#GRNET participated in the #DigitalNetworksAct discussion in Athens, with GRNET Deputy Chairman D.Katsianis highlighting the key role of public digital infrastructures, R&E networks & HPC, in enabling AI, innovation and resilient connectivity in 🇪🇺
More: bit.ly/4ep5wYq




31




Bierzemy udział w europejskim projekcie pilotażowym APTITUDE. Nasi specjaliści testują w nim rozwiązania, które wkrótce mogą pojawić się w Europejskim Portfelu Tożsamości Cyfrowej.
🆕 Interesuje Cię, jak kształtuje się cyfrowa przyszłość Europy i jak ją tworzymy wraz z innymi ekspertami z UE❓
Zachęcamy do subskrypcji oficjalnego newsletteru projektu w języku angielskim. Znajdziesz w nim najważniejsze informacje, wydarzenia i aktualności związane z pracą nad Europejskim Portfelem Tożsamości Cyfrowej.
Zapisz się już dziś i bądź na bieżąco z tym, co się dzieje w APTITUDE! 👉 aptitude.digital-identity-wa…
#AptitudeEU #EUDIWallet #DigitalIdentity #GRNET #DigitalEurope

1
100

🚨 Registration is officially open for the @SONICProject_EU Stakeholders Event!
Join @d1m1tr0 from @grnet_gr as he presents "The GRNET Security Blueprint: Safeguarding Public Services and Infrastructures at Scale."
👉 forms.gle/Ziqez4oJE9jyXrGD9
#SONICProject #Cybersecurity #GRNET

4
8
60
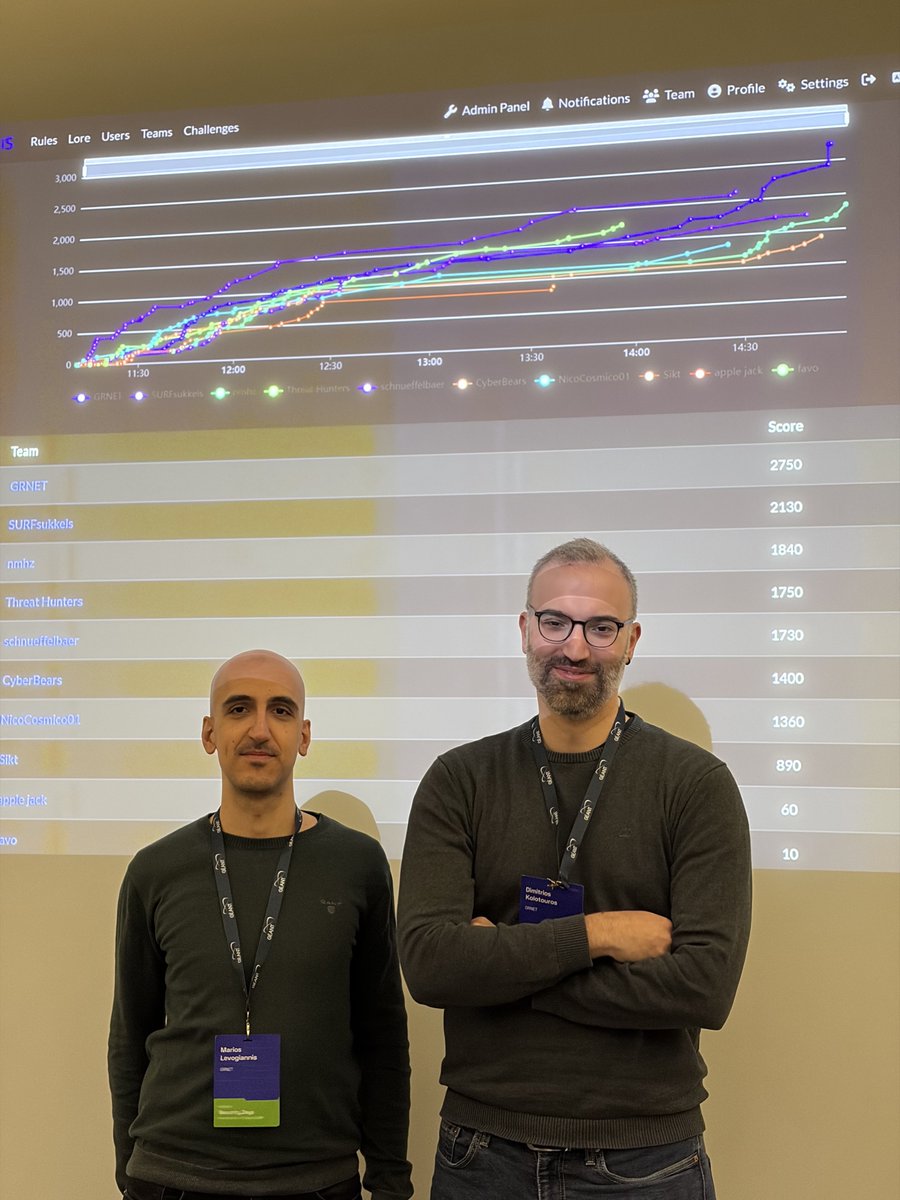
🏆GRNET’s cybersecurity team was featured by the #GÉANT Community following its 1st place win in the CTF competition at GÉANT #SecurityDays 2026.
🔗Read more👉 shorturl.at/ESHye
#GRNET #CyberSecurity #CTF #NREN

