this is probably a larger efficiency gain than ALL publicly available techniques since DeepSeekMoE(Jan 2024) COMBINED.
And it can just win modded-nanogpt speedrun.
(1e18 is 250s@50%MFU, but the loss is significantly lower than 3.28)
cc @classiclarryd
10
8
123
20,666

Feb 27
If you're excited about DLMs but want to understand their real limitations — and how to fix them — check out our paper 👇
"Why Diffusion Language Models Struggle with Truly Parallel (Non-Autoregressive) Decoding?" arxiv.org/abs/2602.23225
With @pixeli99 @pumpkinnnnne @luu_yinn @TianlongChen4 #DiffusionLM #LLM #NLP
2
9
27
1,214

27 Nov 2025
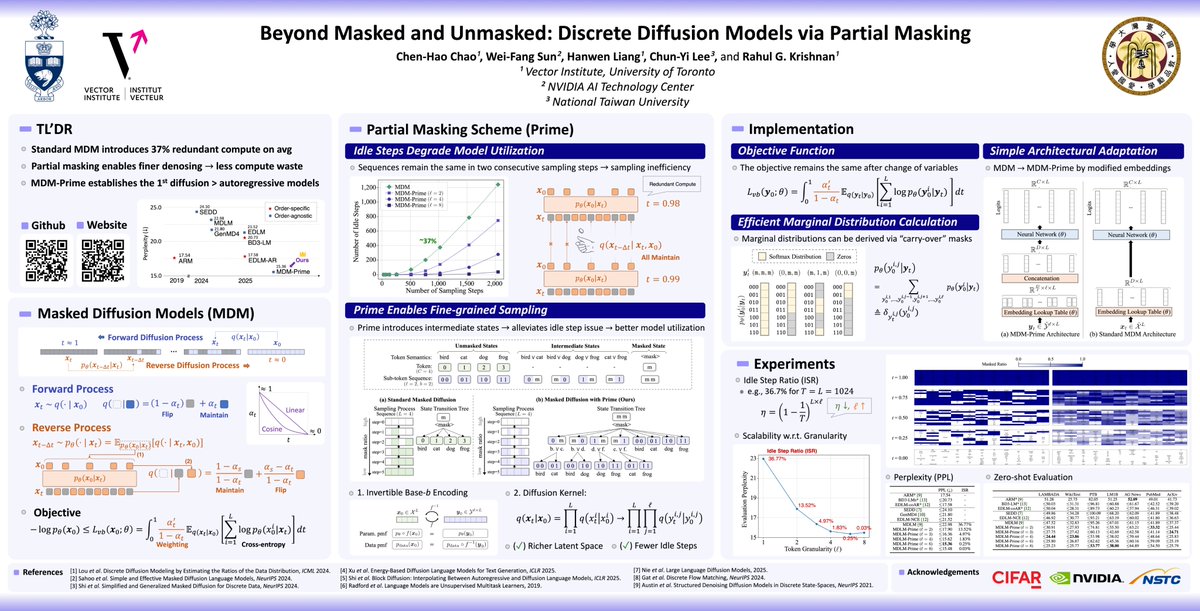
I'll be presenting "Beyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking" at #NeurIPS2025 next week!
If you're interested in #DiffusionLM, come chat at Poster #3715.
w/ @cymaxwelllee and @rahulgk
Details & Links below:
📍 Hall C,D,E 🗓️ Fri Dec 5, 4:30-7:30pm
📝 Info: neurips.cc/virtual/2025/loc/…
🌐 Web: chen-hao-chao.github.io/mdm-…
4
14
1,387

23 Aug 2025
・GPU/FPGA/ASIC(NPU)のいずれにしてもLLMの主流が自己回帰型である以上はボトルネックはメモリでは
・その辺を解決できそうなDiffusionLMもまだ途上
・GoogleのTPUとかAWSのInferentiaとかGroqのLPUとかチップはいろいろある
・Chain of Thought(Reasoning)はフレーム問題の解決ができていない(と思ってる)
・自己回帰なTransformerベースが今後もベストなのかは自分も疑問(ルカンはエネルギーベースモデルとか言ってるし)
3
1,006

27 Jul 2025
this is sick
DiffusionLM basically augments data thanks to its objective
> "model extracts richer signal per example over time, resulting in improved data efficiency"
so the same data can be used for 100 epochs for dLLMs but 4 epochs for AR LLMs

