


Hey Sridhar,
Have you shared the #GroqSpeed demo we made for you with your brilliant @SnowflakeDB developers?
Better yet, they can try #Groq for themselves!
In the meantime, read this post for a few ideas on how the #DataCloud can be #BetterOnGroq. ❄️
hubs.la/Q02rSgT00
1
1
12
4,627
Hey Sridhar,
How's it going settling into your new role?
We have a great idea for how you could have a big win right away: our LPU™ Inference Engine.
Watch the #GroqSpeed demo and you'll understand why your #AI workloads would run #BetterOnGroq.
hubs.la/Q02rlQp50
1
11
4,034
Hey Sridhar at @SnowflakeDB,
Congrats on the new role! Your predecessor once said everything is better in the #DataCloud. ❄️ We believe #LLMs and #GenAI run #BetterOnGroq.
We think you'll agree so we created a #GroqSpeed demo just for you. ⛷️
hubs.la/Q02qwbmT0
3
1
15
3,743

Congrats @JonathanRoss321 @sundeep - we’ve been working on this for some time and it’s already started producing results. Looking forward to seeing even more accelerated #GroqSpeed for #GroqCloud
1 Mar 2024

Some news! :)
wow.groq.com/news_press/groq…
4
8
40
70,433
Monster LPUs being racked up to serve the more than 3,000 pilot customers! 💪 #GroqSpeed

That's a strong-looking GroqRack™ right there, don't ya think? Serving up tokens faster than anyone. We're building A LOT more hardware and increasing capacity weekly. Scaling to be a token factory to help change the world of AI through the world's greatest inference engine.

ALT A GroqRack™, a part of the LPU™ Inference Engine

ALT the GroqRack™ at a datacenter

ALT Beautiful cabling done by our Groqsters at the datacenter. The back of the LPU™ Inference Engine.
5
8
68
74,078

26 Feb 2024
💥 Groq, pas Grok d'Elon Musk, révolutionne l'IA avec des vitesses qui éclairent le futur!
Une équipe de passionnés a testé face aux rumeurs: vérité ou bluff ?
Verdict: c'est une fusée 🚀
Avec 500 tokens/sec contre 40 pour ChatGPT, le jeu change.
#GroqSpeed #IAFuturiste
2
2
143

1
1
2
139
1
2
152
話題のGroq、使ってみました。生成スピードが段違いです。プロンプトを日本語で入れても大丈夫ですが、日本語での返信を求めると少し違和感のある内容が返ってきます。あと途中で切れてしまうことも。
日本語の生成スピードはこんな感じ。 #AI #テクノロジー #人工知能 #Groq #Groqspeed
1
2
4
375
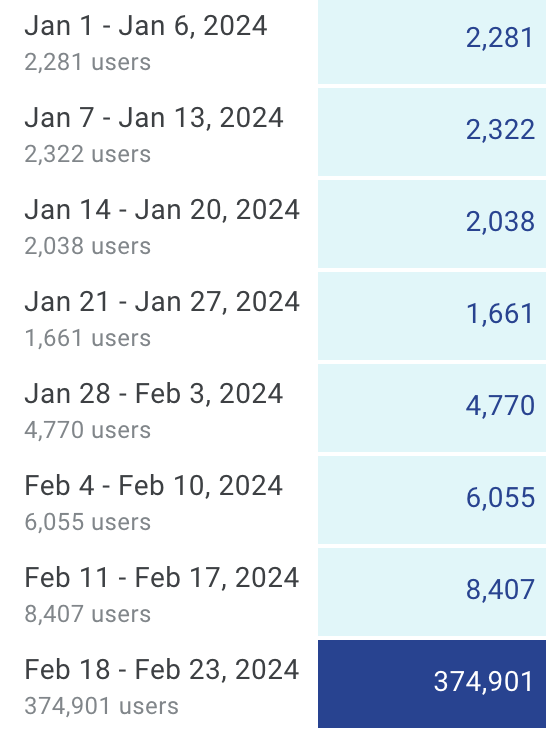

23 Feb 2024
Did someone say they were worried about @Groq's cost/ability to scale? 👀 #GroqSpeed

11
10
75
17,296
21 Feb 2024
Wow on the press recently, thanks (@Gizmodo, @stratechery, @SemiAnalysis_) for the coverage of @GroqInc. 🙏 We're 2 months into providing early access to our LPU™ systems. Since recent publishings we've pushed a software update last night that gets more than 2x the throughput (capacity). Expect another liiiiiitle bit more throughput in the next week or two 😉
#BetterOnGroq #GroqSpeed
9
16
101
16,098


