
OOD-GraphLLM: Graph Large Language Model for Out-of-Distribution Generalized Drug Synergy Prediction
Xin Wang, Linxin Xiao, Yang Yao, Wenwu Zhu
arxiv.org/abs/2605.30247 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙼𝙼]
5
263

[1/24]🧠📢 𝗟𝗮𝘀𝘁 𝗪𝗲𝗲𝗸 𝗶𝗻 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗜 (𝗠𝗮𝘆 𝟮𝟰–𝟯𝟬, 𝟮𝟬𝟮𝟱)
22 impactful papers categorized for fast reading!
Topics: LLMs, multimodal agents, surgical AI, benchmarks, segmentation, and medical datasets. 👇
🧬 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗟𝗟𝗠 & 𝗢𝘁𝗵𝗲𝗿 𝗠𝗼𝗱𝗲𝗹𝘀
• 𝗖𝗼𝘂𝗻𝘁𝗲𝗿𝗳𝗮𝗰𝘁𝘂𝗮𝗹 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗳𝗼𝗿 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗩𝗶𝗱𝗲𝗼 𝗗𝗶𝗮𝗴𝗻𝗼𝘀𝗶𝘀 🔗 arxiv.org/pdf/2605.26483
• 𝗖𝗿𝗼𝘀𝘀-𝗦𝘁𝗮𝗴𝗲 𝗠𝘂𝗹𝘁𝗶-𝗘𝘅𝗽𝗲𝗿𝘁 𝗡𝗲𝘁𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝗕𝗿𝗲𝗮𝘀𝘁 𝗨𝗹𝘁𝗿𝗮𝘀𝗼𝘂𝗻𝗱 🔗 arxiv.org/pdf/2605.25518
• 𝗢𝗼𝗗-𝗚𝗿𝗮𝗽𝗵𝗟𝗟𝗠: 𝗟𝗟𝗠 𝗳𝗼𝗿 𝗗𝗿𝘂𝗴 𝗦𝘆𝗻𝗲𝗿𝗴𝘆 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝗼𝗻 🔗 arxiv.org/pdf/2605.30247
• 𝗩𝗶𝗧 𝗦𝘂𝗯𝘀𝗽𝗮𝗰𝗲 𝗗𝗲𝗰𝗼𝘂𝗽𝗹𝗶𝗻𝗴 𝗳𝗼𝗿 𝗛𝗶𝘀𝘁𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗦𝗰𝗼𝗿𝗶𝗻𝗴 🔗 arxiv.org/pdf/2605.29852
• 𝗨𝗻𝗰𝗲𝗿𝘁𝗮𝗶𝗻𝘁𝘆 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗟𝗟𝗠𝘀 𝗳𝗼𝗿 𝗗𝗶𝗮𝗴𝗻𝗼𝘀𝗶𝘀 🔗 arxiv.org/pdf/2605.25566
• 𝗟𝗟𝗨𝗠𝗜: 𝗟𝗟𝗠 𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗳𝗼𝗿 𝗠𝗲𝗻𝘁𝗮𝗹 𝗛𝗲𝗮𝗹𝘁𝗵 𝗦𝘂𝗽𝗽𝗼𝗿𝘁 🔗 arxiv.org/pdf/2605.30273
• 𝗢𝗽𝗵𝗜𝗻-𝟱𝟬𝟬𝗞: 𝗦𝗰𝗮𝗹𝗶𝗻𝗴 𝗢𝗽𝗵𝘁𝗵𝗮𝗹𝗺𝗶𝗰 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗟𝗟𝗠𝘀 🔗 arxiv.org/pdf/2605.27916
• 𝗩𝗜𝗧𝗔𝗟: 𝗩𝗶𝘀𝘂𝗮𝗹-𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗶𝗻 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗠𝗟𝗟𝗠𝘀 🔗 arxiv.org/pdf/2605.28422
🧪 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸𝘀 𝗮𝗻𝗱 𝗠𝗲𝘁𝗵𝗼𝗱𝗼𝗹𝗼𝗴𝗶𝗲𝘀
• 𝗦𝗮𝗳𝗲𝗥𝘅-𝗔𝗴𝗲𝗻𝘁: 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗱𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗥𝗲𝗰𝗼𝗺𝗺𝗲𝗻𝗱𝗮𝘁𝗶𝗼𝗻 🔗 arxiv.org/pdf/2605.29146
