
CogVideoX-5B-I2Vについて、現時点でわかったことまとめ。(間違ってたらご指摘ください)
商用利用について
CogVideoX-5B-I2Vは、商用利用が可能ですが、特定のライセンスを取得する必要がある。ライセンスを取得すれば、追加料金なしで商用利用ができるらしい。
フレーム数
最大49フレームが推奨されている。
解像度とフレームレート
生成される動画の解像度は720x480ピクセルで、フレームレートは8fps(1秒間に8フレーム)。
動画の長さは6秒(合計49フレーム)で固定されている。
メモリ消費量(VRAM)
メモリの使用量は精度によって異なる。
BF16(半精度浮動小数点):16GB
FP8(8ビット浮動小数点):12GB
Q4(量子化精度):9GB以上
ステップ数(Step)
生成プロセスではデフォルトのステップ数が50ですが、30ステップに減らしても画質の大きな違いはなく、生成速度が少し速くなった。
プロンプトの重要性
プロンプトやネガティブプロンプトは、生成される動画のクオリティに大きく影響する。これは調整が難しく、試行錯誤が必要。沼りポイント。
Google Colabでの使用
成功。Google Colab上で利用可能。特に、A100 GPUを使うと処理が高速化される。ただ、Fluxで画像生成した時ほどの驚きはなかった。Onediffを使えば違うかもしれないので、さらに研究が必要。

🩵朗報!🩵
【れん×みゆきTips】ギャルを踊らせることに成功💃
しかも、ローカルで。
しかも、RTX4070(12GB)で。
これはもう感涙モノだろ😭
ComfyUI歴1ヶ月のアラフィフ社畜副業戦士でコレなら、世の天才たちは裏でどれだけスゴいことやってんだか…
しかし、動きはぎこちないし左胸の上になんか飛び出てるし、これは解決できるのだろうか…
うーん……
いや、解決するんですけどね😆
自分で壁を作って乗り越えるの、ほんとめちゃくちゃ楽しい🥺
1
17
2,685

26 Sep 2024
cogvideo 5B i2v with OneDiff Nexfort pytorch compiler backend,u have to upgrade to torch 2.4 ,then from the second time the inference speed will reach around 4.8 s/it


1
5
1,887

11 Sep 2024
I give TensorRT (1) a try today for fp8/int8 quantization and think OneDiff (2) still has decent edge that easily gives me similar speed as fal.ai out of the box.
Results look promising from TensorRT's blog posts, but it's a typical large company workflow vs. open source solutions people vote with their feet..... You got to install a number of Nvidia deps on linux, calibrate with a few thousand prompts, export an onnx file, build a tensorrt engine, do graph surgery on the onnx file, generate a trt plan that took ~10 mins, and swap that in to another trt specific inference script ...
Meanwhile my earlier OneDiff prototype just does dynamic tracing, produces reusable graph ~1min, with matching perf, can do quick dynamic lora swapping and even support comfyui.
At high level, these frameworks aim to do the same thing, basically produce a compiled, fused, layout optimized computation graph for diffusion models. But
large company and open source project just have different tastes on simplicity and UX when facing tradeoffs on best benchmarked performance.
1) github.com/NVIDIA/TensorRT-M…
2) github.com/siliconflow/onedi…
1
3
347



I managed to get everything working, I was mostly struggling to get oneflow working.
The first problem I had, was I was trying to use python3.12 for which there are no working builds (as far as I can tell). So I swapped down to 3.11.
Then I went down the red herring path trying to understand which oneflow was the right oneflow, there are several distinct pip package repos, many of them include 1.0 packages while the ones I got working with onediff are the 0.9.1 dev builds from github.com/siliconflow/onefl…
I also tried using nexfort, because the onediff readme implies that you only need either nexfort or oneflow. However if you are using the OneDiffX diffusers extensions, you are forced to use oneflow.
So when I say "one does not simply install oneflow", I mean there's a fairly undocumented/confusing/contradictory matrix of dependencies that are difficult to traverse. I don't say that to simply criticize, just trying to share my experience
thank you for onediff, it's great once you've got it working! <3
2
1
58

20 Jun 2024
Playing with OneDiff accelerated AnimateLCM pipelines. This was generated realtime.. need to try some last frame feedback with SparseCtrl...
3
1
7
1,253

