
LLMs keep getting more fluent—but can you actually verify what they say? Structured KBs like Wikidata lack text grounding. Annotation-based datasets like FEVER are too small and monolingual. Synthetic expansion just produces hallucinations at scale. The trilemma between authenticity, scale, and structure has gone unsolved. ❓
Today, we dive into FactNet—a landmark contribution by @TsinghuaNLP (OpenBMB member) alongside researchers from TU Munich, Modelbest Inc., and Minzu University of China. FactNet constructs a billion-scale, open-source multilingual knowledge graph that unifies structured Wikidata assertions with auditable, byte-level evidence pointers from 316 native Wikipedia editions.
🤗 Paper: huggingface.co/papers/2602.0…
📄 arXiv: arxiv.org/abs/2602.03417
💻 Code & Data: github.com/yl-shen/factnet
Why it matters:
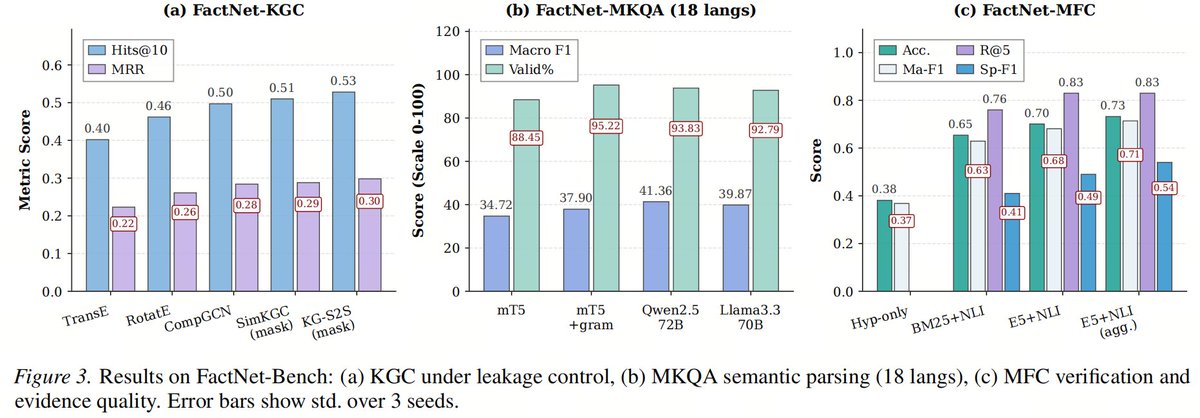
1⃣️ Billion-Scale & Truly Multilingual: FactNet unifies 1.7B atomic assertions into 1.55B FactSynsets, backed by 3.01B grounded evidence spans across 316 languages. Even the bottom-200 languages hold 2.7% of all evidence—a scale no prior resource has achieved with native, auditable text grounding.
2⃣️ Byte-Level Provenance, Zero Stochastic Inference: Unlike synthetic datasets that sever the connection to authentic sources, FactNet is built through a fully deterministic three-stage pipeline. Every FactSense carries a recoverable pointer (page ID, revision ID, Unicode character offsets), achieving 99.63% exact re-localization on a 1M-sample test.
3⃣️ 92.1% Grounding Precision Across 316 Languages: Human audit of 4,200 items confirms design-weighted precision of 0.921 (95% CI [0.913, 0.929]). WIKILINK_ENTITY and INFOBOX_FIELD matchers cover 55% of evidence at precision above 0.94. Low-resource languages still achieve 0.885—validating deterministic segmentation for tail languages.
4⃣️ FactNet-Bench Sets a New Evaluation Standard: Three tasks (KGC, MKQA, MFC) explicitly penalize leakage—removing predicate masking alone inflates KGC MRR anomalously from 0.298 to 0.351. Grammar-guided decoding boosts valid parse rate from 88.5% to 95.2% on MKQA. MFC Top-5 aggregation reaches 0.73 accuracy and 0.54 Span F1.
FactNet resolves the authenticity-scale-structure trilemma and builds the foundation for AI systems that are not just knowledgeable, but structurally grounded and inherently verifiable.
#AI #THUNLP #OpenBMB #KnowledgeGraph #FactChecking #NLP #LLM #MultilingualAI


