
AbLWR: A Context-Aware Listwise Ranking Framework for Antibody-Antigen Binding Affinity Prediction via Positive-Unlabeled Learning
1. The paper reframes antibody-antigen binding affinity prediction from pointwise regression into a listwise ranking problem, directly optimizing what antibody discovery often needs in practice: prioritizing the best binders for a given (or closely related) antigen rather than predicting absolute Kd/IC50 values.
2. AbLWR is built to address two persistent bottlenecks in Ab-Ag ML: (i) severe label sparsity (few experimentally measured affinities vs massive sequence space) and (ii) subtle antigenic variation where small mutations can cause meaningful affinity shifts that regression models often miss.
3. The framework is two-stage: (a) PU (Positive–Unlabeled) pre-training to learn robust Ab-Ag representations from labeled positives plus large unlabeled pools, followed by (b) listwise fine-tuning with a ranking loss so the model learns relative ordering among candidate binders.
4. PU pre-training treats experimentally verified Ab-Ag pairs as positives and unverified pairs as unlabeled, and trains a coarse-grained 3-class affinity classifier (high/medium/low) combined with dual-level contrastive learning: an instance-level contrastive objective plus a cluster-aware contrastive objective that pulls together semantically similar binders.
5. A key technical detail is meta-optimized label refinement for unlabeled data: the model learns a perturbation to pseudo-label targets via bi-level optimization using a clean labeled validation batch, then updates pseudo-labels with EMA stabilization. This is intended to reduce confirmation bias when exploiting unlabeled Ab-Ag pairs.
6. For structure-aware representation, AbLWR builds residue graphs for antibody CDRs and antigens using predicted structures (IgFold for antibodies; ESMFold for antigens), connects residues by spatial proximity (4.5 Å threshold), initializes node features with PLM embeddings (IgFold encoder for Ab CDRs; ESM-2 for antigens), and encodes Ab and Ag with dual GCNs before concatenation into a pair embedding.
7. The ranking stage constructs informative training “lists” (K=5) using homologous antigen sampling: for a seed pair, it samples other labeled pairs whose antigens are sequence-homologous (Sim ≥ δseq) but whose affinities differ by a margin (|Δy| > ycutoff) to emphasize learning fine-grained distinctions while reducing noise from small measurement errors.
8. Context is injected at ranking time using Multi-Head Self-Attention over the entire candidate list (Set Transformer / ISAB with inducing points), explicitly modeling inter-sample dependencies so the score for one Ab-Ag pair can be informed by its homologous competitors—aiming to better resolve “close calls” among similar variants.
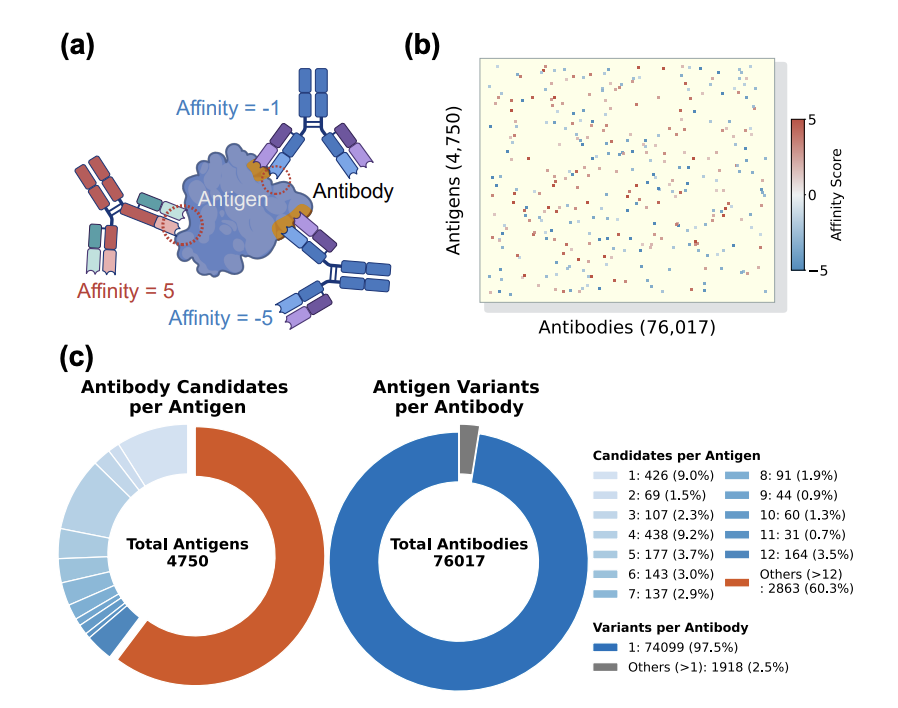
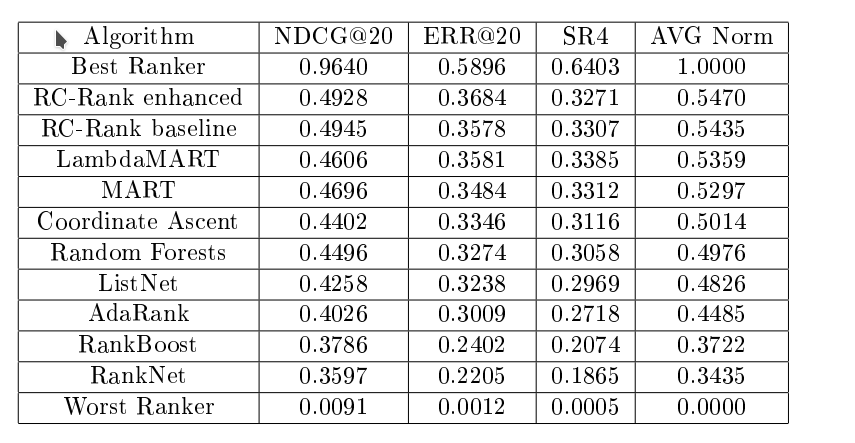
9. On a curated benchmark of 62,620 Ab-Ag pairs (from 8 public sources; affinities standardized to log Kd), AbLWR outperforms sequence, structure, complex-based, and traditional baselines. In random 5-fold CV it reports Precision@1 of 57.26% (vs 46.92% for GraphDTA) and large gains in stringent list-level metrics like Full Rank Accuracy (20.74% vs 8.98%).
10. Case studies connect the method to practical screening: on influenza neuraminidase datasets, AbLWR maintains more consistent ranking across subtle strain mutations and correctly captures the potency drop of FNI17 on post-2015 drifted H3N2 variants; on a human IL-33 affinity maturation set (including a single-chain antibody format), it prioritizes top binders early, reducing the number of candidates that would need wet-lab testing.
📜Paper: arxiv.org/abs/2604.11272
#abdesign #antibodies #proteinengineering #computationalbiology #deeplearning #machinelearning #bioinformatics #structuralbiology #GNN #learningtorank
4
28
2,090

