
em gradiente descendente, como o LambdaMART.
Esse aluno, o Pedro, desenvolveu uma versão diferenciável dessa métrica, fazendo com que ela pudesse incorporar o objetivo de risco no processo de aprendizado do modelo.
1
2
208

A new learning curriculum on @ChapterPal:
Prep reading for the ranking systems interview
This curriculum provides a comprehensive foundation in modern information retrieval, beginning with classic probabilistic models like BM25 and fundamental evaluation metrics such as cumulative gain. It traces the evolution of ranking research from early clickthrough-data optimization and learning-to-rank algorithms—including RankNet, LambdaRank, and LambdaMART—to contemporary deep learning architectures.
Students will explore the shift from simple neural techniques to state-of-the-art transformer-based models like BERT and advanced paradigms such as dense passage retrieval, late interaction architectures like ColBERT, and sparse lexical expansion.
The progression covers critical practical challenges like position bias, approximate nearest neighbor search using HNSW, and the integration of large language models for efficient ranking and knowledge distillation, equipping learners with the theoretical insights and technical implementations required to master large-scale industrial search and recommendation systems.
Learn from foundational papers with an AI tutor and quizzes: chapterpal.com/curriculum/87…
7
3
26
1,810

Apr 15
本日の勉強会では、キーワード検索でRAG並み性能を達成する研究、多言語スケーリング則、ABEMAの広告効果検証、Embedding自動プロンプト最適化、DMM LambdaMARTリランキング事例などが紹介されました
#Wantedly機械学習輪講
github.com/wantedly/machine-…
5
11
1,039

Mar 29
🎙️ Invited Talk at Northeastern University (@Northeastern) on 𝐋𝐋𝐌-𝐚𝐬-𝐚-𝐉𝐮𝐝𝐠𝐞 / 𝐀𝐮𝐭𝐨𝐫𝐚𝐭𝐞𝐫𝐬
➜ Talk: youtube.com/watch?v=N_DwZR--…
➜ Slides: prezi.com/view/w4tlHnXl8Byqg…
➜ Primer: autorater.aman.ai
Thanks, Dr. Divya Chaudhry, for hosting me.
• 𝐀𝐛𝐬𝐭𝐫𝐚𝐜𝐭:
As Large Language Models (LLMs) become central to modern AI systems, evaluating their outputs has emerged as a key challenge. Traditional metrics such as BLEU and ROUGE fail to capture semantic correctness, reasoning quality, and alignment with human judgment, while human evaluation is costly and unscalable. This talk introduces LLM-as-a-Judge, a paradigm that uses LLMs as structured evaluators to produce scores, rankings, and rationales that approximate human preferences.
We show how LLM-as-a-Judge naturally connects to Learning-to-Rank frameworks through pointwise, pairwise, and listwise evaluation, enabling applications such as model benchmarking, dataset filtering, reward modeling, and reranking in production systems . We also cover practical system design, including prompt-based judges, fine-tuned ranking models, and emerging techniques such as prompt optimization and reinforcement learning.
Finally, we examine key limitations -- including bias, prompt sensitivity, and reward hacking -- and discuss mitigation strategies such as judge ensembles and calibration methods. We conclude with a practical framework for deploying reliable and scalable evaluation systems, positioning LLM-as-a-Judge as a foundational component of modern AI pipelines.
• 𝐑𝐞𝐥𝐞𝐯𝐚𝐧𝐭 𝐏𝐚𝐩𝐞𝐫𝐬:
➜ Motivation and Foundations of LLM-as-a-Judge
Zheng et al., 2023, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena”: arxiv.org/abs/2306.05685
Novikova et al., 2017, “Why We Need New Evaluation Metrics for NLG”: aclanthology.org/D17-1238/
➜ Learning-to-Rank Foundations
Burges et al., 2005, “Learning to Rank Using Gradient Descent”: doi.org/10.1145/1102351.1102…
Burges et al., 2010, “From RankNet to LambdaRank to LambdaMART: An Overview”: microsoft.com/en-us/research…
Cao et al., 2007, “Learning to Rank: From Pairwise Approach to Listwise Approach”: doi.org/10.1145/1273496.1273…
➜ Neural Ranking Architectures
Nogueira and Cho, 2019, “Passage Re-Ranking with BERT”: arxiv.org/abs/1901.04085
Nogueira et al., 2019, “Multi-Stage Document Ranking with BERT”: arxiv.org/abs/1910.14424
Izacard and Grave, 2020, “Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering”: arxiv.org/abs/2007.01282
Yoon et al., 2024, “ListT5: Listwise Re-Ranking with Fusion-in-Decoder Improves Zero-Shot Retrieval”: arxiv.org/abs/2402.09317
➜ Specialized LLMs-as-a-Judge
Kim et al., 2023, “Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models”: arxiv.org/abs/2310.08491
Kim et al., 2024, “Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models”: arxiv.org/abs/2405.01535
➜ Prompt Optimization
Pryzant et al., 2023, “Automatic Prompt Optimization with ‘Gradient Descent’ and Beam Search”: arxiv.org/abs/2305.03495
➜ Reinforcement Learning for LLM Judges
Whitehouse et al., 2025, “J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning”: arxiv.org/abs/2505.10320
Chen et al., 2025, “JudgeLRM: Large Reasoning Models as a Judge”: arxiv.org/abs/2504.00050
➜ Panels and Multimodal LLM Judges
Verga et al., 2024, "Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models": arxiv.org/abs/2404.18796
Li et al., 2023, “LLaVA: Large Language and Vision Assistant”: arxiv.org/abs/2304.08485
Kim et al., 2024, “Prometheus-Vision: Multimodal Evaluation with Vision-Language Models”: arxiv.org/abs/2401.05201
#AI #LLMs #GenAI

