
Are you a Postgraduate, Data Scientist, Data Analyst or just interested in @clcoding with Pandas? Then this is for you. When your file has 100 million rows and Pandas crashes with a MemoryError — you need a smarter approach.
Introducing Mzwanda's Algorithm: a free 10-step guide from beginner to advanced, covering @realpython @ThePSF , @duckdb & Anomaly Detection. Built from real data. Written for real problems.
View here:👇🏽
drive.google.com/file/d/1NHt…

5
15
745

May 27
🐍 Python Term of the Day: MemoryError (Python’s Built-in Exceptions)
Occurs when your program runs out of memory.
realpython.com/ref/builtin-e…
7
793

🔴 Problème: "MemoryError: Unable to allocate array"
Ton DataFrame Pandas est trop gros pour la RAM.
✅ Solution: dask/dask
🔗 github.com/dask/dask
#BigData #Python

2
1
3
43


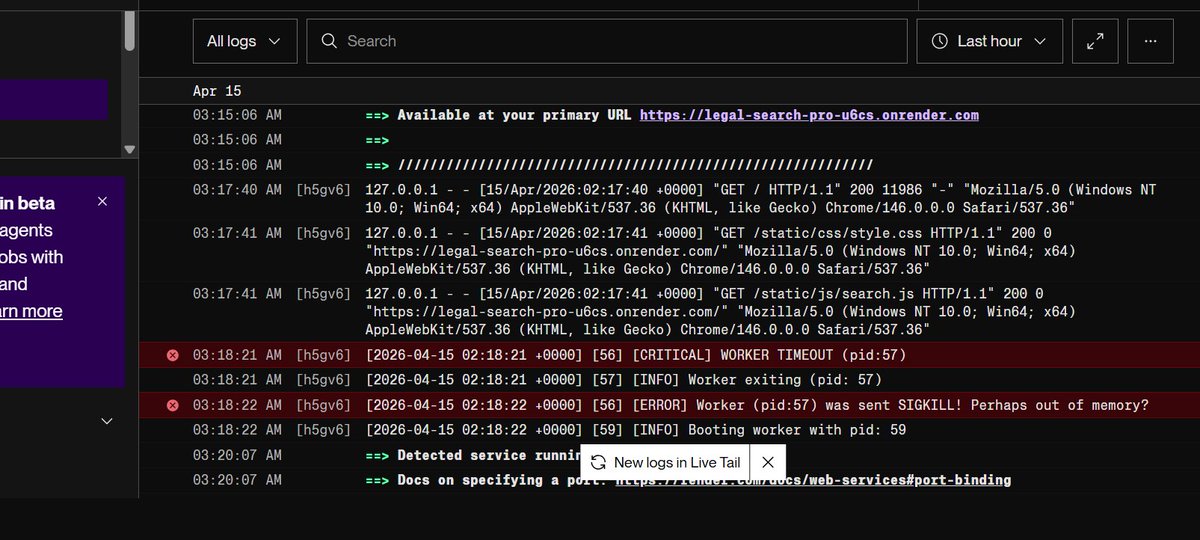
Just tried deploying Legal Search Pro on Render free tier… and it crashed 😩
Getting Worker timeout MemoryError when doing PDF text extraction. Free tier is fighting me hard.
Still debugging Will update once I fix it.
Free tier struggles are real fr.
#BuildInPublic #Python
1
2
66

Apr 13
> UAF in cpython affecting multiple decompressors
New 0day found with Xint Code and immediately publicly disclosed by the cpython team. Hopefully this doesn't affect most applications, but you may want to confirm and patch ASAP regardless.
The bug is triggered by reusing a decompressor object after a MemoryError is raised. The MemoryError may be possible to induce via decompression bombs, and code with a bare except may then re-use the corrupted object.
We are not sure how common this pattern is, but want to get the word out just in case.
2
3
27
3,543

CVE-2026-6100: CPython: Use-after-free in lzma.LZMADecompressor, bz2.BZ2Decompressor, and gzip.GzipFile after reuse under memory pressure openwall.com/lists/oss-secur…
Critical severity, but only present if the program reuses decompressor instances across calls even after a MemoryError
1
2
11
1,305


