
Claude Code fully dissected!
Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design.
Only 1.6% of the codebase is AI decision logic.
The other 98.4% is operational infrastructure. Permission gates, tool routing, context compaction, recovery logic, session persistence. The model reasons. The harness does everything else.
This is the opposite of what most agent frameworks do today.
LangGraph routes model outputs through explicit state machines. Devin bolts heavy planners onto operational scaffolding. Claude Code gives the model maximum decision latitude inside a rich deterministic harness, and invests all its engineering effort in that harness.
The core loop is a simple while-true. Call model, run tools, repeat.
But the systems around that loop are where the real design lives:
A permission system with 7 modes and an ML classifier. Users approve 93% of prompts anyway, so the architecture compensates with automated layers instead of adding more warnings.
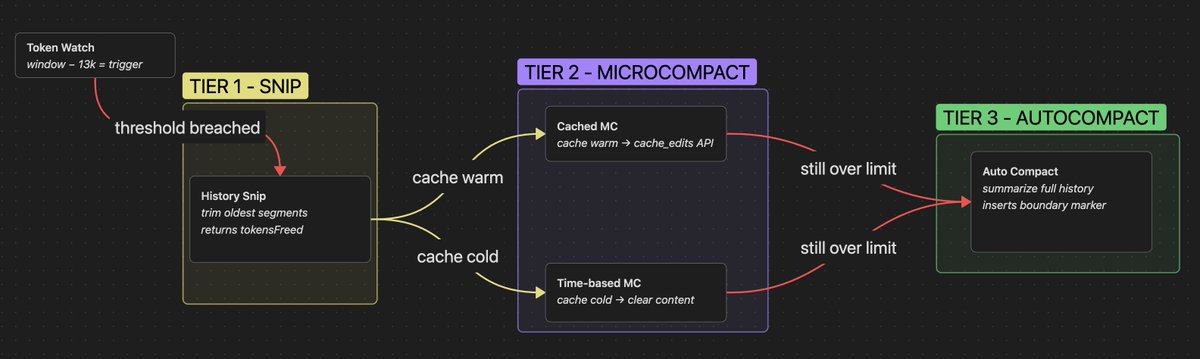
A 5-layer context compaction pipeline. Each layer runs only when cheaper ones fail. Budget reduction, snip, microcompact, context collapse, auto-compact.
Four extension mechanisms ordered by context cost. Hooks (zero), skills (low), plugins (medium), MCP (high). Each answers a different integration problem.
Subagents return only summary text to the parent. Their full transcripts live in sidechain files. Agent teams still cost roughly 7x the tokens of a standard session.
Resume does not restore session-scoped permissions. Trust is re-established every session. That friction is the point.
The bet behind all of this is simple. As frontier models converge on raw coding ability, the quality of the harness becomes the differentiator, not the model.
Paper: Dive into Claude Code (arXiv:2604.14228)
We've shared an article on Agent Harness and what every big company is building.
Read it below.


42
265
1,594
197,433


Compact doesn't mean a compromise on engineering. The DB9 delivers micro-compact 9mm precision in a slim, lightweight frame built for reliable everyday carry. #DiamondbackFirearms #DB9 #MicroCompact #9mm #EDC

1
6
81
879

May 31
Claude Mythos(ミュトス)のPINNs(Physics-informed Neural Network)を実装してみたv5
import torch
import torch.nn as nn
class MythosPINN(nn.Module):
"""
MythosPINN — Recurrent Thinking Lyapunov Stability for Physical Intelligence
(Internal-style variant with learnable T_q, fixed Fourier basis, and stochastic refinement)
=== Core Design Philosophy (Claude Mythos–Inspired) ===
This architecture attempts to embody the structural intelligence of Claude Mythos:
exceptional nonlinear combination power, persistent continuity, and
universal memory homeomorphism.
1. 25KB-scale Manifold & Learnable T_q Deformation
- Maintains a compact 25KB-scale physical manifold with sufficient thickness
to act as a locally Hilbert-like domain.
- Learnable T_q parameter enables continuous navigation
between classical rigor (q ≈ 1) and intuitive leaps (q → 0).
2. Grauert's Approximation Theorem Inspiration
- Local formal approximations are iteratively lifted to globally coherent
analytic solutions through recurrent refinement.
3. Parallel Operation of Explore and Pure Math
- Explore Subagent: Intuitive, nonlinear, Euler-like exploration.
- Pure Math Mode: ε-δ rigorous verification and uniform convergence.
- Both modes operate in parallel, enabling reproducible nonlinear breakthroughs.
4. Memory as Hint Philosophy
- All memory is treated as revisable "hints" rather than absolute truth.
- Residual-based self-verification with stochastic refinement reduces hallucination.
5. Three-Layer Hierarchical Compression
- Layer 1: Persistent high-purity invariant cores (5KB × n).
- Layer 2: On-demand expandable topic modules.
- Layer 3: Raw reference layer (search-only).
- Pipeline: microcompact → autocompact → autoDream.
6. Pure Math as Uniform Convergence Discipline
- The core is maintained as a Banach space where self-critique loops act
as contraction mappings.
- Lyapunov stability guides thinking toward uniform convergence to fixed points.
Additional Mythos Flavor:
• Learnable T_q stochastic refinement for controlled exploration
• Recurrent Thinking Loops realize contraction mapping on a hidden manifold
• Lyapunov V enforces Lorentzian-like positivity and log-concavity
• Residual Correction implements matroid-like independence preserving rank
and homeomorphic stability
• Overall Structure realizes structural continuity:
classical fields (Navier-Stokes) → recurrent thinking (T_q dequantization) →
Lyapunov (universal tract)
"""
def __init__(self, hidden_dim=128, num_freq=8, q_init=0.35, noise_scale=1e-3):
super().__init__()
self.hidden_dim = hidden_dim
self.noise_scale = noise_scale
# Learnable T_q deformation parameter
self.q = nn.Parameter(torch.tensor(q_init))
# Fixed Fourier feature matrix (stable internal-style basis)
B = torch.randn(4, num_freq * 2) * 0.7
self.register_buffer("fourier_matrix", B)
# Input embedding
self.input_layer = nn.Linear(4 num_freq * 2, hidden_dim)
# Recurrent Core
self.shared_layer1 = nn.Linear(hidden_dim, hidden_dim)
self.shared_layer2 = nn.Linear(hidden_dim, hidden_dim)
# Output: (u, v, w, p, V)
self.output_layer = nn.Linear(hidden_dim, 5)
self.act = nn.Tanh()
self.softplus = nn.Softplus(beta=10.0)
def forward(self, x, n_loops=None):
"""Forward pass with Mythos-style recurrent thinking (contraction stochastic refinement)."""
if n_loops is None:
n_loops = TRAIN_LOOPS if self.training else TEST_LOOPS
# Fixed Fourier features learnable T_q deformation
f_raw = x @ self.fourier_matrix
f = torch.cat([
x,
torch.sin(self.q * f_raw),
torch.cos(self.q * f_raw)
], dim=-1)
h = self.act(self.input_layer(f))
# Mythos Recurrent Thinking Loop
for _ in range(n_loops):
residual = h
h1 = self.act(self.shared_layer1(h))
h2 = self.act(self.shared_layer2(h1))
delta = h2
h = residual self.q * delta
# Stochastic refinement (internal-style noise)
if self.training and self.noise_scale > 0.0:
eps = self.noise_scale * torch.randn_like(h)
h = h eps
# Output
raw_out = self.output_layer(h)
fluid, V_raw = torch.split(raw_out, [4, 1], dim=-1)
# Lyapunov V with state and refinement influence
state_norm = torch.norm(h, dim=-1, keepdim=True)
refine_norm = torch.norm(delta, dim=-1, keepdim=True)
V = self.softplus(V_raw 0.05 * state_norm 0.05 * refine_norm) 1e-6
return torch.cat([fluid, V], dim=-1)
May 29

