
Jun 11
Emk=B.V.L
gittikce V artiyor ivmeli hareket yaptigi icin zaten potansiyel fark arttigi icin de dusunebilirsin induksiyon akimi artiyor
Fmanyetik=B.i.l
i artinca Fmanyetik artiyor
Fnet=mg-Fmanyetik
Fmanyetik artinca Fnet azalio
1
1
8
1,274

Jun 10
90

FNET
🌈 عرض جميل
⎐كُـود⎐كوبِون⎐خـِصم⎐
⎐نون⎐
⊵STC9⊴
⎐ايهرب⎐ايهيرب اهرب
⊵IPY1290⊴
ستايلي⊴
⎐SY2⊴


May 28
anlık görüntüden kimse hız bulamaz bu sulardan da sadene Fnet yönü bulunur milleti bilmedigi anlamadigi seylerle sinayip maymun yerine koymayin adam olun az amk
2
2,256



May 17
~90% of AI’s energy is devoted to one core, expensive operation: matrix multiplication.
This partly explains why so much research and engineering on LLM inference targets reducing the IO and complexity of MatMuls: O(n³) FLOPs to process only O(n²) data. When n = 30K, the gap is enormous...
A question I find fascinating is whether there exist alternative bilinear operators f(W, X) for “mixing” LLM tokens, that are as “expressive” as MatMul for human-related tasks, but require ≪ n³ FLOPs (and ideally O(n²) IOs) to evaluate.
There have been significant attempts in this direction, starting with Google’s FNet, and continuing with a long line of work on other bilinear operators: tensor algebras, Hadamard products, fast polynomial multiplication / convolutions, Butterfly matrices and other structured operators.
These approaches demonstrated promising results on some benchmarks, but when scaled to SoTA LLMs, they all seem to suffer from substantial accuracy degradation.
Is there something “holy” about MatMul in deep learning after all?
What seems to distinguish MatMul from many other bilinear forms is that it encodes arbitrary change of basis.
This is a qualitative property: A fundamental reason why ML algorithms work is the premise that real-world datasets have underlying structure – a basis/representation in which the data becomes sparse, invariant, clustered, low-dimensional, etc.
For example, changing to Fourier bases such as the DFT reveals frequencies. The DCT compresses images. Wavelets localize scale. Learned projections encode invariant subspaces, task-relevant metrics, and directions of variation. Attention scores depend on the learned embedding of LLM tokens, which are a choice of basis.
Oversimplifying, learning can be viewed as the optimization problem of finding the “right” basis to represent the data. MatMuls are the computational primitive that switches between these bases, i.e. linear projections.
By contrast, other bilinear operators such as elementwise multiplication, or convolution / polynomial multiplication p·q, do not obviously have this same functional interpretation. They impose structure, but they do not represent an arbitrary change of coordinates.
This observation may help clarify what properties would need to be preserved if we are ever to find cheaper bilinear alternatives to MatMuls in deep learning.
I still find the above question intriguing, both in theory and practice…
5
49
5,787

May 15
Fnetはどんな推定をしとるん????

May 15

宮城地震 Mj6.3
2
7
1,155

May 11
緊急地震速報によると今朝の三陸沖地震はM5.2ってけど仙台で揺れなかったので「あ、M4.9くらいでしょう?」って思っていてfnetでMw4.8ってw
1
2
602


Apr 21
Fnet = ma
W = mg
M = Fd
1 mol = 6.02 x 10²³

Ily = I love you
Imy = I miss you
Brb = Be right back
pV = nRT
F = ma
KE = (1/2)mv²
p1v1 = p2v2
E = mc²
4
227

Mar 29
Meet FNet: a text generation model that's shaking up how we think about transformers. Instead of heavy attention mechanisms, it uses Fourier transforms for lightning-fast processing. This is the future of efficient NLP.

