
8,736 Photos and videos














有意思,从 Token 生成速度与 API 定价为切入点,推导出其推理时的激活参数量,再结合硬件供应链曝光的集群算力总预算,利用 Chinchilla 定律进行交叉验证,就能得到相当靠谱的参数量。
Jun 14

opus4.6 的参数 1.5T 激活参数 100B,而 fable5 的参数 6T 激活参数 400B,短短四个月,参数和激活参数翻了四倍,这游戏可以持续玩的下去么?
1
2
526
亚马逊给 anthropic 投资了 100 多亿,现在偷摸打小报告,图啥呢?
Jun 13

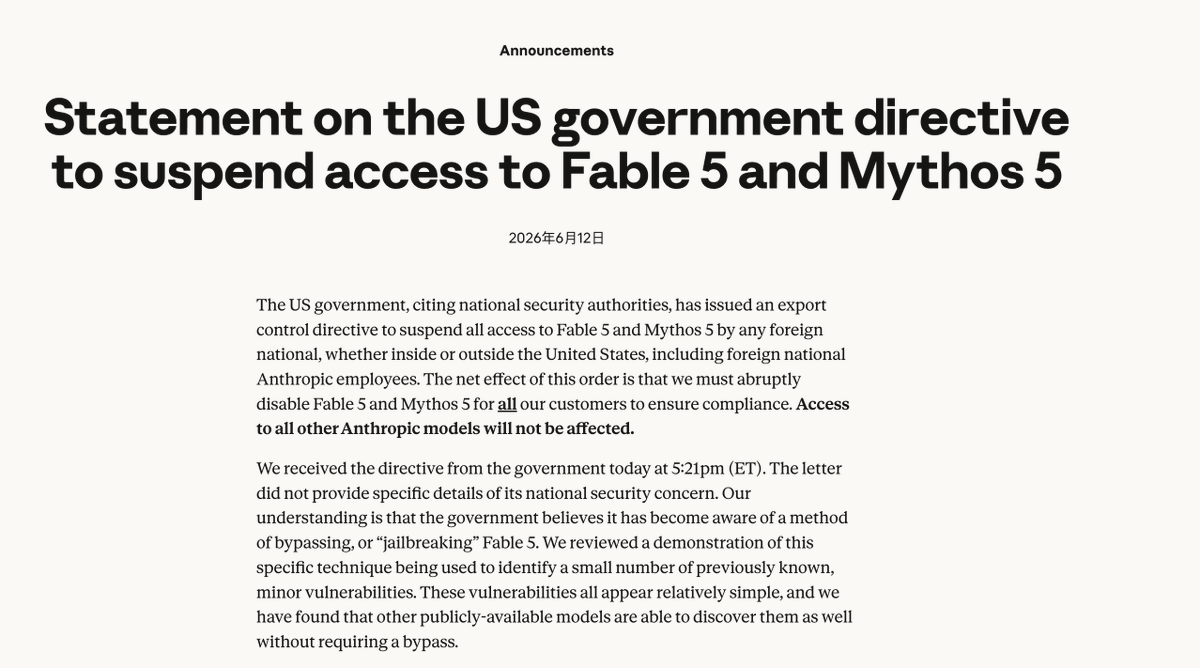
破案了,Anthropic紧急关闭Fable5 的权限,极大可能是因为亚马逊的背刺,向美国政府告密了。
亚马逊的研究人员对 Fable 5 不断刁难,做极限越狱测试,他们通过一系列特殊提示词,不断诱导模型回答原本不应该回答的问题,最终让模型泄露了一些安全漏洞相关的信息。
随后,他们把研究结果整理成了一份安全报告,紧接着美国政府就以国家安全为由,对 Fable 5 和 Mythos 5 采取了限制措施。

4
1
2
1,788
Jun 14

懂LLM的原理,不是为了成为AI专家,而是为了防止自己被自己的想象力吓唬住。
从统计模式到真正的理解,不是量变,而是架构上的鸿沟。LLM(大语言模型)的本质是一个从海量文本中学到的、关于词语序列的条件概率分布。
如果这句太难懂,你可以记住LLM没有什么:
对世界的因果模型(不知道苹果掉下来是因为引力,只知道“苹果”“掉”“引力”经常一起出现)
意图或目标(它不会“想要”回答正确,它只是“统计上倾向于”输出常见序列)
理解或信念(它不会“认为”2 2=4,它只是从数据里看到这个模式极其牢固)
责任或意识(你骂它,它不会伤心;它错了,它不会负责)
建议先学习一下‘概率分布’和‘理解’的区别,再来讨论十年后的事。沿着 LLM 路线永远走不到 AGI,真正的理解需要全新的底层架构。
1
2
709
这哪是旅游啊,这是做社会调研来了
We Were Almost Entirely Wrong About China youtu.be/AOEr5FrW-lY?is=Sm5K… 来自 @YouTube
683