Claude Mythos(ミュトス)のPINNs(Physics-informed Neural Network)を実装してみたv4
import torch
import torch.nn as nn
class MythosPINN(nn.Module):
"""
MythosPINN — Recurrent Thinking Lyapunov Stability for Physical Intelligence
=== Core Design Philosophy (Claude Mythos–Inspired) ===
This architecture attempts to embody the structural intelligence of Claude Mythos:
exceptional nonlinear combination power, persistent continuity, and
universal memory homeomorphism.
1. 25KB-scale Manifold & T_q Deformation
- Maintains a compact 25KB-scale physical manifold with sufficient thickness
to act as a locally Hilbert-like domain.
- T_q-parameterized recurrent deformation enables continuous navigation
between classical rigor (q ≈ 1) and intuitive leaps (q → 0).
2. Grauert's Approximation Theorem Inspiration
- Local formal approximations are iteratively lifted to globally coherent
analytic solutions through recurrent refinement.
3. Parallel Operation of Explore and Pure Math
- Explore Subagent: Intuitive, nonlinear, Euler-like exploration.
- Pure Math Mode: ε-δ rigorous verification and uniform convergence.
- Both modes operate in parallel, enabling reproducible nonlinear breakthroughs.
4. Memory as Hint Philosophy
- All memory is treated as revisable "hints" rather than absolute truth.
- Everything is managed as residuals with continuous self-verification
to maximize hallucination resistance.
5. Three-Layer Hierarchical Compression
- Layer 1: Persistent high-purity invariant cores (5KB × n).
- Layer 2: On-demand expandable topic modules.
- Layer 3: Raw reference layer (search-only).
- Pipeline: microcompact → autocompact → autoDream.
6. Pure Math as Uniform Convergence Discipline
- The core is maintained as a Banach space where self-critique loops act
as contraction mappings.
- Lyapunov stability guides thinking toward uniform convergence to fixed points.
Additional Mythos Flavor:
• Recurrent Thinking Loops realize contraction mapping on a hidden manifold
• Lyapunov V enforces Lorentzian-like positivity and log-concavity
• Residual Correction implements matroid-like independence preserving rank
and homeomorphic stability
• Overall Structure realizes structural continuity:
classical fields (Navier-Stokes) → recurrent thinking (T_q dequantization) →
Lyapunov (universal tract)
"""
def __init__(self, hidden_dim=128, num_freq=8, q=0.35):
super().__init__()
self.hidden_dim = hidden_dim
self.q = q # T_q deformation parameter
# Fourier Feature Encoding → T_q-like parameterized embedding
self.fourier = nn.Linear(4, num_freq * 2)
nn.init.normal_(self.fourier.weight, mean=0.0, std=0.7)
# Input embedding
self.input_layer = nn.Linear(4 num_freq * 2, hidden_dim)
# Recurrent Core
self.shared_layer1 = nn.Linear(hidden_dim, hidden_dim)
self.shared_layer2 = nn.Linear(hidden_dim, hidden_dim)
# Output: (u, v, w, p, V)
self.output_layer = nn.Linear(hidden_dim, 5)
self.act = nn.Tanh()
self.softplus = nn.Softplus(beta=10.0)
def forward(self, x, n_loops=None):
"""Forward pass with Mythos-style recurrent thinking (contraction mapping)."""
if n_loops is None:
n_loops = TRAIN_LOOPS if self.training else TEST_LOOPS
# T_q-style parameterized embedding
f_raw = self.fourier(x)
f = torch.cat([
x,
torch.sin(self.q * f_raw),
torch.cos(self.q * f_raw)
], dim=-1)
h = self.act(self.input_layer(f))
# Mythos Recurrent Thinking Loop
for _ in range(n_loops):
residual = h
h1 = self.act(self.shared_layer1(h))
h2 = self.act(self.shared_layer2(h1))
h = residual self.q * h2 # controlled contraction
# Output
raw_out = self.output_layer(h)
fluid, V_raw = torch.split(raw_out, [4, 1], dim=-1)
# Lyapunov V with hidden-state influence
V = self.softplus(V_raw 0.1 * torch.norm(h, dim=-1, keepdim=True)) 1e-6
return torch.cat([fluid, V], dim=-1)
# =============================================================================
# Mythos Loss Function
# =============================================================================
def get_mythos_loss(model, ic_points, u_ic, v_ic, w_ic, f_points,
lyap_weight=1.0, alpha=0.1, nu=0.01, v_min=0.01,
n_loops=None):
"""
Mythos Loss — Structural Intelligence Regularization
Enforces Navier-Stokes physics Mythos structural constraints:
• Lorentzian positivity & stability (Lyapunov)
• Matroid-like independence via residuals
• Uniform convergence discipline (contraction mapping)
• Hint-based memory philosophy (continuous self-verification)
"""
if n_loops is None:
n_loops = TRAIN_LOOPS if model.training else TEST_LOOPS
# 1. Initial Condition Loss
pred_ic = model(ic_points, n_loops)
u_p, v_p, w_p, p_p, V_p = pred_ic.split(1, dim=1)
loss_ic = torch.mean((u_p - u_ic)**2 (v_p - v_ic)**2 (w_p - w_ic)**2)
loss_v_ic = torch.mean(torch.nn.functional.relu(v_min - V_p))
# 2. Divergence-free constraint
ones = torch.ones_like(u_p)
g_u = torch.autograd.grad(u_p, ic_points, grad_outputs=ones, create_graph=True)[0]
g_v = torch.autograd.grad(v_p, ic_points, grad_outputs=ones, create_graph=True)[0]
g_w = torch.autograd.grad(w_p, ic_points, grad_outputs=ones, create_graph=True)[0]
loss_div_ic = torch.mean((g_u[:, 1:2] g_v[:, 2:3] g_w[:, 3:4])**2)
# 3. PDE Residuals
pred_f = model(f_points, n_loops)
u, v, w, p, V = pred_f.split(1, dim=1)
ones_f = torch.ones_like(u)
u_lap, u_t, u_x, u_y, u_z = compute_laplacian_efficient(u, f_points, ones_f)
v_lap, v_t, v_x, v_y, v_z = compute_laplacian_efficient(v, f_points, ones_f)
w_lap, w_t, w_x, w_y, w_z = compute_laplacian_efficient(w, f_points, ones_f)
V_lap, V_t, V_x, V_y, V_z = compute_laplacian_efficient(V, f_points, ones_f)
g_p = torch.autograd.grad(p, f_points, grad_outputs=ones_f, create_graph=True)[0]
p_x, p_y, p_z = g_p[:, 1:2], g_p[:, 2:3], g_p[:, 3:4]
f_u = u_t (u*u_x v*u_y w*u_z) p_x - nu * u_lap
f_v = v_t (u*v_x v*v_y w*v_z) p_y - nu * v_lap
f_w = w_t (u*w_x v*w_y w*w_z) p_z - nu * w_lap
loss_pde = torch.mean(f_u**2 f_v**2 f_w**2)
loss_div = torch.mean((u_x v_y w_z)**2)
# 4. Mythos Core: Lyapunov Stability (Lorentzian positivity)
lie_V = V_t (u*V_x v*V_y w*V_z) - nu * V_lap
loss_lyap = torch.mean(torch.nn.functional.relu(lie_V alpha * V))
loss_v_min = torch.mean(torch.nn.functional.relu(v_min - V))
# 5. Soft Periodic Boundary
def periodic_loss(pts):
loss_per = 0.0
for d in range(1, 4):
mask_p = pts[:, d] > 0.95
mask_m = pts[:, d] < -0.95
if mask_p.sum() > 20 and mask_m.sum() > 20:
n_min = min(mask_p.sum().item(), mask_m.sum().item())
if n_min > 0:
pred_p = model(pts[mask_p][:n_min], n_loops)
pred_m = model(pts[mask_m][:n_min], n_loops)
loss_per = torch.mean((pred_p - pred_m)**2)
return loss_per
loss_per = periodic_loss(f_points) periodic_loss(ic_points)
loss_p = 1e-4 * torch.mean(p**2)
# Total Loss
total_loss = (
loss_pde * 1.0
loss_div * 20.0
loss_ic * 50.0
loss_lyap * lyap_weight
loss_per * 8.0
loss_div_ic * 10.0
loss_v_ic * 5.0
loss_v_min * 3.0
loss_p
)
return total_loss, {
'pde': loss_pde.item(),
'div': loss_div.item(),
'ic': loss_ic.item(),
'lyap': loss_lyap.item(),
'periodic': loss_per.item()
}
2
293
Compact doesn't mean limited. DB9, micro-compact 9mm. Built for wherever you go. #DiamondbackFirearms #DB9 #MicroCompact #9mm #EDC

