

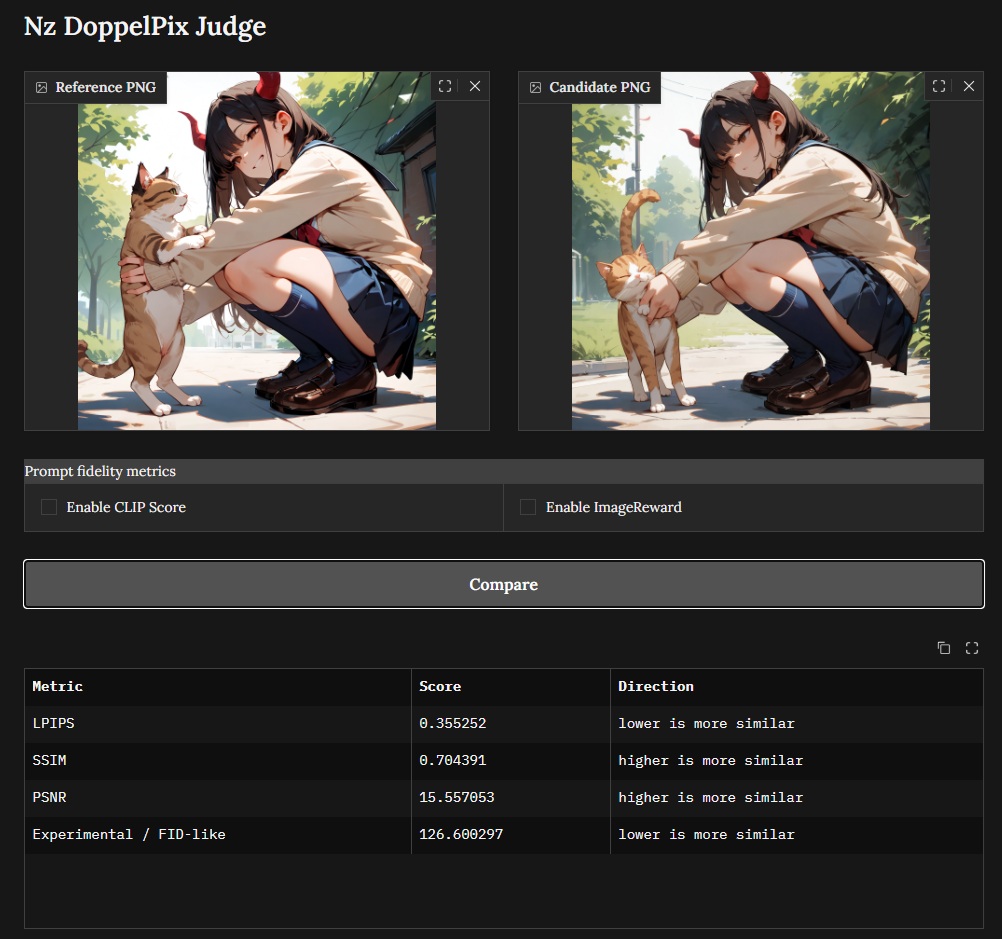
... CLIPScore und PickScore für Prompt-Treue sowie referenzbasierten wie Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity (SSIM) und Learned Perceptual Image Patch Similarity (LPIPS). 2/4
1
1
65

Jun 14
Apple publicó SHARP: subes una foto y en menos de 1 segundo te devuelve una escena 3D navegable. Redujo LPIPS 25-34% y DISTS 21-43% frente al mejor modelo anterior. Es el paper código abierto de Apple. github.com/apple/ml-sharp
49

