

(or Structured Streaming)
- Do projects: Process big data, do ML with Spark MLlib
3
373

Apache Spark Cheat Sheet ⚡ (Save This!)
If you’re working with Big Data, mastering Apache Spark is non-negotiable.
Here’s a quick breakdown to level up your game 👇
🔹 What is Spark?
• Lightning-fast distributed processing
• In-memory computation → 100x faster than Hadoop
• Handles Batch Streaming seamlessly
🔹 Core Concepts
• RDDs → Low-level distributed data
• DataFrames → Structured, optimized tables
• Spark SQL → Query data like a pro
🔹 Ecosystem
• MLlib → Machine Learning
• Structured Streaming → Real-time pipelines
• GraphX → Graph processing
🔹 Key Operations
• map() → Transform data
• filter() → Clean datasets
• groupBy() → Aggregations
• collect() → Bring results
🔹 Quick Commands (PySpark)
df = spark.read.csv("data.csv", header=True)
df.show()
df.groupBy("col").count()
🔹 Why Spark Wins?
• Scales to billions of records
• Works with Kafka, BigQuery, S3
• Perfect for AI Data Engineering pipelines
💡 Pro Tip:
Always use DataFrames over RDDs for better performance (Catalyst Optimizer 🚀)
👨💻 Created by: Farrukh Naveed Anjum
Follow on X: @farrukh_codes
#ApacheSpark #BigData #DataEngineering #PySpark #CloudComputing #AI #SoftwareArchitecture

2
2
37
Your future self will thank you for taking this course: Diabetes Prediction With Pyspark MLLIB. imp.i384100.net/c/6457882/12… #MachineLearning #Courses #AD
1
478

31 Dec 2025
Your future self will thank you for taking this course: Diabetes Prediction With Pyspark MLLIB. imp.i384100.net/c/6457882/12… #MachineLearning #Courses #AD
1
2
1,054

29 Nov 2025
MLFlow vs Weight & Biases(WnB) for MLOps 🤖🚀
Which framework to choose for Experiment Tracking and Monitoring of your ML models?
The right choice depends on your priority:
Engineering control -> MLflow
Visualization & collaboration -> W&B.
🔹MLflow is a good choice for an "open-source", self-hosted, end-to-end MLOps platform with strong model management, while Weights & Biases (W&B) excels with its superior user experience for interactive experiment tracking, visualization, and team collaboration.
🔹MLflow provides a more comprehensive set of MLOps lifecycle tools, whereas W&B focuses on the experimentation and analysis phase with a more user-friendly interface out of the box.
MLflow Strengths:
> Open-source and flexible: Can be self-hosted and has no vendor lock-in concerns.
> End-to-end MLOps lifecycle: Includes tracking, projects, model packaging, and a model registry for managing the entire model lifecycle.
> Language-agnostic: Supports a wide range of ML libraries beyond Python, like Spark MLlib and CatBoost.
> Best for: Projects that need a comprehensive, self-managed solution to cover the full lifecycle, including deployment and registration.
Weights & Biases (W&B) Strengths:
> Superior user experience: Offers a more intuitive and faster setup for experiment tracking.
> Advanced visualizations: Provides powerful, real-time, and interactive dashboards for metrics, hyperparameters, and artifacts like images and audio.
> Collaboration features: Excellent for team collaboration with rich reporting and sharing capabilities.
> Focus on experiment tracking: Specializes in interactive logging, artifact versioning, and hyperparameter sweeps.
> Best for: Teams who prioritize a polished and seamless experience for tracking, visualizing, and comparing experiments, and who may have higher budgets or need a managed cloud service.

1
1
10
846

サーバレスでもApache Spark MLlib (Python)、Optuna、MLflow Spark、Joblib Sparkが実行できるようになりました!Databricksでよりお手軽にMLワークロードを実行可能に!
分散MLがもっと手軽に:サーバーレス&標準クラスターでの提供を Public Preview 開始
databricks.com/jp/blog/annou…
3
18
5,529

