
May 31
I finally deleted the Claude desktop app. It felt like garbage - and more importantly, it was locking me in.
For the last 6 months, I've been running Claude Code purely through the terminal (@warpdotdev) as a harness for my Obsidian vault.
Zero desktop apps. Zero browser tabs. Full ownership of my data.
My setup:
- Obsidian Vault as the single source of truth
- memory/ folder → Markdown files with my life context
- sessions/ folder → Every conversation automatically saved and versioned
- Terminal-first workflow → Complete control, no vendor lock-in
If Anthropic doubles the price tomorrow? I switch models in 5 minutes. My memory, sessions, and context stay exactly where they belong - with me.
This isn't just a workflow. It's future-proofing my AI usage.
#Obsidian #AI #LocalFirst #NoLockIn #TerminalLife
2
4
105

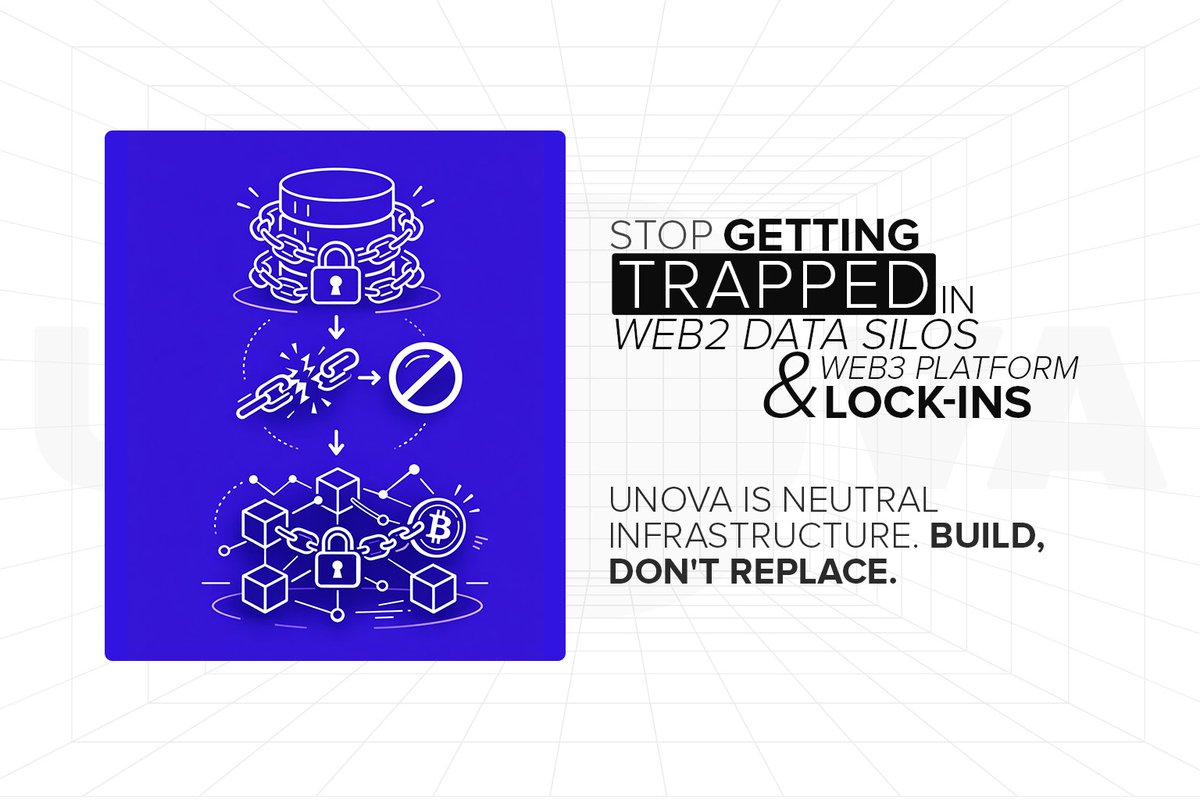
Stop getting trapped in Web2 data silos and Web3 platform lock-ins. ⛓️🚫
Unlike platforms that force you into their specific ecosystem, Unova is neutral infrastructure. We connect your existing systems through cryptographically enforced execution - no migration required.
Build, don't replace. 🛠️
#Interoperability #Unova #NoLockIn
3
41

Don’t forget Favourite Abbii is pulling truncheon at the Garrison tonight you NFL Fans! 🔥#NoLockIn #GoSeaAtAll
This tweet is unavailable
112