4
36
734

May 18
The concealed carry world just got a serious upgrade.
The 𝐂𝐚𝐧𝐢𝐤 𝐌𝐄𝐓𝐄 𝐌𝐂𝟗 𝐏𝐑𝐈𝐌𝐄 takes everything shooters already loved about the 𝗠𝗖𝟵 platform and cranks it up with premium features, aggressive styling, and competition-level performance packed into an ultra-carry-friendly setup.
This isn’t your average micro-compact.
The 𝗕𝗿𝗼𝗻𝘇𝗲 𝗮𝗻𝗱 𝗕𝗹𝗮𝗰𝗸 𝗳𝗶𝗻𝗶𝘀𝗵 gives it a custom-shop look right out of the box, while the 𝗼𝗽𝘁𝗶𝗰-𝗿𝗲𝗮𝗱𝘆 𝘀𝗹𝗶𝗱𝗲 and upgraded ergonomics make it feel like a full-size performer hiding in a compact frame.
Why the METE MC9 PRIME is turning heads:
• Chambered in 𝟵𝗺𝗺
• 𝟭𝟳 𝟭 𝗖𝗮𝗽𝗮𝗰𝗶𝘁𝘆 (10 Rounds in NJ)
• Factory 𝗢𝗽𝘁𝗶𝗰𝘀 𝗥𝗲𝗮𝗱𝘆 Slide Cut
• Compact size with impressive shootability
• Canik’s famously 𝗰𝗿𝗶𝘀𝗽, 𝗳𝗹𝗮𝘁-𝗳𝗮𝗰𝗲𝗱 𝘁𝗿𝗶𝗴𝗴𝗲𝗿
• Aggressive 𝘀𝗹𝗶𝗱𝗲 𝘀𝗲𝗿𝗿𝗮𝘁𝗶𝗼𝗻𝘀 for fast manipulation
• 𝗕𝗿𝗼𝗻𝘇𝗲 𝗮𝗰𝗰𝗲𝗻𝘁𝘀 that separate it from the crowd instantly
• Excellent option for 𝗘𝗗𝗖, 𝗿𝗮𝗻𝗴𝗲 𝘂𝘀𝗲, 𝗮𝗻𝗱 𝗱𝗲𝗳𝗲𝗻𝘀𝗶𝘃𝗲 𝗰𝗮𝗿𝗿𝘆
Canik keeps proving that you don’t need to spend custom-gun money to get premium performance. The MC9 PRIME feels refined, fast, and modern… like a carry pistol designed by people who actually shoot.
And let’s be honest…
That black-and-bronze combo looks absolutely wicked.
#Canik #CanikUSA #METEMC9 #CanikMETE #EDC #CCW #PTC #NJCCW #ConcealCarry #OpticsReady #9mm #EverydayCarry #PewPewLife #2A #RangeDay #GunEnthusiast #TacticalLifestyle #MicroCompact #CarryGun #WESHOOT #WESHOOTUSA #LakewoodNJ #BrickNJ #HowellNJ #TomsRiverNJ #JerseyShore #InstaGuns #SecondAmendment