21 Feb 2024
It's not every day an infra company goes viral, even in AI. Groq is having a moment and it's a case study in direct comms. Here are 4 things they're doing really well and 3 untapped opportunities.
This is where the team really nailed it:
1. MAKING IT VISCERAL
a) Groq coined the perfect new term with LPU (Language Processing Unit), they’re creating a new category around it, and they’ve made fetch happen through sheer repetition.
b) The below visual of their chip next to a GPU is brilliant, specifically because (1) obviously visuals hit in a way that words don’t, (2) images get more engagement and better algo boosts, and (3) while a list of specs might show the GPU winning in many ways, the image highlights Groq’s winning metric: purpose-built simplicity.
c) They use simple numbers (10X, 100X), which trades being precise for being memorable. They also use analogies to make complex ideas clear and easy to repeat (comparing a general purpose chip to an assembly line you have to set up from scratch every time). Much easier to recount over dinner.
2. GOING DIRECT
a) The CEO addresses criticism on Twitter quickly and proactively, while showing his credentials as a technical domain expert. The founder entering the chat to clear up technical details himself can be a KO move.
b) Their team is also super active on Hacker News, responding to comments on a very technical level and sharing details with relevant people (eg potential customers) — while stopping short of compromising trade secrets.
c) Lastly, Groq has been posting content for years now, gradually building up an audience to tap into when the time is right (now)
3. BENEFITS BEFORE BACKEND
a) Many founders get so excited about the technology that they lead with the specs. What people really care about is how it can make their lives easier. The Groq team understands this. Their entire homepage is basically a free demo. Everything else (who we are, all the marketing type stuff) is in the sidebar.
b) “Show, don’t tell” is powerful. The CEO understands this, telling the CNN interviewer that it’s better to show “the magic” before diving into how it works.
c) Jonathan Ross is a gifted communicator and has a way with words. When the interviewer mistakenly asked about Groq’s “models,” he smoothly said, “We don’t make the models, we just make them fast.” To show how engagement drops with lag, he said, “Imagine…if….I…spoke…this…slow…” to make the point. (I think it’s no coincidence he reads a lot of books about comms — see linked post).
4. PERFECT TIMING
a) While they’ve had tech coverage here and there for a while, they timed their mainstream press push perfectly, going on CNN after the biggest wave of chip news in probably the last decade. I often tell founders to concentrate their efforts on a lightning strike moment instead of a low-level drumbeat, and that's what the Groq team pulled off here.
And here are 3 opportunities to get even better (from the uninformed perspective of an outsider):
1. MESSAGING
a) Talk about Groq’s speed advantage not as a marginal difference on a scale (others are only somewhat fast while we’re very fast) but as a 0 to 1 problem: when natural language models actually feel natural, new products and experiences become possible that never were before. (In fact I’d suggest that as a tagline: “Making natural language natural”
b) Target this messaging specifically to potential customers (Groq’s speed isn’t a marginal improvement but a step change), and help developers understand what that speed ENABLES (new interactive experiences like in video games). Groq has undersold this so far and have a chance to own the whole concept of having a true natural language conversation.
c) The debate about pricing vs. NVIDIA is misguided. Even Citrini wrote, “You’d need about 600 of these to have the same performance as a 8x H100 box” — but Groq should emphasize that processing power doesn’t directly represent the speed experienced by the consumer actually running the models. You can’t have a baby in one month with nine women!
d) Similarly, some people will judge Groq on the quality of the output, so the team should keep reminding people that the point isn’t to compare Mixtral to Llama or whatever, the point is that each model runs faster on Groq than on other chips.
2. MORE TARGETING
a) Get more precise about their audience. Eg, sometimes they compare themselves to infra providers, sometimes to NVIDIA. It probably makes most sense to do the infra providers comparison when they’re targeting developers and do the NVIDIA comparison when they’re targeting investors and talent.
3. LEVEL UP WHAT’S WORKING
a) Lean more into LPUs as a new category. Eg, get someone to create a Wikipedia page for “Language Processing Unit” and cite Groq as the inventor of the first LPU and creator of the category.
b) Complement their excellent metrics graphs with even more visceral demonstrations of the product’s capabilities (eg with gifs or more analogies). They're already doing this a lot and it works so well.
c) Use X more effectively. Eg, update the pinned tweet to this one from @BrianRoemmele twitter.com/BrianRoemmele/st….
And consider retiring #groqspeed; hashtags don’t work, nobody else is going to use it, and it makes a post look spammy. I assume more than three hashtags in one post is likely to get treated as spam by the algo too; I think that’s what LinkedIn does.
It's awesome to see more and more founders building their own direct comms channels, and I hope Groq's success on this front is helpful for other founder-led companies in the future.