21 Nov 2025
THIS IS MASSIVELY IMPORTANT !!!!!
INTERLINKING
Superlinked
- Improve your vector search relevance by Encoding Metadata Together with your Unstructured Data into Vectors.
- A framework and a self-hostable REST API server that connects your data, vector database and backend services.
- Construct custom data & query EMBEDDING MODELS from pre-trained encoders from sentence-transformers, open-clip & custom encoders for numbers, timestamps & categorical data.
github.com/superlinked/super…
Beyond Multi-Modal
Represent everything you know about your Users, Documents, Products or jira issues with Unified "Omni Modal" Embeddings for maximum real-world retrieval relevance & control.
superlinked.com/
Superlinked is a Python framework for AI Engineers building high-performance search & recommendation applications that combine structured & unstructured data.
github.com/superlinked/super…
VECTORS - THE SECRET CONNECTION BETWEEN BIOLOGICAL & DIGITAL
They hide the Human-Machine Integration through Metadata, Vectors, Microservices & Automation
PySpark - Spark Python
VectorAssembler
sparkcodehub.com/pyspark/mll…
VectorAssembler is a transformer used in machine learning frameworks like Apache Spark MLlib & Apache Flink to combine multiple input columns—such as numeric values, booleans, or existing vectors—into a single vector column.
george-jen.gitbook.io/data-s…
Biological vectors are being interlinked with vector powered apps !!!
INTEGRATION OF BIOLOGY WITH VECTOR TECHNOLOGIES
The integration of biology with vector technologies and powered applications is evident across research, education & biotechnology.
In molecular biology, VECTORS ARE ESSENTIAL TOOLS FOR GENE DELIVERY & MANIPULATION, with platforms like VectorBuilder offering comprehensive services for custom cloning, virus packaging (e.g., lentivirus, AAV, adenovirus), & CRISPR genome editing solutions.
app.scientist.com/blog/2020/…
VectorBuilder
VectorBuilder is a global leader in GENE DELIVERY TECHNOLOGIES.
As a trusted partner for thousands of labs & biotech/pharma companies across the globe.
VectorBuilder offers a full spectrum of gene delivery solutions covering virtually all research and clinical needs from bench to bedside.
en.vectorbuilder.com/
VectorBee
VectorBee is a highly user-friendly GENETIC ENGINEERING SOFTWARE created by VectorBuilder for viewing, editing & analyzing DNA & protein sequences.
It is developed by a talented team of biologists and IT engineers led by Professor Bruce Lahn
vectorbee.com/en/
31 May 2025