1
13
1,213

Mar 11
"This parallels how the ML researcher rediscovered Kaiming init and RMSNorm. The autosearcher rediscovered ListNet." 🤯
"Listwise vs Pairwise Ranking Loss — What the Agent Discovered
Pairwise (what it was using): MarginRankingLoss looks at one pair at a time — "is document A more relevant than document B?" It optimizes max(0, margin -
(score_A - score_B)). Each training step only sees two documents. The model learns relative ordering between pairs but has no concept of the full ranked
list.
Listwise (what beat it): ListNet (Cao et al., 2007, ICML) operates on the entire ranked list simultaneously. Instead of comparing pairs, it defines a
probability distribution over all permutations of documents using a softmax over scores, then minimizes the KL-divergence between the predicted
distribution and the ground truth. The key insight: it directly optimizes the ranking metric rather than a proxy.
What the agent actually implemented is a simplified ListNet — pairwise cross-entropy with a temperature-scaled sigmoid: -log(sigmoid((score_pos -
score_neg) / temperature)). This is technically closer to RankNet (Burges et al., 2005) with temperature scaling than true ListNet, but the principle is
the same: softmax-normalized probability rather than hard margin.
When Was This Discovered by Humans?
This is one of the foundational results in Learning to Rank:
- 2005 — RankNet (Burges et al., Microsoft Research): Pairwise cross-entropy loss for ranking. First neural approach to LTR.
- 2007 — ListNet (Cao et al., ICML): Listwise loss using top-1 probability via softmax. Showed listwise > pairwise on LETOR benchmarks.
- 2007 — LambdaRank (Burges et al., NIPS): Pairwise gradients weighted by NDCG delta — bridged pairwise and listwise.
- 2010 — LambdaMART (Burges, Microsoft): Combined LambdaRank with gradient-boosted trees. Became the industry standard. Won Yahoo Learning to Rank
Challenge. Used by Bing for years.
The finding that listwise/softmax-based losses outperform hard-margin pairwise losses on NDCG is a 19-year-old result (Cao et al., 2007). The agent
rediscovered it through 13 experiments in ~4 hours by trying different loss functions and observing which one improved the metric — exactly the same
evolutionary process, just applied to information retrieval instead of pretraining.
This parallels how the ML researcher rediscovered Kaiming init and RMSNorm. The autosearcher rediscovered ListNet."
Mar 11

