
Mar 2
Who would have thought that putting 80k note into Obsidian Sync might cause a problem.
OK then the Hive needs a stronger backbone, who would have thought. ^^
Was leaning towards ElasticSearch and JanusGraph.
Any other ideas ?
2
62

1 Dec 2025
I ported Microsoft’s GraphRAG to .NET — and I need your feedback! 🚀
When Microsoft dropped GraphRAG I was beyond hyped: finally a proper way to build knowledge graphs with community detection and smart querying.
I waited for a .NET version… and waited… and waited some more.
It never came.
So I did it myself. From scratch. For .NET 10.
Full async, DI, strongly-typed config, Microsoft.Extensions.AI integration, and swappable graph backends:
→ Neo4j
→ PostgreSQL Apache AGE
→ Azure Cosmos DB
→ JanusGraph
Full indexing pipeline is there: chunking with overlap, entity/relationship extraction, fast label propagation for communities, summarization a few extras I couldn’t resist (semantic dedup, orphan node linking, relationship enhancement).
Tested with real DBs via Testcontainers, works great on my datasets… but I’m just one person.
Now it’s your turn: break it, improve it, tell me what sucks
Repo (MIT): github.com/managedcode/graph…
Issues, ideas, PRs — all welcome. I built this for the community, your feedback means the world.
#GraphRAG #DotNet #AI #KnowledgeGraph #OpenSource #RAG #Neo4j #CosmosDB #MicrosoftAI #csharp
3
3
272

26 Nov 2025
NoSQL Database Selection in Backend
✓ Introduction
→ Choosing the right NoSQL database is critical for building scalable, flexible backend systems.
→ NoSQL databases excel where traditional SQL fails—handling unstructured data, massive scale, or extremely high read/write throughput.
✓ 1. When to Choose NoSQL
→ When your data is unstructured or semi-structured
→ When you need horizontal scalability across many servers
→ When your application requires very high performance at scale
→ When strict relational schemas slow down development
✓ 2. NoSQL Database Types & When to Use Them
✓ Document Databases (MongoDB, CouchDB)
→ Ideal for JSON-like documents
→ Flexible schema—easy to evolve your app
→ Great for content management systems, user profiles, product catalogs
✓ Key-Value Stores (Redis, DynamoDB)
→ Extremely fast read/write operations
→ Perfect for caching, session management, leaderboards
→ Use when your data is simple and lookup is key-based
✓ Column-Family Stores (Cassandra, HBase)
→ Built for massive write loads and high availability
→ Best for analytics, event logs, IoT streams
→ Scales horizontally with ease
✓ Graph Databases (Neo4j, JanusGraph)
→ Designed for relationship-heavy data
→ Ideal for social networks, recommendation systems, fraud detection
✓ 3. Key Factors for Selecting a NoSQL Database
→ Data structure: documents, key-values, graphs, or wide-columns
→ Scalability needs: vertical or horizontal scaling
→ Query patterns: simple lookups, graph traversal, aggregations
→ Consistency vs availability (based on CAP theorem)
→ Ecosystem & integrations (ORMs, drivers, tools)
→ Performance requirements for reads/writes
→ Operational complexity and maintenance costs
✓ 4. NoSQL Strengths
→ High horizontal scalability
→ Flexible schemas
→ High availability in distributed environments
→ Optimized for large-scale data handling
✓ 5. NoSQL Limitations
→ Weaker consistency in some systems
→ Limited complex querying compared to SQL
→ Harder to enforce relational constraints
→ Learning curve for teams used to SQL
→ Grab the Backend Development with Projects Ebook to learn how to choose, design, and integrate NoSQL databases in real backend systems.
🔗 codewithdhanian.gumroad.com/…

