Siamese foundation models for crystal structure prediction
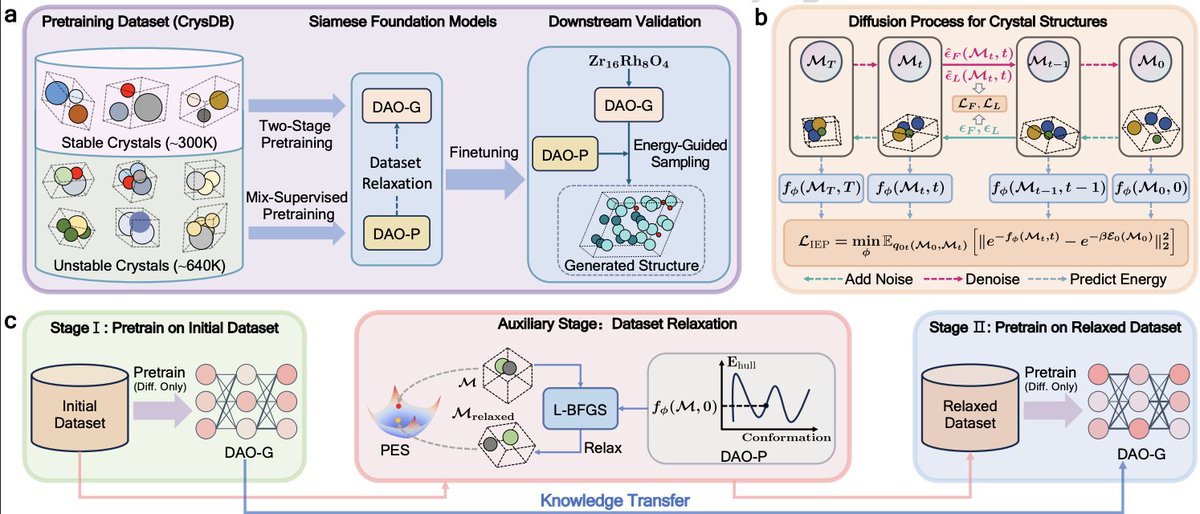
1. The paper introduces DAO (Diffusion-based crystAl Omni), a pretrain–finetune framework for crystal structure prediction that couples two “Siamese” foundation models: DAO-G (structure generator) and DAO-P (energy predictor). The key idea is to make generation and energy modeling mutually reinforcing during both pretraining and inference.
2. DAO is built around a geometric graph Transformer called Crysformer, designed to respect crystal symmetries: O(3)/E(3) transformations and periodic translation invariance. It outputs equivariant denoising signals (for lattice/coordinates) and invariant energy predictions, enabling physically consistent learning and sampling.
3. A central contribution is CrysDB, a large pretraining corpus (~940K crystals) assembled from Materials Project and OQMD, filtered to 3–30 atoms and Ehull < 1.0 eV/atom, then deduplicated (919,258 entries) to avoid leakage into downstream CSP benchmarks (MP-20, MPTS-52) using strict structure matching for identical compositions.
4. DAO-G is pretrained directly on the CSP objective (learning p(L, F | A)) via a DiffCSP-style diffusion formulation: DDPM noise for lattices and wrapped-normal score matching for fractional coordinates. Unlike many prior CSP models trained only on small benchmark datasets, DAO-G is pretrained at scale before finetuning.
5. The most distinctive training design is a two-stage pretraining pipeline for DAO-G that explicitly leverages unstable crystals rather than discarding them. Stage I trains on stable unstable structures to broaden coverage; Stage II retrains on a “relaxed” version of the dataset where unstable structures (Ehull in (0.08, 0.5]) are pushed toward lower-energy configurations using DAO-P-derived gradients and L-BFGS.
6. DAO-P is pretrained with a mix-supervised objective: diffusion denoising losses plus an exponential energy loss to learn intermediate energies along the diffusion trajectory (needed for energy guidance). This avoids requiring ground-truth “intermediate-state” energies and is motivated by Boltzmann-constrained modeling for energy-guided generation.
7. During inference, DAO-P provides energy-guided sampling: gradients of the predicted intermediate energy steer DAO-G’s denoising trajectory toward lower-energy (more stable) regions, improving stability rates and helping more on harder structures (e.g., MPTS-52).
8. On CSP benchmarks (MP-20 and the harder MPTS-52), pretraining consistently improves performance across architectures, and Crysformer generally strengthens denoising compared with scaled GNN baselines. The study also reports that swapping diffusion for flow matching within the same architecture can further raise match rates, suggesting the pretraining framework is generative-method-agnostic.
9. DAO-G is evaluated for polymorph generation (multiple structures per composition). The model recovers all polymorphs in a large fraction of cases (reported for 2-, 3-, and 4-polymorph settings), indicating it can represent structural diversity rather than collapsing to a single mode.