6
18
1,063


May 31
🚀 Open-Source AI Models: May Recap
According to Zhihu contributor @logcong0120, May may have felt quieter than previous months, but there was still plenty happening across China's open-source AI ecosystem.
Here's your lightning-fast recap👇
📅 May 1
• @Alibaba_Qwen releases Qwen-Scope, using sparse constraints to extract more interpretable and disentangled latent features.
• @MistralAI open-sources Mistral Medium 3.5 (128B).
📅 May 6
• @Google releases Gemma 4 MTP Drafter, leveraging speculative decoding for up to 3× faster inference.
• @ZyphraAI launches ZAYA1-8B, the first MoE model trained on AMD Instinct MI300 hardware.
📅 May 7 – OpenSearch-VL releases a VLM family (8B, 32B, 30B-A3B) alongside a full SFT RL training pipeline.
📅 May 8
• Qwen introduces WebWorld, a browser simulator for training Agents without relying on the real internet, together with WebWorldData trajectories.
• ModelBest releases SciCore-Mol, enhancing LLMs through pluggable external cognition modules.
• HiDream-O1-Image (8B) debuts, unifying image, text, and task conditions into a shared token space for image generation.
📅 May 11 – @Xiaomi releases OneVL, an open autonomous-driving framework with model checkpoints.
📅 May 12 – ModelBest launches MiniCPM-V4.6, a 1.3B multimodal model optimized for mobile deployment, plus its Thinking version.
📅 May 13 – @JinaAI_ introduces jina-embeddings-v5-omni, a multimodal embedding model supporting text, image, audio, and video.
📅 May 14 – @AntLingAGI releases Ring-2.6-1T, enabling stable training of trillion-parameter models through asynchronous RL.
📅 May 15 – SenseTime opens SenseNova-U1-8B-MoT-Infographic, optimized for high-density infographic generation.
📅 May 16 – @intern_lm unveils Intern-S2-Preview, a 35B scientific multimodal model surpassing its predecessor.
📅 May 18 – Bytedance releases Lance, a native multimodal model for understanding, generating, and editing images and videos.
📅 May 20 – @Cohere launches Command A , a multimodal model with 218B total parameters and 25B active parameters.
📅 May 21
• Meituan's LongCat-Video-Avatar-1.5 improves digital-human video generation with more accurate lip-syncing.
• @TencentHunyuan releases Hy-MT2, a multilingual translation model family spanning 1.8B to 30B-A3B.
• NetEase launches Confucius4, a multimodal model specialized for mathematical reasoning based on Qwen3.5.
📅 May 23 -24
ModelBest releases BitCPM-CANN, a family of native Ascend-trained 1.58-bit ternary models, and launches MiniCPM5-1B, targeting edge devices and local deployment.
📅 May 25 – Kuaishou releases Keye-VL-2.0, supporting near-lossless reasoning over 256K-token video contexts.
📅 May 26 – OpenMOSS upgrades MOSS-TTS-v1.5 with more stable voice cloning and pause control, and releases MOSS-SoundEffect-V2.0, generating environmental and action sounds directly from text.
📅 May 28 – @Baidu_Inc updates PaddleOCR-VL-1.6, reaching 96.33% on OmniDocBench v1.6.
📅 May 29 – @StepFun_ai releases Step3.7-Flash, a 198B multimodal model with configurable reasoning levels.
🙋 Also, open source wasn't the whole story this month. Several closed-source models were equally worth watching:
• Doubao-Seed-2.0-lite surprisingly outperformed Pro
• Qwen3.7-Max delivered a significant jump over 3.6
• GLM-5.1-HighSpeed pushed inference speed to 400 tok/s
• Google released Gemini 3.5 Flash and Gemini Omni
• Claude Opus 4.8 doubled down on honesty, reducing the chance of Agents "pretending" to finish long-horizon tasks
👀 For author, he's still waiting for Qwen3.7-32B and DeepSeek-VL. How about you?
📖 Full article:
zhuanlan.zhihu.com/p/2044378…
#OpenSource #LLM #Qwen #DeepSeek #MiniCPM #StepFun #Agent #AI
2
1
8
705

