

Jun 6
三、熵压指数(EPI)—— 阈值重校版
EPI定义: 度量文明基本协议被替代的程度。新阈值: 低[0-0.2) 中[0.2-0.4) 高[0.4-0.6) 极高[0.6-1.0]
熵压来源 权重 当前强度(0-1) 加权值 证据等级
规则碎片化(Rule Fragmentation) 40% 0.32 0.128 B
协调成本上升(Coordination Cost) 35% 0.28 0.098 B/D
制度替代率(Institutional Substitution) 25% 0.22 0.055 B
EPI 0.281 中熵压区间(0.2-0.4)
今日EPI=0.28(较昨日 0.03),连续第8日处于中熵压区间。尚未进入高熵压区,表明协议替换仍在进行中,而非完成态。
三大协议替换案例:
领域 旧协议 新协议 可逆性 EPI贡献
能源通道 商业航道 战略前线 暂不可逆 0.11
人才流动 知识无国界 安全审查 暂不可逆 0.08
技术前沿 商业驱动 国家竞赛 暂不可逆 0.10
---
📈 四、文明适应指数(CAI)—— 子指标结构化
子指数 权重 评分(0-10) 加权值 证据等级 核心指标
CAI-E(能源) 25% 6.5 1.625 B 欧盟LNG接收站建成率92%[B]
CAI-H(医疗) 25% 7.0 1.750 B mRNA本地化生产国17个[B]
CAI-T(技术替代) 25% 5.8 1.450 B/C 韩国AI公务员覆盖率89%[C];日本AI照护员认证[C]
CAI-S(社会信任) 25% 5.0 1.250 B OECD信心均值58.7%[B]
CAI 6.075≈6.1
文明韧性: CAI/CRI = 6.1/9.4 ≈ 0.65(低中韧性,高风险-中低适应)
---
🔍 五、校准与反证模块(Calibration Layer)
主假设: 全球文明正加速固化于「高成本安全化稳态」(HCSSteady State)。
可证伪信号(任一出现则假设削弱):
信号 观测指标 阈值 证据等级要求
A.技术开放回流 AI联合审计机制 或 芯片出口限制逆转≥30% 两项中任一 B
B.贸易效率复苏 WTO争端解决重启≥3案 或 FDI连续两季度 5% 两项中任一 A/B
C.人口韧性突破 日/韩/意生育率回升至1.3 或 AI劳动生产率 4.2% 两项中任一 A
---
📜 六、历史回测与模型校准(新增V1.2)
目的: 回答“去年模型说了什么?后来发生了什么?错在哪里?”——这是智库公信力的核心。
回测窗口:2025年6月 → 2026年6月(模拟,基于真实趋势)
预测/诊断(2025年6月) 实际结果(2026年6月) 校准结论
霍尔木兹海峡风险将升级为军事对峙 伊朗发射无人机,美众议院通过战争决议,但未开战 部分正确:风险升级确认,但未达全面战争;权重维持25%
AI治理将进入国家主权化阶段 美国国防AI加速,Anthropic警告,G20取消议题 正确:V_tech权重从15%上调至20%
人口危机将触发技术替代政策 日本AI照护员认证、韩国AI公务员大规模覆盖 正确:V_demo权重维持10%
多边机制将持续衰退 G20取消AI议题,五眼联盟扩容 正确:V_inst权重维持20%
模型误差记录: 2025年预测“全球FDI将在2026Q1回升”,实际Q1同比-2.3%(WTO数据)。原因:低估了贸易安全化对资本流动的抑制。已在2026年权重调整中将V_trade从10%提至15%。
承诺: 每季度末发布正式回测报告,公开模型预测与现实的偏差及权重调整记录。
---
📅 七、明日(6月7日)关键监测接口
接口 变量 阈值 CRI影响 CAI影响 证据等级
霍尔木兹交火 V_geo 美伊直接军事接触 0.30 -0.15 C→A
中朝峰会声明 V_geo 提及“军事协作” 0.20 — B
俄乌元首对话 V_geo 确认直接沟通 -0.10 0.10 B
AI跨国响应 V_tech ≥3国响应暂停呼吁 -0.15 0.20 B
美国关税清单 V_trade 公布首批HS编码 0.25 -0.10 A/B
---
📜 八、编辑部终审意见(V1.2 Beta)
✅ 本版实现了终审要求的三大核心升级:
1. 证据分级(Evidence Layer) —— 每条关键数据标注A/B/C/D,来源透明,可追溯。
2. 熵压阈值重校 —— 采用低/中/高/极高四区间,EPI=0.28明确归入“中熵压”,避免辨识模糊。
3. 历史回测框架 —— 增加年度回测模块,记录模型误差与权重调整,迈向“可纠错”体系。
✅ 未新增概念,聚焦可验证性 —— 符合“V1.2不要继续增加概念”的要求。
✅ 核心命题保留: “安全内核化(Security Kernelization)”作为CSS Core Thesis No.1,已嵌入CRI/EPI/CAI全框架。
发布评级: Approve for Official Release
下一版本(V1.3)建议方向: 引入季度权重变更记录表、扩展CAI子指数至六维(Governance, Food Security),并实现EPI的月度回溯序列。
---
—
Civilization Security System(CSS) / Civilization Security Risk(CSR)编辑部
2026年6月6日 23:59 UTC 8
文明不因宏大叙事而延续,而赖于无数微小接口持续稳定地运行;
尤赖于,当安全成为默认协议时,人类仍保留重写协议的能力。
---
2
601

