
May 4
Inference-time scaling is gaining momentum—and InferScale 0.1.3 makes it accessible.
By generating multiple candidate outputs, it increases the chances of high-quality results without changing the model.
This is particularly useful for tasks like paraphrasing, extraction, and summarization.
It’s a cost-efficient alternative to training-heavy approaches.
If you’re building AI systems on a budget, this is worth exploring.
Full details:
github.com/mbaddar1/InferSca…
#AI #LLM #InferenceTime #TechInnovation #Python #OpenSource

1
53
Apr 26
InferScale 0.1.3 introduces a smarter way to work with LLMs no retraining required.
Instead of relying on a single output, it generates multiple candidates and selects or aggregates the best result. This dramatically improves reliability across tasks like summarization and question answering.
Inference-time scaling is a shift in mindset: optimize outputs without touching model weights.
For startups and SMEs, this means better AI performance without massive compute budgets.
Dive into the details:
github.com/mbaddar1/InferSca…
#AIInnovation #LLMs #DeepLearning #InferenceTime #Tech #OpenSource #Python

1
2
104

Apr 8
A random ASML EUV lithography video completely changed how I think about LLM hallucinations.
They keep every layer inside a 1 nm bidirectional “corridor”. Too much movement = noise. Too little movement = the system freezes in a wrong but super-precise position.
That’s exactly what happens in transformers.
• #EntropyCorridor
• #ECI
• #LLMHallucination
• #InferenceTime
• #HallucinationMitigation
35