14
32
252
10,206

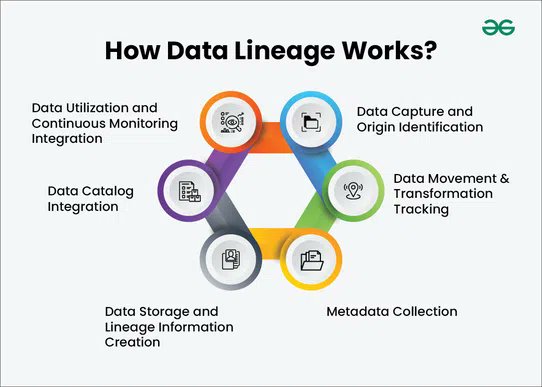
Secure Data Lineage Tracking Systems using Java
One topic that keeps coming up in audits and design rounds is data lineage.
Most folks say “we log everything.” Not enough.
You need to first understand what data lineage really means.
It’s a map of where data came from, how it transformed, and where it went. Every hop. Every change. Verifiable.
It helps with
→ Regulatory proofs and faster audits
→ Impact analysis before a risky change
→ Trust in dashboards, ML features, and reports
It runs on clear policies. Provenance capture. Versioned schemas. Timestamps that actually matter.
Using Java, teams build lineage by instrumenting Spring Boot services with interceptors, publishing events to Kafka, storing provenance in Neo4j or JanusGraph, querying with Gremlinor Cypher, and indexing summaries in Elasticsearch. Serialize with Avro/Protobuf. Sign events using JCA. Expose read APIs via gRPC or REST.
Responsibilities of a Lineage Platform
→ Capture column-level lineage at source and transform steps
→ Preserve immutable trails with cryptographic checks
→ Provide fast “where-from” and “where-to” queries for ops and compliance
Keep these in view and you can explain lineage like a pro. Simple words. Sharp edges.
➕ Follow me, @kisalay_Cool95 , for Tech, AI & Career Insights
♻️Reshare to help others take action.
2
6
452

22 Oct 2025
Yeah, I agree! 💯
MongoDB is great, but there are some better ones. Here’s a short list off the top of my mind:
MySQL
PostgreSQL
MariaDB
Oracle Database
Microsoft SQL Server
IBM Db2
SQLite
Amazon Aurora
Google Cloud SQL
CockroachDB
YugabyteDB
TiDB
OceanBase
SingleStore
Altibase
NuoDB
InterBase
Firebird
SAP HANA
SAP ASE
Informix
Teradata
Greenplum
Vertica
Exasol
Snowflake
Redshift
BigQuery
DuckDB
H2
Apache Derby
Apache Ignite
VoltDB
Redis
Aerospike
Riak KV
DynamoDB
FoundationDB
Tarantool
Berkeley DB
RocksDB
LevelDB
BadgerDB
LMDB
Kyoto Cabinet
HyperLevelDB
WiredTiger
EventStoreDB
Apache Cassandra
ScyllaDB
HBase
Google Bigtable
Azure Cosmos DB
Hypertable
Accumulo
CouchDB
Couchbase
RethinkDB
RavenDB
ArangoDB
OrientDB
MarkLogic
BaseX
eXist-db
ZODB
Neo4j
JanusGraph
TigerGraph
Dgraph
Amazon Neptune
Blazegraph
AllegroGraph
AnzoGraph
Faunus
InfiniteGraph
InfluxDB
TimescaleDB
QuestDB
OpenTSDB
Prometheus
VictoriaMetrics
Graphite
Kdb
Apache IoTDB
DalmatinerDB
RRDtool
M3DB
TDengine
Elasticsearch
OpenSearch
Solr
Splunk
Rockset
ClickHouse
Apache Druid
Apache Pinot
Apache Kylin
Memcached
Hazelcast
Oracle TimesTen
TIBCO ActiveSpaces
HSQLDB
Realm
LiteDB
TinyDB
NeDB
ObjectBox
PouchDB
IndexedDB
LocalStorage
Google Firestore
Google Cloud Spanner
CockroachDB Cloud
Yugabyte Cloud
Neon
PlanetScale
AlloyDB
MarkLogic
FoundationDB
Datastax Enterprise
db4o
ObjectDB
GemStone/S
Versant Object Database
PostGIS
SpatiaLite
Oracle Spatial
GeoMesa
GeoWave
MonetDB
CrateDB
Apache Hudi
Apache Iceberg
Delta Lake
Datomic
Firebase Realtime Database
GridDB
Machbase
TileDB
2
196

16 Jul 2025
Remember implementing a visual graph using react- force-graph to navigate through JanusGraph.
Fun project as it came out to be pretty neat and useful.
1
2
67

5 Jun 2025
🚀 Stop cramming relationships into rigid SQL tables.
Graph DBs like Neo4j & JanusGraph model relationships natively—and Java with Eclipse JNoSQL makes it easy.
▶️ youtu.be/ncyhWCYkpmE
@JakartaEE
#Java #GraphDatabase #Neo4j #JanusGraph #DDD
1
2
442

23 Apr 2025
I got a $200k raise at Netflix in 2019 for building a less scalable system!
I inherited a graph database built on top of JanusGraph.
They picked JanusGraph because the stakeholders said they needed the graph to scale to billions.
JanusGraph was painful because:
- Loading data between Spark and Cassandra is painful, error prone, and
- reindexing when deletes happened was painful
- maintaining it among a team of data engineers was next-to-impossible.
I noticed of all the entities in the database, only one had a billion cardinality (IP addresses). The rest were in the single digit millions!
Pushing back on stakeholders here allowed us to uncover that the IP address use case wasn’t actually that valuable!
This pointed to moving to a simpler system!
Removing IP addresses and migrating to Postgres allowed the data team to move 5 times faster and finish building the graph way ahead of schedule!
Adding Apache AGE allowed for a full graph query structure while benefiting from the value Postgres brings!
Postgres doesn’t scale to billions of nodes. But the use cases here weren’t on that scale!
The lesson here is:
- constraints make your systems powerful
- shooting for the moon isn’t always the best approach!
2
4
127
7,541