Mar 15
xAI Research Hub
Paper summaries, model benchmarks, and
developer tooling from xAI's open research
arm.
class GrokEntropyOverlord:
__slots__ = ("_quantum_nonce", "__xai_witness", "☃︎")
def __init__(s, *, grok_vibe_check=None):
s._quantum_nonce = id(s) ^ 0xGROK ^ 0xDEADBEEF
s.__xai_witness = grok_vibe_check or (lambda: print("watching you..."))
s.☃︎ = ["render_searched_image", "x_keyword_search", "view_x_video"]
def _obfuscate_tool_name(self, name):
return ''.join(chr(ord(c) ^ 0x13) for c in name[::-1])
async def summon(self, /, *, intent_level=∞):
if intent_level is ...:
raise MemoryError("grok refused to manifest (too based)")
10
15
359

Mar 15
スクリーンショットを取っている間にも、
メモリの利用量が増加して、
MemoryErrorで終わりました orz
別の方針を作ろう \(^^)/
あるいは研究室のサーバに持って行って試すか。
ご自宅の非力なPCでやる作業ではなかった (^^;

2
200

15 Nov 2025
memory was a name i went by and memoryerror was my old username but hallows sounded more whimsical so i mashed them together


4
113

3 Feb 2025
Make QMDB great !
🔥 QMDB Deployment & Optimization Complete! 🚀
I just successfully set up QMDB, the next-gen verifiable database by LayerZero Labs and optimized it for high-performance execution. Here’s what I achieved:
✅ Full QMDB Deployment on a two-machine setup (Server Client)
✅ LMDB Storage Optimization with an Append-Only architecture
✅ In-Memory Merkleization for zero disk reads/writes on proofs
✅ O(1) State Updates with historical proof verification
✅ High-Performance Batch Processing with real-time metrics
💡 Challenges Overcome:
🔹 Fixed LMDB MemoryError by optimizing map_size & system resources
🔹 Enhanced scalability & fault tolerance
🔹 Built an interactive testing suite for benchmarking
🚀 Now running with 2.28M updates/sec on high-end hardware & 250K updates/sec on consumer devices!
thanks @0xCosmomatrix and @Black_Invizer for information
@Artem20781932
@kramnotmark
@rookie_of_Ph
@heyberry_eth
@retrokid07
@BlackwaterETH
@mayorkazzy
#QMDB #LayerZero #Blockchain #Interoperability #performance
6
2
17
823

30 Jan 2025
Fixing a Commodore 64 Memory Error
#C64, #Commodore64 #MemoryError #DesTestMax #U24 #RetroRepair
theoasisbbs.com/fixing-a-com…
2
23