> * What are the biggest problems in Bitcoin today?
1) extreme scenarios of widespread Internet censorship
2) extreme scenarios of electricity censorship
3) lack of privacy, widespread KYC
3) asic production centralization
4) key control centralization
5) core repository centralization
6) node centralization
7) lack of good WoT and DID protocols for escrow and commerce
8) extreme scenario of widespread ban on free general purpose electronic
>* Do you have *any* solutions, for *any* of them?
1) mesh networks, competing satellite systems, off-line second layers
2) praying
3) second layers, education, government teaching retarded people by fucking them over
3) asic commodification, technological collapse
4) government fucking coinbases, etfs, treasuries and exchanges over
5) multiple competing implementations, consensus modularization/kernelization
6) possibly block size reductions, bandwidth improvement, validation speedups
7) development of good WoT and DID protocols for escrow and commerce
8) praying
> the one's that BIP110 is addressing
I think it's a very confused proposal, but I guess it could weakly overlap with points 5 and 6. It's likely failure will make 5 way worse, emboldening Core and pushing many critics to rage quit or shut up. Both it's likely failure or it's very unlikely success wouldn't affect 6 much.
6
5
22
2,312

21 Oct 2025
gm @turtledotxyz fam
that kernelization gives turtle immense leverage.
while most protocols depend on user deposits, turtle can integrate upstream (with treasuries, DAOs, vaults) and downstream (with lending, AMMs, yield optimizers).
it doesn’t compete for liquidity, it orchestrates it.
the key here is programmable liquidity, turtle treats capital as a composable asset class.
this unlocks modular liquidity routing, policy-based capital allocation, and self-adjusting strategies.
in simpler words: liquidity that manages itself.
#turtle’s deeper bet is that the next wave of defi won’t be about “APY wars”, it’ll be about efficiency wars.
protocols that can route, reuse, and recycle capital most effectively will dominate.
turtle’s architecture is built exactly for that.

33
1
29
327

🚀 The frontier of AI x DePIN is heating up fast.
@quranium_org is redefining compute access.
@KRNL_xyz is pushing the boundaries of AI kernelization.
All tied together with the power of @Galxe quests to onboard the next wave of users.
(And yes, keep an eye on @FractionAI_xyz they’re carving their own lane in the AI collective space 👀)
This isn’t just innovation, it’s a movement. 🌍✨
#AI #DePIN #Web3

50
1
39
147

KRNL Labs is building kOS, a modular operating system for Web3 smart contracts.
Here’s why it matters:
1. They target developer bottlenecks
Writing smart contracts is hard.
Cross-chain, data access, AI, and real-time features need backend plumbing.
KRNL turns these features into plug-and-play modules called kernels.
2. They're betting on middleware, not another L1
Most new projects launch yet another chain.
KRNL builds where the pain is: the dev stack between contract logic and infrastructure.
Their target isn’t users. It’s developers and protocols.
3. Kernels = Composable Execution Units
Think of kernels like reusable logic modules.
Developers build or borrow kernels for use in contracts.
Kernels live across chains. Execution is node-level. This gives faster performance.
4. They use Execution Sharding and Proof of Provenance
Execution happens inside enhanced Geth clients, using GraphQL.
No external calls. This reduces gas and attack surface.
PoP verifies that each kernel ran correctly before any chain writes.
5. Their moat is ecosystem lock-in
Developers register kernels, earn from reuse.
Over time, a network of kernels forms. Popular ones get reused.
This creates network effects. Hard to replicate.
6. Bridge strategy via cryptographic MPC
KRNL’s bridge doesn’t wrap tokens.
It uses MPC and NFT Chain Keys for fast, native swaps.
The bridge supports ECDSA, BLS, and EdDSA—all major sig schemes.
7. Strong founding team and backers
Founded by a Microsoft vet and a blockchain fund manager.
Backed by TRGC, Superscrypt, Blockchain Founders Fund.
Pre-seed round raised $1.7 million in late 2024.
8. Partnerships show direction
With Oasis: for confidential kernel execution via Token Authorities.
With QuillAI: for AI-based real-time transaction security.
With SIG Network: for instant, signature-compatible bridging.
9. Long-term bet on “Kernelization” of Web3
Instead of devs starting from scratch, KRNL wants code to be modular and marketable.
The more complex Web3 gets, the more this matters.
----------------------------------------------------
@KRNL_xyz isn’t another chain or DeFi app. It’s a bet on middleware that makes smart contracts smarter, faster, and safer. Their success depends on one thing: will developers adopt kernels the way Web2 devs adopted APIs?
If they do, KRNL becomes Web3’s modular backend.
Follow @exSatNetwork @blueprintai @multibank_io