• 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝗗𝗲𝗺𝗲𝗻𝘁𝗶𝗮 𝗗𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻 🔗 arxiv.org/pdf/2605.25540
• 𝗣𝗮𝘁𝗵𝗪𝗜𝗦𝗘: 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗖𝗮𝗻𝗰𝗲𝗿 𝗣𝗮𝘁𝗵𝘄𝗮𝘆 𝗧𝗿𝗶𝗮𝗴𝗶𝗻𝗴 🔗 arxiv.org/pdf/2605.25970
• 𝗠𝗲𝗱𝗩𝗼𝗹-𝗥𝟭: 𝗥𝗲𝘄𝗮𝗿𝗱-𝗗𝗿𝗶𝘃𝗲𝗻 𝗩𝗼𝗹𝘂𝗺𝗲𝘁𝗿𝗶𝗰 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 🔗 arxiv.org/pdf/2605.26621
• 𝗥𝗔𝗣𝗧𝗢𝗥 : 𝗩𝗶𝘀𝗶𝗼𝗻-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗳𝗼𝗿 𝗖𝗮𝗻𝗰𝗲𝗿 𝗥𝗲𝗳𝗲𝗿𝗿𝗮𝗹 🔗 arxiv.org/pdf/2605.25956
• 𝗦𝘆𝗻𝗲𝗿𝗴𝗶𝘀𝘁𝗶𝗰 𝗧𝗼𝗼𝗹 𝗚𝗮𝗶𝗻𝘀 𝗳𝗼𝗿 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗴𝗲𝗻𝘁𝘀 🔗 arxiv.org/pdf/2605.26691
• 𝗘𝗘𝗚 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀: 𝗦𝗽𝗲𝗰𝘁𝗿𝗮𝗹 𝗕𝗶𝗮𝘀 𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 🔗 arxiv.org/pdf/2605.26434
📊 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗟𝗟𝗠𝘀 & 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀
• 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝗶𝗻𝗴 𝗣𝗮𝘁𝗵𝗼𝗹𝗼𝗴𝘆 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 🔗 arxiv.org/pdf/2605.25764
• 𝗠𝗲𝗱𝗖𝗮𝘀𝗲-𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱: 𝗧𝗲𝘅𝘁-𝘁𝗼-𝗙𝗛𝗜𝗥 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝗳𝗼𝗿 𝗘𝗛𝗥 🔗 arxiv.org/pdf/2605.30295
• 𝗖𝗖𝗦: 𝗖𝗹𝗶𝗻𝗶𝗰𝗮𝗹 𝗖𝗼𝗻𝘀𝗲𝗻𝘀𝘂𝘀 𝗳𝗼𝗿 𝗥𝗮𝗱𝗶𝗼𝗹𝗼𝗴𝘆 𝗥𝗲𝗽𝗼𝗿𝘁𝘀 🔗 arxiv.org/pdf/2605.30131
🩺 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗟𝗟𝗠 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀
• 𝗦𝗨𝗥𝗚𝗘𝗡𝗧: 𝗦𝘂𝗿𝗴𝗶𝗰𝗮𝗹 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗔𝘀𝘀𝗶𝘀𝘁𝗮𝗻𝗰𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 🔗 arxiv.org/pdf/2605.29368
• 𝗦𝘂𝗿𝗳𝗦𝘂𝗿𝗴𝟲𝗗: 𝗦𝘂𝗿𝗴𝗶𝗰𝗮𝗹 𝗜𝗻𝘀𝘁𝗿𝘂𝗺𝗲𝗻𝘁 𝗣𝗼𝘀𝗲 𝗘𝘀𝘁𝗶𝗺𝗮𝘁𝗶𝗼𝗻 🔗 arxiv.org/pdf/2605.25598
📂 𝗗𝗮𝘁𝗮𝘀𝗲𝘁𝘀
• 𝗥𝗼𝗯𝗼𝘁-𝗣𝗮𝘁𝗶𝗲𝗻𝘁 & 𝗗𝗼𝗰𝘁𝗼𝗿-𝗣𝗮𝘁𝗶𝗲𝗻𝘁 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗗𝗶𝗮𝗹𝗼𝗴𝘂𝗲 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 🔗 arxiv.org/pdf/2605.26747
• 𝗛𝗘𝗔𝗟𝗧𝗛𝗗𝗜𝗔𝗟: 𝗠𝘂𝗹𝘁𝗶𝗹𝗶𝗻𝗴𝘂𝗮𝗹 𝗦𝗽𝗼𝗸𝗲𝗻 𝗗𝗶𝗮𝗹𝗼𝗴𝘂𝗲 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 🔗 arxiv.org/pdf/2605.30107
🎙️ 𝗪𝗮𝗻𝘁 𝘁𝗵𝗲 𝗱𝗲𝗲𝗽 𝗱𝗶𝘃𝗲?