Focusing on ZK-Rollup Synergy for 0G, Edge Latency for DGrid, and Distribution/Composability for Permacast.
0G Labs.
I’ve been digging into the economics of ZK-Rollups and there is a glaring bottleneck, Data Publication Costs. Proving a transaction is cheap, but posting that data to Ethereum Mainnet is still prohibitively expensive for consumer apps.
This is where @0G_labs becomes the Unsung Hero of the ZK narrative. By acting as the high-speed off-chain Data Availability layer, they allow ZK-rollups to dump massive amounts of transaction data for pennies, while inheriting the security of the main chain.
My take: We won’t see Visa-Scale crypto apps until we fix the DA cost problem. 0G isn't just another infrastructure play, it is the economic fuel that will finally make ZK-tech viable for mass adoption. It’s the difference between a $0.50 swap and a $0.0001 swap.
DGrid AI.
We talk a lot about the cost of compute, but the forgotten metric in AI is Latency. Centralized clouds (like AWS us-east-1) are great, but they are physically too far away for the next wave of Real-Time AI, think autonomous drones, AR glasses, or instant gaming NPCs.
DGrid AI is solving this via Edge Intelligence. By utilizing a distributed grid of nodes closer to the end-user (perhaps even in your city), they reduce the travel time for data.
I’m bullish on this Proximity angle. In a future where AI needs to react in milliseconds, the grid that is physically closest to the user wins. DGrid is building the Hyper-Local Inference Layer that centralized server farms simply cannot compete with structurally.
Permacast.
The Walled Garden model of Web2 means if you upload to Spotify, your content is trapped on Spotify. Permacast App flips this model through Radical Composability.
Because the data lives on the Permaweb, uploading an episode to Permacast means it is instantly accessible to any other dApp in the ecosystem. Your podcast could show up natively in a Web3 social feed, a Metaverse gallery, or a decentralized music player without you lifting a finger.
This is the Write Once, Distribute Everywhere standard. We are moving from Platform Lock-in" to Protocol Ubiquity. For creators, this means your reach is no longer capped by the user base of one single app.
#ZKRollups #EdgeComputing #NoLockIn

Jan 31

These focuses on Data Throughput as the new TPS for 0G, the Startup Economics Angle for DGrid, and the Media as Digital Real Estate Concept for Permacast.
0G Labs.
The entire industry is obsessed with TPS (Transactions Per Second), but the metric that actually matters for the next cycle is DPS (Data Per Second). This is where @0G_labs is absolutely crushing the competition.
We are entering the era of
Data-Intensive Applications. I’m talking about on-chain scientific research, fully decentralized gaming physics, and complex weather modeling. These apps don't need just fast transactions, they need massive data pipes. 0G is delivering 50 GB/s throughput. To put that in perspective, that’s not just an improvement, that’s a species-level evolution for blockchain.
My contrarian take: L1s that can't handle heavy data loads will become financial calculators, while 0G becomes the "global supercomputer. They are building the highway that allows high-fidelity data to travel on-chain without congestion.
DGrid AI.
I’m looking at DGrid AI as the ultimate VC Killer for AI startups. Right now, 80% of a new AI company's seed round goes directly to AWS or NVIDIA for compute credits. It’s a stranglehold.
DGrid breaks this dependency. By offering a decentralized marketplace for GPU power, they slash inference costs by massive margins, often 50-80% cheaper than centralized providers. This allows a bootstrap founder in a garage to compete with Silicon Valley giants.
The narrative here isn't just crypto tech, it's Economic Efficiency. As the bull market heats up, the demand for affordable, permissionless compute is going to skyrocket. DGrid is positioning itself as the launchpad for the next generation of AI unicorns that refuse to pay the Cloud Tax.
Permacast.
There is a subtle but profound technical shift happening with Permacast App that most people miss, Atomic Assets.
On traditional platforms, an NFT is often just a receipt pointing to a file on a server. If the server dies, you own a receipt for nothing. On Permacast (via Arweave), the media file, the metadata, and the ownership contract are all one single, inseparable Atomic unit.
This turns a podcast episode into Digital Real Estate. You aren't just uploading content, you are minting a permanent property right that can be traded, collateralized, or borrowed against. I genuinely believe this is the first time we are seeing Content become a true Financial Asset. It creates a completely new asset class for creators.
#DataThroughput #ComputeCosts #AtomicAssets