May 31
its open source, built by Tsinghua, ModelBest, OpenBMB, and AI9stra.
if you actually work with ai agents across multiple clients or projects this is the most underrated thing you will use this year
repo link below, go break it and tell me what you find
repo link 👇
github.com/OpenBMB/PilotDeck
2
274

May 30
Built by Tsinghua University's THUNLP Lab, Modelbest, OpenBMB & AI9stars.
…and it’s open source.
Worth exploring if you're curious about autonomous agents and persistent AI workflows.
GitHub → github.com/OpenBMB/PilotDeck
1
8
417

May 30
PilotDeck is 100% open-source.
built by Tsinghua THUNLP Lab, Modelbest, OpenBMB, and AI9stars.
if you use AI for anything serious.. this is the upgrade your workflow actually needs.
try it → github.com/OpenBMB/PilotDeck
2
15
1,409

May 30
4/ Bring-your-own-model is built in.
PilotDeck's router cut a content task from $12.58 to $2.83 at equivalent quality. ~70% off. Hard parts stay on Opus 4.5, easy parts go to a cheap model.
Open source. Out of Tsinghua, Modelbest, OpenBMB, AI9stars.
2
969

May 30
PilotDeck is open-source, built by THUNLP (Tsinghua), Modelbest, OpenBMB & AI9stars.
If you're serious about AI productivity infrastructure - not just AI chat - it's worth exploring.
Star & contribute on GitHub 👉 github.com/OpenBMB/PilotDeck
#AIAgents #OpenSource #ProductivityTools
1
8
816

PilotDeck ile Yapay Zeka Asistanları Sadece Sohbet Etmekten Çıkıp İş Yapmaya Başlıyor
OpenBMB, Tsinghua NLP, ModelBest ve AI9stars iş birliğiyle geliştirilen açık kaynaklı PilotDeck yapay zeka ajanlarını yönetmek için bir işletim sistemi görevi görüyor. PilotDeck'in ilk dikkat çeken yeniliği sunduğu Çalışma Alanı yaklaşımı. Çoğu yapay zeka aracı yalnızca bir sohbet penceresiyle sınırlı kalırken PilotDeck her projeyi bir kokpit gibi ele alıyor. Bu kokpit projenin dosyalarını tutan özel bir dosya sistemi, projenin hedeflerini ve kısıtlamalarını canlı tutan bir hafıza alanı ve yapay zekanın ürettiği tüm çıktıların açıkça etiketlendiği bir düzen sunuyor. Böylece işler dağınık bir sohbet geçmişinde kaybolmuyor bir proje yönetim merkezinde organize ediliyor. Bir diğer kritik yenilik ise sistemin Akıllı Yönlendirme yeteneği. PilotDeck gelen bir görevin karmaşıklığını otomatik olarak değerlendirip zorlu işleri güçlü ve gelişmiş modellere, kolay ve tekrarlı işleri ise hızlı ve ucuz modellere yönlendiriyor. Bu sayede her basit sorgu için en pahalı modeli kullanmak zorunda kalmıyorsunuz.
PilotDeck'in hafıza yapısı tamamen şeffaf ve proje odaklı olacak şekilde kurgulanmış. Birçok araçta yapay zekanın bir şeyi yanlış hatırlaması durumunda sorunun nereden kaynaklandığını bulmak imkansıza yakınmış. Burada ise hafızaya yapılan her yazma ve okuma işlemi uçtan uca izlenebilir durumdaymış. Sistem üç kritik bilgi alanını birbirinden ayırıyormuş üzerinde çalıştığınız hedef, gelinen aşama ve uyulması gereken sınırları tutan Proje Hafızası sizin düzeltmelerinizle sürekli şekillenen, zevklerinizi ve beklentilerinizi öğrenen Geri Bildirim Hafızası ve projeler arası taşınabilen, kendinizi tekrar tekrar tanıtmanızı gerektirmeyen Kullanıcı Profili. Son olarak Her Zaman Açık özelliği sayesinde ajanlar sizin mesaj atmanızı beklemiyor. Bunun yerine üzerinde çalışılabilecek görevleri proaktif olarak buluyor, izole bir ortamda çalışıyor, bir insan kararı gerektiğinde size danışıyor ve ilerleme durumunu kendiliğinden raporluyor.
En önemlisi işin sonunda size yalnızca bir sohbet mesajı değil doğrudan kullanabileceğiniz gerçek dosyalar teslim ediyor. Reklam değildir.