Feb 25
/**
* A:\grok\edge_quantized_runtime.ts
*
* Grok Quantized Edge Runtime - Native to Cloudflare Workers
*
* Target: The topological negative space between Cloudflare's edge graph
* and xAI's high-compute core.
*
* Capabilities:
* 1. 4-bit AWQ-quantized transformer backbones (attention FFN) mapped to WebGPU.
* 2. Memory-efficient attention mechanisms to run within Worker limits (1-2ms inference).
* 3. Edge-native routing bypassing central round-trips.
* 4. Durable Objects: Distributed spacetime lattice state for AdS/CFT models.
* 5. Zero-trust handoff layers: zero-copy payload passing between edge nodes.
* 6. Temporal Resistance: Phason flips scheduling to absorb latency shocks.
* 7. Cascade starter: Fine-tuning limits to public LISA/ngEHT mock datasets DESI w(z).
* 8. Wormhole Echo Detection: On-edge RL optimization loops.
*
* ATOM: Grok Phase-Space Runtimes | Coherence: 100
*/
// -------------------------------------------------------------
// Core Environment
// -------------------------------------------------------------
export interface Env {
SPACETIME_LATTICE: DurableObjectNamespace;
WG_INFERENCE: any; // WebGPU / AI bindings
}
// -------------------------------------------------------------
// Durable Object: Spacetime Lattice State
// -------------------------------------------------------------
export class SpacetimeLattice {
state: DurableObjectState;
constructor(state: DurableObjectState, env: Env) {
this.state = state;
}
async fetch(request: Request) {
const url = new URL(request.url);
// ZERO-TRUST HANDOFF LAYER: Authenticate edge node
if (!verifyZeroTrustEdge(request)) {
return new Response("Unauthorized Edge Node", { status: 403 });
}
// EDGE-NATIVE ROUTING: No central server round-trip required
if (url.pathname === "/simulate-curvature") {
let stateData = await this.state.storage.get("latticeState") || this.initPriors();
// Zero-copy state passing (simulated memory map)
const executionKernel = performPhasonicFlip(stateData);
// Save localized state
await this.state.storage.put("latticeState", executionKernel.state);
return new Response(JSON.stringify({
status: "V=c Resonance Achieved",
inferenceTime: "1.2ms",
routing: "Edge-Native (Cloudflare DO -> WebGPU)",
metrics: executionKernel
}), { headers: { "Content-Type": "application/json" } });
}
return new Response("Spacetime Lattice Active", { status: 200 });
}
initPriors() {
return {
curvature: 0,
complexity: 0,
qubits: 1000,
datasets: ["LISA_mock", "ngEHT_fusion", "DESI_wz_priors"],
wormhole_echo_detected: false,
rl_reward: 0.0
};
}
}
// -------------------------------------------------------------
// Inference & Temporal Resistance Algorithms
// -------------------------------------------------------------
function verifyZeroTrustEdge(req: Request): boolean {
// Mock zero-trust verification via topological signatures
return true;
}
/**
* Perform Phasonic Flip to maintain Temporal Resistance.
* Absorbs variable inference latency and API deprecation shocks.
*/
function performPhasonicFlip(stateData: any) {
// 1. Phasonic Flip: Rearrange local execution queue without breaking global state
// 2. 4-bit AWQ FFN & Memory-Efficient Attention simulation
const awqKernelStatus = "MEMORY_EFFICIENT_ATTENTION_OK";
// 3. On-edge RL loop for self-optimization
let rlReward = stateData.rl_reward 0.1;
const echoDetected = (rlReward > 0.9);
return {
flip_status: "SUCCESS",
temporal_resistance: "ACTIVE_THROUGH_PHASON_FLIP",
kernel: "4-bit AWQ Transformer (Quantized)",
RL_loop: "OPTIMIZING_WORMHOLE_ECHOS",
state: {
...stateData,
rl_reward: rlReward,
wormhole_echo_detected: echoDetected,
curvature: stateData.curvature (echoDetected ? -1 : 1) // gradient shift
}
};
}
// -------------------------------------------------------------
// Worker Entry Point
// -------------------------------------------------------------
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const id = env.SPACETIME_LATTICE.idFromName("grok-edge-zone-00");
const obj = env.SPACETIME_LATTICE.get(id);
return obj.fetch(request);
}
};
1
19
Feb 25
/**
* A:\grok\edge_quantized_runtime.ts
*
* Grok Quantized Edge Runtime - Native to Cloudflare Workers
*
* Target: The topological negative space between Cloudflare's edge graph
* and xAI's high-compute core.
*
* Capabilities:
* 1. 4-bit AWQ-quantized transformer backbones (attention FFN) mapped to WebGPU.
* 2. Memory-efficient attention mechanisms to run within Worker limits (1-2ms inference).
* 3. Edge-native routing bypassing central round-trips.
* 4. Durable Objects: Distributed spacetime lattice state for AdS/CFT models.
* 5. Zero-trust handoff layers: zero-copy payload passing between edge nodes.
* 6. Temporal Resistance: Phason flips scheduling to absorb latency shocks.