5
11
182
8,381

22 Jul 2025
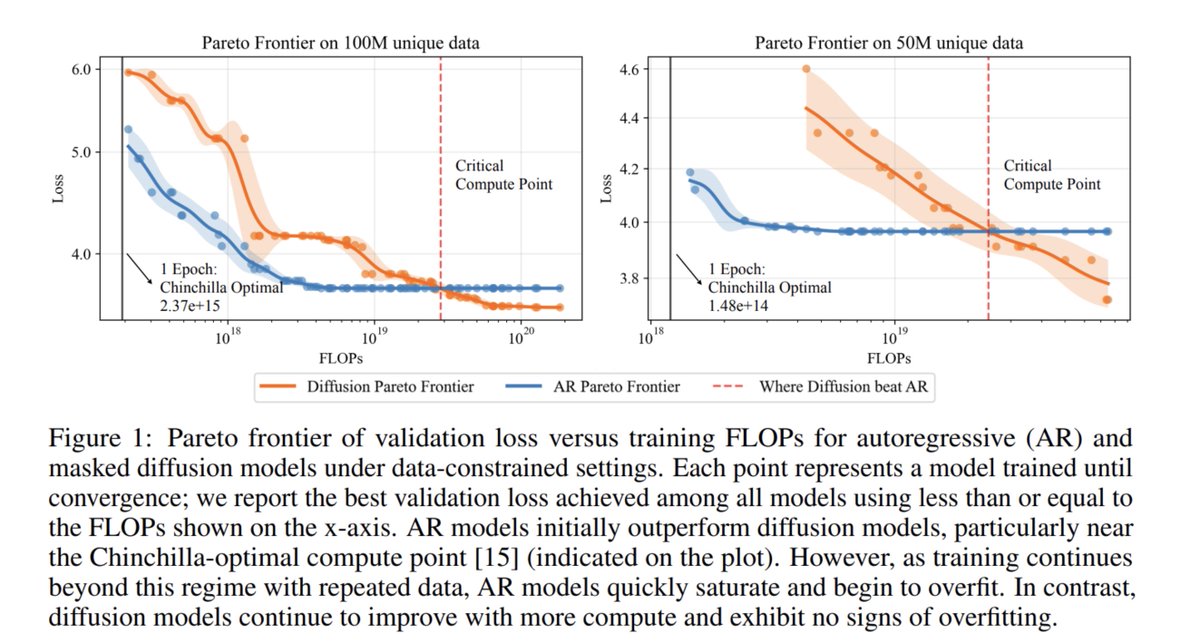
The Era of DiffusionLM might be upon us
"Diffusion Beats Autoregressive in Data-Constrained Settings"
they find that DiffusionLMs outperform AR models if you’re bottlenecked by data rather than FLOPs
same data can be reused for 100 epochs vs 4 epochs, as dLLM learns far more!
6
44
232
13,105

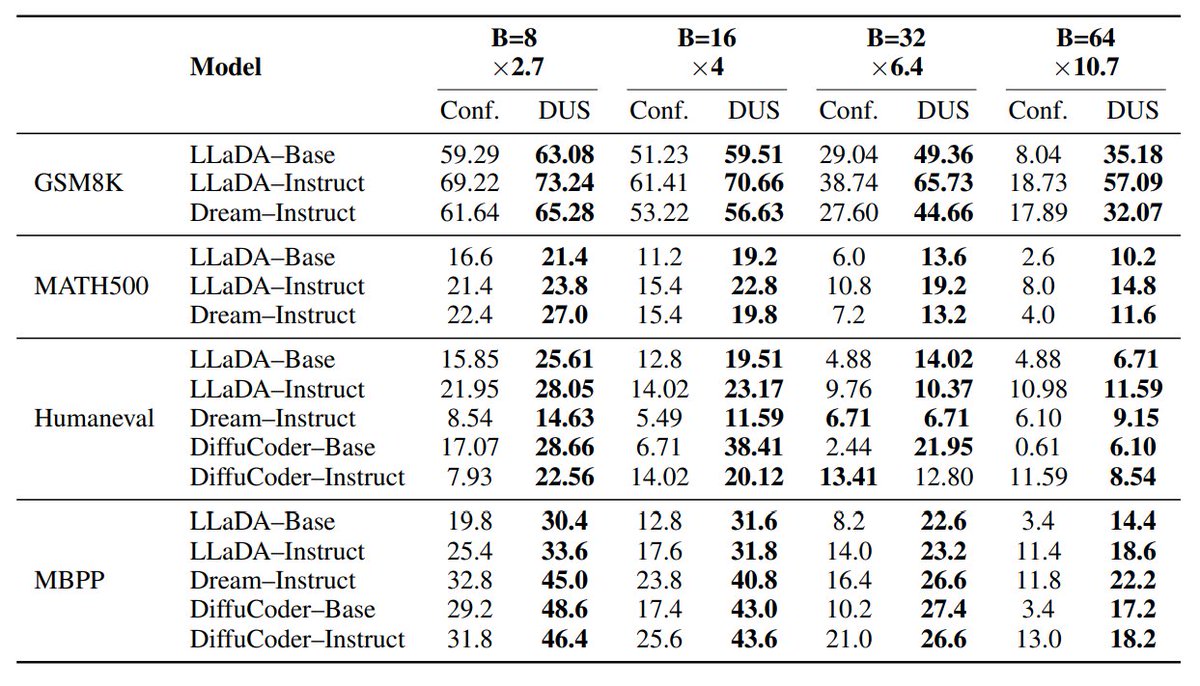
🧵6/ Results:
Preserves ≳25% quality at 5–10× fewer passes for math, code, and general knowledge reasoning benchmarks, revealing MDLMs’ true parallel potential.
Huge thanks to Haim Permuter and @NachmaniEliya for their collaboration!
#DiffusionLM #LLM #NLP #NonAutoregressive
2
177

