
RosettaSearch: Multi-Objective Inference-Time Search for Protein Sequence Design
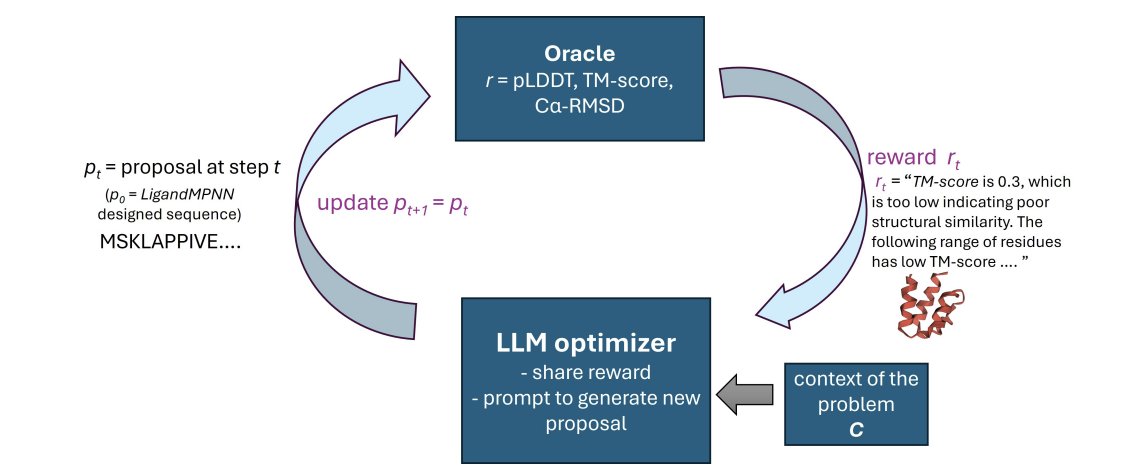
1. RosettaSearch is an inference-time framework that uses LLMs as generative optimizers to refine backbone-conditioned protein sequences via multi-objective search, guided by structural rewards from RosettaFold3, without any retraining or fine-tuning.
2. The key result: on ~400 challenging PDB monomer redesign cases initialized from suboptimal LigandMPNN outputs, RosettaSearch substantially improves structural fidelity (ss-pLDDT, TM-score, Cα-RMSD), yielding about a 2.5× increase in design success rate compared to LigandMPNN single-pass decoding.
3. The method is built around “feedback-driven editing” rather than one-shot generation: the LLM receives (a) global scalar rewards derived from structure prediction metrics and (b) local residue-range annotations highlighting problematic regions (low confidence or high deviation), then proposes targeted sequence edits.
4. Search matters: a priority-based parallel search strategy generally outperforms sequential revision. Priority search maintains a buffer of candidate sequences, repeatedly selects top-K candidates, proposes K new edits in parallel, evaluates via the structure oracle, and re-inserts all candidates—reducing premature convergence and improving robustness under a strict evaluation budget.
5. Multi-objective optimization is implemented as a weighted sum over ss-pLDDT (confidence), TM-score (global similarity), and Cα-RMSD (geometric deviation), with explicit penalties for large RMSD. Empirically, multi-objective setups improve multiple metrics simultaneously and increase success rates beyond single-objective optimization.
6. The paper emphasizes that residue-level feedback is not sufficient by itself: a compute-matched, information-matched random-mutation baseline (mutating only flagged regions) fails to improve and often degrades fidelity. The gains come from the LLM interpreting feedback and making chemically/structurally informed substitutions.
7. To reduce reward hacking (e.g., poly-alanine runs, motif repetition, length manipulation, or returning the native sequence), RosettaSearch adds soft constraints as textual feedback: repetition checks (6-mer redundancy), explicit length constraints, and (when applicable) ligand-binding position constraints to preserve functional interactions.
8. Generalization checks: improvements persist when final sequences are evaluated by an independent structure predictor (Chai-1), suggesting gains are not merely overfitting to RosettaFold3’s inductive biases. The approach also generalizes across LLM families (o4-mini and Gemini-3), and performance scales with reasoning capability (o3-mini < o4-mini).
9. Beyond native backbones, RosettaSearch also improves designs on de novo Dayhoff atlas backbones (RFDiffusion backbones with ProteinMPNN sequences). Even with strong starting success rates, RosettaSearch increases success-rate-1 from 72.4% to 89.5% and success-rate-2 from 45.5% to 67.3%, notably without providing any reference (native) sequence context.
10. A multi-modal extension uses vision-language models: rendered images of predicted structures are included as feedback to provide spatial context. Performance is comparable to text-only optimization in some settings, while producing qualitatively richer reasoning traces.
📜Paper: arxiv.org/abs/2604.17175
#ProteinDesign #ComputationalBiology #ProteinEngineering #LLM #InferenceTimeSearch #MultiObjectiveOptimization #RosettaFold #StructurePrediction #GenerativeOptimization #MachineLearning
4
6
40
2,303