通过晓之以情动之以理苦苦哀求,onediff表示他们完成手头的重构后,会比较容易发布windows原生加速版本,不久后会有时间表。有一说一,如果有windows版,他们不会这么小众,品牌影响力会大得多。

加速这块有个民间高手——onediff,比tensorrt加速更多,而且能和lora、controlnet、ip adapter、instantid一起工作,加载方式也更优雅。唯一的问题,linux only,想在windows上跑要用wsl。
github.com/siliconflow/onedi…

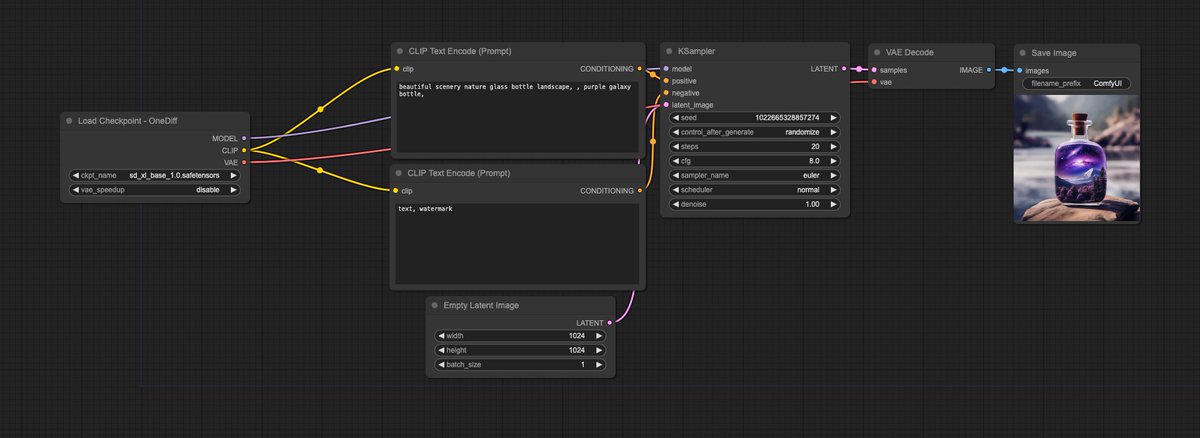
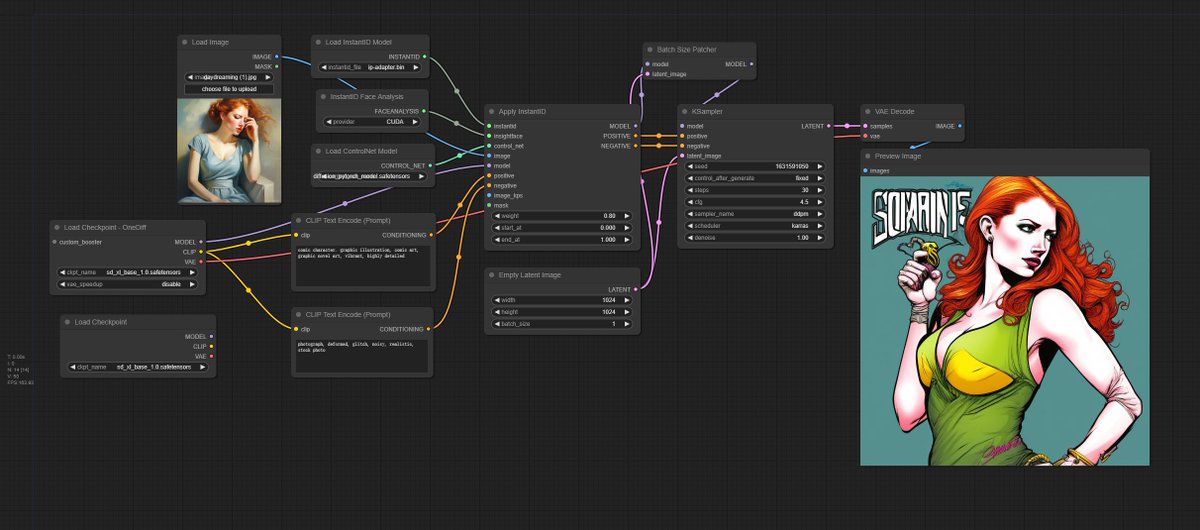
2
6
3,369
加速这块有个民间高手——onediff,比tensorrt加速更多,而且能和lora、controlnet、ip adapter、instantid一起工作,加载方式也更优雅。唯一的问题,linux only,想在windows上跑要用wsl。
github.com/siliconflow/onedi…
3
6
36
9,555