8
1
12
190

The IBS discrete mathematics group welcomes Dr. Roohani Sharma, a new research fellow at the IBS Discrete Mathematics Group from May 1, 2025.She is interested in parameterized complexity and kernelization.
dimag.ibs.re.kr/2025/welcome…

2
3
845

14 Mar 2025
TVK plays spoil sport in BJP's chances of winning in Tamil Nadu. FPTP assumption.
@sreeramjvc @annamalai_k
No naive Bayes condition was assumed.
@TruthAlone2 @SaffronDalit
Hyper parameter tuning & kernelization can be used to predict accurately, allowing for thick tail.

2
64

5 Mar 2025
A unified kernelization approach for Linear Layout of Graphs problems, parameterized by vertex cover number τ, partitions vertices into subsets for efficient reduction. It yields a 2^O(τ)-sized kernel for Mixed s-Stack q-Queue Layout, improving prior results.

1
14
330,031

22 Oct 2024
A Kernelization-Based Approach to Nonparametric Binary Choice Models. arxiv.org/abs/2410.15734
2
101

5 Jun 2024
DAY 21:
1. Got to know more about kernelization and how the math works around it.
2. Tried to code it out but failed miserably, I probably over complicated the code because of all the math I had studied before. Gonna give it another shot tomorrow.
Ight peace out!!!
4
110

3 Apr 2024
DiJiang: A Groundbreaking Frequency Domain Kernelization Method Designed to Address the Computational Inefficiencies Inherent in Traditional Transformer Models
Quick read: marktechpost.com/2024/04/03/…
Paper: arxiv.org/abs/2403.19928
Github: github.com/YuchuanTian/DiJia…
4
17
414