1
5
130

May 14
初参加ライブを思い出してる。
2005年ポルノグラフィティ。THAMP χツアー
2008年GRNET CROW LOCKSツアー
2012年フジファブリック SLS2012
この時レキシも初。ラバッパー卒業
2013年GRNET CROW 解散ライブ
2015年12月USG CITS
ここから10年フジとUSGを追いかけ彷徨い今迷子。
2
200
🏆 GRNET wins 1st place at GÉANT #SecurityDays CTF!
#GRNET cybersecurity team excelled in advanced, real-world challenges in Utrecht 🇳🇱, represented by Dimitris Kolotouros & Marios Levogiannis.
🛡️ Strengthening cybersecurity for research & education
📎shorturl.at/jNA1t
3
6
215

Mar 20
2
60

Τόσο μαλάκες είστε, κάνετε πλοκ το πρώτο τρολ του grnet , το πρώτο τρολ που έγραφε/μιλουσε Ελληνικά, με το όνομα "Banned" και δε ξέρετε τι ειναι καν το Grnet.
Είμαι το πρώτο τρολ του Ελληνικού backbone ρε μαλακες, ηλιθιοι, εχω ιστορική αξία που με μπλοκαρετε κατι κανετε
2
2
98
✨@hellasqci, coord. by #GRNET, participates in the Q-PrEP (Quantum Preparedness) Workshop
⏰ 5/2/26 |📍@NCSR_Demokritos
Experts collaborate on post-quantum security & quantum-safe communications.
🔗Details: shorturl.at/CNmpm
📝Registration: shorturl.at/7zaxU
Feb 3

✨HellasQCI at the Q-PrEP (Quantum Preparedness) Workshop
⏰ 5 Feb 2026 | 📍 Athens (NCSR “Demokritos”)
Experts collaborate to address post-quantum security challenges & advance quantum-safe communications.
🔗Details: shorturl.at/TeglV
📝Registrer: shorturl.at/2OnWP

2
2
102
Jan 28
Living the dream. Somehow I'm back doing controller reticule aiming systems...but on a PC game now. :)
Time is a closed circle.
2
13