12 May 2024
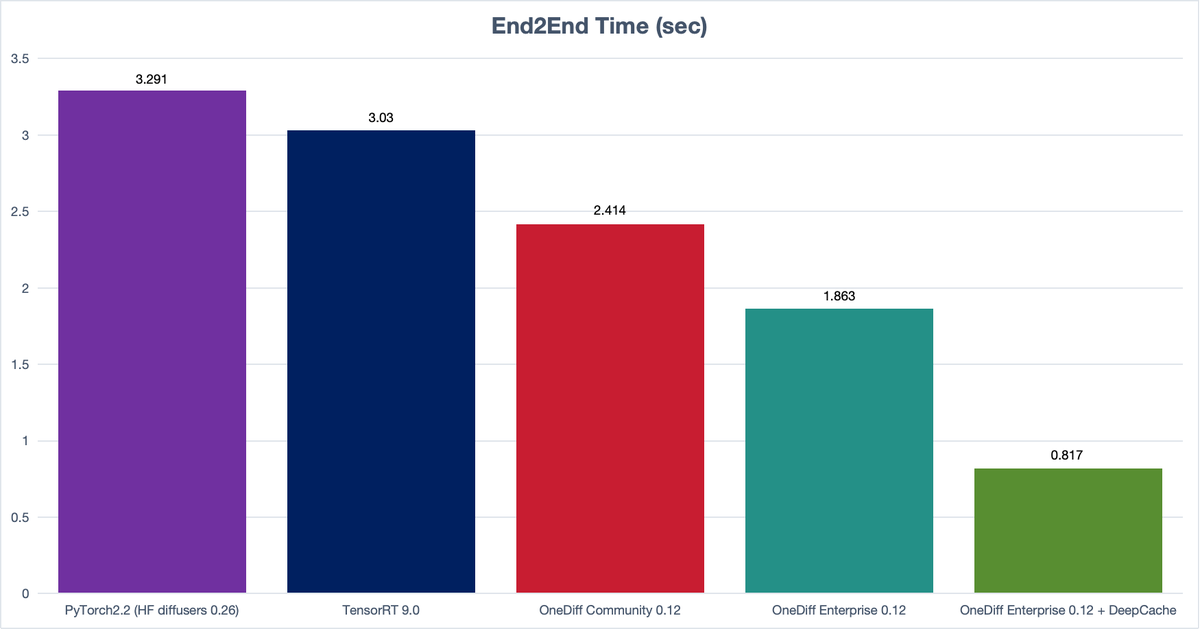
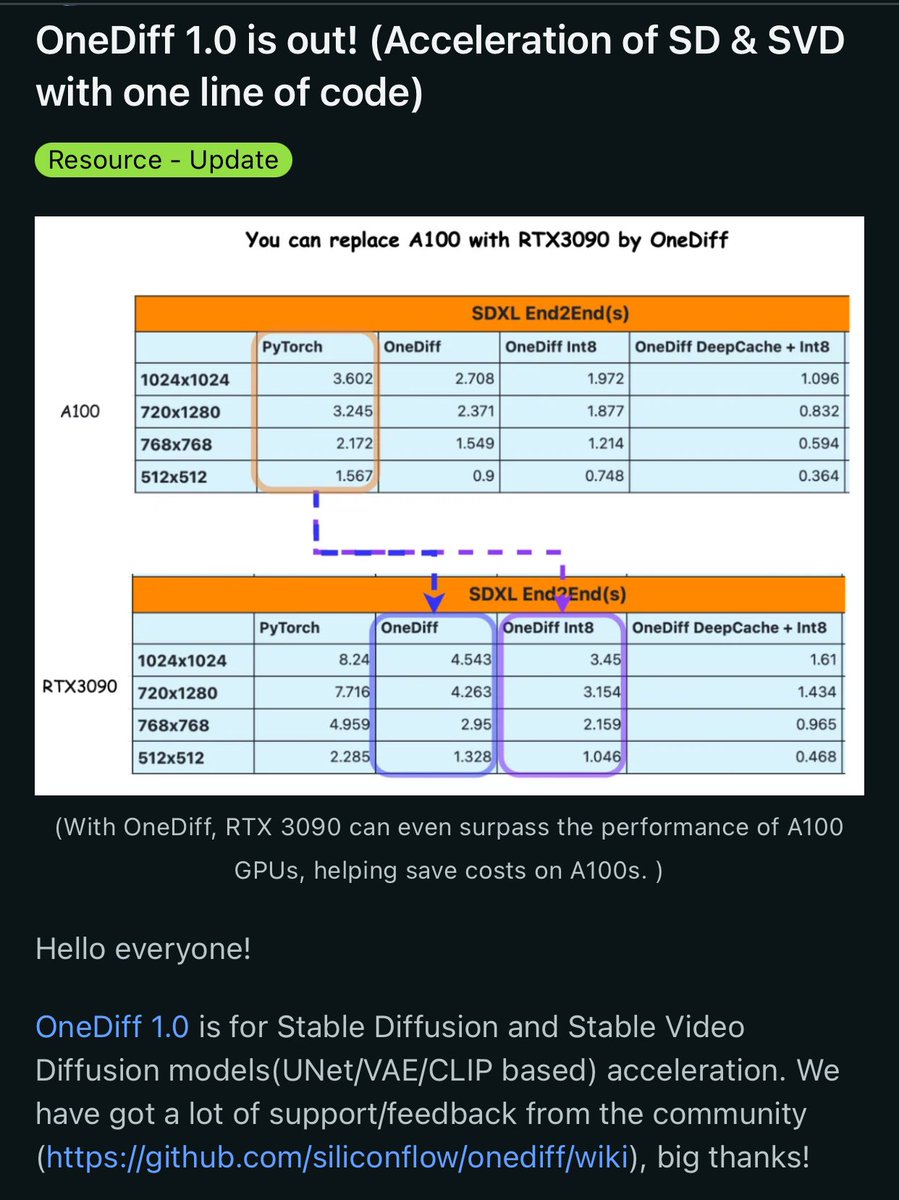
拡散モデルの高速化ツール、OneDiff
StableDiffusionXLの計算がpytorchやTensorRTを使った場合に比べ、2~3割速くなっている。
エンタープライズ版もあるようでそっちだと3倍以上高速化できる。
github.com/siliconflow/onedi…
10
755