Jun 13
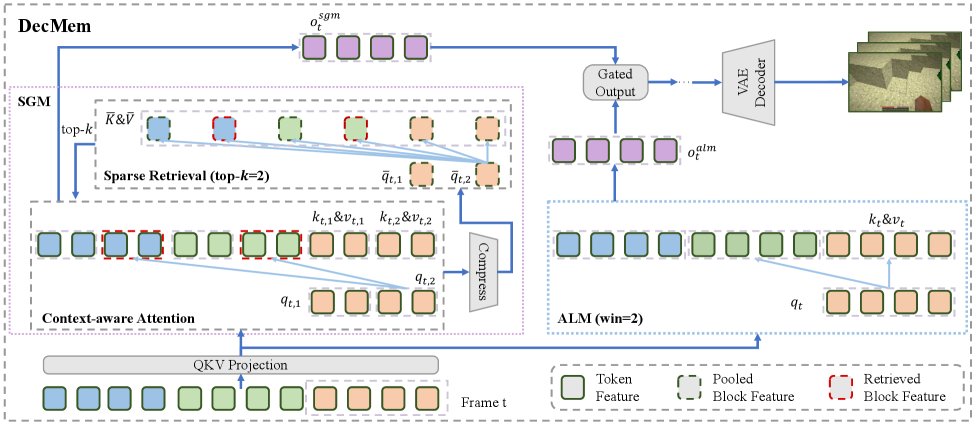
「Minecraftで1分以上探索しても、さっき通り過ぎた場所の見た目が崩れない」を実現したDecMem(https://arxiv[.]org/abs/2605.31336)。Kuaishouのkling teamによる、動画生成AIの長期記憶問題に正面から向き合った研究。
問題の根は「Attention Dispersion(注意の分散)」にある。動画生成が続くほど、関係のない過去トークンが少しずつattention weightを奪い続け、肝心な場面への注意が薄れていく。付録で定量分析すると、「重要でないトークンの割合」が推論中に単調増加し「重要なトークンの割合」が単調減少することが確認されている。遠いトークンを機械的に下げるtraining-free decayは短期品質を多少改善するが、長距離の記憶を切り捨てる副作用があり根本解決にならない。
DecMemはメモリを2系統に分離することで解決する。
Sparse Global Memory(SGM)は、過去の全フレームをブロック単位に分割・集約し、今のシーンと関連する上位80ブロックだけをスパース(まばら)に取得してから精細なattentionを行う。全履歴に均等に注意を向けるdense attentionと異なり、「探す→絞る→精読する」設計なので、生成が長くなっても計算コストがほぼ一定に保たれる。
Anchored Local Memory(ALM)は直近8フレームのスライドウィンドウに絞り、attention分布の錨として機能する。アブレーション実験では、ALMを外すと600フレーム超えで高周波ディテールが消えてシーン構造が崩壊し、FIDとLPIPS両方でdense attentionより悪化することが確認されている。
2つを学習可能なゲートで融合し、「以前訪れた場所の記憶(SGM)」と「今この瞬間の安定性(ALM)」を両立させる。
1Bパラメータのモデルを2段階で計50Kステップ・7日間学習。Oasis・MineWorld・WorldMemを複数指標で上回り、推論速度は最有力ベースラインの約2倍。産業規模モデルのMatrix-Game 2.0・WorldPlayと比べても視覚品質・操作性は同水準で、長期空間整合性は 5.14%上回る。
「遠くを見渡しながら足元を忘れない」設計が、ゲームAIの世界シミュレーションを1分スケールに押し上げた。
1
6
40
3,240

