
18 May 2025
Leveraging Large Language Models for Literature-Driven Prioritization of Protein Binding Pockets
1.This study presents a hybrid pipeline that integrates geometric pocket prediction (via Fpocket) with Large Language Models (LLMs) to prioritize biologically relevant protein binding pockets using experimental literature evidence.
2.The key innovation is using LLMs to extract residue-level binding site information directly from research papers and use that to filter and refine geometrically predicted pockets—automating a task traditionally reliant on expert manual curation.
3.The authors developed a curated benchmark dataset of 10 proteins and 35 annotated papers, including diverse scenarios: no binding site, one known site, or multiple sites—allowing robust LLM evaluation.
4.The LLM pipeline consists of three stages: paper filtering (relevance detection), pocket extraction (residue identification), and pocket refinement (error correction and format enforcement), all using direct prompting without complex reasoning chains.
5.Prompt optimization and a final refinement step increased Pocket Number Accuracy from 0.48 to 0.71, Pocket Specificity from 0.46 to 0.657, and maintained perfect Pocket Recall (1.0).
6.For each target, extracted pockets were mapped onto 3D PDB structures using a clustering algorithm that accounts for chain variations, structural inconsistencies, and multimeric interfaces—yielding spatially resolved binding sites.
7.The final volumetric representation of each pocket is computed by filtering Fpocket alpha spheres against LLM-extracted residues, converting them to a grid format, and trimming volumes using convex hulls to eliminate solvent-exposed artifacts.
8.This approach successfully unified binding site descriptions across multiple publications, enabling more consistent identification of ligand-accessible regions in proteins like GABAA, MLKL, M2 receptor, and Nav1.7.
9.The benchmark revealed limitations in Fpocket’s native output (e.g., site fragmentation or over-merging), which were mitigated by the LLM-assisted filtering and merging process based on spatial residue proximity.
10.The authors provide an open-source benchmark dataset and curated markdown-formatted articles to support further development of LLM-based literature mining tools for structural biology.
11.This study showcases the growing potential of LLMs to automate literature-based knowledge extraction for practical drug discovery tasks—reducing reliance on human domain expertise in structure-based modeling workflows.
💻Code: github.com/MelnychenkoM/LLM-…
📜Paper: biorxiv.org/content/10.1101/…
#DrugDiscovery #LLM4Bio #ProteinBindingSites #BindingPockets #Fpocket #MolecularModeling #AI4Science #StructuralBiology #LiteratureMining #PDB #Bioinformatics #MachineLearning #HybridMethods
4
972
18 May 2025
Leveraging Large Language Models for Literature-Driven Prioritization of Protein Binding Pockets
1.This study presents a hybrid pipeline that integrates geometric pocket prediction (via Fpocket) with Large Language Models (LLMs) to prioritize biologically relevant protein binding pockets using experimental literature evidence.
2.The key innovation is using LLMs to extract residue-level binding site information directly from research papers and use that to filter and refine geometrically predicted pockets—automating a task traditionally reliant on expert manual curation.
3.The authors developed a curated benchmark dataset of 10 proteins and 35 annotated papers, including diverse scenarios: no binding site, one known site, or multiple sites—allowing robust LLM evaluation.
4.The LLM pipeline consists of three stages: paper filtering (relevance detection), pocket extraction (residue identification), and pocket refinement (error correction and format enforcement), all using direct prompting without complex reasoning chains.
5.Prompt optimization and a final refinement step increased Pocket Number Accuracy from 0.48 to 0.71, Pocket Specificity from 0.46 to 0.657, and maintained perfect Pocket Recall (1.0).
6.For each target, extracted pockets were mapped onto 3D PDB structures using a clustering algorithm that accounts for chain variations, structural inconsistencies, and multimeric interfaces—yielding spatially resolved binding sites.
7.The final volumetric representation of each pocket is computed by filtering Fpocket alpha spheres against LLM-extracted residues, converting them to a grid format, and trimming volumes using convex hulls to eliminate solvent-exposed artifacts.
8.This approach successfully unified binding site descriptions across multiple publications, enabling more consistent identification of ligand-accessible regions in proteins like GABAA, MLKL, M2 receptor, and Nav1.7.
9.The benchmark revealed limitations in Fpocket’s native output (e.g., site fragmentation or over-merging), which were mitigated by the LLM-assisted filtering and merging process based on spatial residue proximity.
10.The authors provide an open-source benchmark dataset and curated markdown-formatted articles to support further development of LLM-based literature mining tools for structural biology.
11.This study showcases the growing potential of LLMs to automate literature-based knowledge extraction for practical drug discovery tasks—reducing reliance on human domain expertise in structure-based modeling workflows.
💻Code: github.com/MelnychenkoM/LLM-…
📜Paper: biorxiv.org/content/10.1101/…
#DrugDiscovery #LLM4Bio #ProteinBindingSites #BindingPockets #Fpocket #MolecularModeling #AI4Science #StructuralBiology #LiteratureMining #PDB #Bioinformatics #MachineLearning #HybridMethods

6
27
1,664

2 Dec 2024
Two new #TUPLES Posters at #ANITIDays highlighting its objectives and advancements in building trustworthy planning and scheduling systems.
See the Posters here bit.ly/3ZyX5DC
#AI #TrustworthyAI #Explainability #HybridMethods #Gooseplanners