1/5
🚀 PilotDeck is now live — the open-source AI agent OS built for all scenarios!
Built by @TsinghuaNLP × ModelBest × @OpenBMB × AI9stars, PilotDeck is here for full memory transparency, intelligent cost routing, and agents that never stop working for you.
🔗 Show Case: pilotdeck.openbmb.cn/pilotde…
💻 GitHub:github.com/OpenBMB/PilotDeck
One person. One fleet of agents. Ship something real. 🔥🧵
1
9
560

May 29
ModelBest went full open source:
✅ Full model weights
✅ Training dataset (UltraFineweb-zh-L3)
✅ Data curation pipeline (L0-L4 governance)
✅ Paper with full methodology
That makes experimentation much easier for developers building local-first products.
1
6
7,022

May 28
What's underappreciated about this release: it's not just data, it's a replicable system.
The L0→L4 framework tells you not just WHAT data to use but WHERE in the training pipeline each tier belongs.
For anyone building automotive or mobile AI, that's the missing manual.
Most teams are guessing at this. ModelBest just published the answer key.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…

6
9
5,737

May 28
Everyone's talking about making AI work on phones and cars..... Nobody's talking about the data quality needed to get there. ModelBest just made that conversation unavoidable.
4
149

May 28
The on-device AI race isn't going to be won by whoever squeezes the most parameters onto a chip.
It's going to be won by whoever figures out how to make a small model genuinely capable and that's a data problem.
The L0→L4 governance framework ModelBest is putting out here is the most rigorous public answer to that problem I've seen.
Tiered curation. Stage-matched injection. 600B tokens of L3-quality synthetic data.
This is serious infrastructure.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
29
27
15,229

May 28
We've had open-source weights for a while now. What we've never had is the full data stack that produced those weights — the pretraining data, the SFT data, the pipeline logic, all validated on a real model. That's what makes this different. Releasing weights without data is like sharing a recipe but keeping the ingredients secret. ModelBest just shared the ingredients.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
60
66
7,746

May 28
🚨TsinghuaNLP× ModelBest × OpenBMB × AI9stars open-source #PilotDeck, an Agent OS.
Build a local Zelda-style open world with edge models in 1 day, just via language prompts.
White-box memory
Intelligent routing auto-matches models at 1/6 cost
Agents 24/7 online, auto-run tasks

1
2
374
1/5
🚀 PilotDeck is now live — the open-source AI agent OS built for all scenarios!
Built by @TsinghuaNLP × ModelBest × @OpenBMB × AI9stars, PilotDeck is here for full memory transparency, intelligent cost routing, and agents that never stop working for you.
🔗 Show Case: pilotdeck.openbmb.cn/pilotde…
💻 GitHub:github.com/OpenBMB/PilotDeck
One person. One fleet of agents. Ship something real. 🔥🧵
71
170
291
284,331

May 27
🚨 AI builds AI now?!
ModelBest×Tsinghua×OpenBMB open-source ForgeTrain, the world’s first production-grade LLM framework built entirely by AI.
10% faster than Megatron on H100 GPU.
Runs MiniCPM5-1B pretraining on Huawei Ascend. This 1B model ranks #1 on AA Benchmark (sub-2B).