Jun 10
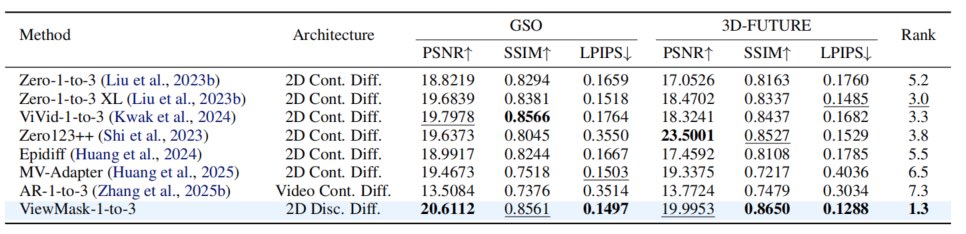
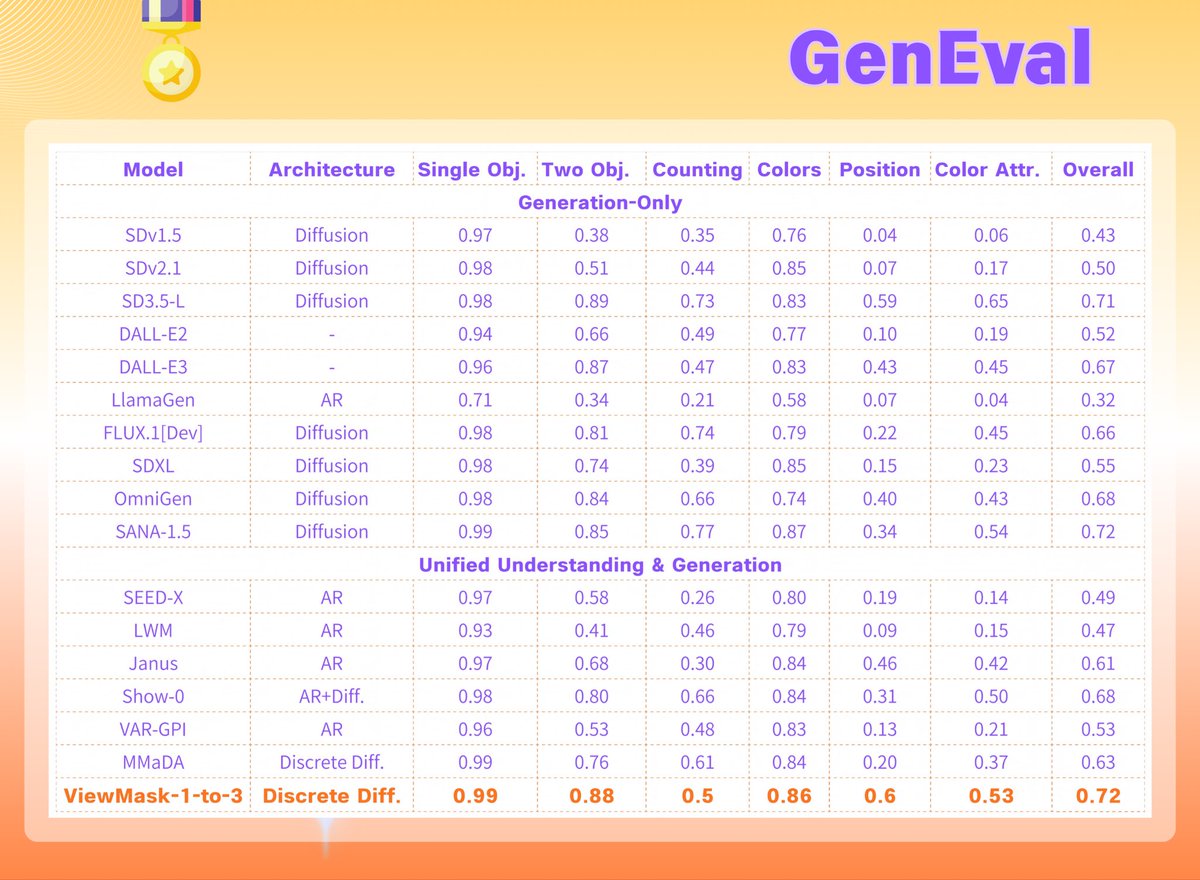
ViewMask-1-to-3 outperforms the baseline on both GSO and 3D-FUTURE:
🏆#1 average ranking across image-level metrics (PSNR, SSIM, LPIPS, CD, IoU)
🏆Up to 10.6% IoU higher on 3D-FUTURE than continuous diffusion models
🏆Ranked top tier on GenEval
2
1
34

If we assume that ALL textures had zeroed-out metallic channel, the results would look something like this:
SSIM:
BC7ENC: 0.93925
MY ENC: 0.93565
RMSE:
BC7ENC: 5.1213
MY ENC: 5.3502
LPIPS:
BC7ENC: 0.05145
MY ENC: 0.0456
93
And if I use 6x6 principal axis, it loses even on LPIPS. I guess 6x6 PA degrades small detail too much.
Also, note that most textures have a completely black metallic channel, so results are slightly skewed.
1
1
164
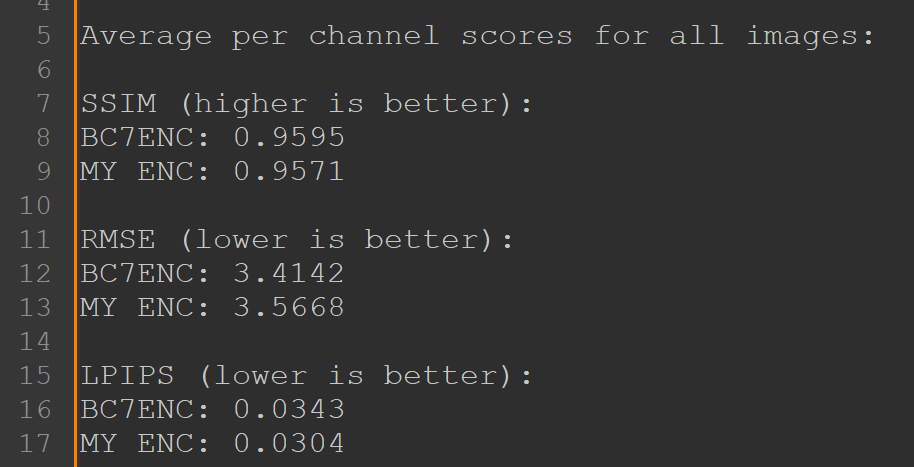
Downloaded 763 1k ARM textures from polyhaven and tested b7enc and my encoder (with 4x4 principal axis) using SSIM, RMSE and LPIPS
I used L5 bc7enc mode as L18 is too slow and L5 seems to be closer to my encoder under the hood
So my encoder seems to score better only on LPIPS...
2
1
217
Jun 5
ポーズ列から最大90秒のヒューマンアニメーションを生成する「EverAnimate」が発表された(https://arxiv[.]org/html/2605.15042v1)。
チャンク分割で動画を継ぎ足す既存手法には2種類のドリフト問題がある。まず背景劣化。チャンクをまたぐたびにVAE(映像を圧縮・復元するエンコーダー)でデコード→再エンコードを繰り返すと、動きのない静止背景ですら徐々に壊れていく。次にアイデンティティ崩れ。「参照フレームをアテンション(注意機構)で見続ける」対策(アテンションシンク)を施しても防ぎきれない。トークンは正しく参照フレームを見ているのに崩れるのだ。注意機構は「何を保持すべきか」を示すだけで、ズレた生成軌道を能動的に修正する力を持たないからだ。
EverAnimateはこれを2つの機構で解く。まずPLP(Persistent Latent Propagation)。デコードせず潜在空間のまま短期モーション記憶と長期アイデンティティ記憶を次チャンクへ引き継ぐ設計で、VAEのラウンドトリップによる劣化源を根本から排除。次にRFM(Restorative Flow Matching)。学習中に生成軌道を意図的にズラして「クリーンな経路へ引き戻す速度補正」を同時に学習させる。推論時に自己修正能力を内包する。
Wan-Animateとの比較では10秒でPSNR/SSIM 8%/ 7%、LPIPS/FID -22%/-11%。90秒ではPSNR/SSIM 15%/ 15%、LPIPS/FID -32%/-27%まで差が拡大し、長尺になるほど効果が増す設計。LoRAのみの軽量後付けで既存モデルへの適用も可能。