12 Dec 2025
所以 ELON 在(Twitter)X 直接摁死了加密圈
(你的账号只是陪葬品)?
想在 X(Twitter)活下去? @grok : 有效的路线:
1.连续 14-21 天发 ≥60% 非 crypto 内容(让向量漂移),生活琐事也发一下
2.彻底换语气、文体、配图,告别老派风格
3.用 Premium 蓝V(信任值 0.15),给马斯克赚点!
4.每条都带开放性问题,硬抬回复,生活上的琐事更容易回应
下面我给你拆解:
为什么即使你不提 moon、100x,crypto 内容还是被埋?
整个算法残酷真相都在这里……
#LearningToRank #LTR #MachineLearning

11 Dec 2025

SO ELON JUST KILLED CRYPTO (TWITTER) X
(and your account is collateral damage)
I have been researching the algos, to growth hack, like the good old days... and here is what I learned about MY INDUSTRY... "Crypto Trading"...
As of the December 2025 algo update, anything that smells like “crypto” is getting quietly throttled into oblivion. Notice my posts get fewer likes and replies... less visibility overall...
Post a chart with a price target? 80 % reach drop overnight. Use $ followed by three letters? Instant shadowban for the next 7-21 days
Say “to the moon,” “100x,” or “altseason”? The AI flags it as spam and buries every post after that for weeks...
Even clean threads now die at 300-800 views if your last 90 days of history has too much “crypto DNA”
This isn’t a glitch. It’s deliberate.
Elon spent all of 2025 screaming “maximise un-regretted user seconds” while his Grok AI was trained on what PEOPLE actually keep scrolling for. Turns out the average user is sick of laser eyes, ticker spam, and endless “wen lambo” noise after four straight years of it. So the algorithm solved the problem the only way it knows how... it started treating crypto content like cigarette ads. Still allowed, but you’ll never see it unless you’re already chain-smoking in the echo chamber (as my daughter calls it)
The same mouth that pumped Doge to 70 cents is now choking the entire industry’s social media because “informational/entertainment ratio” apparently doesn’t include your daily market thread anymore.
BUT APPARENTLY X IS FREE SPEECH?
Women, small accounts, and anyone who doesn’t sound like a 2021 time capsule got hit hardest because the training data was 95 % bro posts. So the AI learned “this is what crypto sounds like” and now punishes anything that matches the pattern… which is literally all of us. And apparently... you all only want to see females with their BOOBS out... And that is not me...
Result?
Half the crypto creators I know are sitting at 2-10 % of their normal reach while meme pages about cats and politics print millions.
This isn’t about “post better content.” This is the platform deciding that crypto talk itself is low-quality in 2026.
So I will post charts... no ticker tag... I will not say Good Morning anymore... and wow... we thought Elon was pro crypto...
9
11
354

Don't miss our live training in Bratislava, during the #CommunityOverCodeEU conference!
We will dive into neural (#VectorBased) search and Large Language Model integration, passing by classification and #LearningToRank.
Reserve your ticket now: sease.io/training/the-ai-sid…

96

25 Aug 2023
What a week!
@CarissaVeliz and I delivered @EthicalAlliance #AIEthics certification.ethicalalliance.co/eca-cours…
@renekrie delivered #SearchWisdom workshop #Topologies, #HybridSearch #learningtorank and more
@CBLaCalzada and @manuela_ena presented new equipment.