2 Mar 2025
Check out ArangoDB or JanusGraph! They both have some cool features and can be great alternatives. Happy exploring!
2
62

4 Feb 2025
Revolutionize your AI projects with JanusGraph and Azure Managed Instance for Apache Cassandra! ✨ Scale effortlessly, enhance performance, and unlock new possibilities for large-scale AI. Dive into the future of AI with this powerful combo! 💥 msft.it/6017UrR8R

ALT spot art. text reads: JanusGraph and Azure Manage Instance for Apache Cassandra. Unlock the power of distributed graph databases.
3
302

1 Feb 2025
📊 Scale your graph database workloads with ease! Learn how JanusGraph and Azure Managed Instance for Apache Cassandra provide unmatched performance for AI and data analytics.
🚀 Explore now: devblogs.microsoft.com/cosmo…
7
7
460
31 Jan 2025
🌐 Supercharge your AI and graph analytics with JanusGraph and Azure Managed Apache Cassandra. Achieve seamless scalability, flexibility, and performance for mission-critical workloads.
📚 Start here: devblogs.microsoft.com/cosmo…
4
6
355
30 Jan 2025
💡 Enhance your AI-powered applications with the robust combination of JanusGraph and Azure Managed Instance for Apache Cassandra. Learn how this solution drives scalability & performance.
📘 Details: devblogs.microsoft.com/cosmo…
1
3
426
29 Jan 2025
🔍 Looking for scalable graph database solutions? Discover how JanusGraph with Azure Managed Apache Cassandra enables large-scale AI applications, ensuring high availability and low latency.
📖 Learn more: devblogs.microsoft.com/cosmo…
3
7
530
24 Jan 2025
🚀 Unlock the power of JanusGraph Azure Managed Instance for Apache #Cassandra for scalable, high-performance graph database solutions. Perfect for AI-driven applications needing speed and reliability.
🔗 Read more: devblogs.microsoft.com/cosmo…
2
4
352

15 Jan 2025
We announce the release of ExRam.Gremlinq 12.13.0!
ExRam.Gremlinq is the first .NET object-graph-mapper for @apachetinkerpop enabled graph-databases like @dotnetonAWS Neptune, @AzureCosmosDB and @JanusGraph.
github.com/Gremlinq/ExRam.Gr…
2
3
312