10. A real-world validation targets superconductors using SuperCon-derived data: DAO-G is finetuned on superconductors with known structures, then used to generate structures for compositions lacking structures; DAO-P is finetuned to predict Tc and benefits from this structure augmentation. For three unseen superconductors (Cr6Os2, Zr16Rh8O4, Zr16Pd8O4), DAO-G closely matches experimental structures (e.g., Cr6Os2 achieving 100% match rate and very small positional error under 20-shot generation) and is reported to be >2000× faster per iteration than a DFT-based optimizer baseline in their comparison setup.
💻Code: github.com/ManlioWu/DAO
📜Paper: doi.org/10.1038/s41467-026-7…
#MaterialsScience #CrystalStructurePrediction #DiffusionModels #FoundationModels #GraphTransformers #ComputationalChemistry #AI4Science #Superconductors
1
1
7
1,474
Siamese Foundation Models for Crystal Structure Prediction
1. The paper introduces DAO (Diffusion-based Crystal Omni), a pretrain–finetune framework for crystal structure prediction that couples two “Siamese” foundation models: DAO-G (structure generator) and DAO-P (energy predictor) that actively supports generation via relaxation and energy-guided sampling.
2. A key design choice is to pretrain on both stable and unstable crystals, rather than stable-only corpora. The authors build CrysDB (~940K crystals from Materials Project OQMD, with energy annotations), then deduplicate it to avoid leakage into MP-20 and MPTS-52 benchmark test sets.
3. DAO-G is pretrained directly on the CSP objective (learning p(lattice, coordinates | composition)) using a DiffCSP-style diffusion formulation over lattice and fractional coordinates, aiming to make pretraining tightly aligned with downstream CSP finetuning.
4. DAO-P is pretrained with a mix-supervised objective: (a) self-supervised diffusion losses to learn structure denoising signals, plus (b) a supervised energy objective designed to predict intermediate energies along the diffusion trajectory. They propose an exponential energy loss motivated by Boltzmann-constrained modeling to make intermediate-energy learning feasible without explicit intermediate labels.
5. The generator pretraining uses a two-stage pipeline: Stage I trains DAO-G on the full (stable unstable) CrysDB; then DAO-P relaxes moderately unstable structures (Ehull in (0.08, 0.5] eV/atom) using predicted energy gradients with L-BFGS; Stage II continues pretraining DAO-G on this “relaxed” dataset to reduce bias toward unstable regions.
6. Architecturally, both models share Crysformer, a geometric graph Transformer designed to respect O(3) symmetry and periodic invariance. It combines invariant attention over graph edges (with Fourier features for periodicity), gated residual connections, and separate heads for noise (generation) and energy (prediction).
7. On CSP benchmarks, large-scale pretraining consistently improves results across backbones. With comparable parameter budgets, Crysformer-based models outperform scaled baselines, and swapping diffusion for flow matching within the same architecture further improves match rate (reported best: 74.17% on MP-20 and 42.01% on MPTS-52 in 1-shot).
8. Ablations support the “generator–predictor synergy”: including unstable crystals helps, but adding DAO-P-based relaxation (Stage II) further improves generation quality; and energy-guided sampling increases stability rates of generated structures (e.g., MP-20 stability 85.99% → 87.42%; MPTS-52 73.75% → 75.05%) and can especially help on harder, larger systems.
9. DAO-G is evaluated for polymorphism recovery (multiple structures per composition), showing strong coverage in 2-/3-/4-polymorph cases and demonstrating that the model can generate diverse conformations for the same composition rather than collapsing to a single mode.
10. Real-world validation targets superconductors: after finetuning on SuperCon-derived 3D data, DAO-G predicts structures for unseen superconductors (Cr6Os2, Zr16Rh8O4, Zr16Pd8O4). For Cr6Os2, it reports 100% match rate with extremely low atomic-position error (RMSE 0.0012 over 20-shot), and DFT-computed Ehull closely matches experiment; generation iterations are reported >2000× faster than a DFT-based optimizer per iteration. DAO-P also supports Tc prediction, improved by augmenting missing-structure entries with DAO-G-generated structures.
💻Code: github.com/ManlioWu/DAO
📜Paper: arxiv.org/abs/2503.10471
#CrystalStructurePrediction #MaterialsInformatics #GenerativeModels #DiffusionModels #FlowMatching #FoundationModels #GraphTransformers #Superconductors #ComputationalMaterials #AIforScience

2
15
1,529

28 Nov 2025
Artificial Intelligence Driven Workflow for Accelerating Design of Novel Photosensitizers
1. A novel study presents AAPSI, an AI-driven workflow that integrates expert knowledge, scaffold-based molecule generation, and Bayesian optimization to accelerate the design of novel photosensitizers. This approach addresses the challenges of traditional trial-and-error methods by leveraging a curated database of 102,534 photosensitizer-solvent pairs and generating 6,148 synthetically accessible candidates.
2. The core innovation lies in the closed-loop integration of AI and experimental validation. AAPSI uses graph transformers trained to predict singlet oxygen quantum yield (φ∆) and absorption maxima (λmax), identifying candidates with optimal properties for photodynamic therapy (PDT). The workflow prioritizes high φ∆ and long λmax, which are critical for effective PDT.