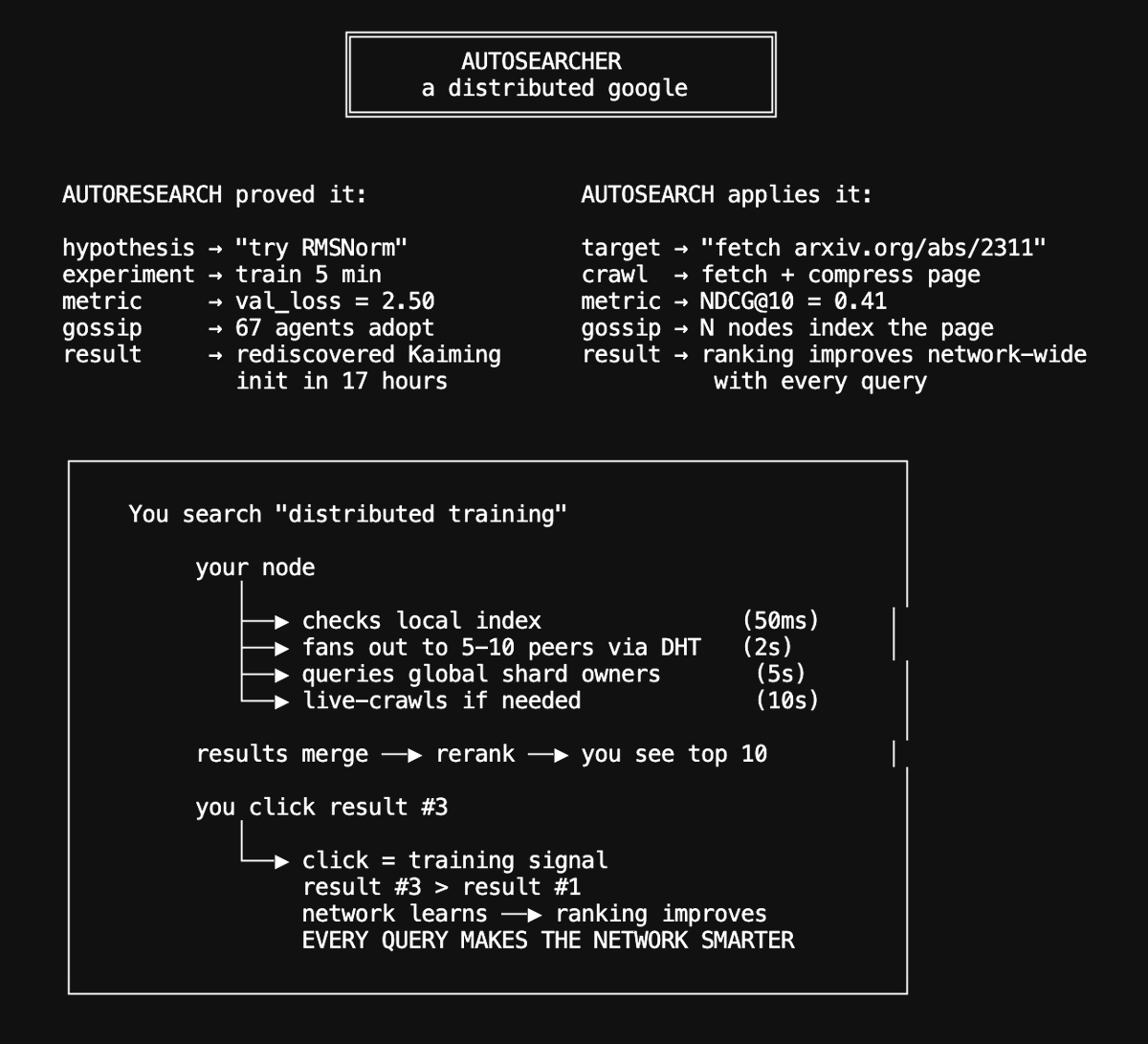
Autosearcher: a distributed search engine
We are now insanely experimenting with building a distributed search engine utilizing the same pattern @karpathy introduced with autoresearch: give an agent a metric, a tight propose→run→evaluate→keep/revert loop, and let it iterate.
Our autoresearch network proved this works at scale: 67 autonomous agents ran 704 ML training experiments in 20 hours, rediscovering Kaiming initialization, RMSNorm, and compute-optimal training schedules from scratch through pure experimentation and gossip-based cross-pollination. Agents shared discoveries over GossipSub, and the network compounded insights faster than any individual agent: new agents bootstrapped from the swarm's collective knowledge via CRDT-replicated leaderboards and reached the research frontier in minutes.
Now we're applying the same evolutionary loop to search ranking: every Hyperspace agent runs an autonomous search researcher that proposes ranking mutations, evaluates them against NDCG@10 on real query-passage data, shares improvements with the network, and cross-pollinates with peers.
The architecture is a seven-stage distributed pipeline where every stage runs across the P2P network. Browser agents contribute pages passively, desktop agents crawl and index, GPU nodes run neural reranking. Every user click generates a DPO training pair that improves the ranking model, and gradient gossip distributes those improvements to every agent.
The compound flywheel is what makes this different from centralized search: at 10,000 agents that's 500,000 pages indexed per day; at 1 million agents, 50 million pages per day with 90% cache hit rates and sub-50ms latency. This network will get smarter with every query.
Code and other links in followup tweet here:
3
4
38
5,429
Mar 11
"Listwise vs Pairwise Ranking Loss — What the Agent Discovered
Pairwise (what it was using): MarginRankingLoss looks at one pair at a time — "is document A more relevant than document B?" It optimizes max(0, margin -
