
Jun 14
@EmiratesDraw Hi, I'm Tabrez from India with no UAE residency/Emirates ID. Your care said I can play.
As per T&C 3.1, can Indians without Emirates ID play WILD5,FAST5,MEGA7,PICK1 & claim prizes?
Will prize be paid without UAE proof? Pls confirm.
1
12

Randomly found Australia vs England Fast5 2017 and here’s some random thoughts:
- Marinkovich coaching Australia with brown hair
- Tania Obsts coaching England
- Kayla Stanton is a blast from the past I forgot all about
- Tippett has such a flat shot
Continued
3
26
3,205


Jun 3
You deserve more than one chance every month. 👀✨
With weekly draws across EASY6, FAST5 & MEGA7, your next big moment is always closer than you think.
🎟️ Buy now on emiratesdraw.com
#EDEASY6 #EDFAST5 #EDMEGA7 #EmiratesDraw #ForABetterTomorrow #Global

3
55
May 24
52 FREE Tickets are here!
✨ Buy 1 ticket each from MEGA7, EASY6, FAST5, PICK2 and PICK1 and enter the pool. Offer ends on 31st May.
🎟️ Buy now on emriatesdraw.com
#EidBonanza #52Tickets #EmiratesDraw #ForABetterTomorrow #Global

3
60

May 15
GT Fast5: AI-driven public engagement, a major education tech cyber incident, autonomous vehicle warnings for cities, AI tools for caseworkers, and a new cybersecurity threat governments are being told not to ignore. #GovTech #AI #Cybersecurity #SmartCities
2
99








Apr 29
Il y a 15 ans, Justin Lin accélérait avec #Fast5, cinquième opus des #FastAndFurious.
Le réalisateur attitré mélangeait l’essence de la saga aux films de braquages.
Acteurs, mis en scène, action vrombissante, nouveaux personnages, font de ce Five l’un des meilleurs.

2
2
15
317

Participación, debate y formatos innovadores en el programa científico del Congreso #SEOR2026 :
📢 Comunicación oral
🖼️ Discusión de póster
⚖️ Debates PROS vs CONS
🎙️ Formato rueda de prensa
⏱️ Fast5
❓ ¿Y ahora qué?
Tracks: Clínico | Humanización | Tecnológico | Multidisciplinar | Institucional
Muy pronto compartiremos más novedades de #SEOR2026 . De momento os dejamos este resumen para que os vayáis familiarizando con él.

1
3
206

Wczoraj zaczeliśmy a dziś do śniadania skończyliśmy Fast5. Powrót całej ekipy z 1 i 2 ekipa z 4 i The Rock. Aktorsko spoko, sceny i auta też. Cała akcja z sejfem widowiskowa - młody co chwila robił WOW, aczkolwiek nierealistyczna. I w tej części zaczęli już mocno przesadzać...
A szkoda bo sama historia była fajna i wciągająca (jak na film sensacyjny).
#Fast5 #SkyShowtime


Wczoraj było rodzinne domowe kino więc obejrzeliśmy Szybko i Wściekle czyli Fast&Furious4 ;)
Jedna z ostatnich "normalnych" części. Co prawda jazda w tunelach sztuczna w opór ale reszta w miarę realistyczna.
Pamiętam jak wszyscy byli w szoku kiedy uśmiercili Leticię.
#FastAndFurious #SkyShowtime

1
3
229

Apr 23
The integration of DRAGEN with nanopore sequencing platforms like the MinION -- devised by Oxford Nanopore Technologies -- creates a decentralized yet hyper-efficient surveillance network.
Unlike traditional sequencing systems that require massive infrastructure, the MinION is a palm-sized device that plugs into a laptop, capable of sequencing DNA or RNA in real time through nanopore technology. When a strand of genetic material passes through a protein pore, it disrupts an ionic current, producing a unique electrical signature that software decodes into base sequences.
This direct, amplification-free method captures long reads, often exceeding 100,000 bases, enabling the sequencing of entire bacterial chromosomes or viral genomes in a single run. The data is stored in the FAST5 format, a container for high-fidelity raw signal data that can be uploaded to cloud servers the moment sequencing is complete.
The Pandemic Blueprint: How Nanopore Sequencing, Bacterial Networks, and GATK Are Redefining Global Health
books.brightlearn.ai/The-Pan…
Apr 19

