
chino retweeted

FlashMemory-DeepSeek-V4
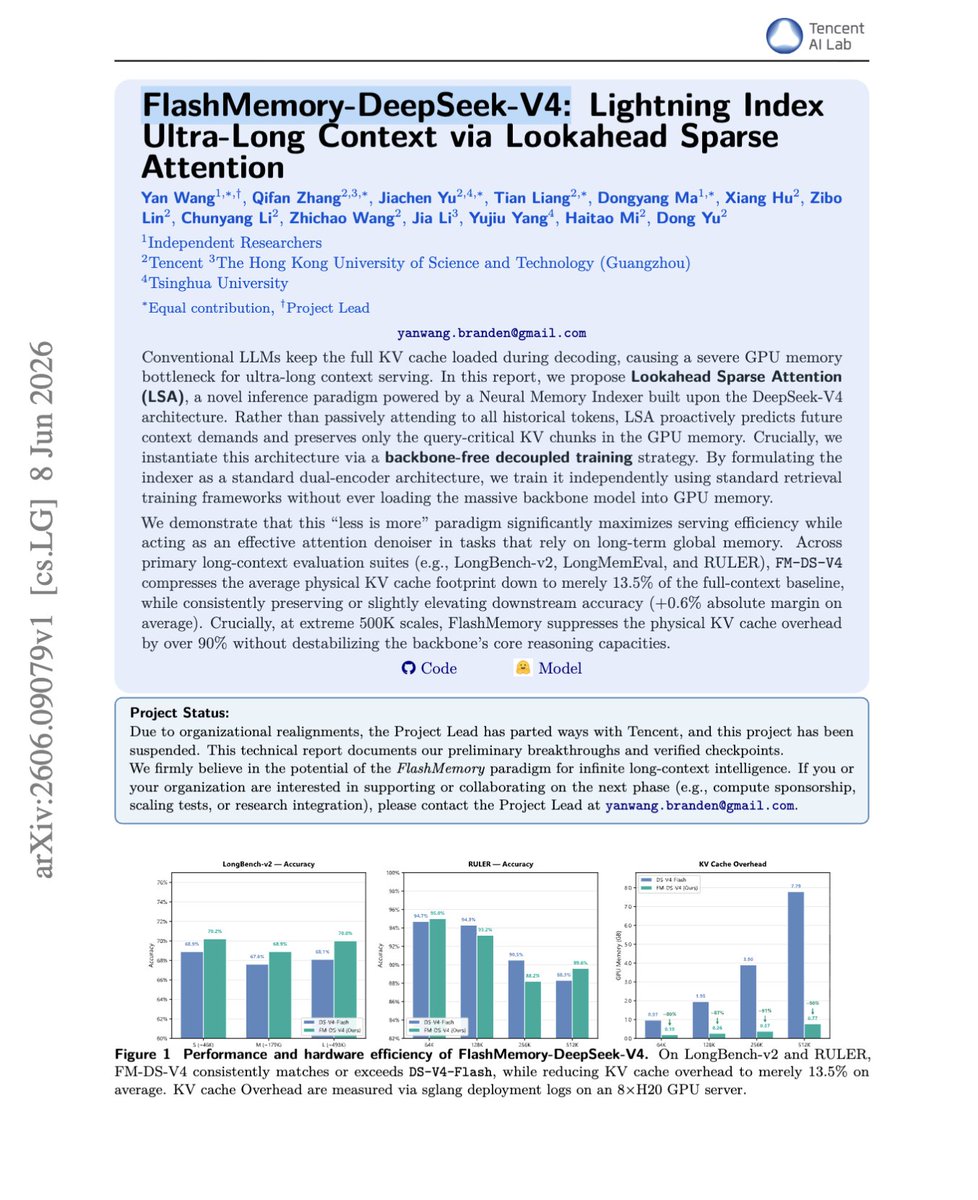
Lookahead Sparse Attention cuts the KV cache by over 90% at 500K context, compressing it to just 13.5% of full size while maintaining or improving accuracy on RULER, LongBench-v2, and LongMemEval.