18 Apr 2024
“一键”加速 SD 和 SVD!OneDiff v1.0.0正式发布
支持Playground v2.5
支持ComfyUI-AnimateDiff-Evolved
支持ComfyUI_IPAdapter_plus
支持Stable Cascade
提高了VAE的性能
为OneDiff企业版提供了量化工具
github.com/siliconflow/onedi…
1
7
39
3,522

7 Mar 2024
Wow, finally! onediff is waiting for SD3, eager to make it run 2X faster as we do on SDXL and SVD.
2
164




1 Feb 2024
Thanks @SiliconFlowAI for their OneDiff integration of our InstantID! You can enjoy accelerated inference for InstantID (1.8x acceleration on RTX 4090). You can find more details at github.com/siliconflow/onedi…
17 Jan 2024

Thanks @_akhaliq for sharing our work!
TL;DR: We introduce InstantID as the state-of-the-art tuning-free method to achieve ID-Preserving generation with only single image.
Code: github.com/InstantID/Instant…
Project Page: instantid.github.io/




3
13
2,175

18 Jan 2024
We are glad to share that #OneDiff SDXL inference has been integrated into fal.ai playground! SDXL inference at the speed of thought. Let's Check it out!
fal.ai/models/onediff-sdxl @fal_ai_data #SDXL #TextToImage #GenerativeAI
4
291

OneDiff is an out-of-the-box acceleration library for diffusion models (especially for ComfyUI, HF diffusers, and Stable Diffusion web UI).
github.com/siliconflow/onedi…
#ArtificialInteligence #LLM #stablediffusion
6
1,358