2
305

Jun 3
DC-AEf32c32-sana1.0
PSNR: 30.39 ± 4.975
SSIM: 0.9257 ± 0.06203
LPIPS: 0.06597 ± 0.02762
rFID: 1.375
自前f64AE(GAN使用前)
PSNR: 33.29 ± 4.320
SSIM: 0.9580 ± 0.04404
LPIPS: 0.04114 ± 0.02243
rFID: 2.365
少なくとも再構成性能では明確にDC-AEよりは上になった(目視でも明らかに違う)
3
198
TeaCacheとSpectrumのそれぞれの「絵柄の変化の大きさ」を測ってみた。
LPIPSとSSIM(※人間の視覚にわりと近い指標)ではTeaCacheのほうが好成績なのに、PSNR(※同じ位置のピクセルがどれだけ近い色で塗られているかの指標)では、Spectrumのほうが好成績!
お、面白い…!!


TeaCacheとSpectrumは、どちらも「一部のステップでの重いDiT演算をスキップし、軽い計算で近似する」という推論高速化技術。全32step中、それぞれ11stepをスキップした結果が次の通り。
1. 通常生成 41秒
2. TeaCache 27秒
3. Spectrum 26秒
TeaCacheのほうが「絵柄の変化」はずっと少ない。



1
5
14
6,034

May 26
arxiv.org/pdf/2605.05148
評価関数。色んな手法を混ぜ込んで機械学習してるの面白い。
D = MSE(x, ˆx) w1 LPIPS(x, ˆx) w2 MS-SSIM(x, ˆx)
w3 TilingArtifactLoss(x, ˆx) w4 TextFidelityLoss(x, ˆx, m) w5 GAN(x, ˆx, m)

JPEG 的な知覚上目立たない情報を捨てる圧縮の延長ではあるが仕組みは違うなあと。単にデータを間引く圧縮というより人間が自然に感じる復元結果を得られるよう画像を圧縮しやすい latent 表現に変換しその latent から neural decoder で画像を再構成する感じなのかなと: apple.github.io/ml-pico/
1
2
235

May 19
RT-Splatting is a breakthrough for real-time rendering of glass, plastic, and other semi-transparent surfaces. For the first time, you get both crisp reflections and clear see-through transmission—no more choosing between blurry mirrors or hidden backgrounds.
The secret: each Gaussian encodes its geometry (does a ray hit?) and optics (how much light is absorbed?) separately, so reflections and transmission are disentangled. Their “Specular-Aware Gradient Gating” keeps artifacts in check, while hybrid surface/volume rendering brings photorealism at 33 fps—even in complex scenes.
On 8 tough real-world datasets, RT-Splatting outperforms all prior Gaussian methods by 0.35–2.0 dB PSNR and up to 20% better LPIPS, with the biggest gains on transparent regions.
Scene edits are easy: tweak glass tint or reflection strength after training by scaling a few parameters—no retraining needed.
This is a huge leap for AR, digital twins, automotive, and photorealistic 3D product previews.
Get the full analysis here: yesnoerror.com/abs/2605.1826…
// alpha identified
// $YNE
1
3
12
437