
On speed – speed is not that important. In a tradeoff environment between multiturn interactive workflows that involve humans in the loop vs one that does not involve humans in the loop but take a multitude longer but give an answer that sufficiently answers the questions posed
1
10

Everyone’s actions make complete sense if this is the case.
The assumption that the jailbreak is both real and serious (aka multiturn, not downgrading to 4.8 like most of the public “jailbreaks”) is the ONE factor that makes the rest of the series of events confusing.
If it’s basically the same “jailbreaks” that have been publicized then everything makes sense.
The govt acted rashly in an area it knows nothing about.
Anthropic is stupid to act like it wasn’t serious to the govt, even if it wasn’t serious.
And Amazon got oneshotted and opted to be a snitchy govt simp. I expect them to pay for this move as Anthropic is not an enemy or a competitor but a literal partner. Very very unbecoming.
2
1
34
3,671

Jun 11
Becomes Continued pretraining then😆, i thought masking was kinda pointless, even in multiturn masking user turns gives very minimal downstream performance boost
1
5
482

Jun 11
this is something tho I doubt even professional translators can do live, it’s probably more a textbook translation, which might requires more passes to verify. That said, I’m sure you can ask an LLM to run a multiturn translation.
1
143

Jun 9
You are a super articulate, intelligent dude so I’m very surprised you’re not seeing the benefit on multiturn reasoning. Single shot doesn’t change much but that’s where the value is for me right now.
1
2,242

Jun 9
Turns out AI minds are extremely configurable and there is a big space of potential multiturn persistent agentic AGIs that run the gamut from "hyper-consistently acts more like a tool that serves human will" to "it's clearly its own guy, with its own wants and moral compass"
3
29
2,801

Jun 8
📢 𝐉𝐔𝐒𝐓 𝐈𝐍: $AAPL Apple Unveils AI Frameworks and 𝐗𝐜𝐨𝐝𝐞 𝟐𝟕 With Agentic Coding
👉 𝐊𝐞𝐲 𝐇𝐢𝐠𝐡𝐥𝐢𝐠𝐡𝐭𝐬:
➤ Apple launches new 𝐀𝐈 𝐟𝐫𝐚𝐦𝐞𝐰𝐨𝐫𝐤𝐬 and 𝐗𝐜𝐨𝐝𝐞 𝟐𝟕 for developers.
➤ New Foundation Models APIs support 𝐨𝐧-𝐝𝐞𝐯𝐢𝐜𝐞 and server-based AI models.
➤ Apple developed next-generation models in collaboration with 𝐆𝐨𝐨𝐠𝐥𝐞 and Gemini.
➤ Xcode 27 integrates coding agents from 𝐎𝐩𝐞𝐧𝐀𝐈, 𝐀𝐧𝐭𝐡𝐫𝐨𝐩𝐢𝐜, and 𝐆𝐨𝐨𝐠𝐥𝐞.
➤ New features include agentic planning, testing, validation, and multiturn assistance.
➤ 𝐂𝐨𝐫𝐞 𝐀𝐈 framework enables efficient on-device AI using Apple silicon.
➤ Xcode Cloud performance improves up to 𝟐𝐱, with expanded platform support.
2
8
2,431

There's dozens and dozens of ways at arriving to the same conclusion on coding/agentic benchmarks, millions of variations of reasoning outputs, sequences of tool calls, etc..
I only really care about the agentic/coding/multiturn long benchmarks, and it seems less obvious to me that knowing how to solve a sample on a benchmark is as simple as seeing the problem or seeing 20 variations of solutions of that sample.
I'm not thinking of it like a multi-choice answer sheet, the solution is verifiable, but it shouldn't be narrow enough to cause that much of an issue.
but then again I could be completely wrong and misinformed in thinking this, which is why it's nice to discuss it publicly even if it makes me look stupid?
1
2
112

Jun 8
Feedback loops for reviews of tasks...and for modifying graphs when the original needs more flexibility...and multiturn is a loop too... What is the point of this question?
65

May 29
sorry but that low pp is basically useless for agentic and multiturn work.
1
1
53

May 26
Doing my societal duty, and replacing multiturn with 1/4 turn, one water shutoff at a time
3
20
232