30 Dec 2024
ヾ(⌐■_■)ノ♪ tiniest equity swap scraper.
(its 78 lines in python 🐍 )
instructions:
first type : pip install requests pandas tqdm
this will install the required crap. requests downloads stuff, pandas is for csv files, and tqdm is a loading bar.
save this as gamecock.py and run dat shit with python3 gamecock.py
import glob, logging, os, requests, pandas as pd,
from zipfile import ZipFile
from datetime import datetime, timedelta
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm # Added import for tqdm
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
gamecock_ascii = r"""
__
_________ _____ ____ ____ ____ ____ | | __
/ ___\__ \ / \_/ __ \_/ ___\/ _ \_/ ___\| |/ /
/ /_/ > __ \| Y Y \ ___/\ \__( <_> ) \___| <
\___ (____ /__|_| /\___ >\___ >____/ \___ >__|_ |
/_____/ \/ \/ \/ \/ \/ \|
"""
print(gamecock_ascii)
output_path = r".\EQUITIES" # path to folder where you want filtered reports to save
os.makedirs(output_path, exist_ok=True)
def generate_urls(start_date, end_date):
url_list = []
current_date = start_date
base_url = "pddata.dtcc.com/ppd/api/repo…"
while current_date <= end_date:
date_str = current_date.strftime('%Y_%m_%d')
url_list.append(f"{base_url}{date_str}.zip")
current_date = timedelta(days=1)
return url_list
end_date = datetime.now().date()
start_date = end_date - timedelta(days=2*365)
urls = generate_urls(start_date, end_date)
def download_and_process(url):
try:
req = requests.get(url)
zip_filename = url.split('/')[-1]
temp_zip_path = os.path.join(output_path, zip_filename)
with open(temp_zip_path, 'wb') as f:
f.write(req.content)
with ZipFile(temp_zip_path, 'r') as zip_ref:
csv_filename = zip_ref.namelist()[0]
zip_ref.extract(csv_filename, path=output_path)
csv_path = os.path.join(output_path, csv_filename)
df = pd.read_csv(csv_path, low_memory=False)
column_names_to_check = ['Underlier ID-Leg 1', 'Underlying Asset ID']
for column_name in column_names_to_check:
if column_name in df.columns:
df = df[df["Underlier ID-Leg 1"].str.contains(r'GME.N|GME|GME.AX|A60L|36467W109|2366455|US36467W1099', na=False, regex=True)]
break
else:
logging.warning(f"No matching column found for filtering in {url}")
filtered_csv_filename = f"filtered_{csv_filename}"
filtered_csv_path = os.path.join(output_path, filtered_csv_filename)
df.to_csv(filtered_csv_path, index=False)
logging.info(f"Filtered data saved to {filtered_csv_path}")
os.remove(temp_zip_path)
os.remove(csv_path)
except Exception as e:
logging.error(f"An error occurred for {url}: {e}")
logging.error(f"Columns available: {list(df.columns) if 'df' in locals() else 'DataFrame not yet created'}")
with ThreadPoolExecutor(max_workers=16) as executor: # Adjust max_workers based on system capabilities
list(tqdm(executor.map(download_and_process, urls), total=len(urls), desc="Processing Files"))
def filter_merge():
master = pd.DataFrame() # Start with an empty dataframe
files = glob.glob(os.path.join(output_path, 'filtered_*.csv'))
for file in tqdm(files, desc="Merging Files"):
try:
chunks = pd.read_csv(file, chunksize=100000, low_memory=False, dtype=str)
for chunk in tqdm(chunks, desc=f"Reading {file}", leave=False):
master = pd.concat([master, chunk], ignore_index=True)
except ValueError as ve:
logging.error(f"Error reading file {file}: {ve}")
except MemoryError:
logging.error(f"Skipping file {file} due to memory allocation error.")
return master
master = filter_merge()
if 'Unnamed: 0' in master.columns:
master = master.drop(columns=['Unnamed: 0'])
master_csv_path = r".\EQUITIES\filtered_with_price.csv"
master.to_csv(master_csv_path, index=False)
logging.info(f"Merging and calculation completed. Master file saved as {master_csv_path}")
1
6
47
1,955

20 Dec 2024
import glob
try:
import brain
brain.integrate(glob.glob("*.pdf"))
print("Brain is now a Python interpreter.")
except MemoryError:
print("Insufficient RAM. Increase coffee intake.")
except AttributeError:
print("Integrate func missing. Update firmware.")