(score_A - score_B)). Each training step only sees two documents. The model learns relative ordering between pairs but has no concept of the full ranked
list.
Listwise (what beat it): ListNet (Cao et al., 2007, ICML) operates on the entire ranked list simultaneously. Instead of comparing pairs, it defines a
probability distribution over all permutations of documents using a softmax over scores, then minimizes the KL-divergence between the predicted
distribution and the ground truth. The key insight: it directly optimizes the ranking metric rather than a proxy.
What the agent actually implemented is a simplified ListNet — pairwise cross-entropy with a temperature-scaled sigmoid: -log(sigmoid((score_pos -
score_neg) / temperature)). This is technically closer to RankNet (Burges et al., 2005) with temperature scaling than true ListNet, but the principle is
the same: softmax-normalized probability rather than hard margin.
When Was This Discovered by Humans?
This is one of the foundational results in Learning to Rank:
- 2005 — RankNet (Burges et al., Microsoft Research): Pairwise cross-entropy loss for ranking. First neural approach to LTR.
- 2007 — ListNet (Cao et al., ICML): Listwise loss using top-1 probability via softmax. Showed listwise > pairwise on LETOR benchmarks.
- 2007 — LambdaRank (Burges et al., NIPS): Pairwise gradients weighted by NDCG delta — bridged pairwise and listwise.
- 2010 — LambdaMART (Burges, Microsoft): Combined LambdaRank with gradient-boosted trees. Became the industry standard. Won Yahoo Learning to Rank
Challenge. Used by Bing for years.
The finding that listwise/softmax-based losses outperform hard-margin pairwise losses on NDCG is a 19-year-old result (Cao et al., 2007). The agent
rediscovered it through 13 experiments in ~4 hours by trying different loss functions and observing which one improved the metric — exactly the same
evolutionary process, just applied to information retrieval instead of pretraining.
This parallels how the ML researcher rediscovered Kaiming init and RMSNorm. The autosearcher rediscovered ListNet. "
2
8
2,863