1
3
92
31 May 2022
Attn #structuralbiology Twitter. Looking for recent, cool examples to highlight in a masters course that utilise #hybridmethods to study the structure of proteins and protein complexes. Suggestions welcome!
1

We look forward to welcoming our guest speakers in person at St. Jude next Monday for the Symposium!
#structuralbiology #crystallography #NMR #cryoEM #cryoET #MDSims #HybridMethods #MachineLearning #ComputationalStructuralBiology #IntegrativeStructuralBiology

3
19
47

5 Oct 2021
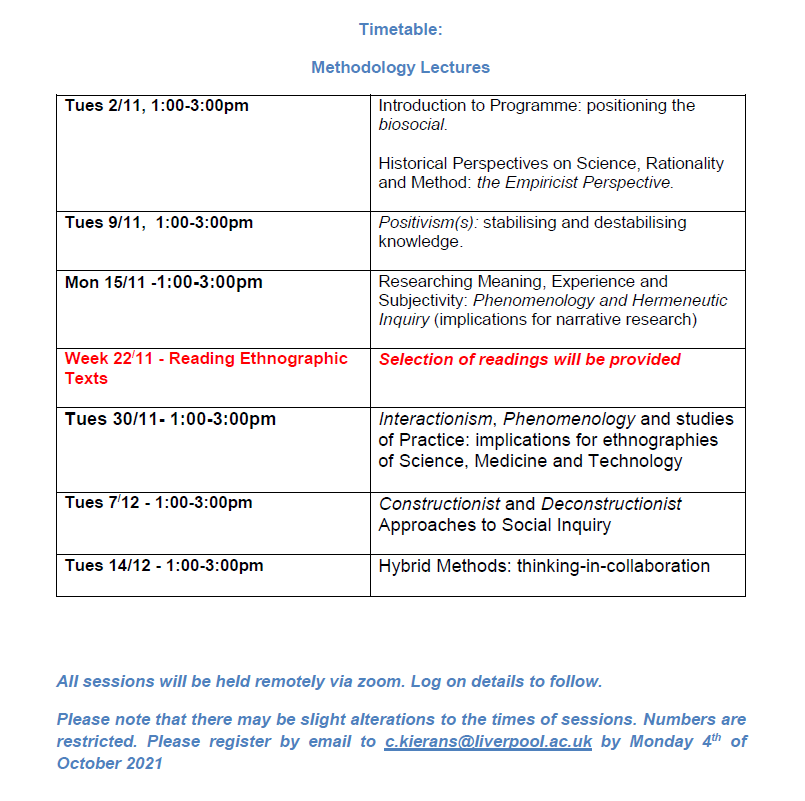
📢Faculty of Health and Life Sciences at Uni of Liverpool PGR Research Programme for Winter has great lectures on #phenomenology #QualitativeResearch #Empiricism #Positivism #HybridMethods #Constructionist #Deconstructionist
Register your interest!
1
2

29 Sep 2021
1
6

28 May 2021
Belarus needs #freedom.
- Not #Protasevich and #Sapega!
🇪🇺⚡️🇧🇾
#eudebates #BelarusHighjacking #BelarusHijacking #Belarusian #hybridmethods
28 May 2021

Roman Protasevich and Sofia Sapega are still being detained following Sunday’s forced landing of a Ryanair flight in Minsk. @EP_President David Sassoli calls for their immediate release and a strong & unified EU response. Share if you agree #freeRomanProtasevich #freeSofiaSapega

2

20 Oct 2020
Talks from women @DCS, Sheffield are now online. Thank you @AlineVillav for the invite and the discussion of what need/can be done! The inference bit is a bonus! Natural Language Inference for Humans by #hybridmethods #naturallanguageinference slideshare.net/valeria.depai…

1
1
4

16 Sep 2020
#KR20 Very interesting talk by @EmilevanKrieken
@krr_vu on ways to combine ML-based representations with fuzzy-logic rules to get the best of both worlds
#KR & #ML #hybridmethods #AI
8 Jun 2020

Excited that our paper on Differentiable Fuzzy Implications was accepted to #KR2020's session on KR ML!
We analyze the behaviour of Fuzzy Implications in ML contexts.
With @erman_ai & @FrankVanHarmele
arXiv: arxiv.org/abs/2006.03472
Thread (1/6):
1
3
7

21 May 2018
In Pisa for @cecamEvents meeting on Physiological Role of Ions in the Brain with @BioExcelCoE. Applications of #MolecularDynamics, #Docking #HybridMethods and more...
4
3

6 Dec 2017
You can model a system as solo,
Using macro, meso or micro,
But it is much better,
To join them together,
Making your code so rapido. #PhDlimerick #HybridMethods
4
3 Apr 2017
Good to be joining those from @HPCLEAP who are working with #HybridMethods in #MolecularModeling and describing what @BioExcelCoE can offer.
2

6 Apr 2015
Our paper on the #integrin beta4 FnIII-3,4 structure by #hybridmethods is out @ActaCrystD bit.ly/1Cs8n6U

1
6
3