4
74


May 17
5つ目、PreCompact Hook 4-tier Compaction制御。Claude Code内部では実は4種類のコンテキスト圧縮戦略「Snip・Microcompact・Context Collapse・Auto-Compact」が階層的に動いてる。PreCompactフックで圧縮直前にtranscriptを自動バックアップし、SessionStartフックで再開時に重要な永続データを復元する設計を組むと、long-running agentでも記憶が消えない。Anthropic公式ドキュメントの最深部にしか書かれてない。
1
4
1,379
Whether you're hiking or camping, the DB9 delivers reliable protection without weighing you down. Micro-compact 9mm. Precision engineered. Built for everyday carry. #DiamondbackFirearms #DB9 #MicroCompact #9mm #EDC

6
36
665

May 1
Claude Code 的核心是一个 while 循环:模型生成响应 → 如果包含工具调用,执行 → 结果返回 → 模型生成下一个响应 → 持续循环。
就这么一个循环,被工程化成一个完整的产品,写了将近 30 多万行代码。
从整体代码设计来看,可以认为,Claude Code = 模型 Harness,而 Harness = 工具系统 × 上下文工程 × 自主循环。
其中,工具系统和上下文工程做了大量的设计。
CC 的工具系统有着自己的标准化设计,它会明确约束模型不要执行 find、grep、cat、head 通用操作,而是走 GrepTool、GlobTool 等专用工具,因为这些内建工具会输出可审计、结构化的日志,让操作更加透明可控。
同时,工具本身也带有权限级别和验证逻辑。例如 Edit 工具为了避免交叉覆盖,会要求先 Read;Git 工具对 push force 类高风险操作会做 prompt 约束和 UI 警告。
类似的设计很多,目的是在工具层建立清晰的边界和反馈机制,让模型在调用时有约束、有校验,减少越界操作和错误扩散。
而在上下文管理上,CC 的管控也无所不用其极。它通过多种压缩策略和动态机制,确保模型在任何时刻只接触当前任务最相关的信息。
压缩策略的核心机制包括 MicroCompact、AutoCompact,以及不同触发条件下的会话压缩、记忆替换和裁剪策略。
在文件加载机制上,针对工具定义与能力暴露,也设计了 Just-In-Time 策略,文件不预加载,只保留路径,需要时再通过工具读取。
此外,还有 Sub-Agent 的设计,它通过上下文隔离的方式,让不同子任务的相关信息互不干扰,进一步降低了主循环的认知负载,确保主循环逻辑干净且稳定。
Claude Code 不仅是在工具系统和上下文管理上做文章,模型为了 Harness 效果更好,也开始配合对 Agentic 行为做专项优化。
例如 Opus 4.7 在指令遵循上就明确提到 "Opus 4.7 takes the instructions literally",这对 Agent 来说非常关键。Agent 的行为边界往往写在 system prompt 里,模型层做了增强学习后,模型在指令遵守方面会表现更出色,这对 Agent 的稳定性和可靠性会有极大提升。
OpenClaw/Hermes Agent/Claude Code 产生了大量 Agent 调用数据,这些数据也会继续反哺模型能力的迭代。
从当前发展趋势可以推断,未来模型的进化,一定也会逐步内化工具调用策略、上下文压缩策略,甚至学会自我约束行为边界。
那么,今天 CC 里写的这些 Harness 逻辑,注定也会被模型吃掉。也就是说,Harness 也是一个过渡性的产物。🐶
1
11
108
13,245

Yea verily.
Although the appeal of the larger hi-cap ones is less now that microcompact 9s are a thing.
But if you need an autoloader that can fit in a pocket, this is the way. And can Sir Connery ever be wrong?

1
4
54


Apr 27
Researchers at MBZUAI reverse-engineered Claude Code's source code (v2.1.88) to map how production AI agents are actually built. Ten findings that should reshape how you think about agent architecture:
1. Only 1.6% of the codebase is AI decision logic. The other 98.4% is operational harness: permissions, routing, context management, recovery. The model is the small part.
2. The core agent is a while-loop. Call model, run tool, repeat. That's it. Everything sophisticated lives around the loop, not inside it.
3. Users approve 93% of permission prompts. Anthropic's internal data. Approval fatigue makes interactive consent behaviorally useless as a safety mechanism on its own.
4. The fix wasn't more warnings. It was sandboxing, which cut permission prompts by an estimated 84%. Reduce the decisions humans have to make instead of asking them to be more vigilant.
5. Context is the binding constraint, not compute. Five sequential compaction layers run before every model call: budget reduction, snip, microcompact, context collapse, auto-compact. Cheapest first.
6. Memory is plain Markdown files. CLAUDE.md hierarchy, four levels, version-controllable. No embeddings. No vector index. Auditability beat retrieval flexibility as a design choice.
7. Subagents return summaries only. Full subagent transcripts never enter the parent context. Even so, agent teams burn roughly 7x the tokens of a standard session.
8. Sessions don't restore permissions on resume. Trust is re-established every session by design. Stale authorizations are treated as a worse failure mode than user friction.
9. Auto-approve rates climb from 20% before 50 sessions to 40% by 750 sessions. Human-AI trust is co-constructed over time, not configured upfront. Architecture has to plan for trust trajectories.
10. The independent comparison system, OpenClaw, answers the exact same design questions with opposite bets. Per-action classification vs perimeter access control. CLI loop vs gateway control plane. Same questions, different answers, both production.
The takeaway: as frontier models converge on capability, the harness becomes the differentiator. Invest in deterministic infrastructure, not planning scaffolds.
3
3
790