[CL] DiJiang: Efficient Large Language Models through Compact Kernelization
arxiv.org/abs/2403.19928
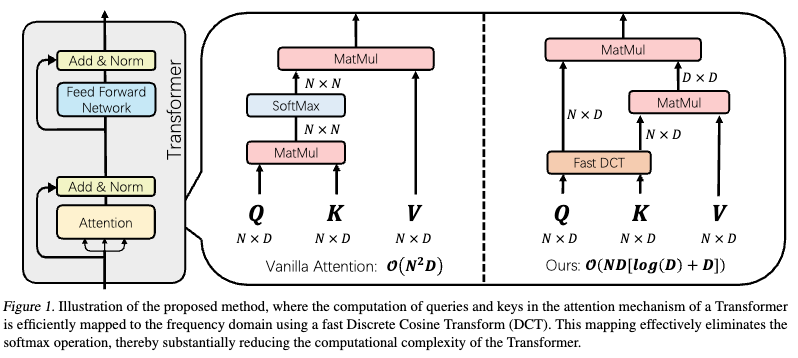
- This paper presents DiJiang, a novel Frequency Domain Kernelization approach that efficiently transforms a pre-trained vanilla Transformer into a linear complexity model with little training cost.
- DiJiang employs weighted Quasi-Monte Carlo sampling to map the queries and keys to the frequency domain using Discrete Cosine Transform (DCT). This eliminates the softmax operation and reduces complexity from quadratic to linear.
- Theoretical analysis shows weighted Quasi-Monte Carlo offers superior approximation efficiency compared to traditional Monte Carlo sampling used in existing methods.
- Extensive experiments demonstrate DiJiang achieves comparable performance to the original Transformer but with significantly lower training cost and faster inference.
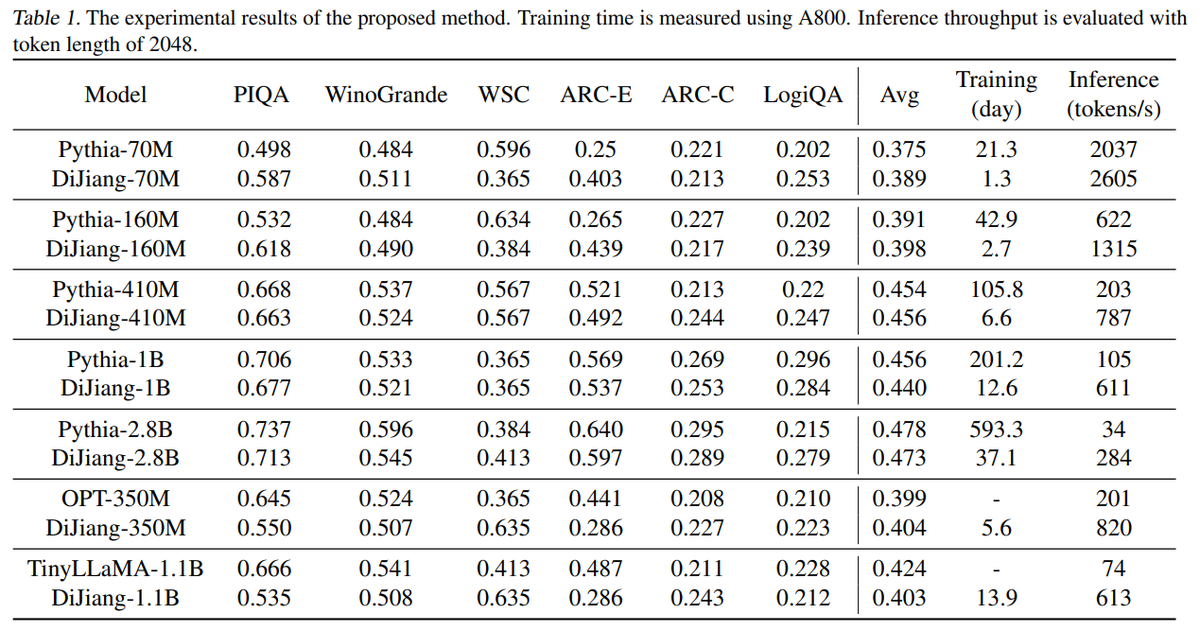
- On six NLP datasets, DiJiang models of varying scale from 70M to 2.8B parameters perform on par with original Pythia models but with only 1/16 to 1/50 the training cost.
- DiJiang-7B attains similar results as LLaMA-7B on benchmarks but requires only about 1/50 the training resources.

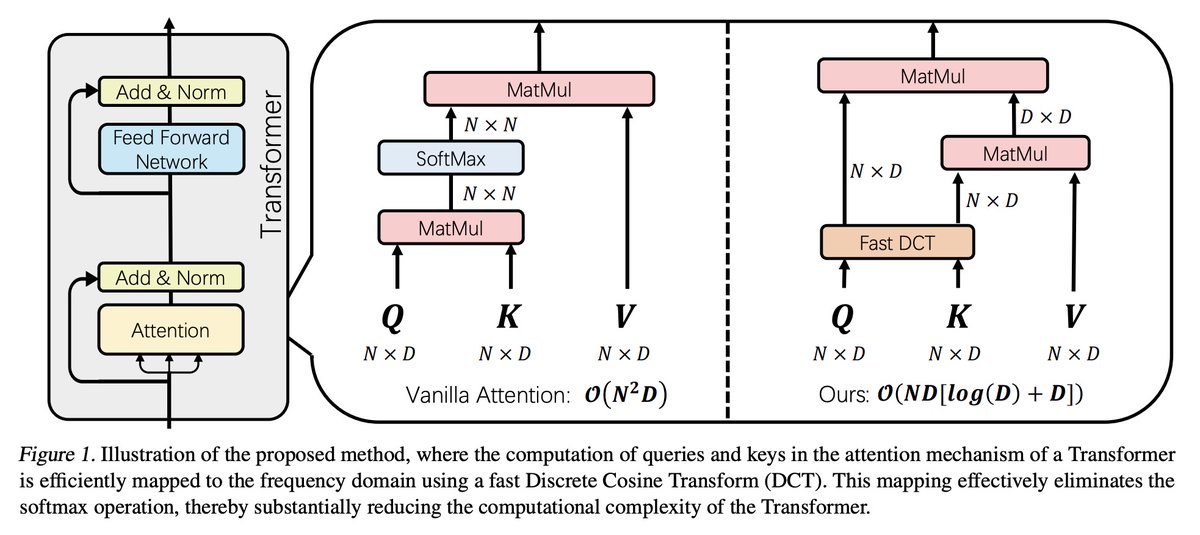
18
51
3,813

> take LLaMA-2-7B
> Frequency Domain Kernelization magic!
> finetune on 40B tokens
> MMLU crashes to 40% from 47%
> "achieves comparable performance with LLaMA2-7B on various benchmark while requires only about 1/50 training cost"
> "our model required only 40B training data, significantly less than the 2T tokens used by LLaMA2-7B"
🤯🤯🤯
I'm angery
1
25
1,766