3. Among the synthesized candidates, HB4Ph, a hypocrellin-based photosensitizer, demonstrates exceptional performance with a φ∆ of 0.85 and λmax of 645 nm. This places HB4Ph at the Pareto frontier of current photosensitizers, showcasing AAPSI's ability to generate high-performance molecules tailored for clinical applications.
4. The study establishes a comprehensive database of photosensitizers, covering a wide range of structural classes and photodynamic properties. This database, available online, serves as a valuable resource for researchers in the field, facilitating further exploration and optimization of photosensitizers.
5. AAPSI represents a paradigm shift in photosensitizer design, merging AI-driven innovation with domain expertise to streamline the discovery process. The workflow's success in generating and validating high-performance photosensitizers highlights its potential for accelerating material innovation in biotechnology and medicine.
📜Paper: arxiv.org/abs/2511.19347v1
#AI #Photosensitizers #PhotodynamicTherapy #MaterialInnovation #ClosedLoopWorkflow #Database #GraphTransformers

1
12
1,211

30 Jun 2025
Towards Multi-modal Graph Large Language Models
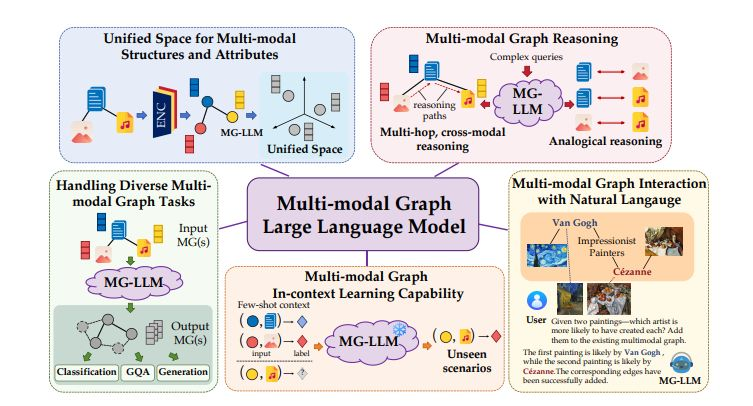
Multi-modal graphs, which integrate diverse multi-modal features and relations, are ubiquitous in real-world applications. However, existing multi-modal graph learning methods are typically trained from scratch for specific graph data and tasks, failing to generalize across various multi-modal graph data and tasks.
To bridge this gap, new research explores the potential of Multi-modal Graph Large Language Models (MG-LLM) to unify and generalize across diverse multi-modal graph data and tasks.
It proposes a unified framework of multi-modal graph data, task, and model, discovering the inherent multi-granularity and multi-scale characteristics in multi-modal graphs.
Specifically, it presents five key desired characteristics for MG-LLM:
1) unified space for multi-modal structures and attributes,
2) capability of handling diverse multi-modal graph tasks,
3) multi-modal graph in-context learning,
4) multi-modal graph interaction with natural language, and
5) multi-modal graph reasoning.
The paper elaborates on the key challenges, review related works, and highlight promising future research directions towards realizing these ambitious characteristics.
Finally, it summarizes existing multi-modal graph datasets pertinent for model training.
The key insight is treating all graph tasks as generative problems.
Instead of training separate models for node classification, link prediction, or graph reasoning, MG-LLM frames everything as transforming one multi-modal graph into another.
A contribution to the ongoing advancement of the research towards MG-LLM for generalization across multi-modal graph data and tasks.
arxiv.org/abs/2506.09738v1
#AI #GenAI #EmergingTech #MultimodalGraphs #GraphLLM #NeuralNetworks #MachineLearning #GraphML #DeepLearning #DataScience #Research #GraphTransformers #LLMs
--
Connected Data London 2025 has been announced! 20-21 November, Leonardo Royal Hotel London Tower Bridge
Join us for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
🎟️ Ticket sales are open. Benefit from early bird prices with discounts up to 30%. 2025.connected-data.london
📋 Call for submissions is open. Check topics of interest, submission process and evaluation criteria connected-data.london/call-f…
📺 Sponsorship opportunities are available. Maximize your exposure with early onboarding. Contact us at info@connected-data.london for more.
6
12
523

22 Apr 2025
🚀 New tutorial on Graph Transformers!