Jan 21
Η ελληνική κυβέρνηση, μέσω του Υπουργείου Ψηφιακής Διακυβέρνησης και του Εθνικού Δικτύου Υποδομών Τεχνολογίας και Έρευνας (GRNET), έχει υπογράψει τις συμβάσεις για την κατασκευή του νέου υπερυπολογιστή “ΔΑΙΔΑΛΟΣ” και του συνοδευτικού Κέντρου Δεδομένων στο Τεχνολογικό και Πολιτιστικό Πάρκο Λαυρίου. Το έργο, με προϋπολογισμό περίπου 58,9 εκατ. € και χρηματοδότηση από το Ελλάδα 2.0 (RRF) και την EuroHPC JU, περιλαμβάνει την προμήθεια των υπολογιστικών συστημάτων (ανάδοχος Hewlett Packard Enterprise) και την εκτέλεση των ηλεκτρομηχανολογικών εργασιών (ανάδοχος MainSys). Ο “Δαίδαλος” θα έχει ισχύ περίπου 89 PetaFLOPS, δηλαδή περίπου 150 φορές μεγαλύτερη από τον υπάρχοντα ελληνικό υπερυπολογιστή ARIS, και αναμένεται να καταταχθεί πολύ ψηλά σε ευρωπαϊκές και παγκόσμιες λίστες υπερυπολογιστών (TOP500 / Green500).
Η ΕΜΥ δεν έχει κάνει ενεργειες για να ενταχθεί ως αυτοτελής Υπηρεσία. Ισω γίνει αυτο μέσω του ΥΠΕΘΑ
2
11
74
2,352

4 Dec 2025
•Barcelona Supercomputing Center (Spain)
•CINECA (Italy)
•CSC (Finland)
•GENCI/CEA (France)
•GRNET (Greece)
•Jülich Supercomputing Center (Germany)
•Linköping University (Sweeden)
•LuxProvide (Luxembourg)
•Poznan Supercomputing Center (Poland) Sofia Tech Park (Bulgaria)
1
1
111

18 Nov 2025
BREAKING $AMD & Eviden 🚀🚀🚀
SANTA CLARA, Calif. and PARIS, Nov. 18, 2025 (GLOBE NEWSWIRE) -- @AMD (NASDAQ: AMD) and Eviden, the Atos Group product brand leading in advanced computing, announced their selection to build Alice Recoque, a next-generation supercomputer to support the need for high performance computing (HPC) and AI, serving as an AI Factory. Alice Recoque will be France’s first and Europe’s second Exascale supercomputer, led by Grand équipement national de calcul intensif (GENCI), operated by Commissariat à l'énergie atomique et aux énergies alternatives (CEA), and powered by next-generation AMD AI and HPC compute technologies.
This project, representing an overall cost of 544 million euros, is funded by EuroHPC JU, with budget stemming from the Digital Europe Programme (DEP), and the Jules Verne Consortium, led by Francethrough GENCI and CEA with the participation of Netherlands IT cooperation SURF and Greece with GRNET.
"We are committed to enabling the next generation of innovation across AI and HPC,” said Dan McNamara, senior vice president and general manager, Compute & Enterprise AI, AMD. “The Alice Recoque supercomputer represents a major step forward for European sovereign AI, uniting national ambition, regional collaboration, and AMD’s high-performance and AI compute technologies. Through our continued collaboration with EuroHPC JU, the Jules Verne Consortium, and Eviden, we are proud to support Europe’s scientific and industrial leadership with a platform purpose-built for scale, efficiency and discovery."
