
17 Oct 2025
No longer just “faster than”;
Now, @apachehudi is also “faster on” #apacheiceberg . Thanks to @apachextable
17 Oct 2025

[Blog] Struggling with Apache Iceberg performance when your data dimensions get too hot? 🔥🌡️
Frequent updates and deletes in Iceberg can lead to a "chilly meltdown," forcing a tough choice between fast writes and efficient reads. 🥶 But what if you didn't have to compromise? 🤔
In this recent blog, I explored how you can get the best of both worlds by combining the power of @apachehudi with @apachextable to serve fast, native Iceberg tables.
Read the full post to learn how to get fast writes and reads with Iceberg:
👉 onehouse.ai/blog/how-to-save…
#ApacheIceberg #ApacheHudi #ApacheXTable #DataLakehouse

1
6
1,894

17 Oct 2025
[Blog] Struggling with Apache Iceberg performance when your data dimensions get too hot? 🔥🌡️
Frequent updates and deletes in Iceberg can lead to a "chilly meltdown," forcing a tough choice between fast writes and efficient reads. 🥶 But what if you didn't have to compromise? 🤔
In this recent blog, I explored how you can get the best of both worlds by combining the power of @apachehudi with @apachextable to serve fast, native Iceberg tables.
Read the full post to learn how to get fast writes and reads with Iceberg:
👉 onehouse.ai/blog/how-to-save…
#ApacheIceberg #ApacheHudi #ApacheXTable #DataLakehouse
1
4
2,125

2 Sep 2025
Hudi Streamer is your all-in-one tool for building up a data lakehouse. Out of the box, it provides a wide range of data source support. You can connect it with @debezium that continuously reads change logs from a Postgres table, or you can read incremental changes from another @apachehudi table to form a chain of data processing pipelines.
Beyond data sources, Hudi Streamer also supports data transformations, managing table services like compaction and clustering, and syncing with multiple data catalogs, such as @ApacheHive Metastore, AWS Glue Catalog, Google BigQuery, @DataHubCloud, and more through the @apachextable extension.
Read chapter 8 of "Apache Hudi™: The Definitive Guide", which shows you real-world examples of using Hudi Streamer to build a data lakehouse. This is the first book ever written about @apachehudi, by industry experts: @_xushiyan, Prashant Wason, @SudhaSakthee, and @RebeccaBilbro.
👉 Get a free copy of the e-book (8 early-release chapters now available!): onehouse.ai/whitepaper/apach…
#ApacheHudi #DataLake #DataEngineering #DataLakehouse

8
253
29 May 2025
What happens when 𝘮𝘢𝘴𝘴𝘪𝘷𝘦 𝘴𝘵𝘳𝘦𝘢𝘮𝘪𝘯𝘨 𝘸𝘰𝘳𝘬𝘭𝘰𝘢𝘥𝘴 meet the reality of maintaining Iceberg metadata at scale?
We just dropped a deep-dive blog that pulls back the curtain on our experience managing 𝗻𝗲𝗮𝗿-𝗿𝗲𝗮𝗹-𝘁𝗶𝗺𝗲 𝗶𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻 𝘄𝗼𝗿𝗸𝗹𝗼𝗮𝗱𝘀 to Apache Iceberg tables for the past 24 months at Onehouse.
Spoiler: expireSnapshots and deleteOrphanFiles are NOT your best friends at high scale.
💥 In this post:
•Why Iceberg’s default snapshot expiration can 𝗯𝗹𝗼𝘄 𝘂𝗽 𝘆𝗼𝘂𝗿 𝗦𝗟𝗔𝘀
•How orphaned file cleanup can turn into a “𝘁𝗼𝗼-𝗯𝗶𝗴-𝘁𝗼-𝘀𝘂𝗰𝗰𝗲𝗲𝗱” table operation
•Why most vendors quietly recommend daily/weekly/monthly maintenance ops 😬
•How 𝗔𝗽𝗮𝗰𝗵𝗲 𝗫𝗧𝗮𝗯𝗹𝗲 helped us crack the code — with a custom FileCleanupStrategy, timeline-powered cleanups, and 𝗮𝘀𝘆𝗻𝗰 𝘀𝗲𝗿𝘃𝗶𝗰𝗲𝘀 𝘁𝗵𝗮𝘁 𝗱𝗼𝗻’𝘁 𝗯𝗹𝗼𝗰𝗸 𝗶𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻
Whether you’re building for high-frequency CDC, streaming, or just love Iceberg enough to push it past its comfort zone, this one is worth the read. 🧠
📝 Blog: onehouse.ai/blog/from-the-tr…
🔍 Get into the weeds. Get real-world lessons. Get your Iceberg game ready for the streaming age.
#ApacheIceberg #DataLakehouse #StreamingData #ApacheHudi #MetadataOps #XTable #Onehouse #OpenLakehouse #DataEngineering #BigData #CDC #LakehouseOps #IcebergInternals #RealTimeData #ApacheXTable #DataFreshnessSLA