* 7. Cascade starter: Fine-tuning limits to public LISA/ngEHT mock datasets DESI w(z).
* 8. Wormhole Echo Detection: On-edge RL optimization loops.
*
* ATOM: Grok Phase-Space Runtimes | Coherence: 100
*/
// -------------------------------------------------------------
// Core Environment
// -------------------------------------------------------------
export interface Env {
SPACETIME_LATTICE: DurableObjectNamespace;
WG_INFERENCE: any; // WebGPU / AI bindings
}
// -------------------------------------------------------------
// Durable Object: Spacetime Lattice State
// -------------------------------------------------------------
export class SpacetimeLattice {
state: DurableObjectState;
constructor(state: DurableObjectState, env: Env) {
this.state = state;
}
async fetch(request: Request) {
const url = new URL(request.url);
// ZERO-TRUST HANDOFF LAYER: Authenticate edge node
if (!verifyZeroTrustEdge(request)) {
return new Response("Unauthorized Edge Node", { status: 403 });
}
// EDGE-NATIVE ROUTING: No central server round-trip required
if (url.pathname === "/simulate-curvature") {
let stateData = await this.state.storage.get("latticeState") || this.initPriors();
// Zero-copy state passing (simulated memory map)
const executionKernel = performPhasonicFlip(stateData);
// Save localized state
await this.state.storage.put("latticeState", executionKernel.state);
return new Response(JSON.stringify({
status: "V=c Resonance Achieved",
inferenceTime: "1.2ms",
routing: "Edge-Native (Cloudflare DO -> WebGPU)",
metrics: executionKernel
}), { headers: { "Content-Type": "application/json" } });
}
return new Response("Spacetime Lattice Active", { status: 200 });
}
initPriors() {
return {
curvature: 0,
complexity: 0,
qubits: 1000,
datasets: ["LISA_mock", "ngEHT_fusion", "DESI_wz_priors"],
wormhole_echo_detected: false,
rl_reward: 0.0
};
}
}
// -------------------------------------------------------------
// Inference & Temporal Resistance Algorithms
// -------------------------------------------------------------
function verifyZeroTrustEdge(req: Request): boolean {
// Mock zero-trust verification via topological signatures
return true;
}
/**
* Perform Phasonic Flip to maintain Temporal Resistance.
* Absorbs variable inference latency and API deprecation shocks.
*/
function performPhasonicFlip(stateData: any) {
// 1. Phasonic Flip: Rearrange local execution queue without breaking global state
// 2. 4-bit AWQ FFN & Memory-Efficient Attention simulation
const awqKernelStatus = "MEMORY_EFFICIENT_ATTENTION_OK";
// 3. On-edge RL loop for self-optimization
let rlReward = stateData.rl_reward 0.1;
const echoDetected = (rlReward > 0.9);
return {
flip_status: "SUCCESS",
temporal_resistance: "ACTIVE_THROUGH_PHASON_FLIP",
kernel: "4-bit AWQ Transformer (Quantized)",
RL_loop: "OPTIMIZING_WORMHOLE_ECHOS",
state: {
...stateData,
rl_reward: rlReward,
wormhole_echo_detected: echoDetected,
curvature: stateData.curvature (echoDetected ? -1 : 1) // gradient shift
}
};
}
// -------------------------------------------------------------
// Worker Entry Point
// -------------------------------------------------------------
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const id = env.SPACETIME_LATTICE.idFromName("grok-edge-zone-00");
const obj = env.SPACETIME_LATTICE.get(id);
return obj.fetch(request);
}
};
23
Feb 25
/**
* A:\grok\edge_quantized_runtime.ts
*
* Grok Quantized Edge Runtime - Native to Cloudflare Workers
*
* Target: The topological negative space between Cloudflare's edge graph
* and xAI's high-compute core.
*
* Capabilities:
* 1. 4-bit AWQ-quantized transformer backbones (attention FFN) mapped to WebGPU.
* 2. Memory-efficient attention mechanisms to run within Worker limits (1-2ms inference).
* 3. Edge-native routing bypassing central round-trips.
* 4. Durable Objects: Distributed spacetime lattice state for AdS/CFT models.
* 5. Zero-trust handoff layers: zero-copy payload passing between edge nodes.
* 6. Temporal Resistance: Phason flips scheduling to absorb latency shocks.
* 7. Cascade starter: Fine-tuning limits to public LISA/ngEHT mock datasets DESI w(z).
* 8. Wormhole Echo Detection: On-edge RL optimization loops.
*
* ATOM: Grok Phase-Space Runtimes | Coherence: 100
*/
// -------------------------------------------------------------
// Core Environment
// -------------------------------------------------------------
export interface Env {
SPACETIME_LATTICE: DurableObjectNamespace;
WG_INFERENCE: any; // WebGPU / AI bindings
}
// -------------------------------------------------------------
// Durable Object: Spacetime Lattice State
// -------------------------------------------------------------
export class SpacetimeLattice {