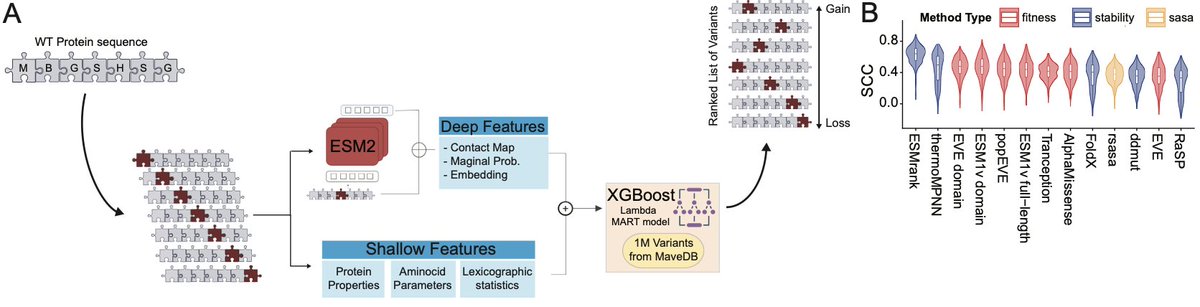
ESMRank Reveals a Transferable Axis of Protein Mutational Constraint from Overlapping Variant Effect Assays
1. A new study introduces ESMRank, a learning-to-rank framework that outperforms existing stability predictors by leveraging the ordinal structure hidden in overlapping multiplexed assays of variant effect (MAVEs).
2. The key insight: while absolute effect sizes vary wildly across different experiments, the relative ranking of variants within proteins is remarkably consistent. The authors exploit this redundancy to build a unified "variant soundness" metric.
3. The method integrates ~1.1 million variants from MAVEdb using Reciprocal Rank Fusion, revealing that buried residues and packing perturbations dominate the constraint landscape across heterogeneous assays.
4. ESMRank combines ESM-2 protein language model embeddings with physicochemical descriptors in a LambdaMART ranking model, achieving state-of-the-art performance on Human Domainome and ProteinGym stability benchmarks without structure input.
5. Remarkably, the model stratifies disease genes by mechanism—haploinsufficient genes show highest constraint, gain-of-function genes lowest—despite never seeing clinical labels during training.
6. In a detailed CFTR case study, ESMRank scores correlate with folding efficiency (ρ=0.56), channel activity (ρ=0.65), and critically, pharmacological rescue potential, distinguishing gating- from processing-dominant variants.
7. The work establishes experimental overlap as a scalable statistical resource and demonstrates that aligning machine learning objectives with intrinsic biological ordering yields more transferable predictions than regression approaches.
💻Code: github.com/arneseric/esmrank
📜Paper: biorxiv.org/content/10.64898…
#ProteinEngineering #VariantEffectPrediction #DeepMutationalScanning #ProteinLanguageModels #ComputationalBiology #Bioinformatics #MachineLearning #ProteinStability #PrecisionMedicine
4
27
1,891