YouTube Deep Dive: youtu.be/ECaXLUqV0hY
Spotify: open.spotify.com/show/4edRuS…
𝗙𝗼𝗹𝗹𝗼𝘄 𝗳𝗼𝗿 𝘄𝗲𝗲𝗸𝗹𝘆 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗜 𝗿𝗼𝘂𝗻𝗱𝘂𝗽𝘀! 📷 𝗥𝗲𝘁𝘄𝗲𝗲𝘁 𝘁𝗼 𝘀𝗽𝗿𝗲𝗮𝗱 𝘁𝗵𝗲 𝗸𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲.
#MedicalAI #LLM #MachineLearning #HealthcareAI #AIResearch

2
3
302

OOD-GraphLLM: Graph Large Language Model for Out-of-Distribution Generalized Drug Synergy Prediction
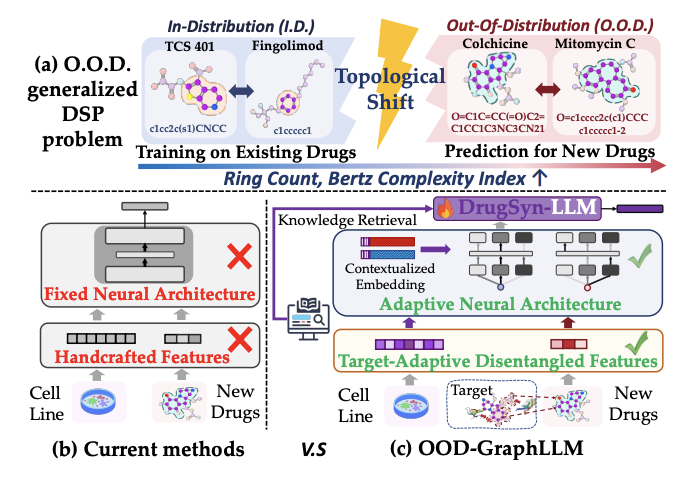
1 OOD-GraphLLM targets a practical failure mode in drug synergy prediction: new compounds introduce scaffold/size shifts, so test drugs can be topologically out-of-distribution (OOD) relative to training. The paper formalizes “OOD generalized DSP” where at least one drug in each test pair comes from an OOD drug set defined by scaffold or molecular weight.
2 The core idea is a unified GraphLLM pipeline that jointly optimizes (a) molecular graph representation learning and (b) biomedical language/semantic representations, so the model can reason over both topology (molecular graphs) and semantics (SMILES, retrieved drug knowledge, cell descriptions) under distribution shift.
3 Component 1: Target-adaptive disentangled molecular graph encoding. Each drug graph embedding is decomposed into target-irrelevant and target-relevant parts, then the target-relevant part is conditioned on drug-associated protein targets via cross-attention to ESM-2 protein embeddings. A decorrelation loss explicitly pushes different target-conditioned representations to capture non-redundant target-specific signals, improving OOD generalization.
4 Component 2: Pairwise attentive graph architecture search (NAS) for drug pairs. Instead of using a fixed GNN, OOD-GraphLLM dynamically routes among candidate message-passing operators (e.g., GCN/GIN/GAT/SAGE/GraphConv/MLP variants) using pairwise attention-informed drug representations. Operators are embedded in a latent space with a cosine-separation regularizer to avoid collapse, enabling differentiable, pair-adaptive architecture selection.
5 Component 3: Multi-level contextualized cellular feature alignment. Cell line context is injected both structurally (concatenating projected gene-expression context to each atom feature before message passing) and semantically (tokenized cell descriptions plus projected gene-expression embeddings aligned to the LLM input space). This treats the cell line as a first-class “context” for synergy.
6 Component 4: DrugSyn-LLM with retrieval-augmented biomedical instruction tuning. The authors fine-tune a biomedical LLM (Galactica backbone) in two stages: (i) instruction tuning to reproduce curated drug descriptions retrieved deterministically from DrugBank (with manual supplementation from trusted sources when needed), then (ii) task training to generate both synergy label and synergy score, while also injecting projected drug-graph and cell embeddings as continuous tokens.
7 Data and evaluation emphasize true distribution shift. Experiments use DrugComb triplets (drug1, drug2, cell line) with four synergy scoring schemes (Loewe/Bliss/HSA/ZIP), filtered to |score| ≥ 10. OOD splits are constructed by scaffold thresholds or size (molecular weight) thresholds, producing clear train/test separation in chemical space (t-SNE), unlike random splits.
8 Results: across scaffold-based and size-based OOD settings, OOD-GraphLLM outperforms DNN, GNN, and LLM baselines (including CancerGPT and BAITSAO) on both classification (ACC/AUC) and regression (MAE/RMSE) for all four scoring schemes. Gains are especially notable for regression, consistent with the claim that numerical synergy prediction under OOD shift is harder than classification.