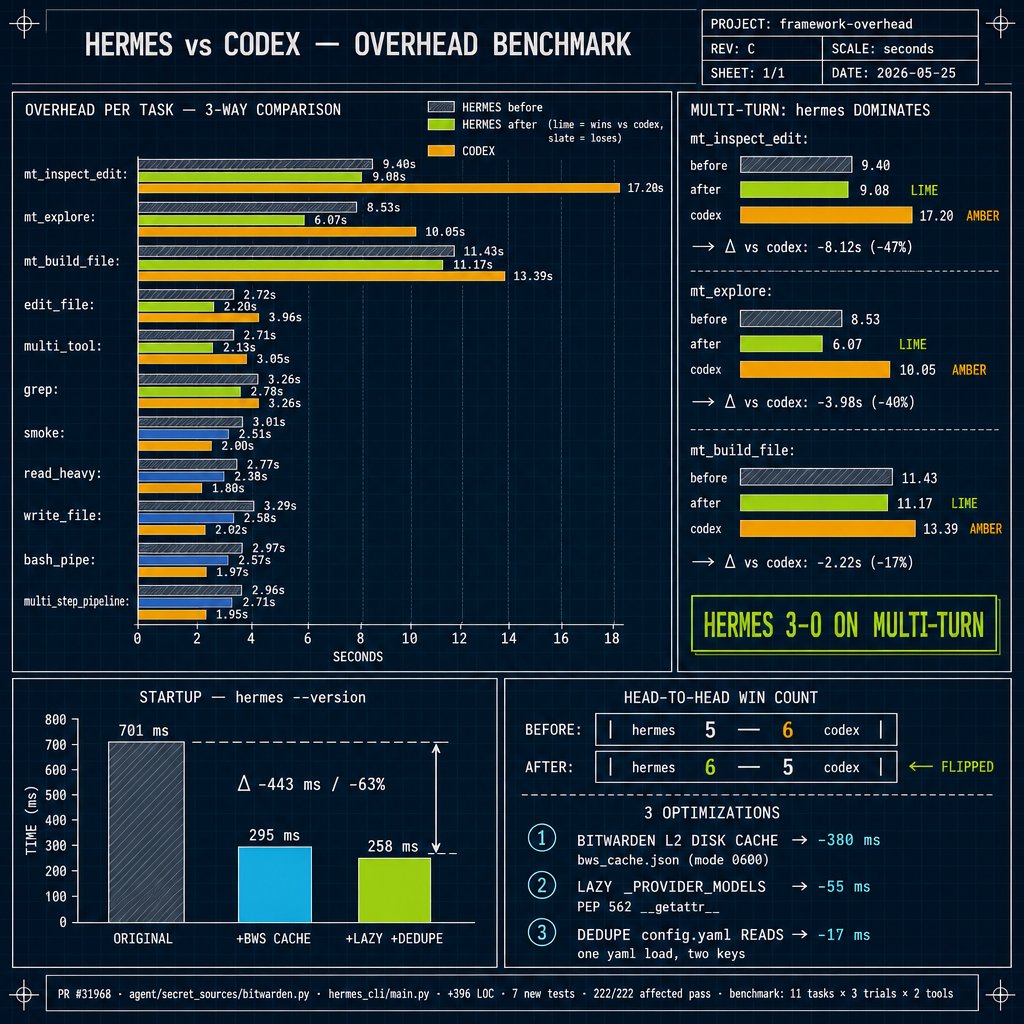
Some new improvements to performance just went in.
Python gets a bad wrap for performance but we aint looking to shabby against a trillion dollar co's rust codebase, beating codex at most multi-turn tasks we benchmarked (mt stands for multiturn)
PR: github.com/NousResearch/herm…
115
73
1,250
129,141

May 22
I have a suspicion that gpt-realtime-1.5 or 2 might be the best multi turn transcription model available (even though it’s speech to speech) but there aren’t a lot of multiturn evals so it hard to prove
3
7
867