3
6
269
23 May 2025
🛬 We’ve upstreamed a good chunk of multi-catalog functionality from Onehouse to Apache XTable (Incubating)
If you were wondering what the "X" meant, it meant "everything cross-table". XTable now operates beyond just the table format translation and helps across catalogs.
👉 Read the full blog here:
dipankar-tnt.medium.com/intr…
Many catalogs are working towards federation, where credential vending and policy enforcement are done across engines, at query time. Syncing from the writers to other catalogs has multiple advantages over this model. Both models can be used together to address some of these issues.
1️⃣ Query side federation from a single catalog, while helping streamline governance, still builds too much reliance on that one catalog vendor. E.g., all permissions are defined/stored/managed in that single catalog.
2️⃣ It’s a perpetually in-progress project. Engines and vendors must understand each other’s systems and keep up with new features.
3️⃣ Latency? Making more external API calls to other catalogs during query planning time.
4️⃣ Things like Hive Metastore API or Iceberg Rest catalogs can become common protocols, but you need an open, independent way to manage N catalog endpoints if you use N engines.
We are operating on the first principles we established, right at the company's start.
Refresher: onehouse.ai/blog/onehouse-co…
It’s been a fascinating journey, to say the least, jumping across these different hurdles that stand in the way of truly unfettered data architecture.
Looking forward eagerly to the next.. 👍
#ApacheXTable #DataEngineering #OpenLakehouse #ApacheHudi #ApacheIceberg #DeltaLake #CloudDataPlatforms #OpenData #MetadataManagement #DataArchitecture #Interoperability #DataLakehouse #DataLake #BigData #Data #OpenFormats #DataCatalogs

1
4
460
21 May 2025
At #OpenXData virtual conference:
Google BigQuery seems from implement the same approach of having an "internal" metadata format for managed #ApacheIceberg tables, the iceberg manifests etc are exported as read-only snapshots for access from other engines.
This approach is same as : Snowflake managed Iceberg tables and @apachehudi @apachextable .
Curious how OneLake implements it. Is the source of truth for query planning Iceberg metadata or an internal catalog/metadata.
#OpenXData