Emmanuel Le Roux, Group SVP, Global Head of Advanced Computing and AI, Eviden at Atos said, “Alice Recoque represents another critical step toward Europe’s digital future, defined by a sovereignty, sustainability and scientific excellence. As a catalyst for scientific and industrial breakthroughs, from climate modeling and healthcare to advanced materials and AI innovation, it will empower researchers and industries across Europe. Born from a shared European vision, this AI Factory reflects on what we can achieve collectively toward a common goal. Eviden is fully dedicated to its success, bringing deep expertise, a collaborative spirit, and a long-term dedication to responsible technological leadership.”
An AI-HPC Factory to Tackle Europe’s Most Pressing AI Challenges
Alice Recoque will tackle Europe’s most pressing societal, scientific, and industrial challenges by combining large-scale simulations, data analysis, and AI.
Alice Recoque covers the entire computing lifecycle, integrating cutting-edge hardware, advanced AI software and proven AI use cases to deliver scalable high-impact solutions. This comprehensive project is a live implementation of the strong collaboration and commitment from Eviden and AMDto accelerate research and industrialization of AI use cases, with a major investment in both human and technological resources.
The Alice Recoque system is powered by next-gen AMDEPYC™ CPUs, codenamed “Venice,” AMDInstinct™ MI430X GPUs—a new MI400 Series accelerator engineered for sovereign AI and scientific computing— and AMDFPGAs, interconnected by Eviden’s network solution (BXI) into its newest BullSequana XH3500 platform, with DDN storage.
This powerful system will enhance climate modeling, accelerate innovation in materials and energy, enable digital twins for personalized medicine, and support next-gen European AI models.
Reaching Exascale with Fewer Resources and Reduced Energy Consumption
Composed of 94 racks, Alice Recoque is expected to be one of the top supercomputers in Europefor double-precision HPC workloads. It will also offer exceptional memory performance enabling deeper insights, faster simulations, and more scientific breakthroughs.
With 25 percent less racks and components than other Exascale systems and up to 50 percent better energy efficiency per GPU, Eviden’s architecture will enable Alice Recoque to deliver maximum performance at minimum cost and power, to meet Europe’s demanding green computing goals.
Alice Recoque supports advanced AI data types from the AMDInstinct MI430X GPUs, including FP4 and FP8, providing leadership AI FLOPs. Each GPU integrates 432 GB of HBM4 memory and 19.6 TB/s of bandwidth which will enable Alice Recoque to deliver leadership capacity and throughput per GPU.
Eviden’s integrated hardware and smart software, powered by AMDHPC and AI technologies, will deliver leading computing power with improved application workload energy efficiency. Real-time monitoring and energy optimization are enabled by Eviden’s Argos intelligent software, while its unique 5th generation Direct Liquid Cooling technology uses warm water to cool 100% of all-in-one rack components, delivering efficiency and sustainability at scale.
16 Nov 2025