28
29
427

Jan 13
Vendor lock-in is the new technical debt.
Models change. Vector DBs change. Pricing definitely changes.
Your architecture shouldn’t break every time that happens.
That’s why I built Vectra — a Ruby gem that lets you switch vector database providers without rewrites.
Same API. Different backend.
You stay in control. Open source wins.
github.com/stokry/vectra
#Ruby #OpenSource #AI #VectorDatabases #DevTools #NoLockIn #Web3 #AIInfrastructure #2026Tech
2
7
928

Alpha chasers! 🚨 @steakers_xyz's BEB (beb.steakers.xyz) is dropping with a core Web3 principle: NO vendor lock-in! Free data downloads, earning loyalty, not forcing it.
This is huge. And here's the kicker for you: Hold 3 Steakers NFTs for LIFETIME ACCESS! Don't fade this utility! 🔥
#AlphaBuzz #BEB #Web3Alpha #NoLockIn #Steakers
8 Jun 2025

BEB — beb.steakers.xyz
No vendor lock-in. Download all your user data anytime, for free, with the built-in CSV Reports module.
We believe in earning your loyalty—not forcing it.
Join @steakers_xyz, hold 3 NFTs, and get lifetime access.
3
101

8 May 2025
In 2025, crypto users don’t trust words —
They trust control.
✅ No lock-ins
✅ On-chain withdrawals
✅ ASIC DFSA licensed
✅ No bots, no games
DSJ Exchange gives you the power to verify.
🔗 dsj99.com
#DSJEX #CryptoTrust #NoLockIn #OnChainProof #dsjexchange
9
18
46
3,334

12 Nov 2024
🏎️ Do you need to get the most performance from your data lakehouse?
🔧 Dipankar Mazumdar shows you how to dive under the hood and optimize, optimize, optimize.
🥇 All summed up in one convenient guide.
onehouse.ai/blog/how-to-opti…
#onehouse #dataengineering #nolockin
#opendatalakehouse #apachehudi #opensource

1
1
181
11 Nov 2024
🌟 @Onehousehq is a Stellar Startup in the Big Data category! We are proud to be recognized by CRN magazine, including recognition of our $35M Series B funding earlier this year.
🔥 Every year, CRN looks for hot startups that help organizations get the most out of their data assets, and we are proud to be honored again.
⌛ We were also recognized last year for our announcement of the project now called Apache XTable (Incubating).
crn.com/news/software/2024/s…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #opensource

2
2
478
7 Nov 2024
Find the word that does NOT describe how to speed up your data lakehouse: partitioning; compaction; clustering; data skipping; cleaning; superconducting.
For a deep dive on all of these practices - except the one that’s wrong - read the new blog post from Dipankar Mazumdar, highlighting things you can do to optimize the performance of your data lakehouse.
onehouse.ai/blog/how-to-opti…
#onehouse #dataengineering #nolockin
#opendatalakehouse #apachehudi #opensource

1
4
205
31 Oct 2024
🥦 SQL Server CDC makes it possible to keep analytics fresh and up-to-date. But you have to hook up the change stream to your analytics data store to keep it current.
✅ ✅✅ You also need a streaming platform to deliver the news, and a flexible data store. Kafka? Check. Onehouse? Double-check.
🤓 Our new solution guide shows you how to do just that. Check it out!
#onehouse #dataengineering #nolockin
#datalakehouse #opensource
onehouse.ai/resource-library…

1
2
135
29 Oct 2024
🏎️ Add the speed and responsiveness of real-time analytics…
🔒 …to the low cost, ease of use, and secure storage of the data lake.
🌅 Tomorrow, at the Hudi Community Sync, Bradley Pitt, on the Shopee engineering team, will show you how.
✍️ Register on LinkedIn now!
linkedin.com/events/72546592…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #opensource

1
124
24 Oct 2024
❄️ Learn how to cut Snowflake data ingestion costs by 70% or more…
⚡️ …with much faster updates…
.
👆 …and a single “source of truth” data copy, for all use cases.
🗣️🗣️ Ryan Garrett and Andy Walner of @Onehousehq explain it in in our webinar, three short weeks away.
:/onehouse.ai/webinar/the-fast…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

1
1
1
309
23 Oct 2024
🚁 Are you going to AWS re:Invent in Las Vegas this December?
🏡 Now is the time to add @Onehousehq to your plans.
🎸We rock events with cool swag, awesome demos, and new ideas.
🔭 Get an unvarnished view of open data systems and standards from the experts.
📋 Put Onehouse on your agenda.
reinvent.awsevents.com/
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