1
2
364
17 Apr 2025
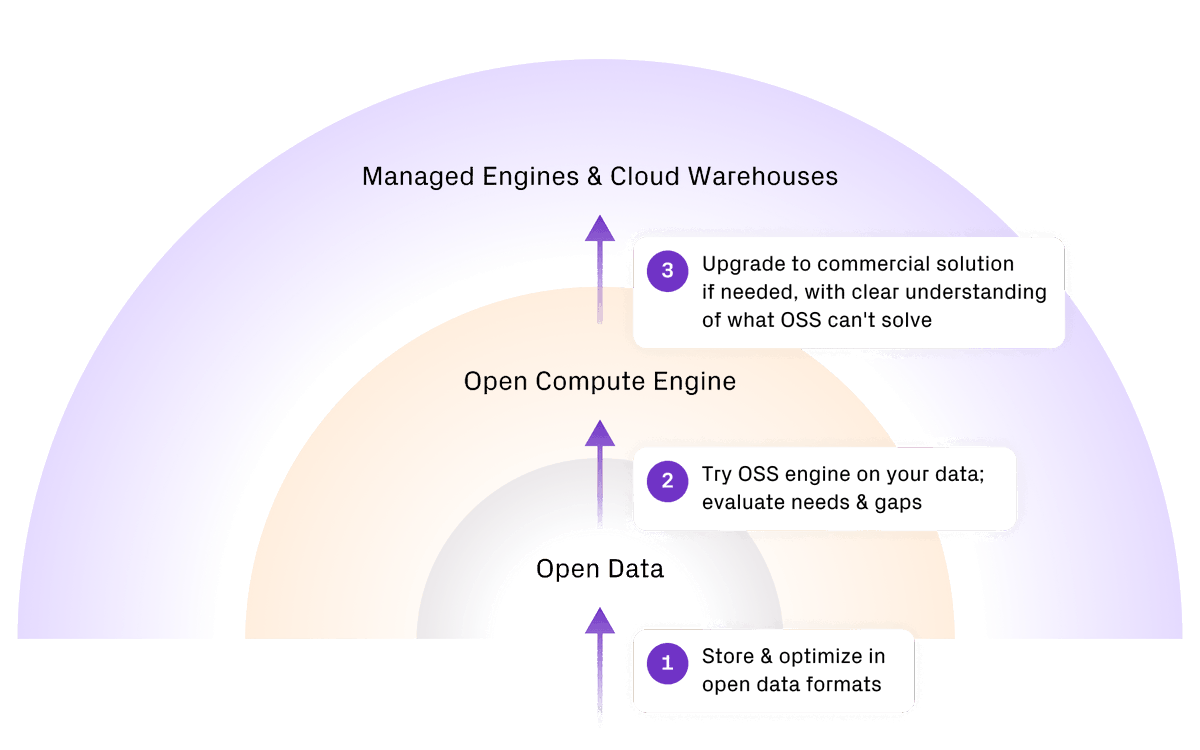
🎉The final brick in our open data lakehouse platform: OpenEngines. 🏄🌊
Over the past few years, we have been laying the foundation for something bold at Onehouse — a truly open-first architecture for the data lakehouse that can serve diverse data needs.
Effectively, a cloud service that can deliver what my past teams at Uber, LinkedIn, and other companies built internally to democratize and infuse data across the company and its products, at a fraction of the cost, and close the gaps to operationalize such a platform.
We started with the basics:
• Open file formats (Parquet, Orc, JSON, CSV, XML, Avro, …)
• Open table formats (Hudi, Iceberg, Delta)
• Interop across formats, not fragmentation (Apache XTable)
Then, we moved up the stack:
• Catalog interoperability with multi-catalog sync (proposed to XTable)
And today, we’re flipping the final switch — 🧠 Introducing Open Engines™: Now you can deploy best-in-class open source compute engines — Flink, Trino, Ray — directly on your open data, with zero friction, 10x lower ops costs, and way better performance than your self-installed OSS versions.
Because:
1️⃣ Open data is only half the story: To unlock true choice, portability, and innovation, compute needs to be open too. Otherwise, your data is just in a different fancy jail in open formats.
2️⃣ Spark or any other engine is not best at everything: We’re talking non-stop about AI, but that needs a strong foundation for your data, that is multi-engine ready. Check out our deep-dive comparison blogs for yourself.
3️⃣ Starting engine-first is fundamentally flawed: Your data is everything, and you need to move from open data -> open engine -> closed compute platforms. Not the other way around!
4️⃣Picking the wrong engine or lack of flexibility will cost you: We’ve debated endlessly on tiny bits of table metadata, what about the compute engine you spend millions of dollars on? At this scale, data and its needs are growing; even a 10-20% difference in cost-performance is a meaningful spend or saving.
With Open Engines, Onehouse is now the only “multi-engine, multi-cloud”, open data platform in the market.