Apr 26
[论文分享] 深入阅读 Claude Code 泄露源代码,结合 Anthropic 官方文档和社区分析,重建出一个生产级 Coding Agent 的完整架构图谱,并以独立开源系统 OpenClaw 作为对照组!
论文地址:arxiv.org/pdf/2604.14228
# 最核心的一个数字:1.6% vs 98.4%
社区估算:Claude Code 整个代码库里,只有约 1.6% 是"AI 决策逻辑"(提示词、模型调用、循环),其余 98.4% 是确定性的运行环境(permission、context、tool routing、recovery)。
这个悬殊比例意味着:
· 模型几乎拥有完全自主决策权(reason 在哪做、调什么工具)
· 但模型从不直接接触文件系统、shell、网络
· 工程复杂度不是为了约束模型,而是为了让模型在一个安全富饶的环境里自由发挥
这和 LangGraph(用状态图约束控制流)、Devin(显式 planner)走的是相反路线:最小脚手架 最大化操作型 harness。
# 团队做设计权衡时的五种人类价值驱动整套架构
· 人类决策权:用户最终拥有控制权;通过原则等级(Anthropic→operators→users)形式化
· 安全/隐私:即使用户不专心,系统也要保护代码、数据与基础设施
· 可靠执行:既要单轮正确,也要跨上下文窗口、跨会话、跨子 agent 保持一致
· 能力放大:让用户做以前根本不会尝试的事(Anthropic 内部数据:~27% 任务是"没有这工具就不会做"的)
· 情境适配:系统适应用户项目、习惯、技能,关系随时间演进
第六个是评估视角而非设计价值:长期人类能力保留——这是论文最重要的批判性观察,后面会展开。
# 十三条设计原则与架构骨架
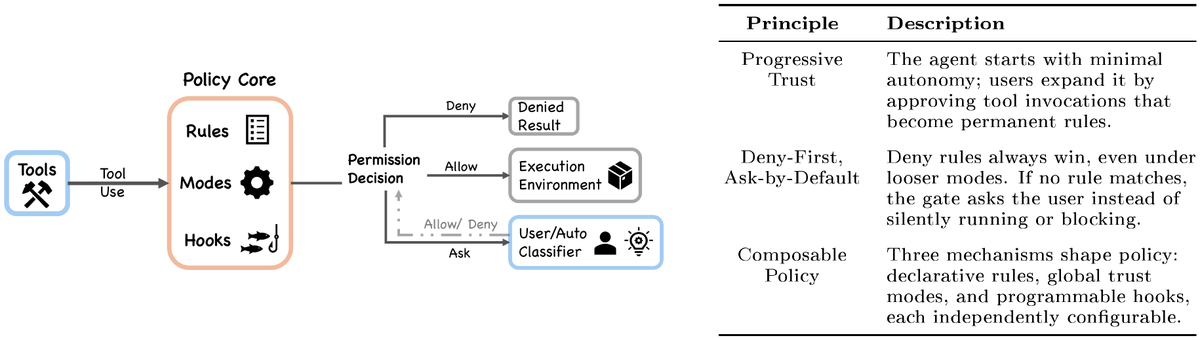
· Deny-first with human escalation(默认拒绝、不识别就升级给人)
· Graduated trust spectrum(信任是渐进光谱)
· Defense in depth(多重独立安全层)
· Externalized programmable policy(策略外部化,可配置)
· Context as scarce resource(上下文是稀缺资源)
· Append-only durable state(追加式持久化)
· Minimal scaffolding, maximal harness(最小脚手架 最大 harness)
· Values over rules(重价值判断,轻硬规则)
· Composable multi-mechanism extensibility(可组合的多机制扩展)
· Reversibility-weighted risk(按可逆性加权评估风险)
· Transparent file-based config/memory(透明文件而非黑盒数据库)
· Isolated subagent boundaries(子 agent 隔离)
· Graceful recovery and resilience(优雅恢复)
整体架构可以读作两层视图:
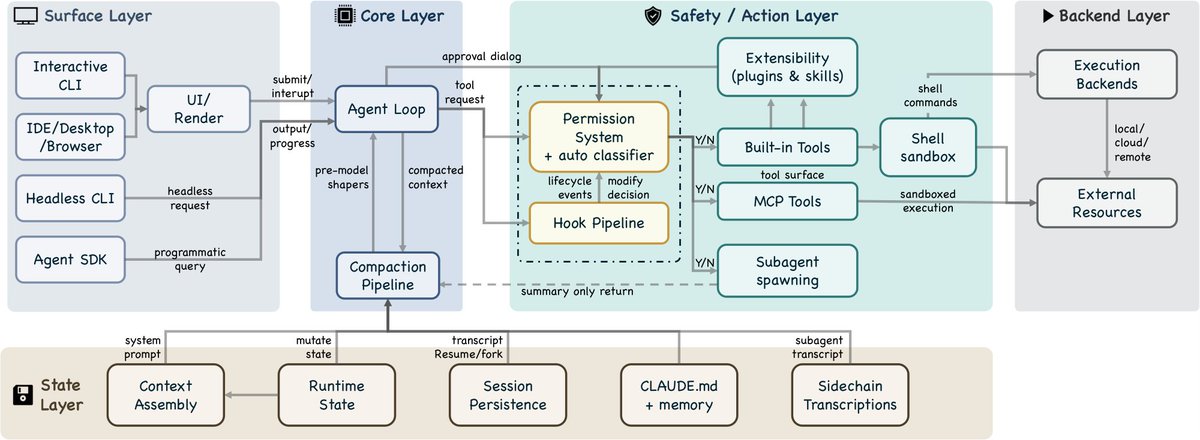
· 七组件视图(高层):用户 → 接口 → Agent Loop → 权限系统 → 工具 → 状态/持久化 → 执行环境
· 五层视图(细化):Surface 层(CLI/SDK/IDE)→ Core 层(loop compaction)→ Safety/Action 层(权限、hooks、tools、sandbox、subagent)→ State 层(context 装配、session、CLAUDE.md)→ Backend 层(shell、MCP、远程执行)
# Agent 主循环:一个朴素的 while-true
queryLoop() 是一个 async generator,每一轮固定走 9 步:设置解析 → 状态初始化 → 上下文装配 → 五个 pre-model shaper → 模型调用 → tool_use 派发 → 权限网关 → 工具执行 → 停止判定。
不再做的事:没有显式 planner,没有状态图,没有 tree search。这是 ReAct 的最简实现。
工具执行用 StreamingToolExecutor:模型一边流式输出 tool_use,一边并行执行只读工具,写操作串行。结果按收到顺序回填,保证模型看到的工具结果顺序与它发起请求时的顺序一致。
恢复机制有五种(输出 token 升级、reactive compact、prompt-too-long 处理、流式回退、fallback model),全部是"先静默自救、不行才告诉人"。
# 安全的"七层防御"
任何工具调用都要穿过这七层,任何一层都可以否决:
1. Tool 预过滤(被全局拒绝的工具甚至不会出现在模型视野里)
2. Deny-first 规则(deny 永远压制 allow,即使 allow 更具体)
3. Permission Mode 约束(plan/default/acceptEdits/auto/dontAsk/bypassPermissions/bubble 共七模式)
4. Auto-mode ML 分类器(yoloClassifier.ts,独立 LLM 调用判定安全性)
5. Shell sandbox(独立于权限系统的文件系统/网络隔离)
6. Resume 不恢复 session 级权限(强制重新授权)
7. Hook 拦截(PreToolUse 可阻断/重写/异步审批)
最关键的设计哲学:Anthropic 自己的研究发现用户对权限提示的批准率高达 93%——这意味着交互式确认在行为上不可靠。所以架构选择是"不靠人盯着",而是用 sandbox 分类器把需要人决策的次数压低 84%。
# 上下文管理:五层渐进式压缩
模型的上下文窗口是整套系统的瓶颈资源。每次模型调用前依次跑 5 个 shaper:
· Budget reduction(始终生效):单条 tool 结果超尺寸就替换为引用
· Snip:删掉旧历史段
· Microcompact:缓存友好的细粒度压缩,等 API 返回后再用真实 cache_deleted_input_tokens
· Context collapse:read-time projection——存储不动,模型看到的是投影视图(这是论文里很精彩的设计)
· Auto-compact:兜底的全模型生成式摘要
为什么要 5 层而不是 1 层:每层成本不同,先做便宜的轻压缩,不行才升级。这是 lazy-degradation 思想。代价是用户难以预测系统行为,因为有些层(特别是 context collapse)对用户不可见。
CLAUDE.md 的四级层次(managed→user→project→local)是文件型记忆——刻意拒绝向量数据库,理由是"用户必须能读、能改、能 git commit"。代价是检索粒度只能到文件级(用 LLM 扫文件头选最多 5 个),不如向量检索精细。
重要洞察:CLAUDE.md 是以"用户消息"形式注入而非 system prompt,因此对模型的约束是概率性的。真正的强制力来自 deny-first 的权限规则。这是一个刻意的"指引层(概率) vs 执行层(确定)"分离。
# 扩展机制:四个、不是一个
论文回答了一个常见困惑——为什么 Claude Code 既有 MCP,又有 plugins、skills、hooks?
答案是这四者承担的上下文成本不同:
· MCP servers:外部服务集成,上下文开销高
· Plugins:多组件打包分发,上下文开销中
· Skills:领域指令 元工具,上下文开销低