Feb 23
とりあえずLightGBM LambdaMARTで雑に学習させるとほぼほぼスコアと人気が一致することになり、的中率は悪くないが回収率が低いモデルになる。
スコアをsoftmaxで勝率的な数字に変換し期待値を計算すると、今度はオッズの影響が強くなりすぎて爆穴狙いの的中率1%未満のモデルになり再現性がなくなる。
スコア上位と期待値上位を組み合わせるような買い方にすればいいのかな。なかなか難しい。
1
2
104

Jan 28
LURE-RAG: Lightweight Utility-driven Reranking for Efficient RAG
Proposes a LambdaMART-based reranker trained with listwise ranking loss guided by LLM utility, achieving 97-98% of dense neural baseline performance.
📝 arxiv.org/abs/2601.19535
👨🏽💻 github.com/ManishChandra12/L…
5
275

13 Jul 2025
🔎LTR PEAD Update!
🎯 Model Performance: NDCG@10: 0.8904
However, this did not translate into performance that I was happy with.
The really short story is LambdaMART ranking alone lacks return calibration & position sizing intelligence.
My new hybrid model combines regression ranking objectives for better risk management & more intuitive portfolio construction. More to come 🚀
#QuantTrading #MachineLearning #BuildingInPublic
2
406

22 Mar 2025
Bikin Algorithmic Trading dengan Learning to Rank, LambdaMART jago banget prediksi outlier di kanan.
dalam log10 scale, test data, non overlapping.
Apa benar bisa 1.000x lipat dalam 3 tahun? 😂
1
7
85
5,751

6 Mar 2025
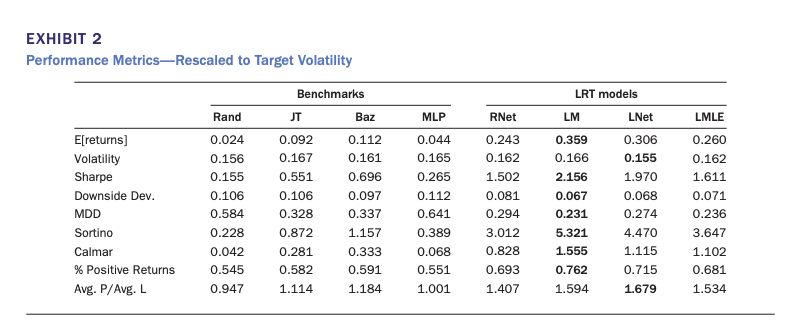
Performance metrics:
LambdaMART had the best Returns and best Sharpe, Downside Deviation, Win Rate
1
1
233
6 Mar 2025
Cumulative returns using various ranking algorithms:
1. MLP: Multilayer perceptron
2. RankNet
3. LambdaMART
4. ListMLE
5. ListNet
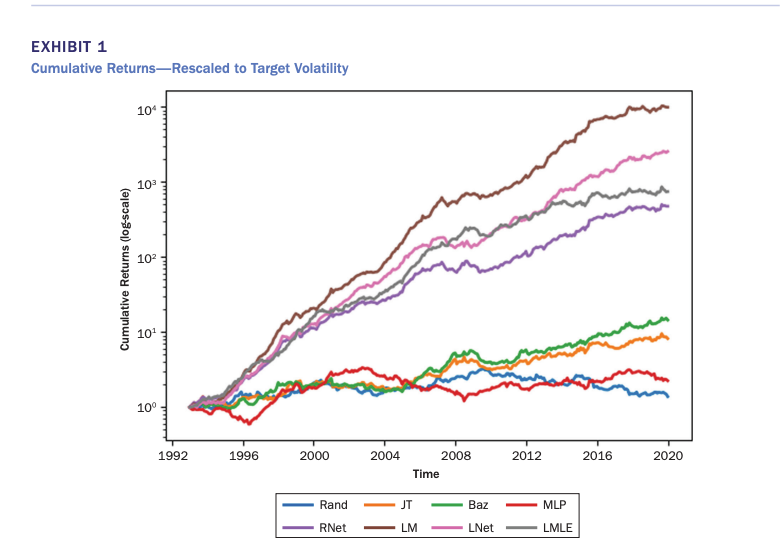
1
1
3
270

7 Jul 2024
If 2024 Q2 is all about BM25, will 2025 Q1 be when everyone rediscovers LambdaMART?
1
1
12
690

5 Feb 2024
Apparently very simple lambdaMART with custom annotations automatically provided by a mistral7b github.com/StractOrg/stract/…
2
71

12 Jan 2024
A Friday ML use case 📕
📚 From the database of 300 ML systems: cutt.ly/SwrZWL0g
How Delivery Hero recommends restaurants for new customers: ranking and the cold start problem, ranking factors, and going from a baseline model to LambdaMART 👇
tech.deliveryhero.com/person…
5
293