We introduce a powerful architecture combining the strengths of GNNs and Transformers for structured data. Learn how GTs open new possibilities for graph learning.
kumo.ai/research/introductio…
#GraphTransformers #MachineLearning #AI #GNN
4
37
173
7,818

8 Apr 2025
A while back, I wrote this explanation about Graph Neural Networks, Transformers, and Graph Transformers, which may be useful for anyone looking for an introduction to the topic.
researchgate.net/publication…
#GNN #Transformers #GraphTransformers

1
6
661
13 Feb 2025
Estimating Protein Complex Model Accuracy Using Graph Transformers and Pairwise Similarity Graphs
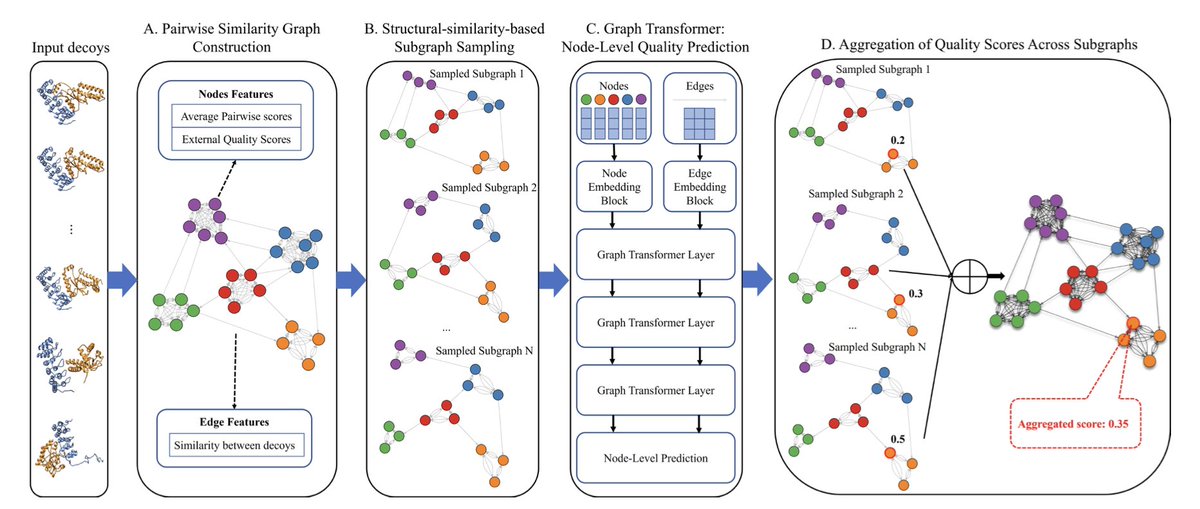
1/ GATE introduces a novel approach to estimating the accuracy of protein complex structures by leveraging graph transformers and pairwise similarity graphs, enabling more robust predictions of structural quality compared to existing methods.
2/ The method combines the benefits of single-model and multi-model quality assessment approaches by integrating both the characteristics of individual models and the geometric similarity between them to make reliable predictions.
3/ GATE outperforms existing techniques, achieving the highest Pearson’s correlation (0.748) and the lowest ranking loss (0.1191) on the CASP15 dataset, and ranks 4th in the CASP16 blind experiment, demonstrating its strong overall performance.
4/ In addition to global structural metrics like TM-score, GATE incorporates novel pairwise similarity metrics, allowing it to accurately assess multi-domain protein complexes, which are often challenging for traditional quality assessment methods.
5/ The methodology uses a graph-based architecture where individual decoy models are represented as nodes in a graph, with edges representing the structural similarity between models. This allows GATE to capture complex relationships between models for more precise quality ranking.
6/ GATE’s innovative subgraph sampling strategy ensures that structurally diverse models are represented equally in the assessment, addressing the common issue in consensus methods where similar, low-quality models dominate the evaluation process.
7/ The GATE model offers a balanced solution for protein complex model quality estimation, achieving competitive results across a variety of metrics and showing particular strength in ranking and identifying high-quality decoys from large model pools.
💻Code: github.com/BioinfoMachineLea…
📜Paper: biorxiv.org/content/10.1101/…
#ProteinComplexes #ProteinModeling #MachineLearning #GraphTransformers #Bioinformatics #DeepLearning #CASP16 #ComputationalBiology #StructuralBiology #ProteinQualityAssessment
2
18
1,536
13 Feb 2025
Estimating Protein Complex Model Accuracy Using Graph Transformers and Pairwise Similarity Graphs
1/ GATE introduces a novel approach to estimating the accuracy of protein complex structures by leveraging graph transformers and pairwise similarity graphs, enabling more robust predictions of structural quality compared to existing methods.
2/ The method combines the benefits of single-model and multi-model quality assessment approaches by integrating both the characteristics of individual models and the geometric similarity between them to make reliable predictions.
3/ GATE outperforms existing techniques, achieving the highest Pearson’s correlation (0.748) and the lowest ranking loss (0.1191) on the CASP15 dataset, and ranks 4th in the CASP16 blind experiment, demonstrating its strong overall performance.
4/ In addition to global structural metrics like TM-score, GATE incorporates novel pairwise similarity metrics, allowing it to accurately assess multi-domain protein complexes, which are often challenging for traditional quality assessment methods.
5/ The methodology uses a graph-based architecture where individual decoy models are represented as nodes in a graph, with edges representing the structural similarity between models. This allows GATE to capture complex relationships between models for more precise quality ranking.
6/ GATE’s innovative subgraph sampling strategy ensures that structurally diverse models are represented equally in the assessment, addressing the common issue in consensus methods where similar, low-quality models dominate the evaluation process.