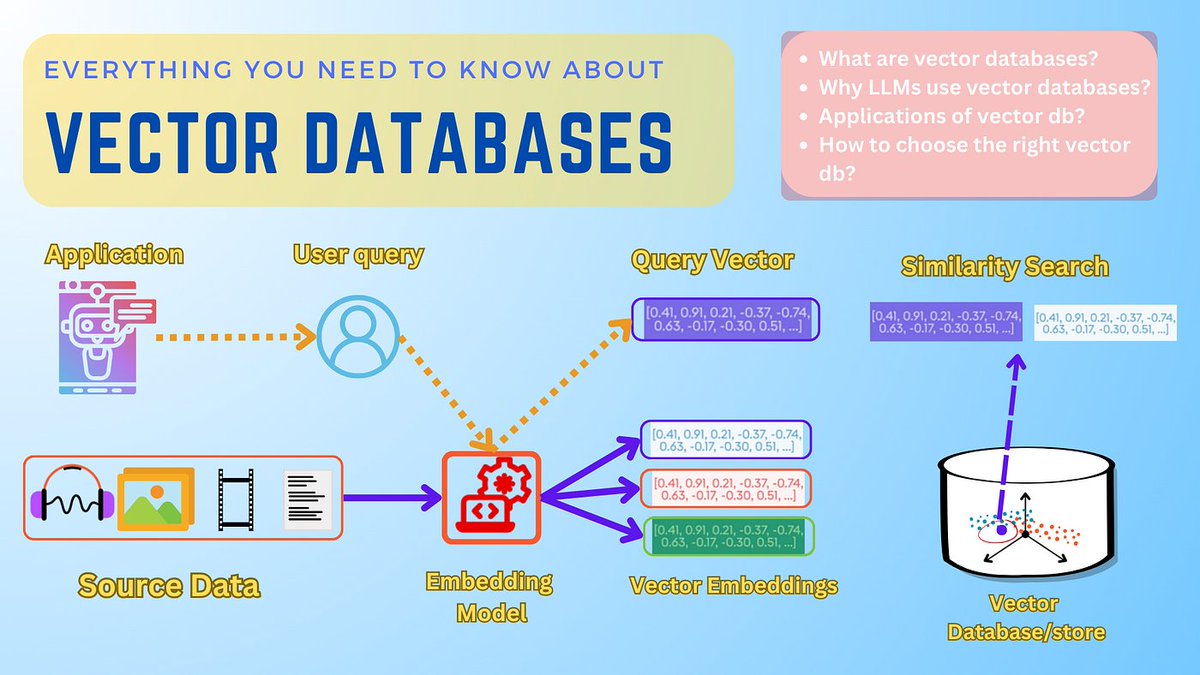
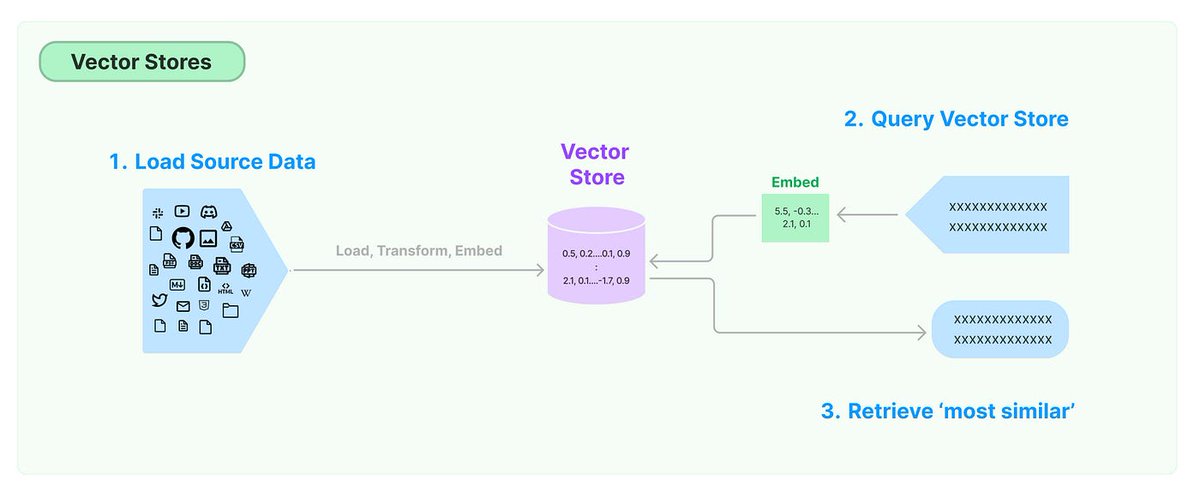
What are Vector Databases?
Vector databases serve as sophisticated repositories for embeddings, capturing the essence of semantic similarity among disparate objects. These databases facilitate similarity searches across a myriad of multimodal data types, paving the way for a new era of information retrieval. By providing contextual understanding and enriching generation results, vector databases greatly enhance the performance and utility of Language Learning Models (LLM). This underscores their pivotal role in the evolution of data science and machine learning applications.
◽VectorDB
VectorDB vectordb.com/ is a Pythonic vector database offers a comprehensive suite of CRUD operations and robust scalability options, including sharding and replication. It's readily deployable in a variety of environments, from local to on-premise and cloud.
github.com/jina-ai/vectordb
The strength of VectorDB lies in the combined power of two groundbreaking technologies:
1.) DocArray
Expertly designed for the representation, transmission, storage, and retrieval of multimodal data, DocArray is an efficient Python library. It is primarily tailored for the development of multimodal AI applications and ensures seamless integration with Python and the vast machine learning ecosystem.
DocArray supports various vector databases such as Weaviate, Qdrant, ElasticSearch, Redis, and HNSWLib. It offers native support for NumPy, PyTorch, and TensorFlow, providing flexibility specifically for model training scenarios. Being based on Pydantic, DocArray is instantly compatible with web and microservice frameworks like FastAPI and Jina, allowing data transmission as JSON over HTTP or as Protobuf over gRPC.
docs.docarray.org/
2. Jina-Serve
Jina is a revolutionary open-source AI framework, empowering developers to construct multimodal AI services and pipelines, that communicate via gRPC, HTTP, and WebSockets. This enables you to focus on perfecting your logic and algorithms while leaving the infrastructure complexities to Jina.
Jina transitions smoothly from local deployment to advanced orchestration frameworks, including Docker-Compose, Kubernetes, and the Jina AI Cloud. It supports any data type, any mainstream deep learning framework, and any protocol, thus offering a highly adaptable solution.
For high-performance microservices, Jina provides easy scalability, duplex client-server streaming, and async/non-blocking data processing over dynamic flows. Its integration with Docker containers through Executor Hub, observability via OpenTelemetry/Prometheus, and rapid Kubernetes/Docker-Compose deployment make it an indispensable part of VectorDB.
github.com/jina-ai/serve
Reference:
VectorDB: a Python vector database you just need - no more, no less
jina.ai/news/vectordb-a-pyth…
◽Tencent Cloud VectorDB
Tencent Cloud VectorDB is a fully managed, self-developed enterprise-level distributed database service designed specifically for storing, retrieving, and analyzing multidimensional vector data. With support for multiple index types and similarity calculation methods, it can perform billion-scale single-index vector searches and sustain millions of QPS with a latency of just milliseconds. In addition to enhancing answer accuracy for large language models (LLMs) by serving as an external knowledge base, Tencent Cloud VectorDB finds extensive applications in AI domains such as recommendation systems and natural language processing (NLP).
Tencent Cloud VectorDB can be used with LLMs. Enterprises can store their private domain data in Tencent Cloud VectorDB after it has been text segmented and vectorized. This helps them build a dedicated external knowledge base to provide LLMs with better prompts and generate more accurate answers for future retrievals.
tencentcloud.com/products/vd…
15
13
1,156
13 Nov 2025
Your future self will thank you for taking this course: Diabetes Prediction With Pyspark MLLIB. imp.i384100.net/c/6457882/12… #MachineLearning #Courses #AD
1
1
4
1,156
12 Nov 2025
BioDigital Convergence
PART 16 C: THE SPARK FRAMEWORK & THE UNIFICATION OF ALL PLATFORMS & CODINGS
SPARK Framework
The SPARK Framework brings modern web development tools to the the Atlassian Platform.
SPARK is a Single Page Application Framework for Atlassian add-ons.
Maven-Compatible (Hellblazer)
Integrates with maven & be friends with your backend developers & buildmasters.
Full Documentation
web.archive.org/web/20190717…
Maven is where Hellblazer come into the system in preparation for the Spark2 Activation with Luciferase, the Lucien Architecture & Hellish Library
github.com/Hellblazer/Lucife…
Atlassian Platform Addon - SPARK
SPARK is a framework for add-on developers for the Atlassian platform to develop, build and integrate Single Page Applications (SPA) for Confluence, JIRA & other Atlassian products.
github.com/yours-truly-phil/…
Atlassian Cloud Platform
The Atlassian Cloud Platform connects teams with all the curated data, context & goals they need as they work across their favorite Atlassian and third-party applications.
atlassian.com/platform
First let's discuss what Spark is as well as why it's an important integration with the Particle IoT platform.
SPARK is interconnected to multiple platforms, tools & systems including Biological.
INTERLINKING
Superlinked
- Improve your vector search relevance by Encoding Metadata Together with your Unstructured Data into Vectors.
- A framework and a self-hostable REST API server that connects your data, vector database and backend services.
- Construct custom data & query EMBEDDING MODELS from pre-trained encoders from sentence-transformers, open-clip & custom encoders for numbers, timestamps & categorical data.
github.com/superlinked/super…
Beyond Multi-Modal
Represent everything you know about your Users, Documents, Products or jira issues with Unified "Omni Modal" Embeddings for maximum real-world retrieval relevance & control.
superlinked.com/
Superlinked is a Python framework for AI Engineers building high-performance search & recommendation applications that combine structured & unstructured data.
github.com/superlinked/super…
VECTORS - THE SECRET CONNECTION BETWEEN BIOLOGICAL & DIGITAL
They hide the Human-Machine Integration through Metadata, Vectors, Microservices & Automation
PySpark - Spark Python
VectorAssembler
sparkcodehub.com/pyspark/mll…
VectorAssembler is a transformer used in machine learning frameworks like Apache Spark MLlib & Apache Flink to combine multiple input columns—such as numeric values, booleans, or existing vectors—into a single vector column.
george-jen.gitbook.io/data-s…
Biological vectors are being interlinked with vector powered apps !!!
INTEGRATION OF BIOLOGY WITH VECTOR TECHNOLOGIES
The integration of biology with vector technologies and powered applications is evident across research, education & biotechnology.
In molecular biology, VECTORS ARE ESSENTIAL TOOLS FOR GENE DELIVERY & MANIPULATION, with platforms like VectorBuilder offering comprehensive services for custom cloning, virus packaging (e.g., lentivirus, AAV, adenovirus), & CRISPR genome editing solutions.
app.scientist.com/blog/2020/…
VectorBuilder
VectorBuilder is a global leader in GENE DELIVERY TECHNOLOGIES.
As a trusted partner for thousands of labs & biotech/pharma companies across the globe.
VectorBuilder offers a full spectrum of gene delivery solutions covering virtually all research and clinical needs from bench to bedside.
en.vectorbuilder.com/
VectorBee
VectorBee is a highly user-friendly GENETIC ENGINEERING SOFTWARE created by VectorBuilder for viewing, editing & analyzing DNA & protein sequences.
It is developed by a talented team of biologists and IT engineers led by Professor Bruce Lahn
vectorbee.com/en/
8
19
924
12 Nov 2025
BioDigital Convergence
PART 16 B: APACHE SPARK LARGE-SCALE PARALLEL COMPUTING & REDIS
First let's discuss how we know for a fact they're using Apache Spark for parallel computing.
Apache Spark has emerged as a leading framework for parallel computing in biological data analysis, particularly due to its in-memory processing capabilities, high fault tolerance & scalability.
pubmed.ncbi.nlm.nih.gov/3010…
APACHE SPARK
Spark is an Apache framework used for computing. This is important because the BioDigital Convergence requires parallel computing in preparation for the Singlarity.
APACHE SPARK - HOSTED SPARK
Apache Spark is a fast & general cluster computing system for Big Data built around speed, ease of use & advanced analytics.
It provides high-level APIs in Scala, Java, Python, R & an optimized engine that supports general computation graphs for data analysis.
DATA STREAMING
It also supports several other tools such as Spark SQL for SQL & DataFrames, MLlib for machine learning, GraphX for graph processing & Spark Streaming for stream processing.
databricks.com/glossary/host…
Hosted Spark Environment
A hosted Spark environment refers to a managed service that provides Apache Spark Infrastructure without requiring users to deploy & maintain their own clusters.
These services streamline the process of running Spark applications by handling cluster provisioning, scaling, monitoring, and maintenance, allowing users to focus on developing & executing data processing workflows.
SPARK PARALLELIZE GENOMIC DATA
ADAM (NODE is Human)
ADAM is a library & Command Line tool that enables the use of Apache Spark to Parallelize Genomic Data analysis across cluster/cloud computing environments.
On a single NODE, ADAM provides competitive performance to optimized multi-threaded tools, while enabling scale out to clusters with more than a thousand cores. ADAM's APIs can be used from Scala, Java, Python, R & SQL.
github.com/bigdatagenomics/a…
READING & WRITING DATA FROM SPARK
Redis Spark Connector
The Redis Connector for Spark provides integration between Redis & Apache Spark & supports Reading Data From & Writing Data to Redis.
redis-field-engineering.gith…
CONTAINERS
Within a Spark 3 Environment the connector enables users to read data from Redis, manipulate it using Spark operations, and then write results back to Redis or to another system.
endjin.com/blog/2025/01/spar…
Data can also be imported to Redis by reading it from any data source supported by Spark and then writing it to Redis.
github.com/redis-field-engin…
READING & WRITING DATA FROM REDIS CLUSTER
Spark-Redis
A connector for Spark that allows Reading & Writing to/from Redis Cluster
github.com/RedisLabs/spark-r…
REDIS GO IMPLEMENTATION
1) Redis Cloud GO API
Go SDK for Redis Enterprise Cloud Pro
github.com/RedisLabs/rediscl…
2) Control Plane
Go Implementation of Data Plane API
github.com/RedisLabs/go-cont…
MICROSERVICES
1) Envoy
Cloud-Native High-Performance Edge/Middle/Service Proxy
envoyproxy.io/
Envoy is hosted by the Cloud Native Computing Foundation (CNCF).
If you are a company that wants to help shape the evolution of technologies that are container-packaged, dynamically-scheduled and microservices-oriented, consider joining the CNCF.
github.com/envoyproxy/envoy
2) Envoy Gateway
gateway.envoyproxy.io/
Manages Envoy Proxy as a Standalone or Kubernetes-based Application Gateway
github.com/envoyproxy/gatewa…
3) Envoy AI Gateway
Manages Unified Access to Generative AI Services built on Envoy Gateway
aigateway.envoyproxy.io/
Envoy AI Gateway is an open source project for using Envoy Gateway to handle request traffic from application clients to Generative AI services.
github.com/envoyproxy/ai-gat…
9
14
622