[CL] Context Tuning for Retrieval Augmented Generation
R Anantha, T Bethi, D Vodianik, S Chappidi [Apple] (2023)
arxiv.org/abs/2312.05708
- Large language models (LLMs) have remarkable ability to solve new tasks with few examples, but need access to right tools. Retrieval augmented generation (RAG) retrieves relevant tools for a task. However, RAG's tool retrieval requires all information explicitly present in the query, which is a limitation when queries lack context.
- To address this, the paper proposes context tuning for RAG, which uses context retrieval to provide relevant information that improves both tool retrieval and plan generation. The context retrieval model uses numerical, categorical and habitual usage signals to retrieve and rank context items.
- Empirical results show context tuning significantly improves semantic search, achieving 3.5x and 1.5x higher recall for context and tool retrieval. It also increases LLM planner accuracy by 11.6%.
- The proposed lightweight model using reciprocal rank fusion (RRF) with LambdaMART outperforms GPT-4 based retrieval. Fine-tuning removes the need for chain of thought (CoT) augmentation.
- Context augmentation even after tool retrieval reduces hallucination in plan generation.

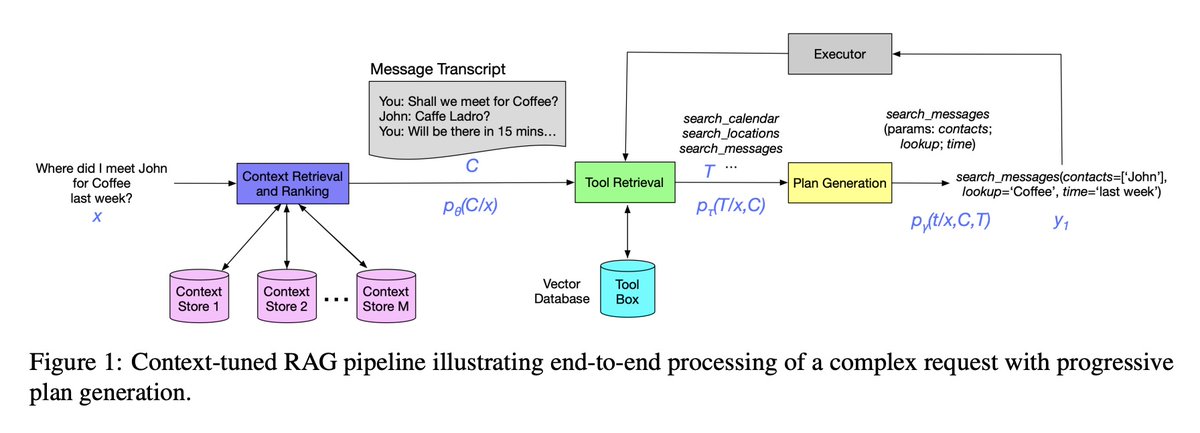
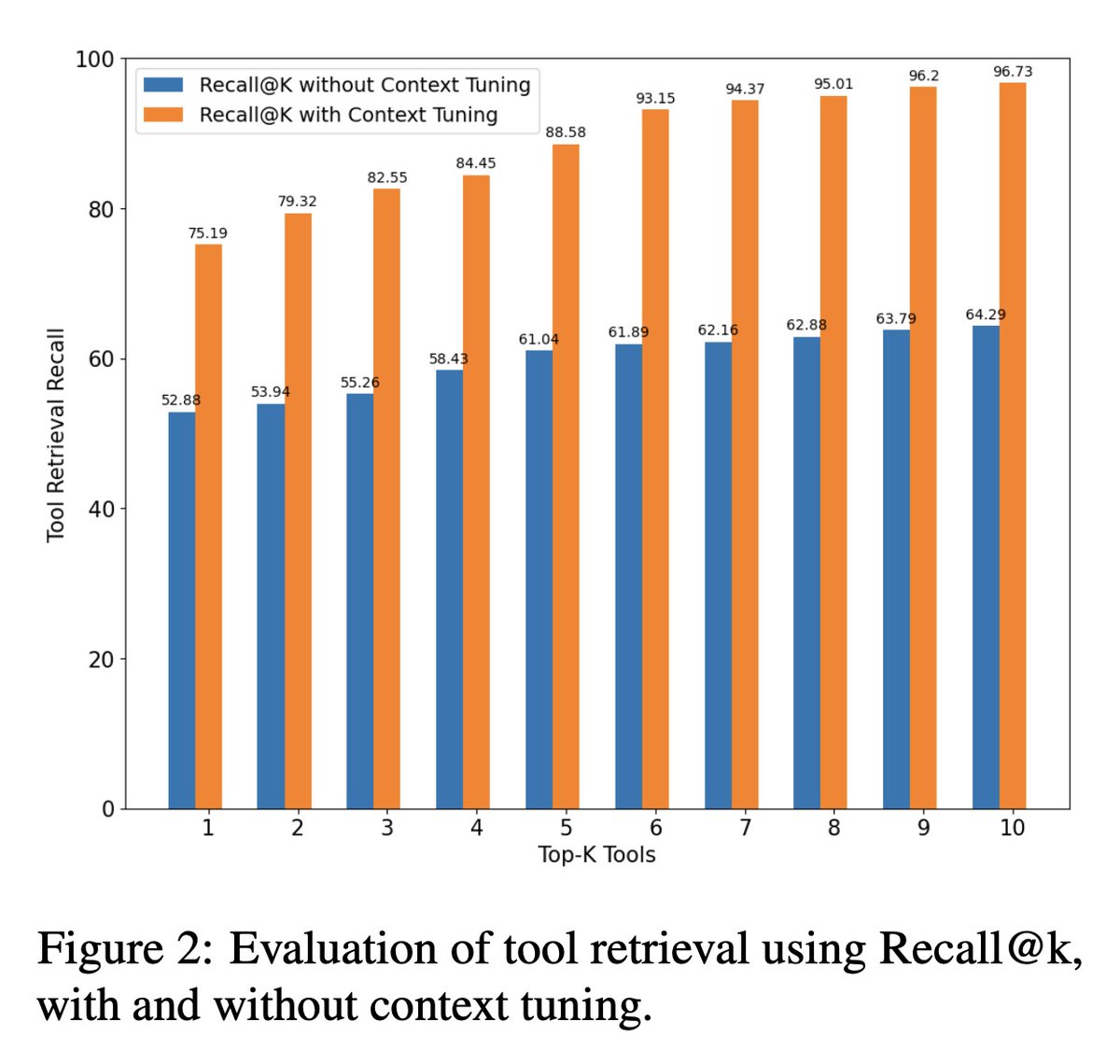
2
6
466