7/ The GATE model offers a balanced solution for protein complex model quality estimation, achieving competitive results across a variety of metrics and showing particular strength in ranking and identifying high-quality decoys from large model pools.
@jianlincheng
💻Code: github.com/BioinfoMachineLea…
📜Paper: biorxiv.org/content/10.1101/…
#ProteinComplexes #ProteinModeling #MachineLearning #GraphTransformers #Bioinformatics #DeepLearning #CASP16 #ComputationalBiology #StructuralBiology #ProteinQualityAssessment

1
18
1,517

5 Dec 2024
Graph Transformers, a class of neural networks inspired by the success of transformers in natural language processing, have become a powerful tool for graph representation learning. 📉
thequantuminsider.com/2024/1…
#GraphTransformers #Quantum #Dataset #QuantumLinks
2
5
532
26 Nov 2024
Interformer: an interaction-aware model for protein-ligand docking and affinity prediction @NatureComms
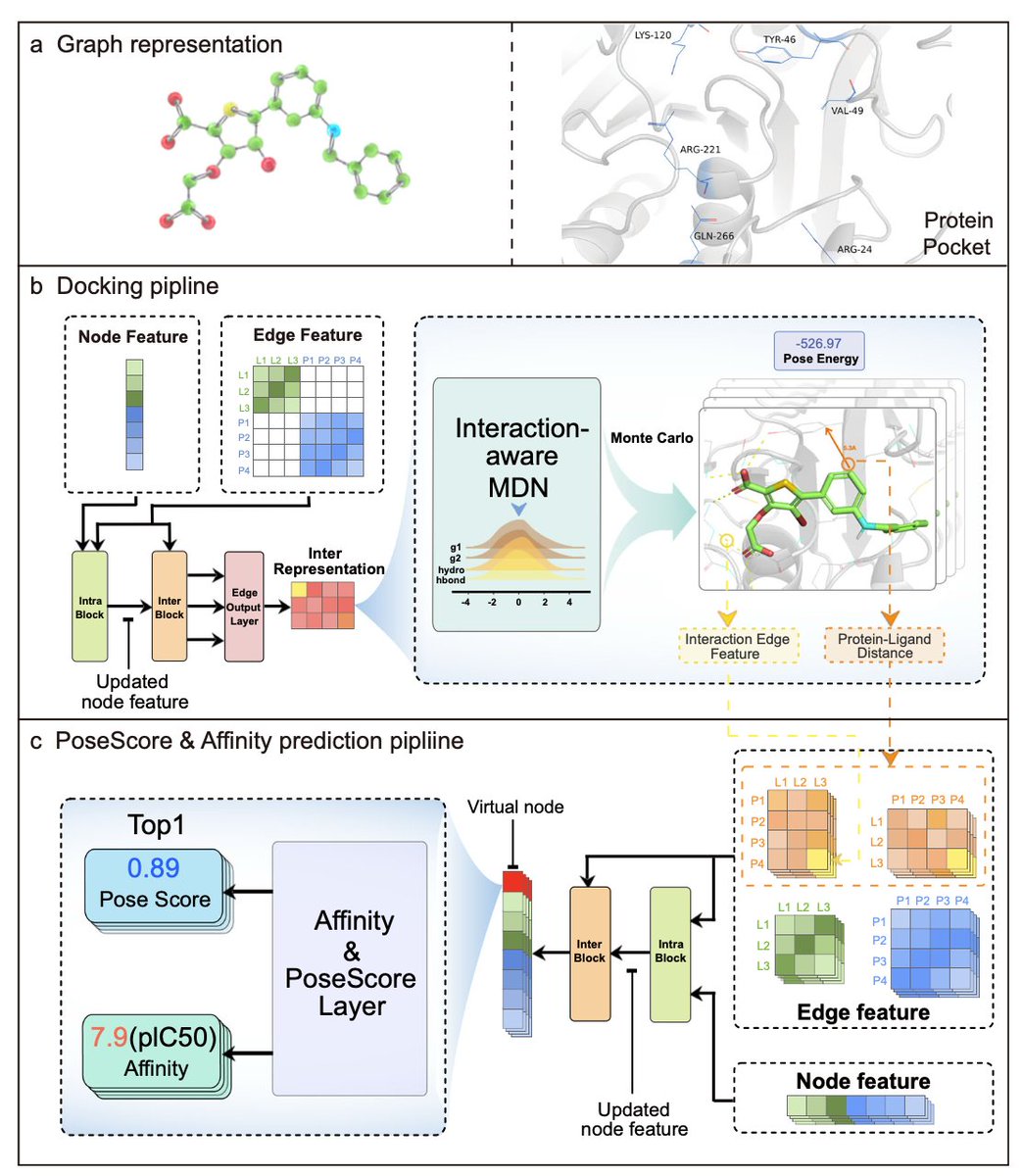
• Interformer introduces a Graph-Transformer-based model, tailored for protein-ligand docking and binding affinity prediction, capturing non-covalent interactions crucial for real-world drug development scenarios.