9 Ablations show each module matters; removing cellular context (w/o Ctx) or disabling NAS (w/o NAS) causes the largest drops, particularly on regression. Removing retrieval-augmented instruction tuning, disentanglement decorrelation, pairwise attention, or operator-separation regularization also consistently degrades performance, supporting the “joint optimization” design.
10 Interpretability analyses suggest the model learns meaningful signals: target-level attention highlights plausible mechanisms (e.g., KU-55933 attending to ATM; Imiquimod to TLR7), and SMILES attention focuses on chemically interpretable fragments (e.g., polar head groups, heteroatom-rich nucleoside regions, fluorinated aromatic motifs). A case study (5-Fluorouracil Vorinostat in NCI-H226) illustrates how target-adaptive modeling can align mechanistic clues across structurally divergent OOD drugs.
💻Code: github.com/EkkoXiao/Bio-Grap…
📜Paper: arxiv.org/abs/2605.30247
#ComputationalBiology #Bioinformatics #DrugDiscovery #GNN #LLM #GraphML #OOD #SynergyPrediction #MultimodalAI #MachineLearning
3
13
1,191

30 Jun 2025
Towards Multi-modal Graph Large Language Models
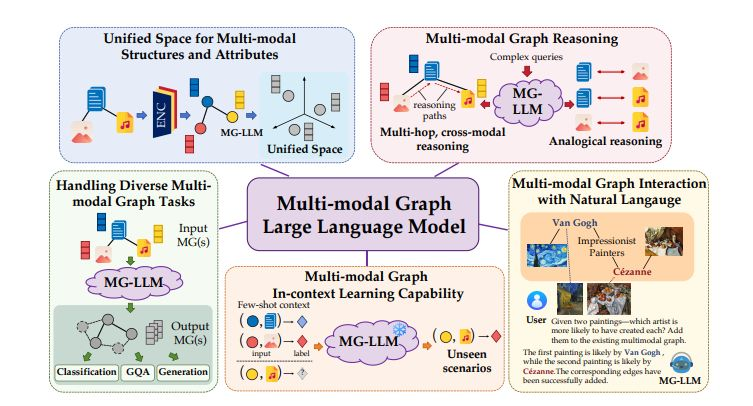
Multi-modal graphs, which integrate diverse multi-modal features and relations, are ubiquitous in real-world applications. However, existing multi-modal graph learning methods are typically trained from scratch for specific graph data and tasks, failing to generalize across various multi-modal graph data and tasks.
To bridge this gap, new research explores the potential of Multi-modal Graph Large Language Models (MG-LLM) to unify and generalize across diverse multi-modal graph data and tasks.
It proposes a unified framework of multi-modal graph data, task, and model, discovering the inherent multi-granularity and multi-scale characteristics in multi-modal graphs.
Specifically, it presents five key desired characteristics for MG-LLM:
1) unified space for multi-modal structures and attributes,
2) capability of handling diverse multi-modal graph tasks,
3) multi-modal graph in-context learning,
4) multi-modal graph interaction with natural language, and
5) multi-modal graph reasoning.
The paper elaborates on the key challenges, review related works, and highlight promising future research directions towards realizing these ambitious characteristics.
Finally, it summarizes existing multi-modal graph datasets pertinent for model training.
The key insight is treating all graph tasks as generative problems.
Instead of training separate models for node classification, link prediction, or graph reasoning, MG-LLM frames everything as transforming one multi-modal graph into another.
A contribution to the ongoing advancement of the research towards MG-LLM for generalization across multi-modal graph data and tasks.
arxiv.org/abs/2506.09738v1
#AI #GenAI #EmergingTech #MultimodalGraphs #GraphLLM #NeuralNetworks #MachineLearning #GraphML #DeepLearning #DataScience #Research #GraphTransformers #LLMs
--
Connected Data London 2025 has been announced! 20-21 November, Leonardo Royal Hotel London Tower Bridge
Join us for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
🎟️ Ticket sales are open. Benefit from early bird prices with discounts up to 30%. 2025.connected-data.london
📋 Call for submissions is open. Check topics of interest, submission process and evaluation criteria connected-data.london/call-f…
📺 Sponsorship opportunities are available. Maximize your exposure with early onboarding. Contact us at info@connected-data.london for more.
6
12
523

6 May 2024
recent literature (GoT, ALPHALLM, GraphLLM, etc) suggests:
>search strategies improve accuracy and quality
>search strategies get better with more capable foundation models
as the quality of foundation models seems poised to increase, i think llm search will be promising
1
1
7
217