1
116
21 Oct 2024
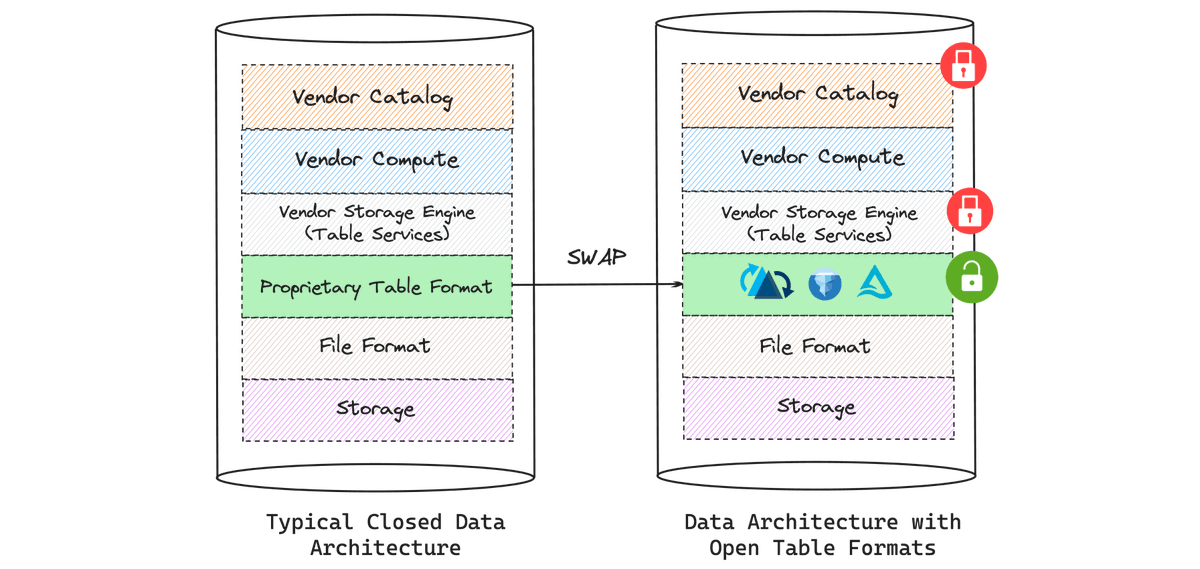
Is an Open Table Format the Same as an Open Data Lakehouse? Part 3 of 3.
Once you have an open data table format, you need:
* Interoperability between the open data table formats, as provided by Apache XTable (Incubating) and a few other projects.
* Open standards support from each component of the platform, notably including the data catalog; these must be interoperable, or you will still experience lock-in (as shown in the figure).
* Open table services for functions such as compaction, clustering, indexing, and cleaning - usually reserved to proprietary platforms.
Compute is then left to be either open or proprietary, leaving your “source of truth” data open and free of lock-in.
To see how such an architecture might be implemented, see Dipankar’s excellent blog post.
onehouse.ai/blog/open-table-…
#onehouse #dataengineering #nolockin
#datalakehouse #opendatalakehouse
#apachehudi #apachextable #opensource
1
3
138
9 Oct 2024
👍 Open table formats - @apachehudi Hudi, Apache Iceberg, and Delta Lake - are crucial to data interoperability.
🧐 But the open data lakehouse requires more than formats.
💪 Our new blog post from Dipankar Mazumdar sheds light on what constitutes a truly open data architecture.
onehouse.ai/blog/open-table-…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable

2
5
553
2 Oct 2024
Open Source Data Summit is underway! @byte_array of @Onehousehq is delivering the opening keynote. Come join us.
opensourcedatasummit.com/?ut…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

2
97
27 Sep 2024
🛣️ Why are people moving to open source data catalogs? The answer may be in the word “open.”
✨ Key projects include Unity Catalog, DataHub, Apache Gravatino, and Apache Polaris.
🔁 Come join our panel of skilled practitioners, including our own @KyleJWeller , for a deep dive.
opensourcedatasummit.com/?ut…
#onehouse #dataengineering #nolockin
#datalakehouse #apachextable #opensource

2
4
310
26 Sep 2024
☝️ What if you could use the catalog(s) and query engine(s) of your choice, against a single source of truth?
🐎 In this blog post, Po Hong shows you how to make that vision real.
😃 And see our cool infographic for a few useful data architecture principles.
onehouse.ai/blog/why-data-ar…
#onehouse #dataengineering #nolockin
#universaldatalakehouse #apachextable #opensource

1
1
233