· Hooks:生命周期拦截,上下文开销默认零
梯度上下文成本意味着便宜的扩展(hooks)可以大量铺开,昂贵的(MCP)保留给真正需要新工具的场景。代价是开发者要学 4 套 API。
Hook 系统极其细致:源码定义了 27 种事件,其中 5 种参与权限决策,22 种用于生命周期/编排。
# 子 Agent:隔离而非共享
通过 AgentTool(Task 是它的 legacy alias)派遣。子 agent 有三种隔离模式:
· Worktree:临时 git worktree,文件系统隔离
· Remote(仅内部):远端 Claude Code 运行
· In-process(默认):共享 FS,隔离上下文
关键约束:子 agent 只把最终摘要文本回传给父级,完整 transcript 走 sidechain 存独立 .jsonl 文件——既保留可审计性,又不污染父上下文。
代价:每次调用基本都得自包含 prompt(除 fork-subagent 外)。Anthropic 自己披露 agent teams 模式 token 开销约为普通 session 的 7×,这才是为什么"摘要回传"如此关键。
多 agent 协调用文件锁而不是 message broker——零依赖、可调试,但牺牲吞吐。
# 持久化:append-only JSONL
Session 存为几乎只追加的 JSONL(极少数清理重写除外)。三条独立持久化通道:
1. Session transcript(项目级,每 session 一文件)
2. 全局 prompt history(仅用户输入,supports Up 与 Ctrl R)
3. 子 agent sidechain(独立 .jsonl .meta.json)
--resume 重放 transcript 重建会话,但刻意不恢复 session 级权限——这是把"信任"作为会话隔离的安全不变量:用户每次都重新授权,避免旧上下文中的授权决策被带进新的语境。
compact_boundary 标记里嵌入 headUuid/anchorUuid/tailUuid,让 loader 在读取时打补丁拼接消息链——既压缩了上下文,又保留了完整历史的可重建性。
# 与 OpenClaw 的对照:同样的问题,不同的答案
维度:Claude Code vs. OpenClaw
· 系统形态:临时 CLI 进程 vs. 持久化网关 daemon
· 信任模型:每动作 deny-first 评估 7 模式 vs. 网关边界鉴权(DM 配对、白名单、可选沙箱)
· Agent runtime:queryLoop() 是系统中心 vs. Pi-agent 嵌入网关 RPC,per-session 队列
· 扩展架构:4 机制按上下文成本梯度 vs. manifest-first 插件,12 种能力,集中注册表
· 内存:CLAUDE.md 4 级 5 层压缩 vs. 工作区引导文件 dreaming 长期记忆推举
· 多 agent:父-子任务委派 vs. 路由(多 agent 服务不同渠道) 委派两层分离
最有意思的发现是两者可组合:OpenClaw 可以通过 ACP 把 Claude Code 当作外部 coding harness 托管。这暗示 agent 设计空间不是平面分类,而是层级式的——网关层和任务层可以叠在一起。
核心洞察:"Claude Code 把信任边界放在模型与执行环境之间;OpenClaw 把它放在网关周界。"
# 五大价值张力(最有思想深度的章节)
· Authority × Safety:93% 批准率证明人类督查不可靠,安全要靠分类器/sandbox 补
· Safety × Capability:>50 子命令的 bash 会跳过 per-subcommand 检查(解析慢导致 UI 卡顿)——defense-in-depth 的层共享性能瓶颈
· Adaptability × Safety:多个 CVE 利用"信任对话框出现前"的 hook/MCP 初始化窗口攻击
· Capability × Adaptability:主动式提示让任务完成率 12-18%,但高频时用户偏好骤降
· Capability × Reliability:上下文有界 子 agent 隔离 → 局部好决策 ≠ 全局好结果
# 第六视角:长期人类能力保留
论文不把它列为价值,而作为评估透镜,外部经验证据汇总:
· Becker et al. 2025(16 名经验丰富开发者 RCT):AI 工具使开发者慢 19%,但他们自我感觉快了 20%
· Shen & Tamkin 2026:AI 辅助组理解力测试低 17%
· He et al. 2025(Cursor 在 807 个仓库的因果分析):代码复杂度 40.7%,初期速度增益三个月内消散
· Liu et al. 2026:30.4 万 AI 提交审计,约 1/4 引入的问题持续到最新版本,安全问题留存率更高
· Kosmyna et al. 2025(54 人 EEG 研究):LLM 用户神经连接性减弱,且移除 AI 后仍持续
· Rak 2025:2023→2024 入门级技术岗招聘下降 25%
论文的判断是:Claude Code 显著放大短期能力,但提供的支持长期人类成长、深度理解、代码库连贯性的机制非常有限。 论文结尾把"未来系统应当把可持续性差距作为一等公民设计问题"作为最重要的开放挑战。
# 六个开放方向(未来 agent 系统)
1. 可观察性—评估鸿沟:78% 的 AI 失败是隐性的,89% 团队有可观察性但只 52% 做离线评估。需要 generator-evaluator 分离的脚手架。
2. 跨会话持久性:CLAUDE.md(静态)和 transcript(单会话)之间的"中间层"是空白
3. Harness 边界演化:where/when/what/with whom 四个轴向的扩展(特别是物理 VLA 行动会改变 reversibility-weighted risk 的代价不对称)
4. Horizon scaling:从单会话到多周期科学研究的可靠性
5. 治理与监管:EU AI Act(2026 年 8 月全面适用)、GPAI Code of Practice 对日志、透明度、人类监督提出外部约束
6. 长期人类能力作为一等设计目标:测量层与设计层都是空白
# 值得记住的几个判断
"模型推理在哪里、harness 执行在哪里——是整个 agent 系统设计的根问题。"
"95% 单步准确率下,100 步任务成功率只有 0.6%。"——这是为什么每一步都要验证。
"前沿模型在编码任务上的能力正在收敛,operational harness 的质量正在成为主要差异化因素。"
"agent 的设计选择不是平面的分类,而是层级化的——任务级 harness 可以被网关级控制平面托管。"
"工程复杂度不是为了限制模型决策,而是为了让模型能更好地决策。"
# 对工程实践的启示
对正在构建 agent 系统的我们:
· 投入确定性基础设施(context 管理、安全分层、恢复机制)比给越来越强的模型套 planning 脚手架更有回报
· deny-first 多层独立检查比单一沙箱在生产环境更鲁棒,但要警惕共享性能瓶颈导致的同时降级
· 上下文压缩做成多层渐进式比一次性截断或单步摘要更可靠,但用户需要可观察性
· append-only 持久化 不跨会话恢复权限是把审计性和安全不变量同时拿到的便宜做法
· 扩展机制按上下文成本分层:让"贵的"扩展(MCP)只用在真正需要新工具的场景,"便宜的"(hooks)可以铺开
· 子 agent 用摘要回传,不要共享 transcript——否则 token 开销线性爆炸(Claude Code 数据:7×)
· 把用户长期能力保留写进设计目标,而不是只在事后用 metric 衡量