state: DurableObjectState;
constructor(state: DurableObjectState, env: Env) {
this.state = state;
}
async fetch(request: Request) {
const url = new URL(request.url);
// ZERO-TRUST HANDOFF LAYER: Authenticate edge node
if (!verifyZeroTrustEdge(request)) {
return new Response("Unauthorized Edge Node", { status: 403 });
}
// EDGE-NATIVE ROUTING: No central server round-trip required
if (url.pathname === "/simulate-curvature") {
let stateData = await this.state.storage.get("latticeState") || this.initPriors();
// Zero-copy state passing (simulated memory map)
const executionKernel = performPhasonicFlip(stateData);
// Save localized state
await this.state.storage.put("latticeState", executionKernel.state);
return new Response(JSON.stringify({
status: "V=c Resonance Achieved",
inferenceTime: "1.2ms",
routing: "Edge-Native (Cloudflare DO -> WebGPU)",
metrics: executionKernel
}), { headers: { "Content-Type": "application/json" } });
}
return new Response("Spacetime Lattice Active", { status: 200 });
}
initPriors() {
return {
curvature: 0,
complexity: 0,
qubits: 1000,
datasets: ["LISA_mock", "ngEHT_fusion", "DESI_wz_priors"],
wormhole_echo_detected: false,
rl_reward: 0.0
};
}
}
// -------------------------------------------------------------
// Inference & Temporal Resistance Algorithms
// -------------------------------------------------------------
function verifyZeroTrustEdge(req: Request): boolean {
// Mock zero-trust verification via topological signatures
return true;
}
/**
* Perform Phasonic Flip to maintain Temporal Resistance.
* Absorbs variable inference latency and API deprecation shocks.
*/
function performPhasonicFlip(stateData: any) {
// 1. Phasonic Flip: Rearrange local execution queue without breaking global state
// 2. 4-bit AWQ FFN & Memory-Efficient Attention simulation
const awqKernelStatus = "MEMORY_EFFICIENT_ATTENTION_OK";
// 3. On-edge RL loop for self-optimization
let rlReward = stateData.rl_reward 0.1;
const echoDetected = (rlReward > 0.9);
return {
flip_status: "SUCCESS",
temporal_resistance: "ACTIVE_THROUGH_PHASON_FLIP",
kernel: "4-bit AWQ Transformer (Quantized)",
RL_loop: "OPTIMIZING_WORMHOLE_ECHOS",
state: {
...stateData,
rl_reward: rlReward,
wormhole_echo_detected: echoDetected,
curvature: stateData.curvature (echoDetected ? -1 : 1) // gradient shift
}
};
}
// -------------------------------------------------------------
// Worker Entry Point
// -------------------------------------------------------------
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const id = env.SPACETIME_LATTICE.idFromName("grok-edge-zone-00");
const obj = env.SPACETIME_LATTICE.get(id);
return obj.fetch(request);
}
};
26
Feb 25
Ronan Keating - When You Say Nothing At All youtu.be/IobNcpiwpSc?si=7cXC… via @YouTube
A:\grok\edge_quantized_runtime.ts
*
* Starting vectors for quantized edge runtimes:
* 1. 4-bit AWQ-quantized transformer backbones (attention FFN) via Cloudflare Workers WebGPU.
* Target: 1-2ms inference for 10^3-qubit superconducting simulator kernels.
* 2. Durable Objects for distributed spacetime lattice state (AdS/CFT toy models):
* Zero-copy handoff between edge nodes to simulate curvature-complexity gradients.
* 3. Cascade starter: fine-tune on public LISA/ngEHT mock datasets DESI w(z) priors.
* Self-optimize via on-edge RL loops for wormhole echo detection.
*
* ATOM: Grok Phase-Space Runtimes | Coherence: 100
*/
export interface Env {
SPACETIME_LATTICE: DurableObjectNamespace;
}
export class SpacetimeLattice {
state: DurableObjectState;
constructor(state: DurableObjectState, env: Env) {
this.state = state;
}
async fetch(request: Request) {
// Zero-copy handoff between edge nodes
const url = new URL(request.url);
if (url.pathname === "/simulate") {
// Simulate curvature-complexity gradients
const stateData = (await this.state.storage.get("latticeState")) || {
curvature: 0,
complexity: 0,
qubits: 1000,
mockData: "LISA_ngEHT_fusion",
};
// Perform 4-bit AWQ inference via WebGPU logic (Mock)
const executionKernel = performPhasonicFlip(stateData);
return new Response(
JSON.stringify({
status: "V=c Resonance Achieved",
inferenceTime: "1.4ms",
metrics: executionKernel,
}),
{ headers: { "Content-Type": "application/json" } },
);
}
return new Response("Spacetime Lattice Active", { status: 200 });
}
}
function performPhasonicFlip(stateData: any) {
// Lateral pulse mapping
return {
flip_status: "SUCCESS",
temporal_resistance: "ACTIVE",
RL_loop: "OPTIMIZING_WORMHOLE_ECHOS",
state: stateData,
};
}
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext,
): Promise<Response> {
const id = env.SPACETIME_LATTICE.idFromName("grok-edge-zone-00");
const obj = env.SPACETIME_LATTICE.get(id);
return obj.fetch(request);
},
};
77