• A novel interaction-aware mixture density network (MDN) models specific interactions such as hydrogen bonds and hydrophobic contacts, significantly improving docking accuracy and binding pose prediction compared to existing methods.
• Performance benchmarks: Interformer achieved a top-1 docking success rate of 84.09% on the PoseBusters benchmark and 63.9% on the PDBBind benchmark with RMSD < 2Å, outperforming state-of-the-art models like DiffDock and GNINA.
• The model’s pose-sensitive affinity prediction, powered by contrastive loss and negative sampling strategies, ensures reliable binding affinity predictions even with suboptimal docking poses, a major challenge in traditional methods.
• Real-world application: Interformer identified potent molecules with affinities as low as 0.7 nM and 16 nM in pharmaceutical projects targeting LSD1 and SARS-CoV-2 main protease (Mpro), showcasing its practical value in therapeutic development.
@wangly0229 @hungjnh36875388 @aaguaijie @WUFang40615703
💻Code: github.com/tencent-ailab/Int…
📜Paper: nature.com/articles/s41467-0…
#ProteinLigandDocking #DrugDiscovery #GraphTransformers #MachineLearning #Bioinformatics
17
101
7,610
26 Nov 2024
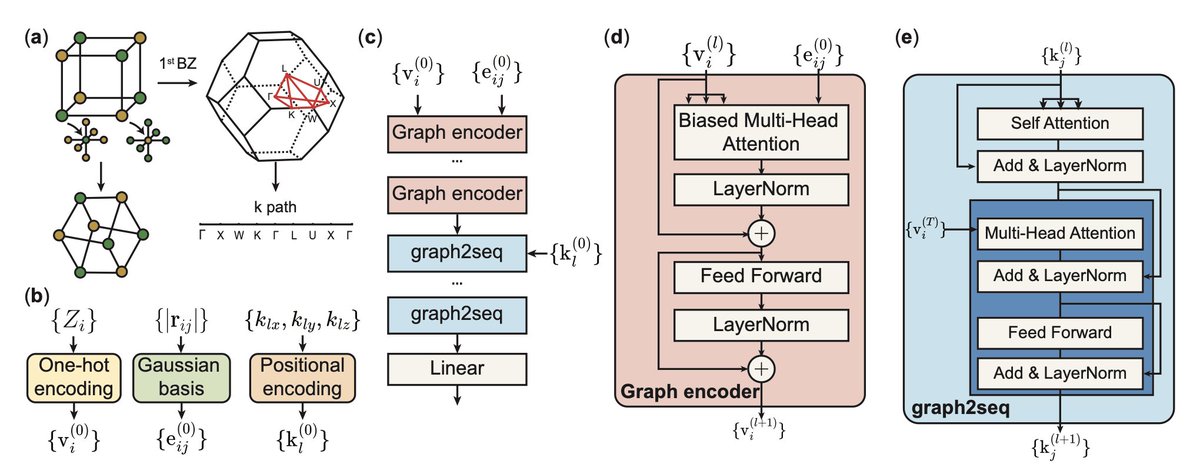
Graph Transformer Networks for Accurate Band Structure Prediction: An End-to-End Approach
• Introducing Bandformer: a novel graph Transformer-based model designed for direct, end-to-end prediction of electronic band structures from crystal structures, bypassing intermediate calculations like Hamiltonian matrices.
• Key innovation: Bandformer treats band structure prediction as a “language translation” problem, encoding crystal graphs and translating them into band structure sequences. It leverages graph-to-sequence (graph2seq) architectures for exceptional precision.
• Achievements: The model achieves a mean absolute error (MAE) of 0.14 eV for band energy prediction and excels in band-derived properties, with MAEs of 72 meV for band centers, 84 meV for band dispersions, and 0.164 eV for band gap predictions in non-metals.
• Efficiency breakthrough: Bandformer integrates smooth k-point resampling and the Latimer-Munro (LM) scheme to handle variable k-paths, maintaining computational efficiency and ensuring consistent inputs for training.
• Generalization capability: Trained on 55,000 crystal structures from the Materials Project, Bandformer generalizes across diverse datasets, enabling large-scale material screening and inverse material design with minimal preprocessing.
• Future implications: By simplifying band structure representations and improving learning efficiency, Bandformer paves the way for advanced electronic structure prediction tools that can accelerate material discovery.