$AMD 40-50% Growth & $META CapEx Strategy 🧵
@Meta is aggressively scaling its AI infrastructure to power Llama models, recommendation systems, and consumer-facing features like AI-generated content and assistants. CapEx refers to the cash Meta spends on long-term assets, with AI-focused CapEx dominating covering data centers, servers, GPUs, CPUs, networking, and power/cooling systems. After Q3 ER, Meta's full-year 2025 CapEx guidance is $70–72 billion (up from an initial $60–65B in January and $66–72B in July), a ~81% YoY increase from 2024's ~$39B. This funds ~1 GW of new compute capacity, bringing total GPUs to >1.3 million by year-end.
How to understand Meta CapEx Allocation:
~Hardware (GPUs/CPUs/Servers: 60–70%, ~$42–50B): Dominates for AI accelerators and compute nodes.
~Data Centers/Facilities (20–25%, ~$14–18B): Includes a planned 2.2 GW Louisiana site (equivalent to two nuclear plants) and global expansions.
~Networking/Power/Cooling (10–15%, ~$7–11B): Rack-scale designs like Open Rack Wide (ORW) for dense AI clusters.
~Software/Other (5%, ~$3–4B): ROCm optimizations and in-house MTIA chips (but <10% of spend).
Meta is AMD's largest hyperscaler customer, hedging NVIDIA (58–70% of GPU spend) with AMD for diversification, cost (20–30% savings), and open ecosystems (ROCm vs. CUDA). This includes MI-series GPUs for inference/training and EPYC CPUs for servers.
AMD Instinct MI Series (GPUs: ~$7–10B, 70–75% of AMD allocation)
~Current (MI300X/MI325X): Meta deployed ~250K MI300X units (equiv. 600K NVIDIA H100s in perf), powering all Llama 405B inference. Handles 70% of workloads ( AI stickers, image editing).
~(MI350/MI355X, H2 2025): 250–300K units allocated (~$6–8B at $25–30K/unit vol. discount). Excels in inference (35x gen-over-gen uplift, 288GB HBM3E). Meta co-optimized for ORW racks; testing shows 1.5x faster Llama inference vs. NVIDIA H200 at 40% lower cost/token
~Future (MI450, 2026): Lead partner for Helios racks (72-GPU clusters, 6.4 EFLOPS). Expected 800K units (~$24B at $30–35K/unit), part of 1–2 GW ramp. Zuckerberg hinted at "massive" 2026 buys post-OpenAI's 6GW AMD deal.
~Why MI series? 2–4x better price/perf for inference; ROCm maturity (80% parity with CUDA) and a reliable supplier. Total 2025–2028: 800k–1m units/year.
~Meta runs >1.5M EPYC units globally (5th Gen "Turin" for Grand Teton platform). Powers deep learning recs and memory-intensive tasks.
~Expecting massive ramp up on 2026 EPYC "Venice" due to chiplet breakthrough design.
But things changed after Creative Financing with Blue Owl
Meta's headline $70–72B 2025 CapEx (Q3 guidance, up ~81% YoY) captures on-balance-sheet spend, but total effective AI infrastructure investment balloons to $90–100B when factoring in these creative vehicles. The Blue Owl JV alone adds ~$27B in "ghost CapEx"—funded externally but enabling Meta's 1 GW compute ramp (total GPUs >1.3M by YE). This hybrid model (PE bonds leasebacks) lets Meta retain operational control while Blue Owl's funds ( anchored by PIMCO's $18B debt tranche) shoulder 80% of the risk/ownership.
~Structure: Meta contributes 20% equity ($5.4B), gets a $3B upfront payout, and leases the asset back on 4-year terms (not long-term liabilities under GAAP). Debt stays in the SPV, not Meta's books.
~Scale Acceleration: Enables 2–3x faster builds Hyperion (Richland Parish, LA) will house 500K GPUs by 2027, equivalent to two nuclear plants' output. Without this, Meta's grid/power constraints (permitting delays) would cap growth at 500–700MW.
Basically due to this creative financing structure, $META can spend 1.5-2x more on $AMD CPU/GPU in 2026-2030.
AMD stands at the precipice of a decade-defining growth explosion, poised to deliver 40–50% compound annual total revenue growth from 2026 through 2030, catapulting its top line from ~$34 billion in 2025 to $180–220 billion by 2030, a 5–6x expansion. This isn’t speculative hype; it’s grounded in Meta’s revolutionary $27 billion Blue Owl JV, which acts as a force multiplier for AMD’s Data Center dominance, unlocking unprecedented scale in AI accelerators (MI series) and server CPUs (EPYC) without the traditional constraints of CapEx, power, or grid bottlenecks.
Meta’s off-balance-sheet financing model structured via SPVs, leasebacks, and private credit at 6–7% yields removes the ceiling on compute deployment. Hyperion, the 2.2 GW AI supercluster in Louisiana, will host over 1 million AMD GPUs and 2 million EPYC cores by 2027-2028, with MI450X-powered Helios racks delivering 6.4 ExaFLOPS per cluster at 30% lower power density than NVIDIA equivalents. $META can easily scale 5GW with AMD CPU/GPU into 2030 with higher AI CapEx allocation in the coming years. This isn’t just efficiency, it’s strategic lock-in: Meta’s open-architecture ORW standard and ROCm co-optimization make AMD the default inference engine for Llama 4/5, Reels AI, and next-gen agents.
4
47
5,734