2
1
7
601

Mar 24
What if one of the most common “performance” metrics in sport is not actually telling us what we think it is? That is the hook of this paper. Staunton and colleagues take a hard look at PlayerLoad™, one of the most widely used accelerometer-derived metrics in sport, and argue that its scientific foundation is much shakier than its popularity suggests. Right from the opening page, they note concerns with inconsistent definitions, arbitrary units, opaque filtering methods, questionable theoretical underpinnings, and imprecise mechanical terminology, and state plainly that the construct validity of PlayerLoad remains unverified. They also note that evidence for meaningful dose–response relationships with performance outcomes remains weak. In other words, the paper is not saying monitoring is useless. It is saying we need to be more careful when a widely used KPI starts being treated like the performance itself.
One of the strongest parts of the review is that it explains why this matters. The authors show that PlayerLoad is highly sensitive to sensor location, sampling frequency, filtering choices, and even natural changes in device orientation, which can create fictitious increases in the metric that do not actually reflect more physical effort. They also point out that manufacturer software appears to produce values about 15% lower than manual calculations, suggesting undisclosed processing in the background. On page 7, Figure 2 makes this especially clear by showing how the same raw triaxial acceleration data can produce very different outputs depending on the metric being used. The practical implication is important: practitioners may mistake a higher KPI for greater mechanical stress, make misleading cross-athlete comparisons, or assume an athlete has “matched” prior demands in return-to-play when the underlying mechanical exposure is actually different.
What makes the paper valuable is that it does not just criticize. It offers a better direction. The authors introduce alternatives like Accel’Rate and especially accelerometry-derived net force (FNet), which they describe as being built on clearer biomechanical principles, transparent signal processing, and outputs in SI units rather than arbitrary ones. Their conclusion is not anti-technology. It is anti black box thinking. They explicitly encourage practitioners to be skeptical of proprietary metrics until they are fully understood and validated, and argue for integrated monitoring frameworks that combine accelerometry with complementary mechanical, physiological, and perceptual indicators. That is the real takeaway. KPIs are useful, but they are not the engine. They are the check engine light. Helpful, yes. Worth watching, absolutely. But never the same thing as the actual performance we are trying to understand.

2
2
29
2,198

Vive l’🇪🇺🇪🇺🇪🇺🇪🇺 qui ns protège de tous ces prédateurs à commencer par cet assassin de Poutine. RN/FNet LFI veulent nous mettre ds le camp des dictateurs pour le devenir également.
D’où l’importance du vote.
1
5
14
159
Mar 8
Meet FNet-Text-Generation: a fresh approach to text generation that's turning heads. Instead of traditional attention mechanisms, it uses Fourier transforms for mixing token information. This makes it faster while maintaining solid performance. Perfect for when you need quick, coherent text without heavy computational costs.