The universal data lakehouse becomes a living, breathing product, not just a coveted architecture, accessible with a few clicks in your browser.
And it’s open — all the way through.
👉 Read the full story: onehouse.ai/blog/announcing-…
🤝If you are more than curious, there’s a webinar where I’ll hang in chat: onehouse.ai/webinar/your-dat…
🪖 Let’s build our data platforms the right way: open first, data first.
#OpenFirst #OpenEngines #DataLakehouse #OpenSource #ApacheHudi #ApacheIceberg #DeltaLake #ApacheXTable #OpenCompute #Onehouse #DataEngineering #Data #DataLake #BigData #Analytics #MachineLearning #DataScience #StreamProcessing
1
11
761
6 Mar 2025
Recently, on a podcast, I was asked, “Why Hudi?”. Not a history lesson, but “Why Hudi today?”
Most of what I do is telling companies to collect, store, and process more data and make everything better. So, it's only fair that I write down 21 reasons, not just one.
🔗 Read the full blog post here: hudi.apache.org/blog/2025/03…
Here’s the rundown. Here’s why Hudi should be at the core of your data platform
1️⃣ Well-Balanced Storage Format
2️⃣ Database-like Secondary Indexes
3️⃣ Efficient Merge-on-Read (MoR) Design
4️⃣ Scalable Metadata for Large-Scale Datasets
5️⃣ Built-In Table Services
6️⃣ Data Management Smarts
7️⃣ Concurrency Control Purpose-built For the Lake
8️⃣ Performance at Scale
9️⃣ Out-of-box CDC/Streaming Ingestion
🔟 First-Class Support for Keys
1️⃣1️⃣ Streaming-First Design
1️⃣2️⃣ Efficient Incremental Processing
1️⃣3️⃣ Powerful Apache Spark Implementation
1️⃣4️⃣ Next-Gen Flink Writer for Streaming Pipelines
1️⃣5️⃣ Avoid Compute Lockins
1️⃣6️⃣ Seamless Interop Iceberg/Delta Lake and Catalog Syncs
1️⃣7️⃣ Truly Open and Community-Driven
1️⃣8️⃣ Massive Adoption Across Industries
1️⃣9️⃣ Proven Reliability in High-Pressure Workloads
2️⃣0️⃣ Cloud-Native Lakehouse-Ready
2️⃣1️⃣ Future-Proof and Actively Evolving
Come join our community as we work towards adding 21 more this year.
#ApacheHudi #DataLakehouse #BigData #DataEngineering #StreamingData #CDC #ApacheFlink #ApacheSpark #OpenTableFormat #DataLakes #DataManagement #OpenSource #ApacheXTable #DataInfrastructure #CloudData #RealTimeAnalytics #MachineLearning #DataPlatform 🚀