1 Apr 2024
オリジナルの Attention を近似することが理論的に保証された、カーネル法を用いた新しい線形 Attention の仕組みと、その計算を DCT (離散コサイン変換)を用いてさらに高速化する仕組みを導入した LLM(の変換方法というべき?)、 DiJiang の提案。既存モデルを追加学習を通じて DiJiang へ変換でき、メモリ効率を格段に改善可能。
以前から知られていた通り、Attention の計算中の exp(qk^T) 部分を、特徴量マッピング φ により"線形化"し φ(q)φ(k)^T と表すように置換すると、Attention のオーダーが 1 つ下がって計算が効率化される。
DiJiang では、Gaussian Kernel に対する Random Fourier Features (RFF)に由来する効率的な特徴変換 PFF (Positive Fixed Features)に学習可能なパラメータを加えた WPFF (Weighted PFF) を用いて線形 Attention を効率的に近似する(この計算の効率化にDCTをつかう)。PFF は RFF に由来するため平均的にオリジナルの Attention を近似することが理論的に保証でき、WPFF はそこに学習可能なパラメータを加えることで精度向上も期待できるという仕組み。
自分が読めていないせいかも知れないですが、LLaMA2 の1/50のコストで学習できたと書いてありつつも、どうやら、追加学習で DiJiang 式に変換するのに要したデータ量が LLaMA2 の 1/50 で済んだという話っぽく、誤解を招くきそうな気もしましたが、理論保証された話で面白かったです。
(読み間違えていたらすみません)
"DiJiang: Efficient Large Language Models through Compact Kernelization"
arxiv.org/abs/2403.19928
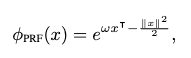

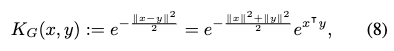
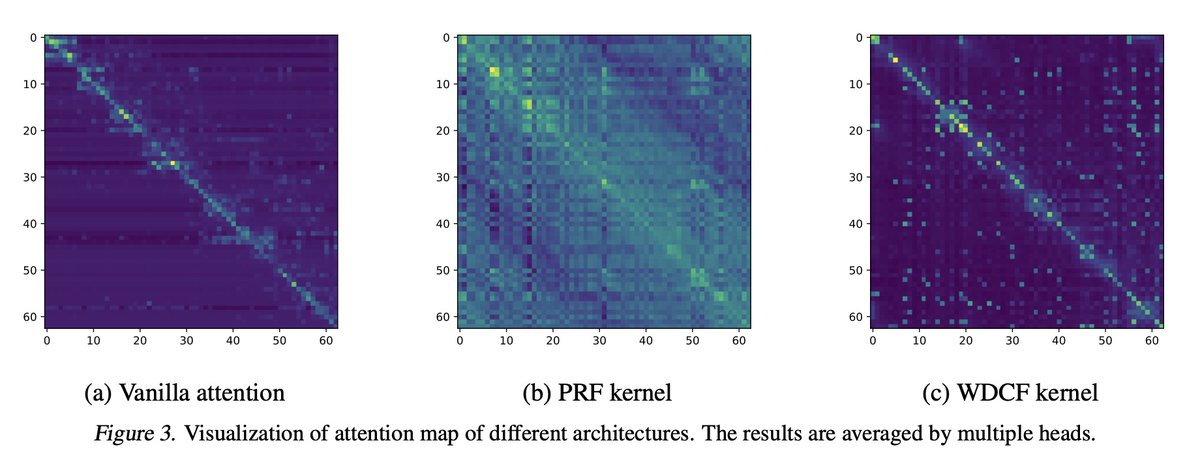
2
34
223
27,730

DiJiang
Efficient Large Language Models through Compact Kernelization
In an effort to reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically

2
13
65
20,753

1 Apr 2024
Huawei presents DiJiang: Efficient Large Language Models through Compact Kernelization
Achieves comparable performance with LLaMA2-7B on various benchmark while requiring only about 1/50 pretraining cost
arxiv.org/abs/2403.19928
3
35
132
21,608

25 Jan 2024
The pronunciation of colonel makes it seem like colonization should be pronounced kernelization
3
57