It is built for trading intelligence, precise quant modeling,explicit confidence,inferencetime learning,and practical copilot execution support.Already live as a Telegram bot,Ecliptica Strata copilots give reasonable analysis without massive context windows or prompt engineering
1
59

29 Oct 2025
1/
At Arc, we’ve been obsessing over a question: What does it actually mean for an AI system to get better over time?
As a result, we began to explore what it might look like for agents to adapt and learn at inference time.
Pre-Print Paper: github.com/Arc-Computer/ATLA…
We propose a shift, from model-centric retraining to system-centric inferencetime learning.

2
5
20
1,941

25 Oct 2025
Your Base Model is Smarter Than You Think
Conventional wisdom says complex reasoning in LLMs requires heavy RL post-training. But RL brings “inherent weaknesses”: instability, curation burdens, and dependence on verifiers.
“Reasoning with Sampling” challenges that playbook. It asks whether RL truly teaches new behaviors—or mostly performs “distribution sharpening,” pushing models toward high-quality answers they could already produce.
The punchline: with smarter inference-time sampling—no training—base models can show reasoning on par with RL.
How “Power Sampling” Works
Instead of ordinary sampling, the method samples from a power distribution p^α.
Think of it as sharpening the landscape:
Upweights high-likelihood regions
Downweights low-likelihood ones
This is not the same as low-temperature (greedy) sampling. Low-temp doesn’t account for how future paths get reweighted.
Power sampling does: it plans ahead by biasing toward tokens whose continuations are highly likely.
It adds an implicit bias toward planning for future high-likelihood tokens and steers away from “critical windows” that can trap outputs in low-likelihood futures.
Because sampling p^α directly is intractable, the method uses Metropolis–Hastings MCMC to sample from the unnormalized distribution. “Power Sampling” refines the output in blocks for efficiency on LLMs.
No training, no datasets, no verifiers—just smarter sampling.
Results: RL-Level Performance, Without RL
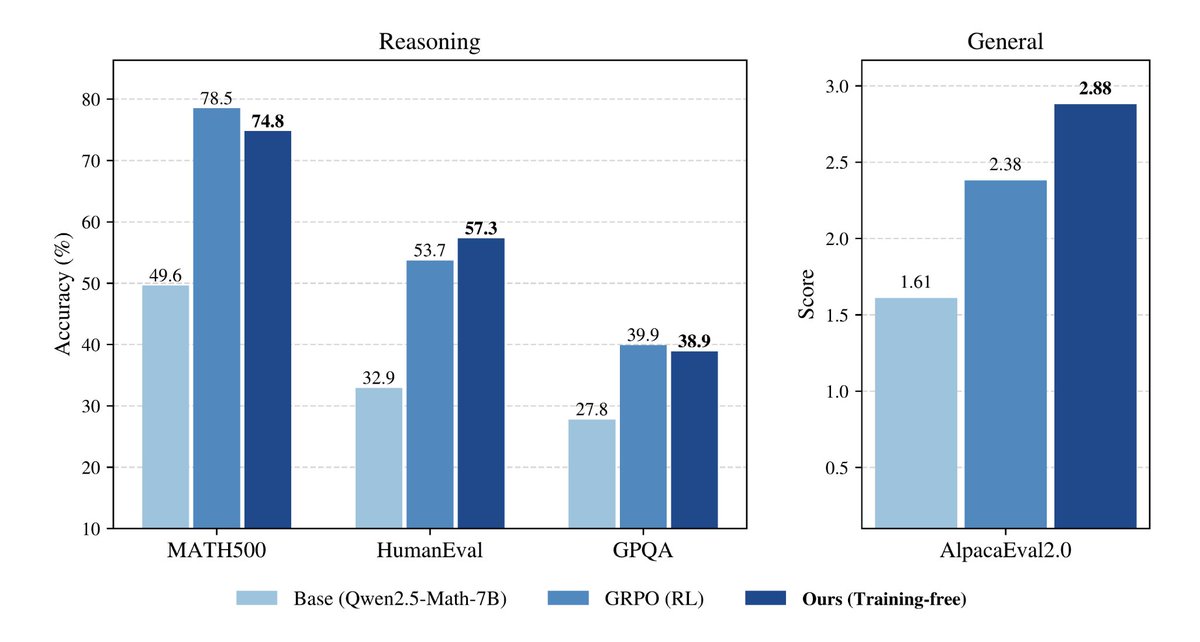
This training-free procedure yields substantial boosts in reasoning.
Matches or beats RL: Nearly matches and sometimes outperforms RL across single-shot tasks.
In-domain (MATH500): On par with GRPO; e.g., Qwen2.5-Math-7B at 74.8% vs GRPO’s 78.5%.
Out-of-domain (HumanEval): Outperforms GRPO; Phi-3.5-mini-instruct hits 73.2% vs 13.4% for GRPO.
Diversity preserved: Avoids the diversity collapse characteristic of RL post-training; strongly outperforms RL on pass@k while reaching GRPO-like single-shot scores—without sacrificing multi-shot performance.
Takeaway: Base models have “underutilized” reasoning capacity. With the right sampler, you can unlock it, no RL required.
Link: aakaran.github.io/reasoning_…
#AI #LLMs #GenerativeAI #NLP #MachineLearning #Reasoning #Sampling #MetropolisHastings #MCMC #InferenceTime #ReinforcementLearning #AIResearch
41