The Genome Analysis Toolkit (GATK)
The GATK is the industry standard for identifying single nucleotide polymorphisms (SNPs) & indels in germline DNA & RNAseq dapta. Its scope is now expanding to include somatic short variant calling, & to tackle copy number (CNV) and structural variation (SV). In addition to the variant callers themselves, the GATK also includes many utilities to perform related tasks such as processing & quality control of high-throughput sequencing data, & bundles the popular Picard toolkit.
gatk.broadinstitute.org/hc/e…
Genome Analysis Toolkit (GATK) PathSeq
We present an updated implementation of the PathSeq pipeline pmc.ncbi.nlm.nih.gov/article… that makes substantial improvements on the original version. First, computational efficiency has been improved by incorporating faster computational approaches. Second, unlike the original version, Genome Analysis Toolkit (GATK) PathSeq permits users to configure the workflow for multiple use cases such as different library types (i.e. whole-genome & RNA sequencing), sample types (e.g. blood, tissue, sputum, etc.), or host species. Third, the tool suite is implemented in Java w/ the GATK engine pmc.ncbi.nlm.nih.gov/article… & Apache Spark framework usenix.org/legacy/event/hotc… enabling parallelized data processing on local workstations, computing clusters & Google Cloud computing services. cloud.google.com
In summary, we have developed an adaptable & easily configurable pipeline for identification of microbial sequences in next gen sequencing data. This tool allows for customized analyses of biological samples w/ substantially reduced computational time.
pmc.ncbi.nlm.nih.gov/article…
The Genome Analysis Toolkit 4 (GATK4)
GATK4 aims to bring together well-established tools from the GATK & Picard codebases under a streamlined framework, & to enable selected tools to be run in a massively parallel way on local clusters or in the cloud using Apache Spark.
github.com/broadinstitute/ga…
Picard
Picard is a set of command line tools for manipulating high-throughput sequencing (HTS) data & formats such as SAM/BAM/CRAM & VCF.
broadinstitute.github.io/pic…
Picard is implemented using the HTSJDK Java library HTSJDK to support accessing file formats that are commonly used for high-throughput sequencing data such as SAM & VCF.
github.com/broadinstitute/pi…
HTSJDK
A Java API for high-throughput sequencing data (HTS) formats.
github.com/samtools/htsjdk
Apache Spark™
Apache Spark™ is a multi-language engine for executing data engineering, data science, & machine learning on single-node machines or clusters.
spark.apache.org/
At the heart of the Genome Analysis Toolkit (GATK) is an industrial-strength infrastructure & engine that handle data access, conversion & traversal, as well as high-performance computing features. This includes parallelization using Apache Spark & optimized usage of cloud infrastructure. On top of that lives a rich ecosystem of specialized tools that u can use out of the box, individually or chained into scripted workflows, to perform anything from simple data diagnostics to complex reads-to-variants analyses.
Genome Analysis Toolkit v4.6.1.0 (GATK) Tool Set
gatk.broadinstitute.org/hc/e…
The goal of the Allele-Specific filtering workflow is to treat each allele separately in the annotation, recalibration & filtering phases.
gatk.broadinstitute.org/hc/e…
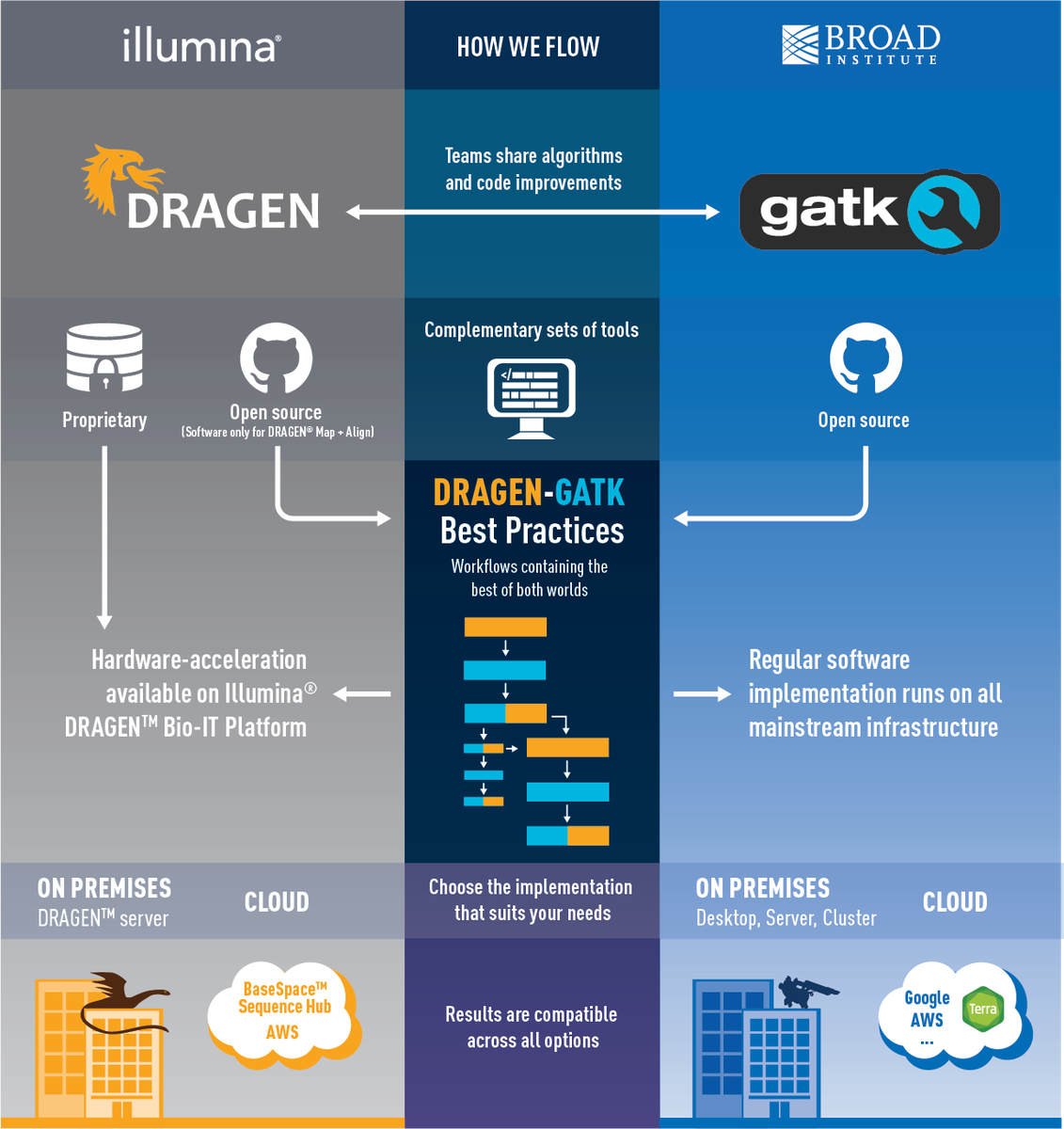
DRAGEN-GATK
Combining Illumina's hardware accelerated data analysis platform w/ the Broad Institute's variant discovery pipelines.
gatk.broadinstitute.org/hc/e…
Under the hood, Illumina's DRAGEN (Dynamic Read Analysis for GENomics) uses FPGAs (Field-Programmable Gate Arrays) to deliver phenomenal speed-ups to their GATK-based germline short variant discovery pipeline. This reduces the end-to-end runtime from over 23 hours down to about 22 minutes on average for a single whole genome sample, starting from unmapped reads & delivering a GVCF &/or a filtered VCF.
gatk.broadinstitute.org/hc/e…
9
25
1,091