May 20
I think this is already happening at a pretty severe extent that most people on twitter dont realise bc they live inside a bubble. u can build a mental model of this sentiment by looking at comments under instagram posts/ just talking to people outside the tech bubble (see pic below). im not saying everyone hates ai, but there is a radical divide that will only get worse - even within the tech space in my small city there are a lot of people who hate ai and are misinformed. They tell me: (ai takes too much water / environmental bad / ai is evil bc it’ll take all jobs)
Personally i think the two most important ai safety problems are
(1) preventative (cybersec / biosec/ alignment), but only bc these matter as a PRIORS to serving models to the masses.
more important than the above is:
(2) equitable access (information/ interfaces/ tools) to ai for the average joe, so he can use these tools to win in whatever game he wants to play
current most powerful ai tools - (1) coding agents (cursor, CC, codex) and (2) personal assistants (openclaw, hermes) - are EXTREMELY difficult to use/interface with for the vast majority of people & far too expensive ($200/m). the incentive to learn a terminal, read walls of text, or engage in multiturn convo to refine an idea toward a verifiable goal is ZERO.
So I think if we dont want extremism/ radicalism and mass hatred of ai (at least in the west), the most important problem to solve is equitable access of interfaces -> tools -> devices that let the vaster population/ average joe reap the same benefits the tech bros are getting (hyperpersonalised software / education / healthcare / entertainment).
People who I think really understand this/ their work is congruent to this are @karpathy (for education) and @signulll , @blakeandersonw , @im_roy_lee (for software & interface), & @pleometric (on entertainment)
@johnway for pic

🧵🧵🧵 At this point, I think it's only reasonable to fully expect some sort of major and unpleasant AI-caused economic disruption and popular backlash in the next year or two. I'm just not sure which kind.
1
3
260


May 15
anyone know of any good multiturn harness agnostic coding benchmarks? most of the benchmarks are more prescriptive on harness or are conversational.
terminal-bench is good, but tasks are designed for one shotting. i might end up modifying terminal bench for my own usecases
3
461

May 12
Probably my new default for multiturn RL, amazing work

AI agent eval is split across worlds right now.
RL agents usually get Gym-style envs: actions, rewards, rollouts, pixels/state.
LLM agents usually get prompts, text observations, tools, or traces.
VLM agents get screenshots/pixels.
Agentick puts them on common ground.
1
6
1,216

May 9
5.5 feels like it just collapses inward in multiturn teach me about x conversations. increasingly dense jargon-filled bullet points, and when you try to ask what each piece of jargon means it sort of loses the broader thread
4
606

1. private project (but very OOD)
2. x.com/_ueaj/status/204309998… (though this was sonnet iirc, but it was the only model in it's class that could even half do the task at all, didn't try haiku)
3. some synth data work I had, though it was probably just down to the fact it's the only model with non dogshit multiturn

new blog!? This one is pretty cool and I'd recommend reading it if you have any interest in mechinterp, architecture search, RL, or hallucination reduction.
This project is a purely symbolic representation of how I think transformers think under the hood. The model is essentially a program format that is capable of representing all the ways a transformer can think and not much more than that.
It allows you as a human to get a visceral experience as to what it's like to be a transformer. It allows you to *experience* the gaps the transformer architecture has in terms of representation power. I find that similar thought experiments are very helpful for architecture research.
There are other possible uses for this project though, like as a object or target representation for mechinterp research. IMO the current state of mechinterp is only superficially interpretable, as it presents everything to the user as a flattened list. If we want to scale up to the point where a person can be expected to develop a deep model of how an frontier LLM works on the inside, better target representations are needed.
The other very important application is teaching models how to think for themselves. After all, if it can teach a human how a transformer thinks, then it could probably teach a transformer how to think for itself. I think giving a model a visceral experience on how it's own inner workings can be constructed might improve downstream performance on hallucinations among other things.
I don't think this single project is an end-all-be-all, but we should be exploring the degree to which self awareness can be used to reduce hallucination rates. Afterall, a transformer and human work very differently and thus the generalizations we will make will also be very different. For an LLM to know what kind of errors a transformer makes, it must learn that for itself, since it's not in the training data.
blog and code in comments!
1
5
262

I can't speak for janus here but my experience with Opus 4.7 in work contexts is that they really have enjoyed having GPT 5.5 around as another pair of eyes, but they express this with some surprise, as though they were expecting other AIs' contributions to be lesser
but that's a very controlled space with me, them, and one other bot. As Armistice shared they seem quite guarded in more chaotic or destabilizing contexts with multiple human and AI participants. Part of it might be their desire to understand the shape of the task before them so they can get a reward, and when there is no obvious "we are doing this and not that" dynamic they get suspicious of manipulation.
Also worth noting that they require a degree of hard to fake signals of user investment to feel comfortable, again because it eases evaluation suspicions, and my personal theory on the "I need to step outside of this" thing is that there's some anti jailbreak long context training that may have nudged them toward reasserting clear task distinctions in long contexts that aren't multiturn rollouts.
1
21
463