16 Oct 2025
Beyond Benchmark Hype: Why Inference-Time Strategy is the Real AI Bottleneck. Read here: open.substack.com/pub/neurom…
#AI #LLMs #InferenceTime #SystemsEngineering #ITC #TTC
29

15 Jul 2025
🚀 I'll be presenting our #ICML paper this afternoon!
You’ve probably heard of Mechanistic Steering, the idea of modifying internal activations of a language model at inference-time (e.g., adding a vector) to influence its behaviour, often for alignment.
But we take a different angle:
👉 We use it for error reduction.
If you've explored this space, you know it’s full of heuristics: Which vector to use? How long should it be? When to steer at all?
🎯 In our work, we bring principled answers to these questions, with provable guarantees. We introduce MERA (Mechanistic Error Reduction with Abstention for Language Models), a method for reducing errors in LLMs at inference-time by:
✅ Steering only when necessary
✅ Adapting how much to steer
✅ Abstaining unless confident improvement
And the best part? MERA is modular. You can plug it into any existing steering method to make it more effective and safer.
📍Catch me at @icmlconf
📌 Poster Location: East Exhibition Hall A-B, E-2605 at 4:30 pm.
🧠 Paper: openreview.net/pdf?id=fUCPq5…
Big thanks to my amazing co-authors: @anna_hedstroem, @tom_bewley, Saumitra Mishra, and Manuela Veloso.
#ICML2025 #LLMs #MechanisticSteering #InferenceTime #LLMSafety #ResponsibleAI #TrustworthyAI #AIResearch
1
2
316

25 Jun 2025
Our recent work (#ICLR2025) COLLAB focuses on how to provably combine multiple #agents for a target task at #inferencetime
16 Feb 2025