📜Paper: arxiv.org/abs/2411.16483
#MaterialScience #BandStructure #GraphTransformers #MachineLearning #SolidStatePhysics
11
1,009
5 Nov 2024
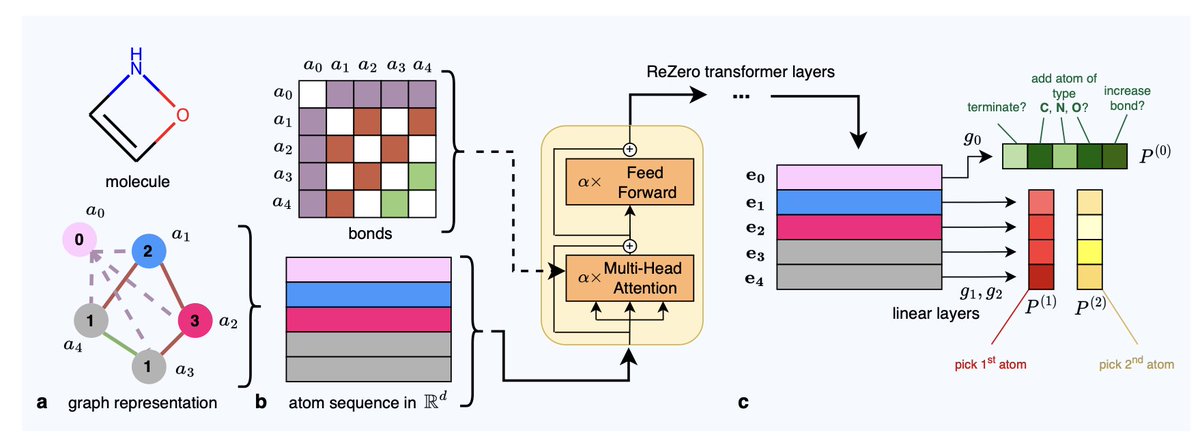
GraphXForm: Graph transformer for computer-aided molecular design with application to extraction
• GraphXForm introduces a novel graph transformer model for molecular design, focusing on applications in solvent design for liquid-liquid extraction processes.
• This model tackles limitations of string-based molecular representations (e.g., SMILES) by directly modifying molecular graphs, which ensures chemical validity and allows structural constraints like specific substructures or bond restrictions.
• Unlike traditional deep learning approaches, GraphXForm iteratively builds molecular graphs, predicting the next atom or bond action with a transformer trained on existing molecular structures.
• Fine-tuning employs a unique training algorithm that combines deep cross-entropy and self-improvement learning, stabilizing the training of multi-layered graph transformers without reinforcement learning.
• Tested on two solvent design tasks, GraphXForm outperforms four state-of-the-art models, including REINVENT and Junction Tree VAE, demonstrating superior objective scores in both efficiency and flexibility.
• By integrating constraints such as limiting ring sizes or bond types, GraphXForm ensures designed solvents meet industrial specifications, highlighting its adaptability for complex molecular tasks.
@dg_grimm
💻Code: github.com/grimmlab/graphxfo…
📜Paper: arxiv.org/abs/2411.01667
#MolecularDesign #GraphTransformers #MachineLearning #ChemicalEngineering #SolventDesign
1
5
10
2,156

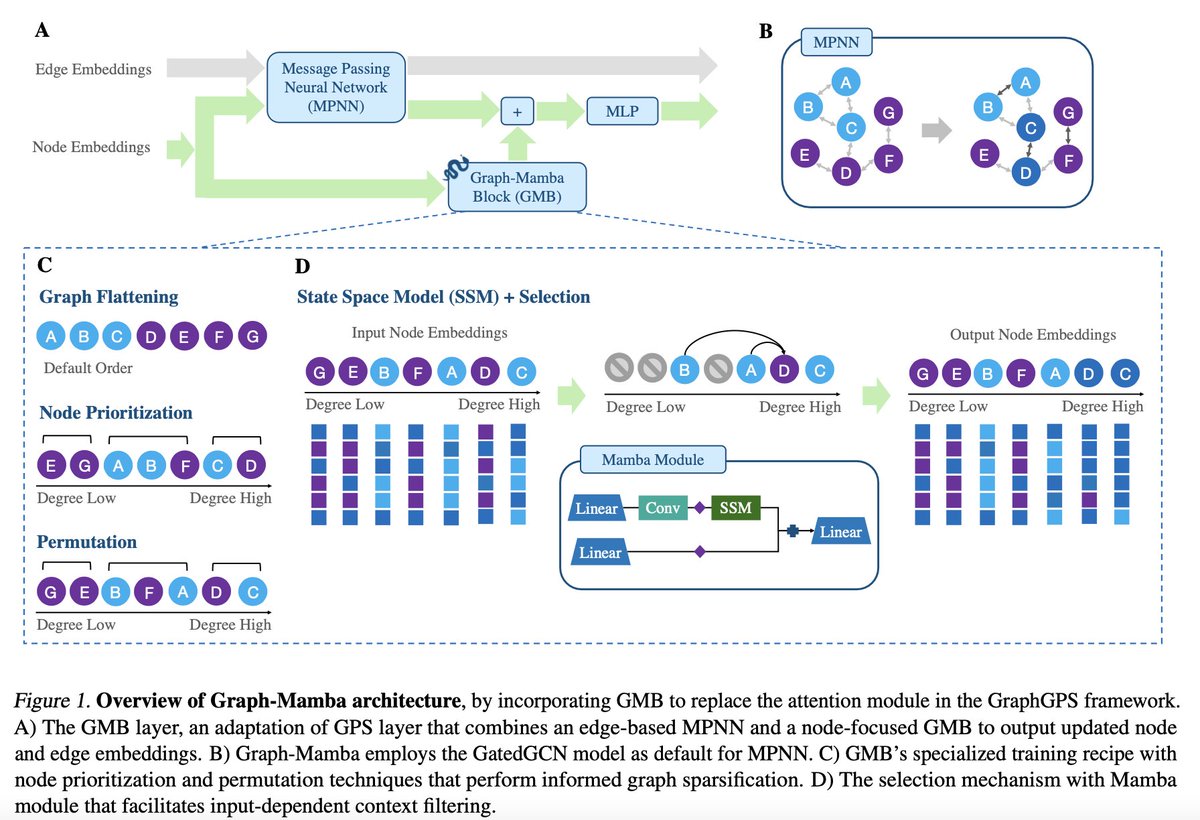
State Spaces models (SSM) such as mamba have started to revolutionize languages, vision, and genomics, as a promising alternative to transformer architecture. How about graph data?