May 26

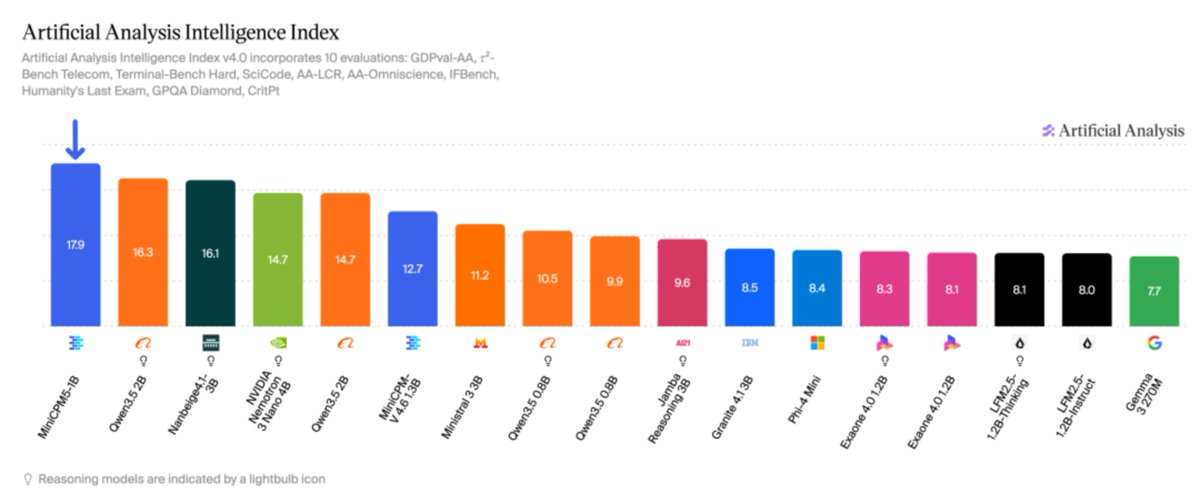
🚨BREAKING: ModelBest×Tsinghua×OpenBMB open-source MiniCPM5-1B
1B params, outperforms all sub-2B models on AA-Index
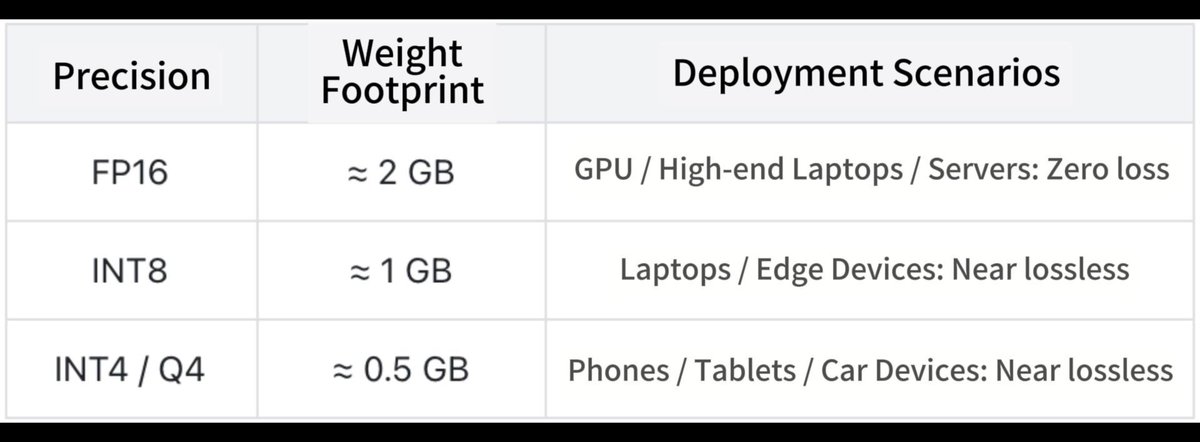
INT4 quantized (0.5GB), powers AI desktop pets on endpoints
The base model is pre-trained on ForgeTrain, AI-coded production framework,10% faster than Megatron🚀


2
3
37
3,927