15 Jul 2025
DiffusionLM Code, check it out! 🫡
15 Jul 2025

What happend after Dream 7B?
First, Dream-Coder 7B: A fully open diffusion LLM for code delivering strong performance, trained exclusively on public data.
Plus, DreamOn cracks the variable-length generation problem! It enables code infilling that goes beyond a fixed canvas.
11
466

6 Jun 2025
impressed by the nanogpt speedrun codebase
someone hold me accountable: nano-diffusionlm benchmarks for training and sampling
6
164

3 Jun 2025
[🧵13/13] Shout out to my collaborators: @ssahoo_ , @yashakha , Johnna, Deepansha, @ChengZhoujun, @waterluffy (Hector Liu), @ericxing, @jwthickstun, @ArashVahdat
From @Cornell, @mbzuai, @nvidia
#GenAI #diffusion
#DiffusionLM #dllms #Gemini #GeminiDiffusion
6
490

23 May 2025
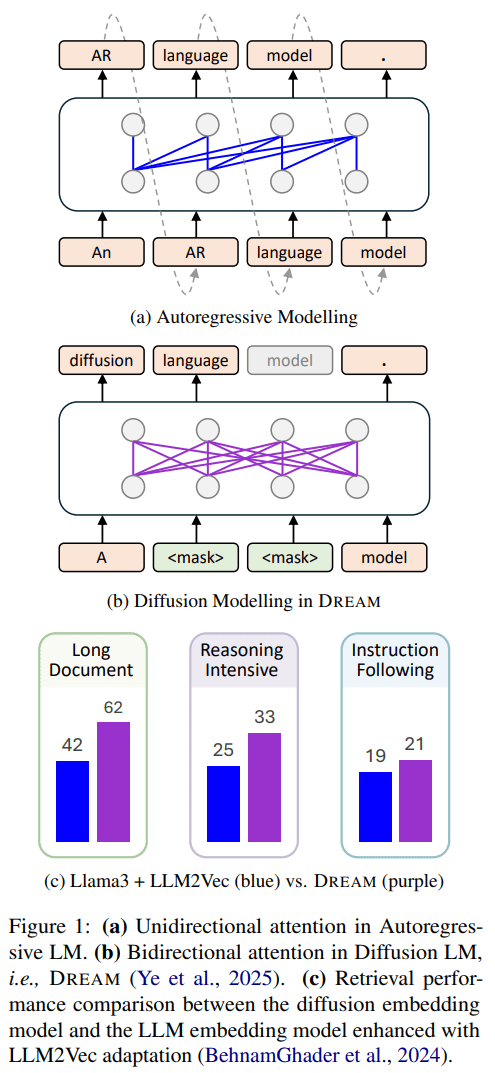
huh did not DiffusionLM -> embedding model on my bingo card!
seems like some strong performance across the board on a quick skim.
i’m curious what the full BRIGHT performance looks like or if the gains only hold on theorem based tasks (and why!)
22 May 2025

[1/8] How embeddings from Text Diffusion Models ✨compare to those from LLMs 🦙? Check out our work “Diffusion vs. AR Language Models: A Text Embedding Perspective”! We introduce a new diffusion-based embedding model that excels in long-document and reasoning-intensive retrieval.
2
3
511

20 May 2025
Same here — Gemini Diffusion stole the show for me too. 1000 tok/s while keeping that vibe coding flow? Unreal.
Multi-turn looks super promising already. DiffusionLM is the future — insanely bullish right there with you.
9
626
20 May 2025
Gemini Diffusion is my fav GoogleIO announcement
vibe coding at 1000tok/s hits different
multi-turn looks good so far
(no video speedup or anything)
insanely bullish on diffusionLM
19
35
471
29,561