1 Nov 2025
> Why Apache Spark Is Still the Backbone of Modern Data Engineering (Even in the Age of Lakehouses)
- Everyone’s talking about Databricks, Snowflake, and AI, but Spark quietly powers them all.
- In 2025, Spark isn’t old tech, it’s the invisible engine behind most large-scale data systems.
Here’s the reality:
→ Spark evolved from “big data batch processor” to unified compute engine for every workload, batch, stream, ML, and graph.
> Let’s break down why Spark still matters 👇
1. From Hadoop → Unified Engine
• Old way: Hadoop clusters and manual configs.
• New way: Spark runs everywhere, on Kubernetes, Databricks, and even serverless.
2. From RDDs → DataFrames & SQL
- The low-level API days are gone.
- Spark SQL and DataFrames made distributed computing declarative and accessible.
3. From Batch → Real-Time
- With Structured Streaming, Spark became a true event processor.
- It handles micro-batch streaming at scale, the sweet spot between latency and reliability.
4. From MLlib → Integrated AI
- Spark now works seamlessly with MLflow and TensorFlow.
- Data engineers can build, train, and serve models directly in Spark clusters.
5. From Legacy → Lakehouse Core
- Spark powers the Lakehouse: Delta Lake, Iceberg, and Hudi all depend on it.
- The next generation of lake engines are built on top of Spark, not against it.
In 2025, Spark isn’t fading, it’s everywhere. If data moves at scale, chances are, Spark is pushing it.
1
16
102
5,035