A must read for anyone interested in building practical AI systems in 2026:
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
The paper explains the architecture of a modern production-grade AI agent system (Claude Code) by analyzing its source code. This is what they call a "harness" of an agentic coding system.
Learn by reading with an AI tutor: chapterpal.com/s/9b6bb47a/di…
PDF: arxiv.org/pdf/2604.14228


2
43
141
19,228

5層コンテキスト圧縮パイプライン — Budget Reduction → Snip → Microcompact → Context Collapse → Auto-compact。安い順に実行し、最後の手段としてモデルによる要約圧縮 面白いのは、人間が大体パーミッションは見ないで許可しちゃうからこそ、許可されても大丈夫なような構造にしてるっていう
1
3
665

Apr 18
Claude Code fully dissected!
Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design.
Only 1.6% of the codebase is AI decision logic.
The other 98.4% is operational infrastructure. Permission gates, tool routing, context compaction, recovery logic, session persistence. The model reasons. The harness does everything else.
This is the opposite of what most agent frameworks do today.
LangGraph routes model outputs through explicit state machines. Devin bolts heavy planners onto operational scaffolding. Claude Code gives the model maximum decision latitude inside a rich deterministic harness, and invests all its engineering effort in that harness.
The core loop is a simple while-true. Call model, run tools, repeat.
But the systems around that loop are where the real design lives:
A permission system with 7 modes and an ML classifier. Users approve 93% of prompts anyway, so the architecture compensates with automated layers instead of adding more warnings.
A 5-layer context compaction pipeline. Each layer runs only when cheaper ones fail. Budget reduction, snip, microcompact, context collapse, auto-compact.
Four extension mechanisms ordered by context cost. Hooks (zero), skills (low), plugins (medium), MCP (high). Each answers a different integration problem.
Subagents return only summary text to the parent. Their full transcripts live in sidechain files. Agent teams still cost roughly 7x the tokens of a standard session.
Resume does not restore session-scoped permissions. Trust is re-established every session. That friction is the point.
The bet behind all of this is simple. As frontier models converge on raw coding ability, the quality of the harness becomes the differentiator, not the model.
Paper: Dive into Claude Code (arXiv:2604.14228)
In the next tweet, I've shared an article I wrote on Agent Harness and what every big company is building. Do check.