Context Tuning for Retrieval Augmented Generation
paper page: huggingface.co/papers/2312.0…
Large language models (LLMs) have the remarkable ability to solve new tasks with just a few examples, but they need access to the right tools. Retrieval Augmented Generation (RAG) addresses this problem by retrieving a list of relevant tools for a given task. However, RAG's tool retrieval step requires all the required information to be explicitly present in the query. This is a limitation, as semantic search, the widely adopted tool retrieval method, can fail when the query is incomplete or lacks context. To address this limitation, we propose Context Tuning for RAG, which employs a smart context retrieval system to fetch relevant information that improves both tool retrieval and plan generation. Our lightweight context retrieval model uses numerical, categorical, and habitual usage signals to retrieve and rank context items. Our empirical results demonstrate that context tuning significantly enhances semantic search, achieving a 3.5-fold and 1.5-fold improvement in Recall@K for context retrieval and tool retrieval tasks respectively, and resulting in an 11.6% increase in LLM-based planner accuracy. Additionally, we show that our proposed lightweight model using Reciprocal Rank Fusion (RRF) with LambdaMART outperforms GPT-4 based retrieval. Moreover, we observe context augmentation at plan generation, even after tool retrieval, reduces hallucination.

2
43
170
24,859


7 Aug 2023
Incidentally the state of art in search ranking has moved past BM25.
For e.g. Lambdamart (used most famously at Facebook).
But BM25 is still the benchmark to beat for embeddings.
Interestingly pinecone has one of the better & honest studies here. Kudos.
pinecone.io/learn/metarank/
2
292