20 Feb 2024

Groq's LPU is faster than GPUs, handling requests and responding more quickly.
Groq's LPUs don't need speedy data delivery like Nvidia GPUs do because they don't have HBM in their system. They use SRAM, which is about 20 times faster than what GPUs use. Since inference runs use way less data than model training, Groq's LPU is more energy-efficient. It reads less from external memory and uses less power than a Nvidia GPU for inference tasks.
The LPU works differently from GPUs. It uses a Temporal Instruction Set Computer architecture, so it doesn't have to reload data from memory as often as GPUs do with High Bandwidth Memory (HBM). This helps avoid issues with HBM shortages and keeps costs down.
If Groq's LPU is used in places that do AI processing, you might not need special storage for Nvidia GPUs. The LPU doesn't demand super-fast storage like GPUs do. Groq is claiming that its technology could replace GPUs in AI tasks with its powerful chip and software.
20
50
482
114,169
I was reading up on the Sora release and wondered what about AI causes so much backlash. Then wrote a blog post. And please be sure to check out the Dashboard at vapi.ai and see what #Groqspeed combined with Voice AI can do. @GroqInc
blog.vapi.ai/sora-markov-cha…
11
15
87
21,532
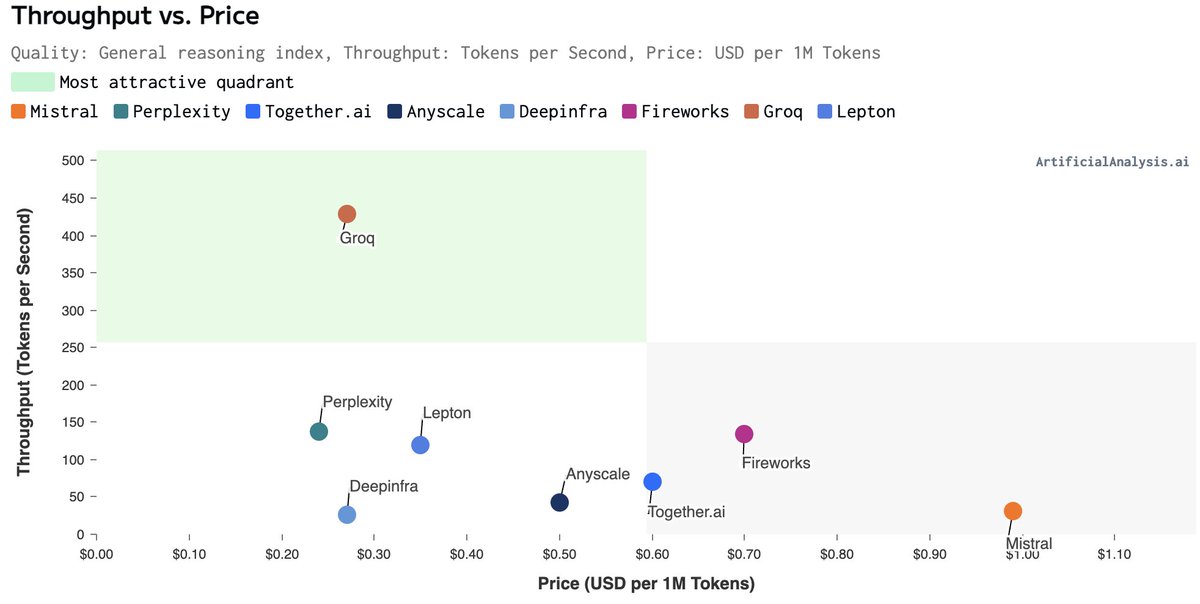
21 Feb 2024
What do @GroqInc's LPUs cost? So much curiosity!
We're very comfortable with this pricing and performance - and no, the chips/cards don't cost anywhere near $20,000 😂
#Groqspeed
30
37
377
346,831
Talk to the Churchill bot created by @Vapi_AI powered by the #Groqspeed of our LPU™ Inference Engine. Conversational AI at ultra-low-latency unlocks so much potential for agents and beyond. Well done Vapi!

Good afternoon! Dropping another demo powered by @GroqInc Speed combined with Vapi's Voice AI dashboard. Introducing, Sir Winston Churchill-bot. 🇬🇧
#GenAI #VoiceAI #ConversationalAI #ChatGPT
youtu.be/VKrWh3G7OH4
3
18
9,463
Shout out to one of our partners @Vapi_AI who continues to push boundaries in speech-to-text solutions running our LPU™ Inference Engine in the background.
#betterongroq #groqspeed
Good evening! As a follow-up to the Taylor Swift-bot demo, we wanted to walk you through our dashboard to see how simple it is to create voicebots powerful enough for any use case.
Thanks to @GroqInc @DeepgramAI @OpenAI @play_ht
#GenAI #voicebot #voiceai #ChatGPT #ConversationalAI
3
22
8,429