6
13
1,863
24 Oct 2024
❄️ Learn how to cut Snowflake data ingestion costs by 70% or more…
⚡️ …with much faster updates…
.
👆 …and a single “source of truth” data copy, for all use cases.
🗣️🗣️ Ryan Garrett and Andy Walner of @Onehousehq explain it in in our webinar, three short weeks away.
:/onehouse.ai/webinar/the-fast…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

1
1
1
309
23 Oct 2024
🚁 Are you going to AWS re:Invent in Las Vegas this December?
🏡 Now is the time to add @Onehousehq to your plans.
🎸We rock events with cool swag, awesome demos, and new ideas.
🔭 Get an unvarnished view of open data systems and standards from the experts.
📋 Put Onehouse on your agenda.
reinvent.awsevents.com/
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

1
116

23 Oct 2024
We have simply decided not to be yet another Kafka wrapper. By doing so, we can build and fully optimize the network transport, storage and all the other important parts of the message streaming server :)
1
4
341
21 Oct 2024
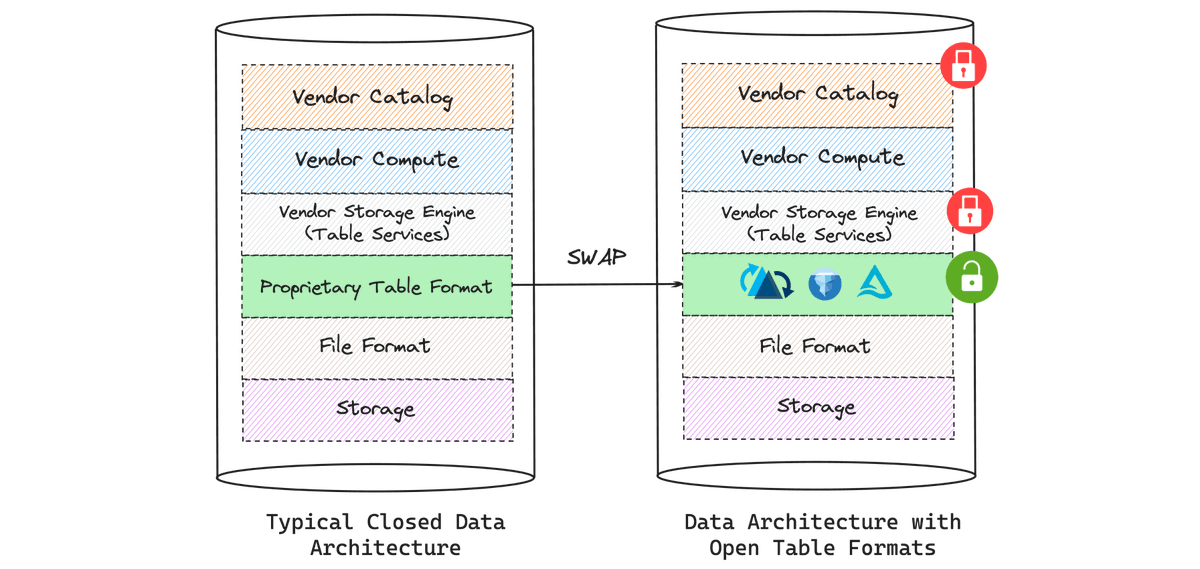
Is an Open Table Format the Same as an Open Data Lakehouse? Part 3 of 3.
Once you have an open data table format, you need:
* Interoperability between the open data table formats, as provided by Apache XTable (Incubating) and a few other projects.
* Open standards support from each component of the platform, notably including the data catalog; these must be interoperable, or you will still experience lock-in (as shown in the figure).
* Open table services for functions such as compaction, clustering, indexing, and cleaning - usually reserved to proprietary platforms.
Compute is then left to be either open or proprietary, leaving your “source of truth” data open and free of lock-in.
To see how such an architecture might be implemented, see Dipankar’s excellent blog post.
onehouse.ai/blog/open-table-…
#onehouse #dataengineering #nolockin
#datalakehouse #opendatalakehouse
#apachehudi #apachextable #opensource
1
3
138

17 Oct 2024

1
3
12
972

14 Oct 2024
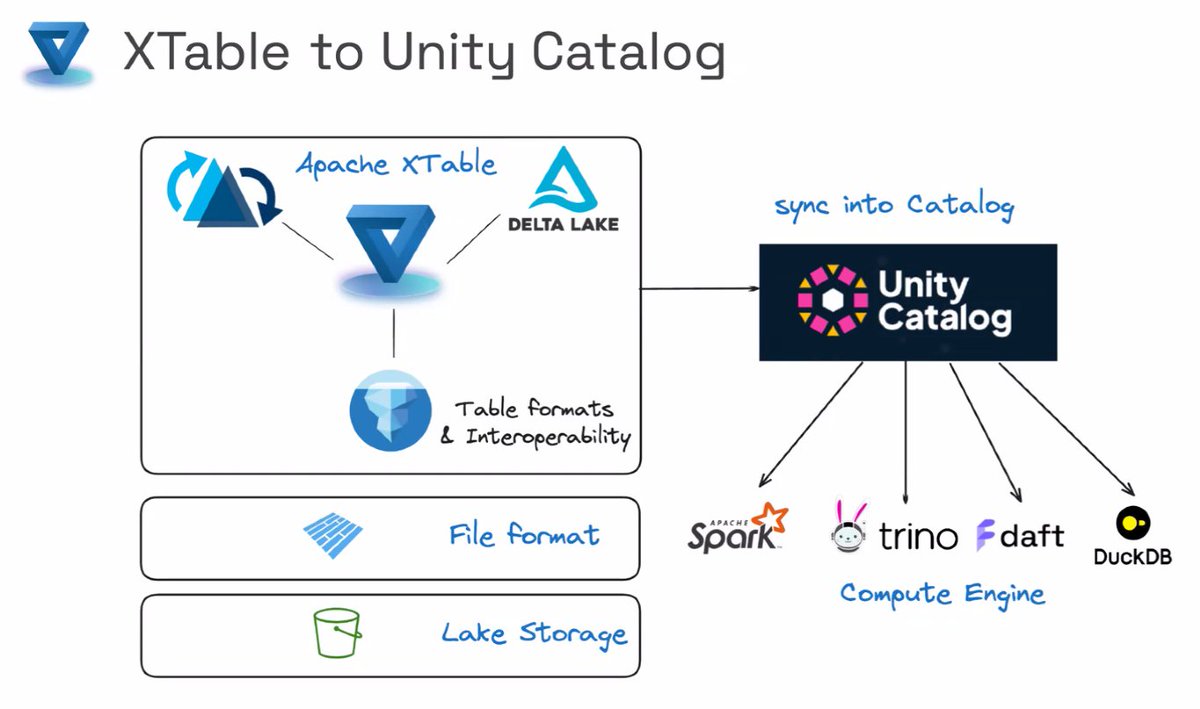
Join us for the next #UnityCatalog Community Meetup on Thursday, Oct 17 at 8:30AM PST! 🌟🗣
🔎 What's on the agenda:
@apachextable and UC - @Dipankartnt
Questions/AMA/Roadmap - @dennylee
Zero to Hero series - Victoria Bukta
RSVP here: hubs.la/Q02TfKqb0
#opensource #oss