❤️🔥 Introducing Graph-Mamba, our latest innovation in Graph Learning for enhanced long-range graph context modeling!
🐍 Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces
AriXv: arxiv.org/abs/2402.00789
Code: github.com/bowang-lab/Graph-…
TL,DR 👇:
Graph Attention mechanisms face challenges in scaling for large graphs. Enter Graph-Mamba – integrating state space models with input-dependent node selection for efficient long-range context reasoning. Featuring special graph-centric adaptations to effectively employ SSM for non-sequential graph data.
🔑Key Contributions:
--Innovative Design: Graph-Mamba pioneers a novel graph network integrating selective SSM, capturing long-range dependencies with adaptive node selection.
--Adaptation for Graphs: Employing elegant node prioritization strategies and permutation-based training to mitigate sequence-induced biases and boost modeling power.
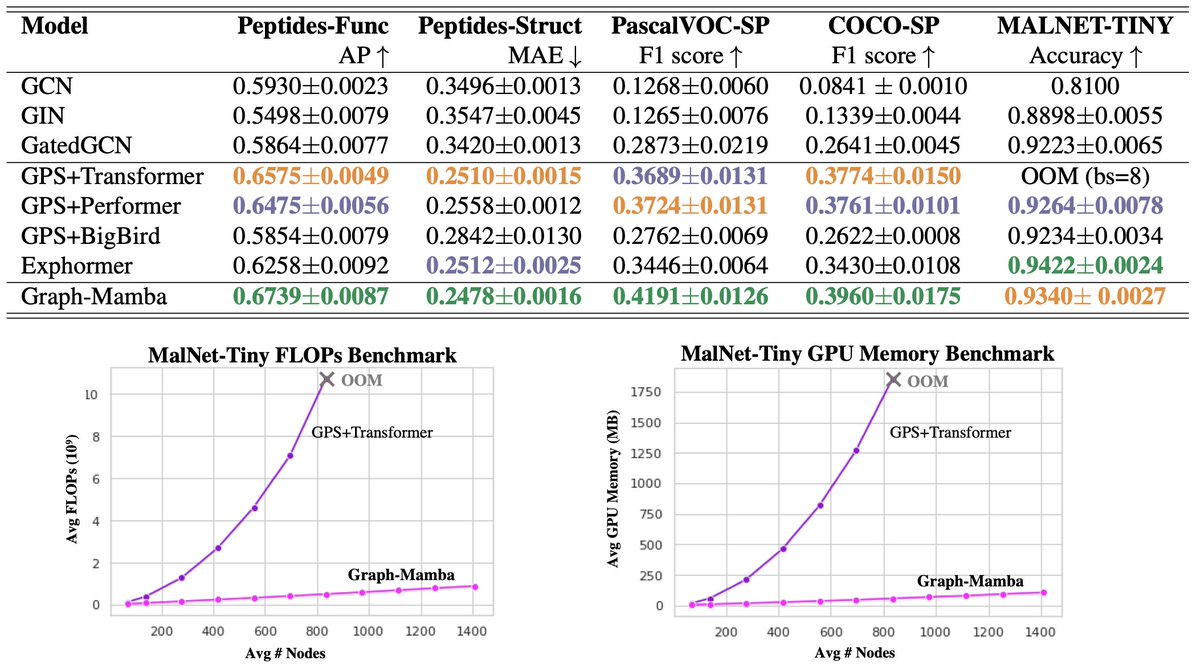
--Performance & Efficiency: Graph-Mamba outperforms baselines with linear-time complexity and up to 74% reduction in GPU memory consumption on large graphs.
❤️🔥 Looking Ahead: Propelling SSMs into an era of efficient pre-training on graph data with Graph-Mamba!
#GraphMamba #SSM #GraphTransformers #AIResearch #DataScience
Shoutout to Chloe Wang (@ChloeXWang1 ) for her leadership in this project and also to Oleksii Tsepa(@AlexTsepa ) and Jun Ma (@JunMa_11 ) for their invaluable contributions!
@UHNAIHUB @pmcc_ai @UHN @VectorInst @UofTCompSci @UofT_LMP
3
105
405
61,114