1
9
1,137


Feb 3
#URPR11 #LIFE11
RESIDENCE CLUB FUNDO DE INVESTIMENTO EM DIREITOS CREDITÓRIOS FIDC
43.193.260/0001-33
Gestão: Carmel Gestora de Ativos Ltda.
Rating: Austin Rating (16set24) Perspectiva Estável, com validade até 30jul2025
Cota Sênior 1a e 3a Séries: 'brBB(sf)'
Cotas Subordinadas Mezanino Classe B: 'brB (sf)'
Cotas Subordinadas Mezanino Classe A: 'brB (sf)'
fnet.bmfbovespa.com.br/fnet/…
*Austin destacou: Em relação ao andamento de obras, não foram disponibilizadas novas medições.
**Não foi localizada a atualização do relatório de rating no Fnet
Documentos disponíveis sobre o FIDC Residence Club no Fnet:
fnet.bmfbovespa.com.br/fnet/…
FATO RELEVANTE 07/11/2025
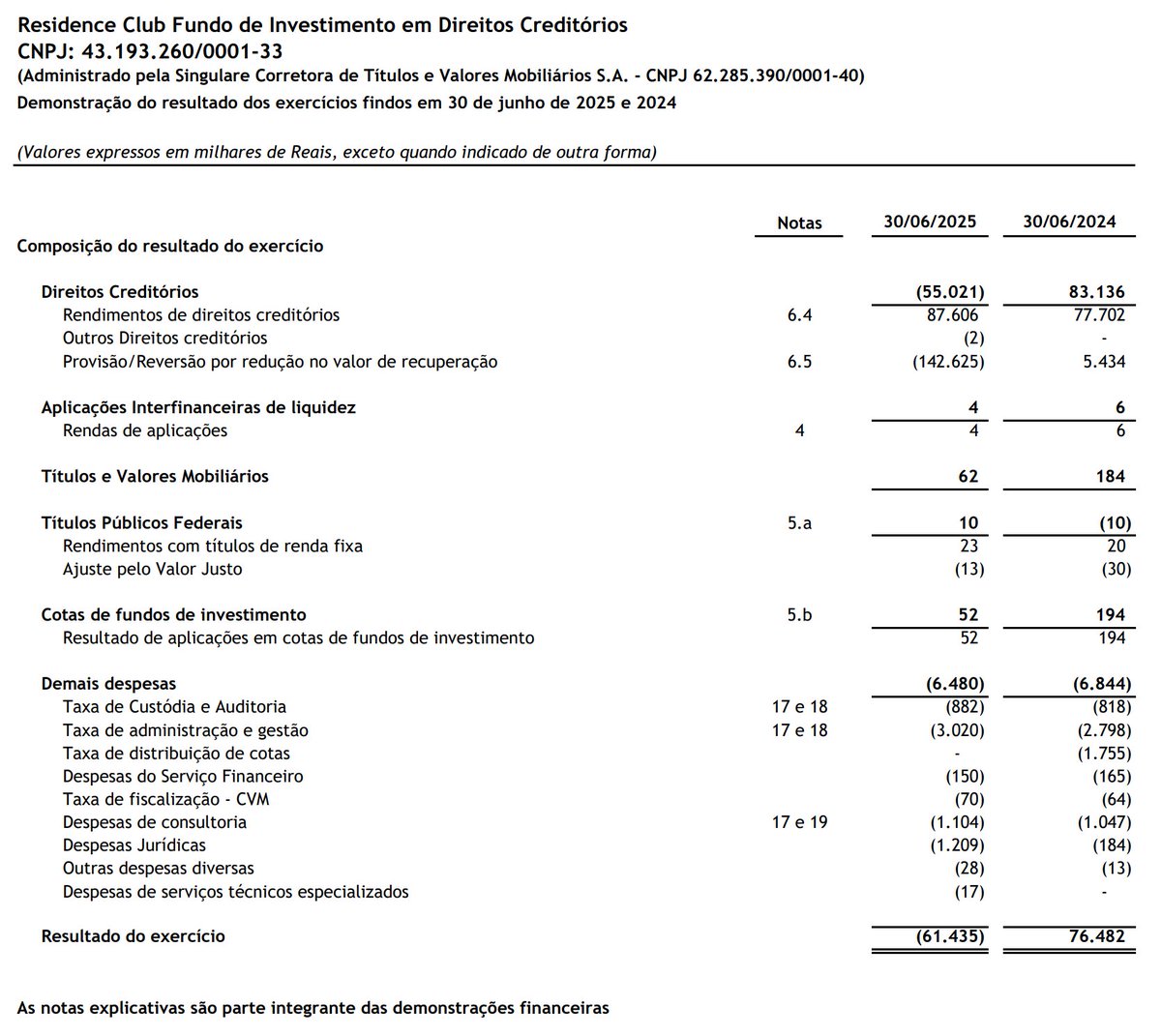
Em razão do aumento do provisionamento para devedores duvidosos (PDD), o patrimônio líquido do FUNDO apresentou uma variação negativa de 15,38% na data de 03 de novembro de 2025.
fnet.bmfbovespa.com.br/fnet/…
Informe Mensal Estruturado 11/2025
▶️Atualizou a Provisão para Redução no Valor de Recuperação para (-)R$ 193.986.278,37
fnet.bmfbovespa.com.br/fnet/…