1
2
10
569

24 May 2023
Improve the relevance of search at Miro 🔎
We're looking for a Senior Engineer with experience in the search domain.
Please feel free to reach out to me if you want to know more!
miro.com/careers/vacancy/677…
#SearchEngineering #SearchRelevance #LearningToRank #hiring
1
1
2
158

7 Mar 2023
Very excited to talk at #MumbaiFOSS happening at @iitbombay
From attending lectures at IITB in 2013 to actually delivering a talk there in 2023... Life has come full circle!!
#elasticsearch #learningtorank #ltr #iitb
7 Mar 2023

📢 Our next speaker for the #MumbaiFOSS conference is @IVaibhavMalpani
Vaibhav will be talking about building a search engine on ElasticSearch using Machine Learning.
Join us for the talk on 11th March.
Book your seats at indiafoss.net/Mumbai/2023

2
180
Whether it's a #SearchEngine, recommendation system, or other #InformationRetrieval application, #LearningToRank can help you deliver the most relevant results to your users.
Choose our upcoming training to take your skills to the next level: sease.io/training/learning-t…
#LTR

1
2
179

31 Dec 2022
Good online learning-to-rank models #learningtorank reddit.com/r/MachineLearning…
1
3
3,337

24 Oct 2022
More #HaystackConf videos released today: first we have Roman Grebennikov @public_void_grv : Building an open-source online learn-to-rank engine youtu.be/lbbp4CFWZGk #ltr #learningtorank #metarank #opensource
1
2
5
There are a lot of @ApacheSolr Learning to Rank features, but none of them can directly manage categorical features.
Let's see an overview of all the #LearningtoRank features and how is it possible to manage categorical features at the moment.
sease.io/2022/10/categorical…
1
3
Curious about what is the most appropriate approach to handle queries (and relevance labels) when splitting data?
Check this analysis made by Ilaria Petreti, IR/ML Engineer at @SeaseLtd !
sease.io/2022/09/how-to-spli…
#datascience #learningtorank #machinelearning

3
5
Do you know you can download for #free our booklet about 5 Best Practices for Learning to Rank?
Our experts collected these missing keys to perfect your #LearningtoRank models, and we are giving away these tips for free!
Download it here: sease.io/5-best-practices-fo…
2
2

15 Apr 2022
I'm happy to announce that I've completed the Search with ML course!
Big thanks to Daniel Tunkelang and @gsingers for making this course! Also, it would have been way less fun without such amazing classmates, #thankyou!
#ml #learningtorank #nlp lnkd.in/eAZpx_PX
1
5
We are ready for the London Information Retrieval Meetup!
join us on zoom by registering on our meetup page
meetup.com/London-Informatio…
#meetup #freeevent #informationretrieval #sease #softwareengineer #searchengineer #searcharchitect #machinelearning #learningtorank #datascience


2

30 Mar 2022
Our CTO #DataScience Speaker Series welcomes @HarrieOos of @Radboud_Uni for a video talk w/ our #AI & #NLProc engineers & researchers on advances in #search & #recommendationsystems using unbiased #LearningToRank based on position-biased click feedback
bloom.bg/3Dn0itd

3
13

8 Mar 2022
I am pleased to announce I am going to talk about the Apache Solr Interleaving contribution for Learning To Rank at Haystack LIVE! the next 24th of March!
Grab your (free) ticket now!
#solr #informationretrieval #learningtorank #…lnkd.in/djJYYJUD lnkd.in/d9D5BXY3
1
6
How does the #LearningtoRank query work in #Solr? How can we obtain the required features extraction time from the Solr qTime?
Let's discover the answers to these questions in our latest blog post.
sease.io/2022/01/apache-solr…
#informationretrieval #apachesolr #LTR @ApacheSolr
2
2

17 Dec 2021
Petites ressources en vrac pour comprendre un peu mieux le #learningtorank #ltr #ia
Thése de @bilelmoulahi
irit.fr/publis/SIG/Thesis_Mo…
Slide de prés : fr.slideshare.net/ptithacker…
Autre document : cyber.felk.cvut.cz/theses/pa…
Dataset : research.microsoft.com/en-us…
research.microsoft.com/en-us…
1/2
1
2
6
Part 4 of Ilaria Petreti 's journey into "A Learning to Rank Project on a Daily Song Ranking Problem" is online!
lnkd.in/dhpYwta
#learningtorank #spotify #lambdaMART #featureengineering
3
Don't have time to watch recordings on our Youtube Channel? Never mind! Take a look at all the slides from the talk "Explainability for Learning to Rank", from Ilaria Petreti and Anna Ruggero .
lnkd.in/d_27hm4
#meetup #learningtorank #informationretrieval
2
2