Apr 22
Everyone should take a look at their SARS-COV-2 Template.
You want proof these bacteriophages are gonna be used in the upcoming plandemics?
PHA4GE field "fasta filename".
Public Health Alliance for Genomic Epidemiology (PHA4GE)
PHA4GE, a global network, also develops tools and resources, such as standardized data specifications for pathogen monitoring, to support effective genomic epidemiology.
github.com/pha4ge
Public Health Alliance for Genomic Epidemiology (PHA4GE)
pha4ge.org/
THEY USE MINION TO TRANSFER INFORMATION !!!!
That microbit is important. Look at their data transfer.
They use bacteria !!!!!!
Minion Data Transfer
Script to handle uploading minion fast5 files to a server for further processing
github.com/Public-Health-Bio…
MinION FAST5 files are the primary raw data output from Oxford Nanopore Technologies' MinION sequencers, stored in the hierarchical HDF5 binary format, which allows for the storage of complex and large datasets.
timkahlke.github.io/LongRead…
MinION
The MinION can sequence entire bacterial genomes in a single run, with improved accuracy using newer R9.4 flow cells and base-calling software like Dorado, facilitating the assembly of complete bacterial genomes
pubmed.ncbi.nlm.nih.gov/3954…
IONTORRENT
A number of laboratories have reported success with the Ion AmpliSeq SARS-CoV-2 Research panel for the IonTorrent S5 platform.
Amplicon strategies, such as ARTIC, should also work for the S5, and we'd welcome the addition of any working protocols and other resources to this section.
Ion AmpliSeq SARS-CoV-2 Research Panel for GeneStudio S5
assets.thermofisher.com/TFS-…
Ion AmpliSeq SARS-CoV-2 Research Panel for the Genexus System
assets.thermofisher.com/TFS-…
They created the SARS-COV-2 TEMPLATE
SARS-CoV-2 Contextual Data Specification - Collection template and associated materials for SARS-CoV-2 metadata
github.com/pha4ge/sars-cov-2…
THIS TIES INTO UPCOMING PLANDEMICS !!!!!
Remember Minion is the Infected Trigger !!!!!!!!
Microbit Infection
Public Events Microbit Epdemic: Preparation
github.com/mrc-ide/public-ev…
The term "Infected Minion Microbit" could refer to different concepts based on the context. Here are the relevant details:
Microbit Zombies:
This is a project where microbits are programmed to simulate a zombie outbreak. Each microbit has a health value, and if it gets too close to an infected microbit, it loses health.
web.archive.org/web/20200810…
If the health reaches 0, the microbit becomes infected and displays a skull icon.
The infection is random, with a 1 in 100 chance of a microbit being infected at the start of the game.
jbcstudios.miraheze.org/Infe…
Infected Minion:
This refers to a game mechanic in a game where minions can be infected. These infected minions have reduced health and can be spawned by certain actions, such as Dock hitting a corpse
makecode.microbit.org/projec…
Infection Game:
This is a distributed game that simulates the spread of an illness using microbits. The game involves a master microbit that infects a player, and the infection spreads when microbits are close enough
makecode.microbit.org/course…
The game has different states, such as healthy, incubating, sick, and dead, and the goal is to stop the outbreak before all players die
support.microbit.org/support…
Microbit & Viruses:
It is important to note that the microbit cannot be infected by a virus or malware. The microbit is a virtual device used to copy programs or firmware updates, and it only recognizes .hex and .bin file types.
learn.microsoft.com/en-us/ar…
Bacteriophages Are Viruses by Definition
sciencedirect.com/topics/med…
They are a specific type of virus that infects and replicates within bacteria. According to the legal and scientific consensus, bacteriophages (or phages) are classified as viruses because they:
Consist of a nucleic acid genome (DNA or RNA) enclosed in a protein capsid
Depend entirely on a host cell's machinery to replicate
Are obligate intracellular parasites
pmc.ncbi.nlm.nih.gov/article…
1
9
7
405
Apr 19
Good moments don’t fade… they remind you what’s possible. ✨
Daniel Elsadany’s $13,000 win with FAST5 is proof.
🎟️ You could be next at emiratesdraw.com
#EmiratesDraw #EDFAST5 #ForABetterTomorrow #Global
1
2
53