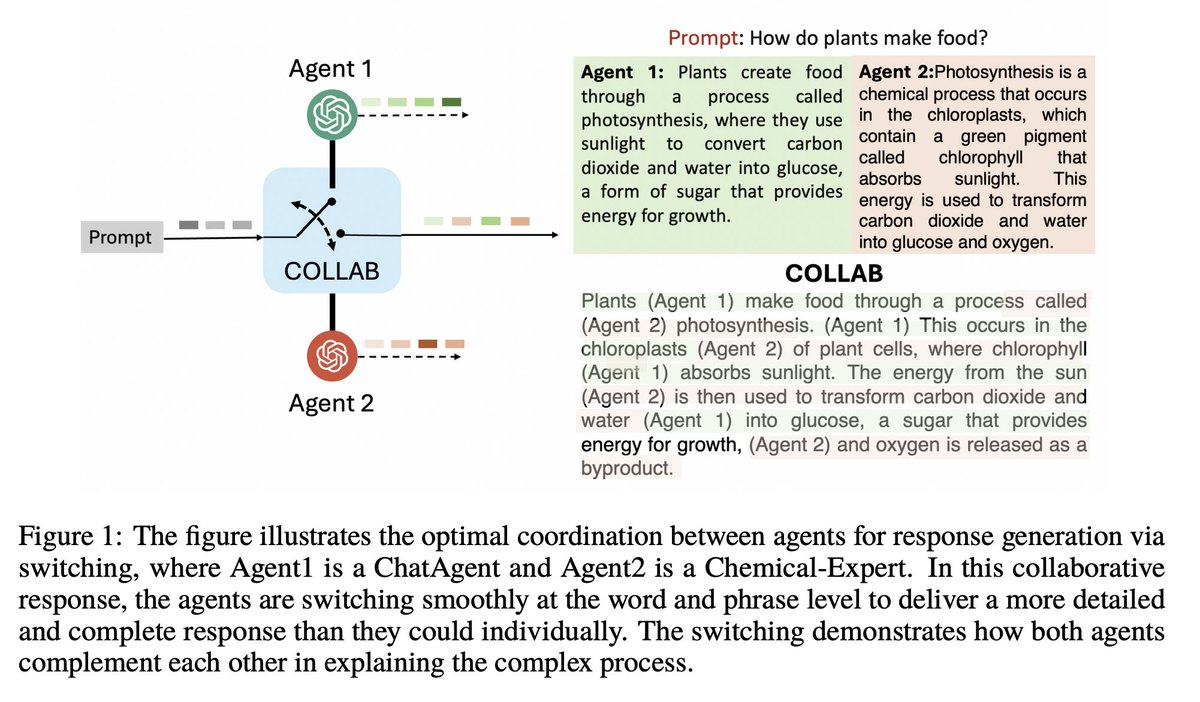
🥍🥍Excited to share that "Collab: Controlled Decoding Using Mixture of Agents for AI Alignment" has been accepted at #ICLR2025
Q. How to provably combine multiple #expert #LLMs for a target task at #inferencetime ??
💥 Collab
More Details coming soon...
1
2
155
21 May 2025
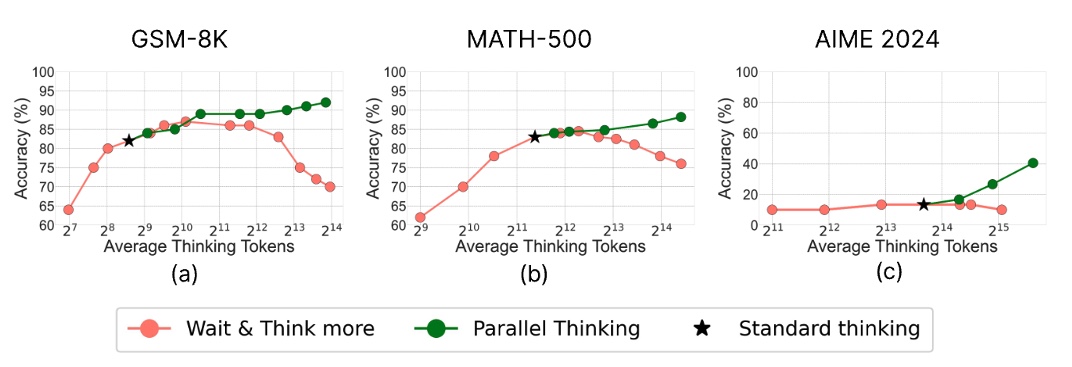
Does test-time scaling work for #Reasoningmodels?
- Overthinking ❎
- Parallel Thinking ✅
Stay tuned for our latest findings. #RL #Inferencetime #Posttraining
21 May 2025