3
7
64
2,483

Innovative hardware security techniques use 3D V-NAND flash memory to hide and selectively reveal cryptographic information, enhancing resistance against physical tampering and data extraction attacks.
#CyberSecurity #HardwareSecurity #Encryption #FlashMemory #cryptography

2
22
Kevin John Parrish retweeted

FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Yan Wang, Qifan Zhang, Jiachen Yu, Tian Liang, Dongyang Ma, Xiang Hu, Zibo Lin, Chunyang Li, Zhichao Wang, …
arxiv.org/abs/2606.09079 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙰𝙸]
💬Code: github.com/libertywing/Flash…
1
1
108

Jun 12
Long context on GPU is still a memory problem. FlashMemory fixes that for DeepSeek-V4.
- Retriever predicts which KV chunks the next tokens need
- Keeps only ~10–15% of CSA KV cache on-device
- Matches or beats full-attention on long-context reasoning
github.com/libertywing/Flash…
22

FlashMemory-DeepSeek-V4 applies lookahead sparse attention to prune the KV cache based on predicted future weights. Targets ultra-long context decoding. The failure mode to watch: perplexity on retrieval tasks. That's where lookahead assumptions break. #LLMs
21

Jun 12
魔法! DeepSeekV4 上下文内存压缩到1/10!
大家都知道 DeepSeekV4 是支持1M上下文的, 而且经过了极度优化, 如果要真的用到1M上下文, 显存占用只需要10G左右, (对比之下 DeepSeek-V3.2 大概需要84G显存). 然后我刚看到了FlashMemory这个论文, 直接能把显存占用压到 1.3GB! 甚至输出效果不降反升!
哥们你骗兄弟可以, 骗自己就没意思了, 真的吗? 压缩后反而性能上升? 我赶紧看了论文细节:
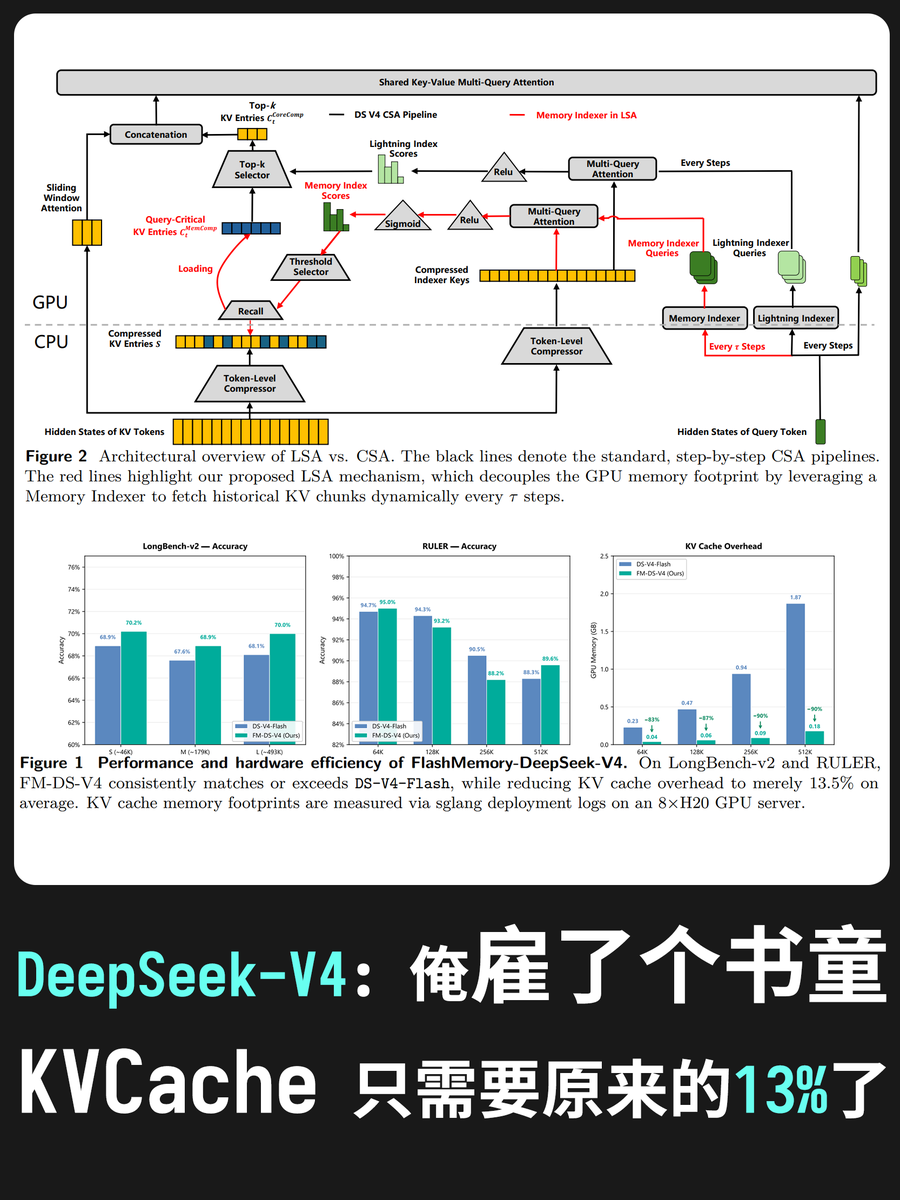
咱们先复习一下传统做法: 模型每吐出一个字,都要把之前的几十万字重新看一遍(这就是全局注意力).
FlashMemory 的做法是: 预测未来需要什么, 它内置了一个神经内存索引器(Neural Memory Indexer, 其实就是个小模型了),能够主动预判接下来生成内容时需要用到历史文本里的哪些片段. 然后预先准备好这些片段, 接下来只要做到命中率超高, 那么这个提升就绝对有效. 即它的假设是, KVCache里面的东西并不是生成每个字的时候全都需要的, 只需要按需提前加载即可.
很像做作业的时候, 把参考资料摊满桌子, 然后优化了一下就是把参考资料需要用到的部分直接拍照, 用的时候看照片就行了.
那么听上去很简单, 但实际的难点在于, 训练一个专用的索引器小模型, 需要把 DeepSeek-V4模型加载到显存里一起炼. 相当耗费算力.
于是这篇论文第二个亮点来了, 它搞了个解耦训练. 他们把这个索引器当成一个标准的"双编码器(Dual-encoder,类似做搜索推荐的模型)"来单独训练. 在这个过程中,根本不需要把庞大的 DeepSeek-V4 基座模型加载到显存中. 这让训练成本断崖式下降,且兼容标准的检索(Retrieval)训练框架. (简单来讲就是它是通用方法训练的, 通过query预测需要检索哪些长句子. 所以其实是个通用模型)
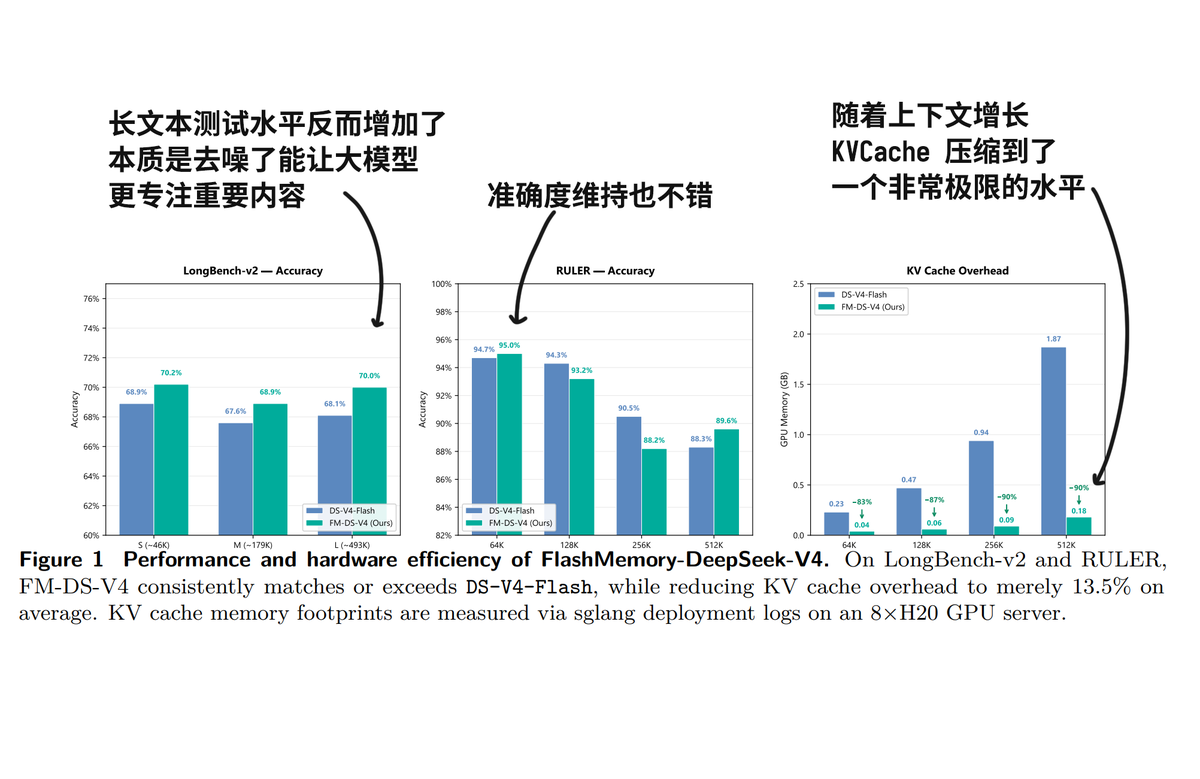
听上去靠谱, 那也只是显存占用少了, 怎么就性能还提高了呢? 答案是注意力降噪. 因为每次只提取和当前生成最相关的记忆块(Chunks)放入显存,模型在运算时就看不见那些无关的冗余信息了.天然地起到了一种"去噪"作用,这也是为什么显存占用少了,模型准确率反而略微提升的原因.官方测试在长文本评测集(如 LongBench-v2 等)上的准确率平均最终提升了 0.6%.
(其实还有数据如何逐出显存和如何预测数据实现预加载, 这部分也很棒, 很有启发性. 建议看原论文, 篇幅原因写不下了)
论文地址: arxiv.org/abs/2606.09079
项目地址: github.com/libertywing/Flash…
#FlashMemory #DeepSeekV4 #FlashMemoryDeepseekV4

17
18
223
27,529
A.Adarsh Jagannath retweeted

Jun 9
“FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention”
With how Long context LLMs are being bottlenecked by KV cache, because every old token keeps consuming GPU memory even when most of it is irrelevant, this paper turns long context into retrieval.
They used a small Memory Indexer to predict which old KV chunks the model will need soon, keeps only those on GPU, and leaves the rest offloaded.
This provides 13.5% average KV cache footprint, up to 90% memory reduction at 500K context, with slightly better accuracy than DS V4 Flash.
4
38
219
8,728

Jun 11
Paper page - FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention share.google/xknRj6QVoe2ndzD… Meanwhile, someone is trying to get a LSTM to train quickly. Matmul seems to be the limiting factor which I have 2 hacks for. Zeroing, caching & selecti
18

AIモデルの進化と倫理的課題:最新動向を詳しい考察
DiffusionGemma、FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention、Cybersecurity
kurage.exbridge.jp/kuragev.p…
#Kurage #AI動画
1,089