20 Dec 2023
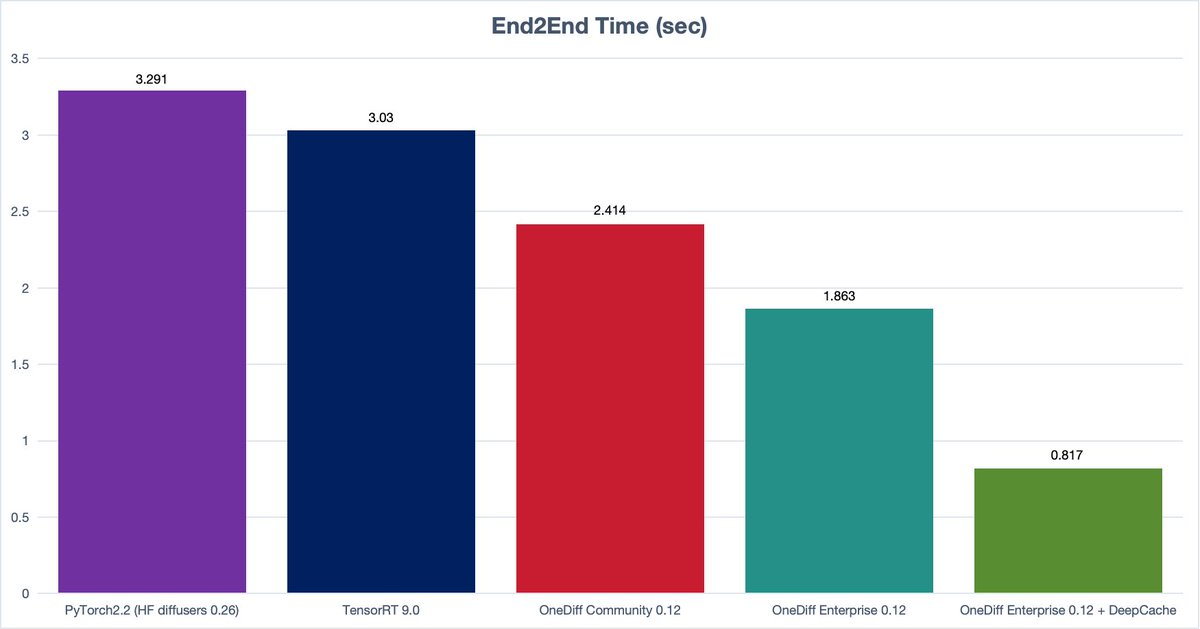
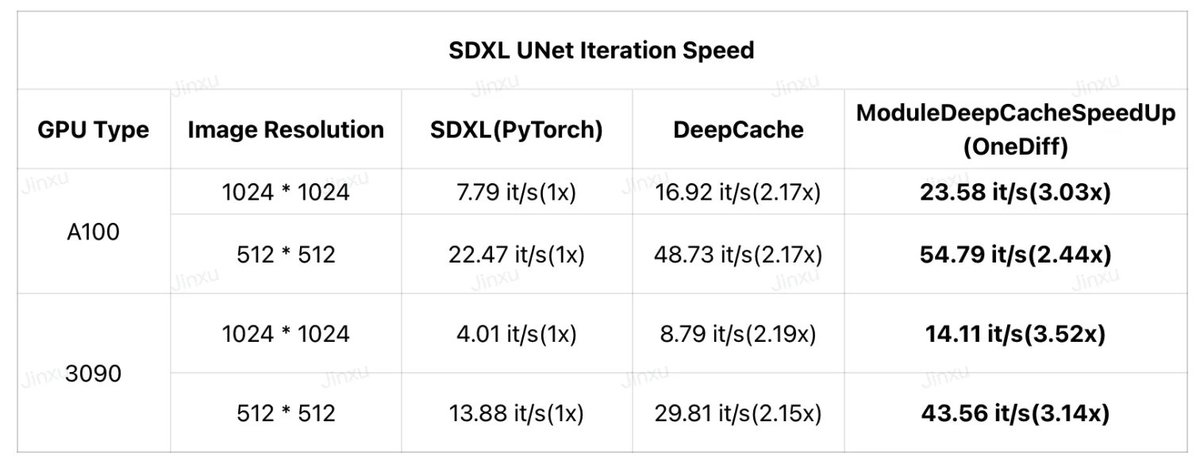
DeepCache is integrated into OneDiff, and DeepCache with OneDiff can achieve 3x speed up😎
See Github:
github.com/Oneflow-Inc/onedi…
and Reddit: reddit.com/r/StableDiffusion…
Big Thanks for Oneflow and OneDiff!
1
8
27
4,311