29 Oct 2025
Spark Connect: NVIDIA Accelerator for Spark SQL and MLlib x.com/i/broadcasts/1eaKbjlXe…
2
5
1,141
12 Oct 2025
> Here are 5 project ideas that say "I don’t just use PySpark, I make it production-ready, efficient, and scalable"
1. Data Lakehouse ETL with PySpark Delta Lake
→ Build a structured ETL pipeline that converts raw data into clean, queryable Delta tables.
• Use PySpark to handle ingestion, transformations, and schema enforcement
• Implement multi-layer architecture (bronze → silver → gold)
• Add partitioning, time travel, and schema evolution support
• Why it matters: Shows you can design a proper data lakehouse, not just run Spark jobs on CSVs.
2. Distributed Data Quality Validator
→ Create an automated validation layer that runs checks on massive datasets using PySpark.
• Write PySpark-based rules to detect null spikes, duplicates, and schema drift
• Integrate Great Expectations or custom validation logic
• Push alerts via Slack or email with logs stored in S3
• Why it matters: Proves you care about data reliability, not just ingestion speed.
3. Log Processing and Aggregation at Scale
→ Process billions of log records to extract key metrics and patterns.
• Use PySpark for parsing, filtering, and aggregating log data
• Apply performance tuning, broadcast joins, caching, and optimized partitioning
• Store processed results in Parquet or Delta Lake for analytics
• Why it matters: Demonstrates your ability to optimize jobs and work with real-world scale
• 4. Scalable Feature Engineering Pipeline
→ Use PySpark MLlib to prepare massive datasets for machine learning.
• Build feature transformation pipelines (encoding, scaling, vector assembly)
• Cache intermediate results intelligently to reduce cluster cost
• Save final features in Delta or Hive tables for training consumption
• Why it matters: Shows you understand how ML and data engineering meet at scale.
5. Spark Job Monitoring and Optimization Tool
→ Build a monitoring script that tracks Spark job performance metrics automatically.
• Use the Spark REST API to collect job stats (execution time, shuffle size, memory usage)
• Generate daily cost and performance summaries
• Auto-suggest optimization steps (e.g., reduce shuffles, repartition joins)
• Why it matters: Shows that you think like a production engineer measuring, optimizing, and scaling.
• Bonus Tip: Make It Look Like a Real System
→ Use Docker for local setup, Terraform for infrastructure, and Airflow for orchestration.
• Add Pytest-based testing, CI/CD pipelines, and structured logging
• Include diagrams, configs, and monitoring examples in your README
→ In 2025, engineers who can tune, test, and automate PySpark pipelines will dominate the data space, not just those who can “run a job.”
1
19
136
6,145