18 Nov 2025
$AMD AMD und Eviden errichten Alice Recoque, Frankreichs ersten und Europas zweiten Exascale-Supercomputer, der als leistungsstarke KI-Fabrik dienen soll.
Das €544 Mio. teure Projekt wird vom französischen GENCI geleitet, vom CEA betrieben und mit modernsten AMD-KI- und HPC-Technologien ausgestattet.
Finanziert wird es gemeinsam von der EuroHPC Joint Undertaking sowie dem Jules-Verne-Konsortium unter Führung Frankreichs mit Beteiligung der Niederlande (SURF) und Griechenlands (GRNET).
1
3
96

18 Nov 2025
📢 𝐉𝐔𝐒𝐓 𝐈𝐍: $AMD AMD and Eviden to Power Europe’s New Exascale Supercomputer, the First Based in France
AMD and Eviden, the Atos Group product brand leading in advanced computing, announced their selection to build Alice Recoque, a next-generation supercomputer to support the need for high performance computing (HPC) and AI, serving as an AI Factory. Alice Recoque will be France’s first and Europe’s second Exascale supercomputer, led by Grand équipement national de calcul intensif (GENCI), operated by Commissariat à l'énergie atomique et aux énergies alternatives (CEA), and powered by next-generation AMD AI and HPC compute technologies.
This project, representing an overall cost of 544 million euros, is funded by EuroHPC JU, with budget stemming from the Digital Europe Programme (DEP), and the Jules Verne Consortium, led by France through GENCI and CEA with the participation of Netherlands IT cooperation SURF and Greece with GRNET.
1
1
16
2,160
#GRNET joined #PSValueTalks2025 on 11 November at the National Gallery, Athens. S. Kollias presented how #PHAROSAIFactory supports culture, creativity and responsible AI innovation.
More👉bit.ly/481DvCK

1
3
110
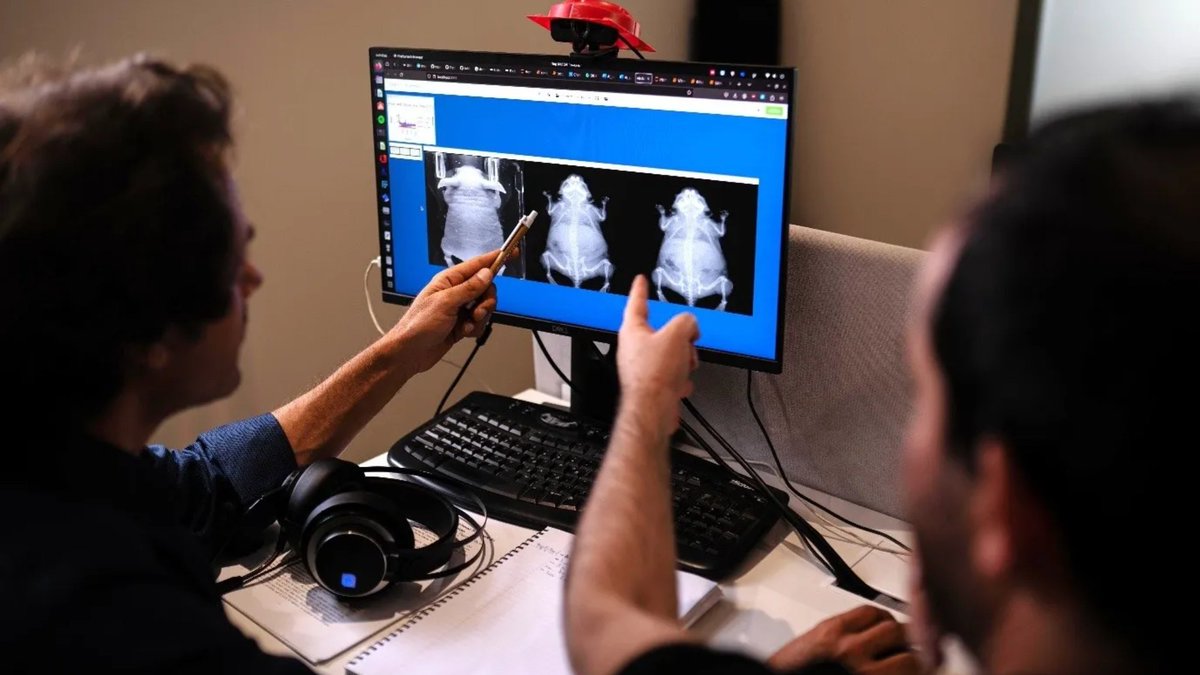
💡How can #HPC help deliver safer, personalised pediatric dosimetry?
#GRNET, #EuroCCGreece & #Bioemtech share the answer in a #FFplus interview with P. Papadimitroulas.
▶️Watch👉 shorturl.at/2y39J
📘Read👉 shorturl.at/sKkLf
🔬Success Story👉 shorturl.at/yVz0P

14 Nov 2025

💡How can #HPC help deliver safer, personalised pediatric dosimetry?
#EuroCCGreece, #GRNET & #Bioemtech share the answer in a #FFplus interview with P. Papadimitroulas.
▶️Watch👉 shorturl.at/5YGvz
📘Read👉 shorturl.at/sKkLf
🔬Success Story👉 shorturl.at/yVz0P
1
3
123