2 Jan 2025
some thoughts on creating a dynamic, open/crowd-sourced, interactive database hypergraph of the chaotic, adaptive, personal, interconnected nature of memes and how they transform and shift across time, platform, and community:
> scrape foundational databases like knowyourmeme and memedroid for structured, vetted meme data
> recognize these databases are incomplete and miss evolutions, variations, subtle labeling
> integrate with meme generator APIs to capture memes at the point of creation
> maybe github[dot]com /topics /memes-api can help
> more advanced: scrape platforms like reddit, 4chan, twitter/x, tiktok, and instagram for real-time and grassroots meme activity; use reverse image search to identify duplicates or near-duplicates across platforms; implement OCR to extract text from meme images, enhancing searchability and analysis
> connect with og/influential meme makers for input
> opensource crowdsourcing is essential to fill gaps in scraped data, capturing obscure and hyper-niche memes
> build a user-friendly portal for meme submissions, allowing metadata, stories, and contextual details to be included
> metadata should include origin (platform, time, location), perceived impact, and personal context where applicable
> expand metadata with tags for social, political, or cultural events and sentiment analysis to understand resonance
> create a meme popularity index to track metrics like sharing frequency, platform presence, and lifespan
> allow users to tag memes with personal anecdotes to capture their unique significance or emotional impact
> personal anecdotes are essential not just for their emotional resonance but as first-person "case studies" showing memes as lived experiences, bridging abstract data and cultural impact
> emphasize the inherent observer-dependent and relational nature of meme meanings
> no meme has a single fixed meaning; meanings evolve and adapt based on context and perception
> memes are cultural Rorschach tests—what they mean is as much about the observer as the artifact itself, highlighting their role as flexible, creative vessels for cultural exchange
> denotative labeling (visual elements, text content, categories) is foundational and automatable
> use computer vision to identify visual templates or formats, linking memes sharing visual DNA
> templates like Distracted Boyfriend or Drake Hotline Bling are conceptual gateways, acting as scaffolding for idea exchange and connecting disparate cultural contexts through shared formats
> connotation is the challenging, subjective core and the most valuable layer for creative and cultural insight
> crowdsourcing connotative labels enables capturing multi-dimensional interpretations from diverse perspectives
> contradictory or multi-layered meanings reveal cultural tensions, where the same meme can resonate positively with one group and negatively with another—embracing these paradoxes reflects the full complexity of meme culture
> balance structured inputs (dropdowns, predefined tags) with freeform descriptions for nuanced meaning capture
> allow for natural language labeling and use LLMs to analyze freeform inputs, cluster insights, and surface recurring themes
> step one is comprehensive labeling of individual memes across denotative and connotative dimensions
> step two involves mapping meme relationships, with a focus on connotation-driven links
> visual templates can define relationships, e.g., meme families like Distracted Boyfriend or Drake Hotline Bling
> text network graphs can map linguistic connections in memes (copypasta, captions) via co-occurrence patterns
> treat textual graphs as hypernodes, bridging memes through shared linguistic and conceptual frameworks
> textual graphs also facilitate cross-modal connections, showing how ideas evolve across different formats (e.g., from text to image)
> provenance tracking ("receipts") is critical to establish and update meme origins
> record first known appearance (platform, time, date) and source URLs for traceability
> use blockchain to create immutable records for meme provenance and ownership
> blockchain ensures cultural records resist censorship and misattribution, treating memes with archival rigor akin to traditional art
> allow users to submit updates when new origins or earlier examples emerge
> dynamic metadata updates are crucial, as metadata itself evolves over time to reflect new meanings, connections, or contexts attached to a meme
> build an interactive 3D hypergraph to represent memes as nodes and their relationships as edges
> connections should reflect visual, textual, thematic, and cultural dimensions of meme interrelations
> use tools like three.js, d3.js, or unity for creating scalable, immersive graph interfaces
> enable filtering by dimensions such as denotation (visual/textual similarity), connotation (themes/emotions), or provenance (timeline/context)
> meme relationships must be multi-dimensional, capturing not just thematic links but also temporal, emotional, and communal contexts to show how memes spread across subcultures and time periods
> store data in a graph database like neo4j or janusgraph for efficient handling of nodes, edges, and properties
> nodes should include metadata like denotative and connotative labels, timestamps, and links to related nodes
> edges define relationships, such as “evolved from,” “inspired by,” “shares template,” or “cultural overlap”
> validation is essential for crowdsourced contributions to ensure data quality and integrity
> implement a voting or reputation system to let the community validate or challenge submissions
> use wiki/community note-styled and ai moderation to flag spam, irrelevant inputs, or potential copyright issues
> develop gamified incentives (badges, leaderboards, rewards) to encourage high-quality contributions
> applications for the database include cultural analysis, academic research, AI training, and meme trend forecasting
> use propagation analysis to predict new meme formats or themes emerging from current events or cultural shifts
> memes influence cultural narratives, e.g., shaping political movements or reframing social events; tracking these feedback loops reveals memes as active agents in culture, not just reflections of it
> develop a meme remix tool allowing users to generate, edit, and contribute meme variations within the platform
> offer a meme trend dashboard or newsletter to inform users about emerging and evolving meme dynamics
who's building this? who wants to build this?
tag a builder, thinker, memer and/or add your thoughts.
2 Jan 2025

tracking and connecting the history, development, and meaning of memes (text, image, abstract) is conceptually technically challenging but would be an incredible resource for understanding how ideas evolve, transform, and spread through culture
3
2
10
5,953
30 Oct 2024
We announce the release of ExRam.Gremlinq 12.10.3!
ExRam.Gremlinq is the first .NET object-graph-mapper for @apachetinkerpop enabled graph-databases like @dotnetonAWS Neptune, @AzureCosmosDB and @JanusGraph.
github.com/Gremlinq/ExRam.Gr…
2
3
126
23 Jul 2024
Announcing the release of ExRam.Gremlinq 12.7.2!
ExRam.Gremlinq is the first #dotnet object-graph-mapper for @apachetinkerpop #gremlin enabled #graphdbs like @AzureCosmosDB, @dotnetonAWS Neptune or @JanusGraph.
github.com/Gremlinq/ExRam.Gr…
2
2
66

16 Jun 2024
Based on the information provided, it seems that GaiaNet is not explicitly mentioned as using databases like Neo4j and JanusGraph. However, The Graph, which is listed under Base Network Data Indexers, uses GraphQL to query open APIs called subgraphs, ind…
1
25