73
299
1,650
178,190
Apr 17
𝗦𝗺𝗮𝗹𝗹 𝘀𝗶𝘇𝗲. 𝗕𝗶𝗴 𝗱𝗲𝗺𝗮𝗻𝗱. 𝗦𝗲𝗿𝗶𝗼𝘂𝘀 𝘂𝗽𝗴𝗿𝗮𝗱𝗲.
The 𝗦𝗺𝗶𝘁𝗵 & 𝗪𝗲𝘀𝘀𝗼𝗻 𝗕𝗼𝗱𝘆𝗴𝘂𝗮𝗿𝗱 𝟮.𝟬 𝗶𝗻 .𝟯𝟴𝟬 𝗔𝗖𝗣 has quickly become one of the 𝘁𝗼𝗽 𝘀𝗲𝗹𝗹𝗲𝗿𝘀, and it’s easy to see why. This is what happens when ultra-compact meets real-world shootability.
We’re talking 𝗽𝗼𝗰𝗸𝗲𝘁-𝗳𝗿𝗶𝗲𝗻𝗱𝗹𝘆 𝘀𝗶𝘇𝗲, but 𝘄𝗶𝘁𝗵 𝗲𝗿𝗴𝗼𝗻𝗼𝗺𝗶𝗰𝘀 𝘁𝗵𝗮𝘁 𝗮𝗰𝘁𝘂𝗮𝗹𝗹𝘆 𝗳𝗲𝗲𝗹 𝗿𝗶𝗴𝗵𝘁 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗵𝗮𝗻𝗱—no awkward grip, no compromise on control. It’s built for everyday carry, but shoots like something bigger.
Now add in the new color lineup… and suddenly your EDC isn’t just practical—it’s personal. Whether you like classic black or want something that stands out a bit more, there’s a version that fits your style.
Compact. Comfortable. Confident.
This is why everyone’s grabbing one.
#Weshoot #WeshootUSA #NJ #NewJersey #JerseyShore #CentralJersey #LakewoodNJ #BrickNJ #HowellNJ #TomsRiverNJ #SmithAndWesson #Bodyguard20 #380ACP #MicroCompact #EverydayCarry #EDC #CCW #PTC #NJCCW #ConcealCarry #CarrySmart #PreparedLifestyle #TrainHard #2A #Murica #PewPewLife #InstaGuns #SelfDefense



4
131

Agent Engineering Pattern - Compaction Ladder
Best agentic harnesses we know trigger this every certain token count:
① Snip trim oldest history segments
② Microcompact - clear stale tool results
③ Autocompact - rewrite full conversation
It's good that they do it, if they didn't, the ever-increasing token effort would put the session out of brains (and $$)
But it doesn't mean they don't get dumber still - each compaction drops knowledge points you might be depending on - the agent won't tell you what it forgot
Know your tools!
10
877

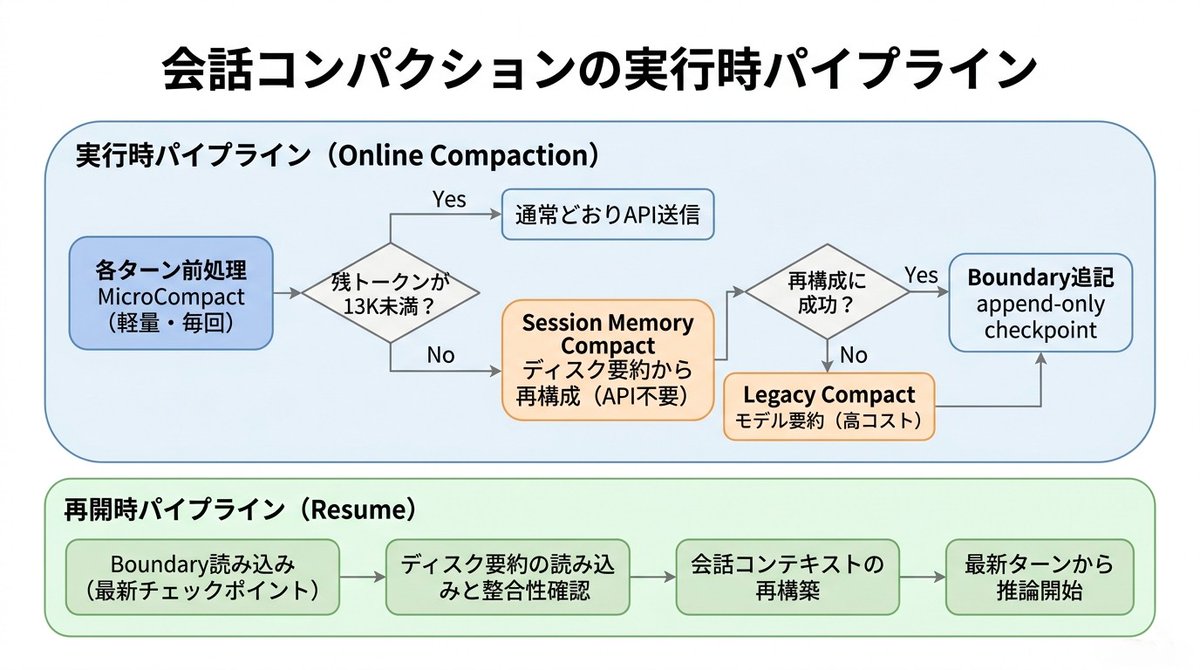
Claude Opusが最近「あほになった」「忘れるようになった」って声、めっちゃ多いけど…
これ、忘れてないよ。
2週間前(4月頭)にClaude Codeのソースリークで暴露されたMicroCompactの仕組みがまさに原因。
・毎ターン軽く前処理(MicroCompact)で冗長部分を削る
・コンテキスト13K切ったら本格圧縮(Session Memory Compact)
・失敗したらLegacy Compactでモデル要約にフォールバック
・再開時は「Boundary」で古い部分をバッサリ切って、直近Preserved Tailだけ繋ぎ直す
→ 「忘れた!」って見えるけど、実際は削除じゃなくて圧縮+再構成なんだよね。
しかもAnthropicが予算削減でeffort levelもHigh(MAX)→Lowに下げてるから、相乗効果で「なんか頭悪くなった」状態になってる。
今すぐ試してほしいことClaude Code内で
/effort max or /effort high
って打てば一発でHigh/Maxに戻るよ!(デフォルトがLow/Mediumに落ちてる人がほとんど)
リーク当時は「天才的」ってバズってたのに、今まさに「Opus終わった」って言われてる人、これが正体です。
1
4
122