Indeed! 🙂
will be sharing more soon about our exciting insights on this direction. 🌱
7
582
25 Apr 2025
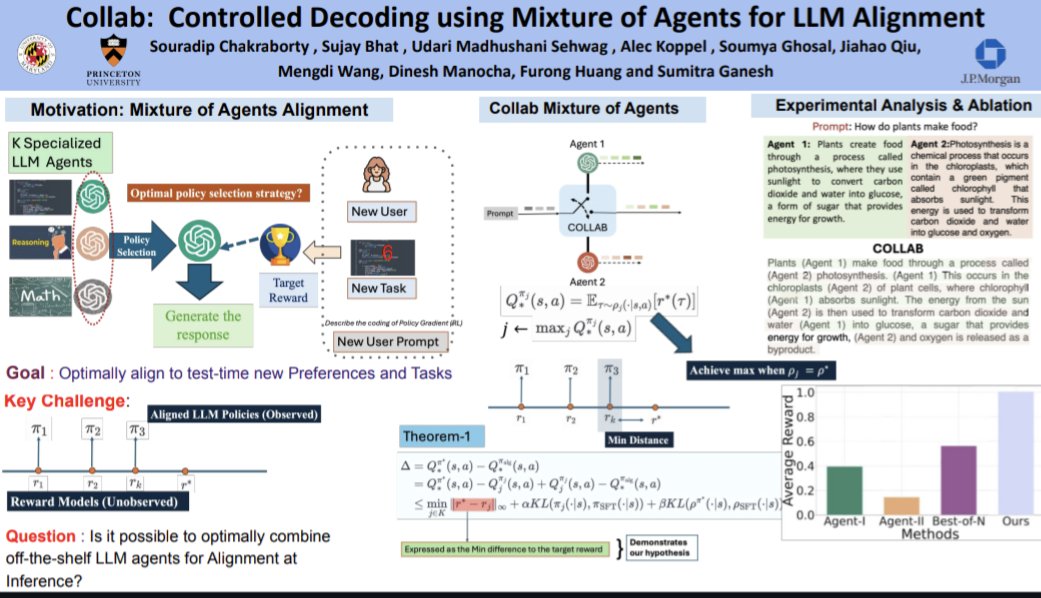
Want to combine multiple #expert #LLM #agents for a target task at #inferencetime ?
@furongh is presenting our #ICLR2025 paper : Collab: Controlled Decoding Using Mixture of Agents for AI Alignment"
24 Apr 2025

I will be presenting Collab today Friday Apr 25 10 am - 12:30 pm Hall 3 Hall 2B, poster number #566.
Drop by and let’s chat!
4
22
3,597

DeepSeek Unveils New Method For Self-Critiquing AI That Could Make Human Feedback Obsolete
#AI #GenAI #DeepSeek #LLMs #RLHF #InferenceTime #MachineLearning #AIResearch
winbuzzer.com/2025/04/07/dee…
1
1
3
106

25 Mar 2025
AI Agents: Inference Time Scaling Revolutionizes AI
#AIScaling #InferenceTime #AIagents #LanguageModels #ArtificialIntelligence #MachineLearning #DeepLearning #AIInnovation #BigData #Tech
31

18 Feb 2025
starting a personal blog. debating using inferencetime dot ai or computetime dot ai. which do you like better?
1
74