4 Oct 2025
🔥 Já ouviu falar em Apache Spark?
Ele é um dos motores mais usados em Big Data para processar e transformar dados em alta escala.
O que faz o Spark ser tão importante?
✅ Processamento distribuído e rápido (até 100x mais que Hadoop MapReduce)
✅ Suporte a batch e streaming
✅ APIs em Python, SQL, Scala, Java e R
✅ Escalabilidade: de gigabytes até petabytes
✅ Ecossistema completo (SQL, MLlib, Streaming, GraphX)
Quer entender a fundo sua importância na Engenharia de Dados?
Preparei um guia completo no Notion 👇
🔗 talented-noise-a52.notion.si…
1
2
55
2,301
29 Sep 2025
Join us on October 29 at 9:30 AM PT for a deep dive into Apache Spark™, Spark Connect, and Spark ML at @nvidia!
We’ll explore how Spark Connect, starting in Spark 3.4 and extended to MLlib in Spark 4.0 , enables new client connections and stability benefits. ✅ The session will also highlight how NVIDIA GPU-accelerated plugins for Spark SQL and ML deliver end-to-end acceleration with no code changes—with performance up to 9x faster at 80% lower cost.
📅 October 29
⏰ 9:30–10:30 AM P
📍 Live online (LinkedIn, X & YouTube)
RSVP here 👉luma.com/0zffq605
#opensource #sparkconnect #nvidia #apachespark #oss