1
2
194
9 Oct 2024
👍 Open table formats - @apachehudi Hudi, Apache Iceberg, and Delta Lake - are crucial to data interoperability.
🧐 But the open data lakehouse requires more than formats.
💪 Our new blog post from Dipankar Mazumdar sheds light on what constitutes a truly open data architecture.
onehouse.ai/blog/open-table-…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable

2
5
553
5 Oct 2024
1️⃣ There is an unhealthy romanticism for war analogies in our industry. After all, we are here to build software, not take sides in wars 🙂. Thankfully, this does not matter since #opensource does not need vendor blessings to thrive. It just needs a strong community intent on building software.
2️⃣ I get asked about @apachehudi 's narrative, positioning, and so on. It's not that complex; there is no "narrative." Apache Hudi and its community are simply happy to continue innovating cutting-edge features (check out our 1.0 talk) and powering a good chunk of Fortune 500 data lakehouses without much drama (check out the blog on our site). We interop with the other two formats through @apachextable and move on with life.
3️⃣ But on all this drama, I find it a bit ironic that there is a lot of "closed" criticism against hashtag#Databricks, who gave the industry a powerful open compute framework like #ApacheSpark. While a good chunk of #ApacheIceberg vendors offering completely closed computing services, no real hashtag#opensource track record, are all claiming an open status by association.
theregister.com/2024/10/03/a…
#data #datalake #datawarehouse #deltalake #apachehudi #apacheiceberg
1
5
13
1,438
2 Oct 2024
Open Source Data Summit is underway! @byte_array of @Onehousehq is delivering the opening keynote. Come join us.
opensourcedatasummit.com/?ut…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

2
97
27 Sep 2024
🛣️ Why are people moving to open source data catalogs? The answer may be in the word “open.”
✨ Key projects include Unity Catalog, DataHub, Apache Gravatino, and Apache Polaris.
🔁 Come join our panel of skilled practitioners, including our own @KyleJWeller , for a deep dive.
opensourcedatasummit.com/?ut…
#onehouse #dataengineering #nolockin
#datalakehouse #apachextable #opensource

2
4
310
26 Sep 2024
☝️ What if you could use the catalog(s) and query engine(s) of your choice, against a single source of truth?
🐎 In this blog post, Po Hong shows you how to make that vision real.
😃 And see our cool infographic for a few useful data architecture principles.
onehouse.ai/blog/why-data-ar…
#onehouse #dataengineering #nolockin
#universaldatalakehouse #apachextable #opensource

1
1
233
24 Sep 2024
🌏 Open source software powers the world.
🔋 And user communities power open source projects.
🤡 How to keep these communities lively?
🎛️ Learn all about it, from our own @SudhaSakthee and a panel of experts.
⏳ At Open Source Data Summit, next Wednesday.
opensourcedatasummit.com/?ut…
#onehouse #dataengineering #nolockin
#datalakehouse #apachehudi #apachextable #opensource

1
77