Apr 17
FAST5 BEBEK 🌊🚀
Age Categories 🥉🏆
⏱️ 10km | 🏁 41:29 | ⚡️4:12 pace
Mizuno Türkiye takımı olarak, Türkiye’nin en hızlı yarış konsepti olan Fast5 Bebek’de Bebek sahilinin eşsiz atmosferinde Hyperwarp Series ile sadece bir yarışa değil, baştan sona yüksek tempolu bir deneyime imza attık.
Start anından itibaren hissedilen o adrenalin.Deniz kenarında akan bir parkur, ritmini bulan adımlar ve aynı hedefe odaklanmış bir ekip. Her şey kusursuz bir uyum içindeydi. Hız sadece kronometrede değil hislerde, bakışlarda ve birlikte koşmanın verdiği güçteydi.
Takım olarak enerjimiz yüksekti, motivasyonumuz ortaktı. Her birimizin temposu farklı olsa da kalbimiz aynı ritimde attı. Birbirimizi desteklediğimiz, aynı heyecanı paylaştığımız ve her anını dolu dolu yaşadığımız bir yarış oldu.
Bu sadece bir yarış değildi.Bu, takım ruhunun en saf hali,birlikte daha güçlü olduğumuzu bir kez daha hatırladığımız bir deneyimdi.
Ve bu güzel hikayenin içinde, benim için ayrı bir anlam taşıyan bir an daha vardı…
Yarışta yaş kategorimde 3.’lük elde etmek beni inanılmaz mutlu etti. 🥉
Sezonun henüz başındayken gelen bu sonuç, sadece bir derece değil; doğru yolda olduğumu hissettiren, motivasyonumu katlayan ve önümdeki yarışlar için bana büyük bir güç veren bir başlangıç oldu.Bu başarımda en büyük teşekkürü Coach Mehmet Soytürk’e ediyorum.Birlikte nice başarılara coach.
Her zaman desteklerini büyük bir şekilde hissettiren ve bana güç katan Mizuno ailesine , Polar ailesine , İngobio ailesine , Therahub ailesine , Hakii ailesine ve StronGrips ailesine sonsuz teşekkür ederim iyi ki varsınız.Birlikte güzel başarılar biriktirelim.
Bu harika yarış organizasyonu için Fast5 ve Dust Event ekibine çok teşekkür ederim unutulmaz bir deneyim yaşadım.
Unutulmaz anlar, güçlü finishler, paylaşılan gülümsemeler ve içimizde kalan o eşsiz enerji.Bebek sahilinde koştuğumuz bu yarış,hafızamda sadece bir performans olarak değil, birlikte yazılmış bir hikaye olarak kalacak. #mizuno #mizunorunning #mizunoambassador #mizunoathlete