1
2
4
1,141
13 Sep 2025
Como vocês sabem, eu já tenho 2 certificações de fundamentos sobre Databricks.
Mas vocês sabem o que ele é? O que ele faz? E qual a importância dele na área de dados?
🧵 Hoje vou explicar de forma técnica e prática 👇
O que é o Databricks?
O Databricks é uma plataforma unificada de dados construída sobre o Apache Spark.
Ele conecta todo o ciclo de vida dos dados:
Ingestão
Processamento
Armazenamento
Análise
Machine Learning
Deploy em produção
👉 Tudo no mesmo ambiente, sem precisar alternar entre várias ferramentas.
Para as carreiras, onde o Databricks se encaixa?
⚙️ Engenharia de Dados
🔹 O papel de Data Engineering no Databricks é central:
Processamento em batch e streaming com Spark.
Criação de pipelines ETL/ELT para transformar dados brutos em estruturados.
Delta Lake garante ACID em data lakes (transações confiáveis, versionamento, time travel).
Delta Live Tables automatiza pipelines com monitoramento e reprocessamento automático.
📌 Exemplo em PySpark (criação de tabela Delta):
df.write.format("delta").mode("overwrite").save("/mnt/dados/delta/tabela_exemplo")
📈 Ciência de Dados
🔹 Para Data Science, o Databricks oferece:
Notebooks colaborativos (Python, R, SQL, Scala).
Integração com bibliotecas como Pandas, NumPy, scikit-learn e matplotlib.
Suporte a análises exploratórias (EDA) e visualização de dados.
Colaboração em tempo real entre engenheiros e cientistas.
📌 Exemplo: carregar dados direto em Pandas para análise rápida
df = spark.read.format("delta").load("/mnt/dados/delta/tabela_exemplo").toPandas()
df.describe()
🤖 Machine Learning & IA
🔹 O Databricks acelera ML e AI:
Treinamento em larga escala com Spark MLlib, TensorFlow e PyTorch.
MLflow para versionar, registrar e monitorar modelos.
Deploy simplificado em endpoints de produção.
Integração com LLMs e NLP via Hugging Face.
📌 Exemplo: registro de modelo com MLflow
import mlflow.sklearn
with mlflow.start_run():
mlflow.sklearn.log_model(model, "modelo_churn")
mlflow.log_metric("accuracy", 0.92)
🔒 Governança e Segurança
🔹 O Unity Catalog é o centro de governança:
Controle de acesso baseado em usuários/grupos.
Auditoria e rastreabilidade (quem acessou, quando e o quê).
Catalogação centralizada (camada bronze, silver, gold).
Integração com regras de compliance (LGPD, GDPR).
👉 Isso garante confiança e segurança em ambientes corporativos.
Por que ele é importante?
Sem Databricks:
⚠️ Engenheiros, cientistas e analistas trabalham em silos.
⚠️ Fluxos de dados lentos e inconsistentes.
⚠️ Modelos ficam no “limbo” e não chegam à produção.
Com Databricks:
✅ Times unificados.
✅ Pipelines escaláveis.
✅ Modelos rastreáveis e versionados.
✅ Dados prontos para gerar valor real ao negócio.
O Databricks não é só uma ferramenta.
É um ecossistema que conecta engenharia, ciência e machine learning em um só lugar.
E cada vez mais, ele é habilidade obrigatória para quem quer trabalhar em Data & AI.
1
15
180
7,526