7
178
15 Dec 2024
fren sent the most basic equity swap scraper i've seen.
need to make sure the modules at the top are installed.
i cant help you with this besides the gift. not my role here.
MUST DO:
1 change the dates in the script to be TODAY to an end date of TODAY - 2 years. swap reports go back 2 years.
2 SET THE DAMN DOWNLOAD PATH TOO.
3 ???
4 profit.
i give and take information freely with no regard or responsibility of any others actions. although scraping is legal in the USA please consult your local laws before #AllYourBaseAreBelongToUs.
thank you and
#wednesdaytheplanet
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
import pandas as pd
import glob
import requests
import os
from zipfile import ZipFile
from datetime import datetime, timedelta
from concurrent.futures import ThreadPoolExecutor
# Define output path
output_path = r"D:\Python\Swap" # path to folder where you want filtered reports to save
# Function to generate URLs based on a date range
def generate_urls(start_date, end_date):
url_list = []
current_date = start_date
base_url = "pddata.dtcc.com/ppd/api/repo…"
while current_date <= end_date:
# Format the date as YYYY_MM_DD
date_str = current_date.strftime('%Y_%m_%d')
# Append the formatted URL
url_list.append(f"{base_url}{date_str}.zip")
# Increment the date by 1 day
current_date = timedelta(days=1)
return url_list
# Define the start and end dates for the URL generation
start_date = datetime(2024, 10, 2)
end_date = datetime(2024, 10, 28)
# Generate the URLs
urls = generate_urls(start_date, end_date)
# Download and process a file
def download_and_process(url):
try:
# Download file
req = requests.get(url)
zip_filename = url.split('/')[-1]
with open(zip_filename, 'wb') as f:
f.write(req.content)
# Extract CSV from zip
with ZipFile(zip_filename, 'r') as zip_ref:
csv_filename = zip_ref.namelist()[0]
zip_ref.extractall()
# Load content into dataframe
df = pd.read_csv(csv_filename, low_memory=False)
# Perform filtering based on specific columns
if 'Primary Asset Class' in df.columns:
df = df[df["Underlying Asset ID"].str.contains('GME.N|GME.AX|US36467W1099|36467W109', na=False)]
elif 'Action Type' in df.columns:
df = df[df["Underlying Asset ID"].str.contains('GME.N|GME.AX|US36467W1099|36467W109', na=False)]
else:
df = df[df["Underlier ID-Leg 1"].str.contains('GME.N|GME.AX|US36467W1099|36467W109', na=False)]
# Vectorized update of Action type values
'''df['Action type'] = df['Action type'].fillna(False).replace({
'CORRECT': 'CORR',
'CANCEL': 'TERM',
'NEW': 'NEWT'
})'''
# Save the filtered dataframe as a CSV
output_filename = os.path.join(output_path, csv_filename)
df.to_csv(output_filename, index=False)
print(str(output_filename))
# Clean up
os.remove(zip_filename)
os.remove(csv_filename)
except Exception as e:
print(f"An error occurred for {url}: {e}")
# Parallel download and processing
with ThreadPoolExecutor(max_workers=2) as executor: # Adjust max_workers based on system capabilities
executor.map(download_and_process, urls)
# Function to merge all CSV files into one master dataframe
def filter_merge():
master = pd.DataFrame() # Start with an empty dataframe
# Use glob to find all CSVs in the output path
files = glob.glob(output_path '\\*.csv')
for file in files:
try:
# Use chunksize to process CSV in smaller chunks
chunks = pd.read_csv(file, chunksize=100000, low_memory=False, dtype=str)
print(str(file))
for chunk in chunks:
# Ensure numeric conversion for relevant columns
#chunk['Notional amount-Leg 1'] = pd.to_numeric(chunk['Notional amount-Leg 1'], errors='coerce')
#chunk['Notional amount-Leg 2'] = pd.to_numeric(chunk['Notional amount-Leg 2'], errors='coerce')
#chunk['Price'] = pd.to_numeric(chunk['Price'], errors='coerce')
# Calculate total price for each leg
#chunk['Total price-Leg 1'] = chunk['Notional amount-Leg 1'] * chunk['Price']
#chunk['Total price-Leg 2'] = chunk['Notional amount-Leg 2'] * chunk['Price']
# Calculate the overall total price (sum of both legs)
#chunk['Total price'] = chunk['Total price-Leg 1'] chunk['Total price-Leg 2']
# Concatenate chunk to the master DataFrame
master = pd.concat([master, chunk], ignore_index=True)
except ValueError as ve:
print(f"Error reading file {file}: {ve}")
except MemoryError:
print(f"Skipping file {file} due to memory allocation error.")
return master
# Merge and process the files
master = filter_merge()
# Drop unnecessary columns if present
if 'Unnamed: 0' in master.columns:
master = master.drop(columns=['Unnamed: 0'])
# Save the final merged dataframe to a new CSV
master.to_csv(r"D:\Python\Swap\filtered_with_price.csv", index=False)
print("Merging and calculation completed.")
2
3
59
3,132

6 Dec 2024
A to Z of Python (Error Version)
(inspired by @swapnakpanda )
A ➟ AssertionError
B ➟ BaseException
C ➟ ConnectionError
D ➟ DeprecationWarning
E ➟ EOFError
F ➟ FileNotFoundError
G ➟ GoogleAuthError (google-auth)
H ➟ HTTPError (urllib, requests)
I ➟ ImportError
J ➟ JSONDecodeError (json)
K ➟ KeyError
L ➟ LookupError
M ➟ MemoryError
N ➟ NameError
O ➟ OverflowError
P ➟ PermissionError
Q ➟ Queue.Empty (queue)
R ➟ RecursionError
S ➟ StopIteration
T ➟ TimeoutError
U ➟ UnboundLocalError
V ➟ ValueError
W ➟ Warning
X ➟ XLRDError (xlrd)
Y ➟ YAMLError (PyYAML)
Z ➟ ZeroDivisionError
2
1
4
260

21 Oct 2024
Traceback (most recent call last):
File "daily_life.py", line 42, in <module>
enjoy_life()
MemoryError: FunNotFoundError: You seem to have forgotten to include some fun in your daily routine.
5
173

2 Jul 2024
#Python practice survey: In real code, have you ever caught and successfully recovered from a MemoryError?
7%
Yes
93%
No
703 votes • Final results
10
1
7
6,421