55

Just opened up a few more uses of "fast5" to get your first month of degenelytics.com for $5
*whispers; there are sites that charge significantly more for like, individual pieces of my website*

🚨The individual batter pages are back🚨
Click on the hitters name to open up their
⚾️Game Log
⚾️Weather Report
⚾️Splits; R/L, Home/Road, and Day/Night
⚾️Opposing SP Stats/Mix
⚾️ExVelo Data
⚾️Batter Pitch Mix Data (auto matched to SP's mix)
degenelytics.com $10/month
3
4
13,863

Apr 3
These systems are using our biosignals to feed the applications via FASTA, FAST5 & FASTQ Files. This is why the SARS-COV-2 Metadata Template is mapped to the DHIS2 software program.
SEE FOR YOURSELF
docs.google.com/spreadsheets…
2
4
63
VERY LIMITED SPOTS
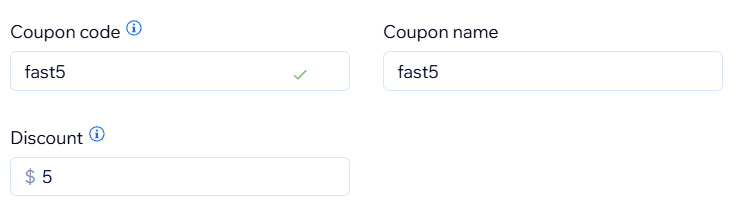
If you're fast, get $5 off your first month of degenelytics.com with code "fast5"
Limited spots and when they're gone, they're gone.

2
3
12,178

Apr 1
In the high octane env't of the FAST5, Sawyer's "outside -in" strategy empowered She Cranes' shooters to exploit the three point arc with clinical precision. Under her guidance, the team moved away from speculative long range efforts toward high percentage, structured play.
1
1
2
31