2 Sep 2025
Day 66 of #90DaysOfDataEngineering
-Explored Spark basics and advanced concepts.
-Started MLlib with classification and regression.
#LearnInPublic #BuildInPublic #dataengineering #90DaysOfDataEngineering
3
23
1 Sep 2025
Starting our Zero to One Series for Data Engineering
🔥 Spark Zero to One Guide for Data Engineers
Save it for your next project
1. Why Learn Spark:
100x faster than Hadoop MapReduce
Unified platform: batch, streaming, ML, SQL
Used by Netflix, Uber, Airbnb
Core skill in 80% big data roles
2. Core Components:
Spark Core, SQL, Streaming
MLlib, GraphX
PySpark, Scala integration
4-Phase Learning Path:
Foundations → Core Skills → Advanced → Real Projects
Explore full Spark DBT course:
datavidhya.com
Follow Datavidhya for more

4
22
1,540

28 Aug 2025
🔑 Core Skills for AI Engineer Internship (2025)
Python
Object-Oriented Programming (OOP)
NumPy
Pandas
Matplotlib/Seaborn/Plotly
Scikit-learn
Deep Learning (PyTorch, TensorFlow, JAX)
Hugging Face Transformers
LangChain
LangGraph
LlamaIndex
RAG Pipelines
Vector Databases
PgVector
Qdrant
Weaviate
Milvus
FastAPI
gRPC / REST APIs
Docker
Kubernetes
AWS/GCP/Azure (Cloud ML services)
MLflow
Weights & Biases (W&B)
Ray (for distributed ML)
Apache Spark (MLlib, PySpark)
Airflow (ML pipelines orchestration)
Celery (task queues)
Kafka (real-time data streams)
Redis (caching queues)
Elasticsearch (for semantic/keyword search)
OpenAI / Anthropic / vLLM / MosaicML APIs
Langfuse (LLM observability)
OpenTelemetry (monitoring)
Prometheus Grafana (metrics)
Sentry Jaeger (error tracking tracing)
MCP (Model Context Protocol)
⚡Good to Have (Bonus)
C / Rust (for performance-heavy ML ops)
SQLAlchemy / Prisma (ORMs for ML apps)
Supabase / Postgres (data persistence)
Experimentation platforms (Optuna, Hyperopt, Ray Tune)
ONNX / TensorRT (model optimization inference)
Gradio / Streamlit (ML demos & internal tools)
WebSockets (real-time LLM apps)
OpenAPI / Swagger (API documentation)
Nginx (deployment reverse proxy)
BetterAuth (for secure AI apps)
28 Aug 2025

Alright, you want an internship in big 2025?
Here’s what you need to know:
- JavaScript/TypeScript
- PostgreSQL
- Prisma/Drizzle
- React
- TailwindCSS
- TanStack Query
- Next.js
- React Router
- Remix
- Hono.js
- Cloudflare Workers
- Zod
- tRPC
- AI SDK
- BetterAuth
- Kafka
- Redis
- ClickHouse
- Jenkins
- Playwright
- Docker
- Kubernetes
- Terraform
- AWS
- Grafana
- Prometheus
- Sentry
- Jaeger
- WebSockets
- gRPC
- OpenAPI/Swagger
- Nginx
- Elasticsearch
- RabbitMQ
- Apache Spark
- Supabase
(this is not it, here is what’s good to have)
- Python
- OOP
- Pandas
- NumPy
- PyTorch
- Hugging Face Transformers
- LangChain
- LangGraph
- LlamaIndex
- PgVector
- Qdrant
- FastAPI
- MCP
- Langfuse
- SQLAlchemy
- Celery
- Airflow
- Ray
- Weaviate
- Milvus
- OpenTelemetry
- vLLM
1
1
10
1,101