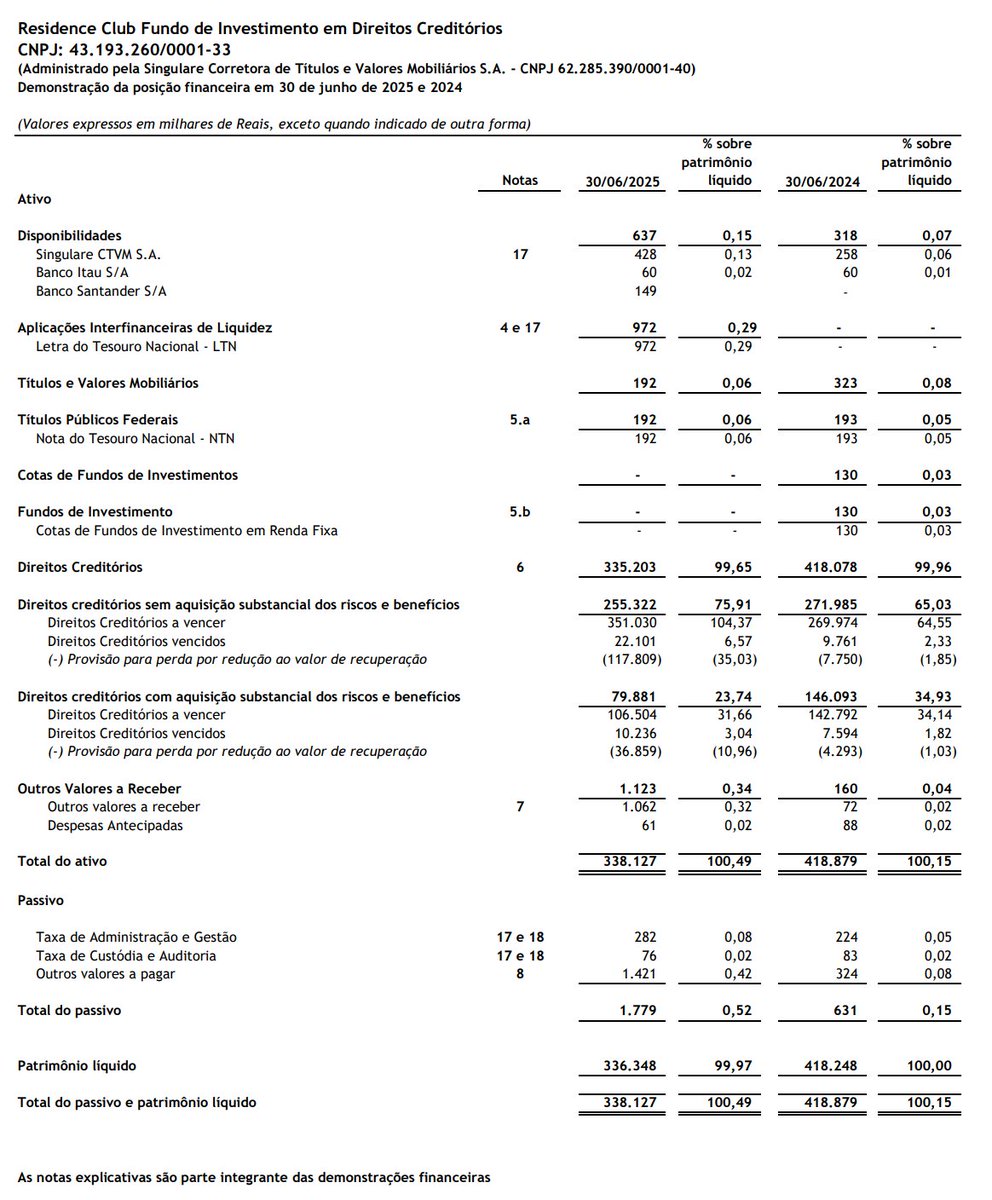
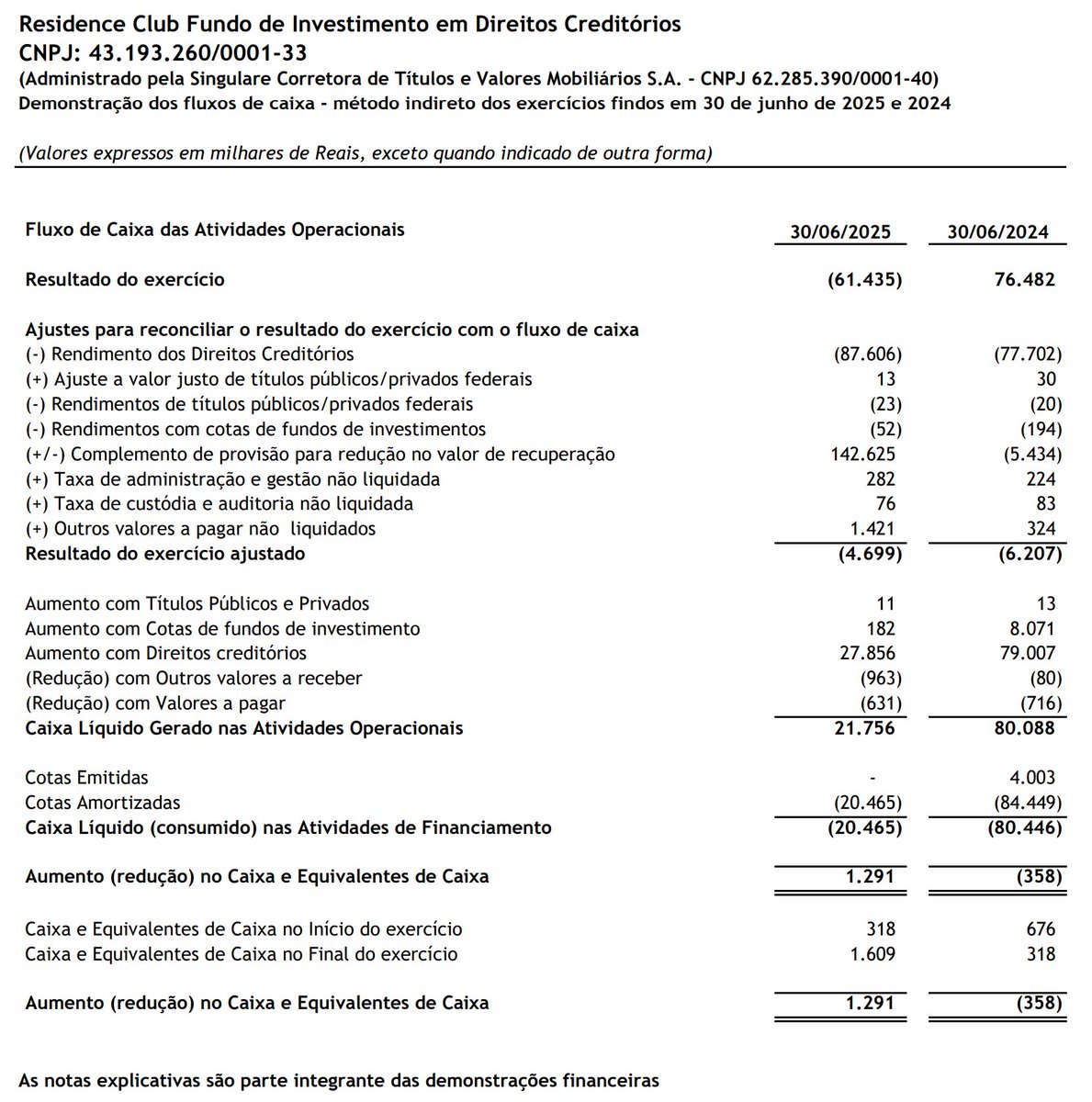
Demonstrações Financeiras 30/06/2025
Parecer de auditoria com Ênfases:
▶️Alienação fiduciária dos direitos creditórios: vide nota explicativa 24. Demanda Judicial envolvendo imóvel alienado fiduciariamente ao FIDC, em que o fundo não integra de forma direta, teve decretada a indisponibilidade da matrícula 2.189 do 2o Ofício de Paraipaba/CE. Que pode afetar as frações imobiliárias que compõem empreendimento em desenvolvimento.
▶️Desenquadramento do índice de subordinação: vide nota explicativa 13. Em 30jun25 o PL da classe subordinada representaca 0% do o PL do fundo (mínimo deveria ser 30%). Foi deliberado e aprovado plano de resolução de desenquadramento em até 163 dias, previsto para encerrar em 30jan2026.
Distratos:
▶️Segundo Nota Explicativa 6.7, no exercício encerrado em 30jun25, houve recompra e distrato de direitos creditórios de R$ 97,23mm (R$ 95,24mm no ano anterior). Representa 64,73% do total de baixas, cujo limite é 70%, portanto enquadrado dentro do regulamento (item 13.7).
fnet.bmfbovespa.com.br/fnet/…

5
447



Jan 9
Black & neon yellow fnet bra/thong. In/out of shows ‘till 5PMish ES... onlyfans.com/vanessawet
3
4
59

Update: 1) The fix is ready and tested. 2) Contract upgrades will be queued tomorrow.
- The increased fee conditions were recreated exactly on our FNet deployment, which includes a copy of Tinyman.
- dualSTAKE was confirmed to fail in the same way as on Mainnet
- The fix was upgraded after a reduced 1 hour timelock (FNet specific)
- dualSTAKE was confirmed to work after the upgrade
Testing notes available here: docs.google.com/document/d/1…
The contract upgrades will be queued tomorrow, January 8th, and will become applicable after 1 week.
Fix version: v1.2 github.com/MythFinance/dualS…
Upgrade notes available here: docs.google.com/document/d/1…
Note that older dualSTAKE contracts will be receiving the v1.1 upgrade as well - refer to upgrade notes for details.
Next steps:
- Queue smart contract upgrades to v1.2, ETA tomorrow January 8th
- Execute smart contract upgrades, ETA January 15th
1
1
16
431