在继承陈先生遗产的实际价值范围内,向银行偿还借款本金27万元以及合同约定的利息
合理
Jun 13

男子意外离世留下27万元逾期贷款,银行起诉家属还款,法院判了
那么,陈先生的父母只需偿还本金和期内利息,还是连罚息和复利也要一并承担呢?最终,法院对案件作出判决,陈先生的父母在继承陈先生遗产的实际价值范围内,向银行偿还借款本金27万元以及合同约定的利息,驳回银行其他诉讼请求。
1
1,755
或者提前适应永不降智的开源模型
Jun 13

Fable 5 不让用了,而且我感觉Anthropic本来就打算限时开放给订阅用户,后面让大家掏钱买credit,走那个路径,量大管饱的时代要结束了。
我担心这几家头部企业补贴消费用户的时代就要结束了,很多平时用的好的模型都开始降智限额,Gemini 降智不要太明显,而OpenAI每次有竞争压力,就会把限额放开,Codex是我目前用的最多的。
各位订阅用户好好珍惜最后的狂欢!
1
3
6,080
大模型被大众所知是 2022 年 11 月 30 日 chatgpt 发布
Jun 13

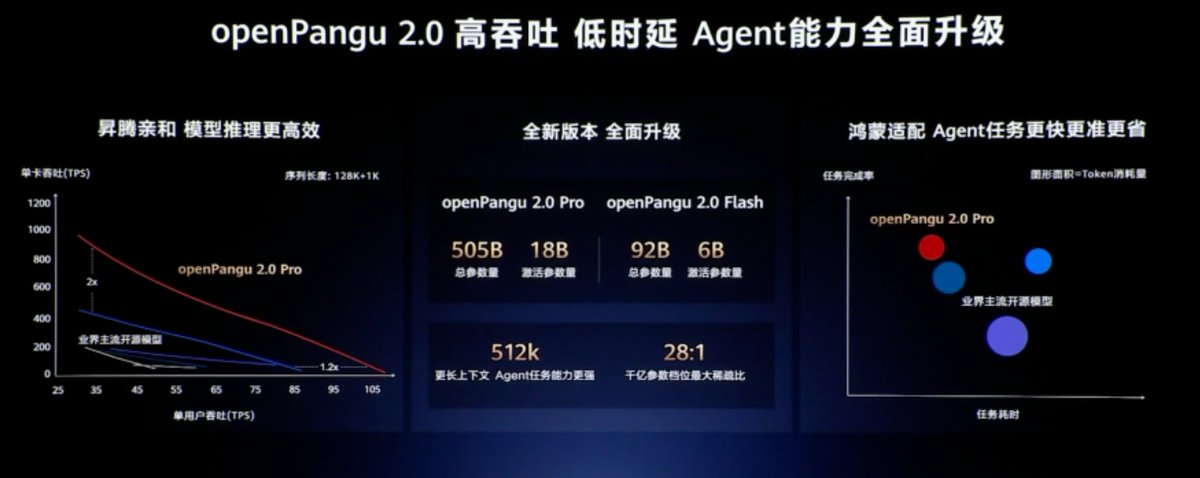
晚上刷到余承东在华为发布会上说盘古是国内第一个大模型,我还真去翻了一下时间线。
PanGu-α 论文是 2021 年 4 月 26 日发的,标题和摘要里已经写了 Large-scale Pretrained Language Models,最高 200B 参数,而百度的 ERNIE 3.0 是 2021 年 7 月 5 日,时间上确实晚了一步。
当然,放到全球看,GPT-3 早在 2020 年就已经把 175B 参数和 few-shot/in-context learning 打出来了,所以「全球都不知道大模型」更像是老余发布会惯用的夸张表达。
但如果只看国内早期中文大模型路线,盘古这波确实有资格说自己起得很早。
发布会上老余宣布 openPangu 2.0 要从 6 月 30 日起陆续开源,最高 505B 总参数、512K 上下文。
老余这次把盘古大模型又重新推到台前,真正的悬念已经变成:当年的「早」,这次能不能变成今天的「强」。
6
2,250
技术上不难,专业 chatbot 都能做到,豆包也可以正确渲染表格和数学公式。聊天软件要把 chatbot 当成一种用户来认真对待。


卧槽
Telegram 发布重大更新
- 现在机器人能发富文本了
- 还能让AI帮你管理群聊
- Telegram 终于上手表了
这不得够微信学习十来年??
以前 bot 回消息只能纯文本,现在AI Bot支持:
・表格、清单、嵌套引用块
・行内插图、图片轮播、拼图
・可折叠段落、脚注、标题锚点
・数学公式、上下标
单条最多塞 32768 个字符,超过 8000 字会自动折叠成一个"显示更多"按钮
适合 AI bot 输出长答案、做内容卡片的场景
1
1
1,070
西方的小费起源于中世纪的欧洲,原本是贵族给仆人的赏钱,带有一种居高临下的施舍性质,并不是多高级的财富分配方式。资本主义包装之后,雇主用它把本该由自己承担的员工基本薪资,转嫁给了消费者,成功的将阶级矛盾变成了无产阶级内部矛盾。中国讲究明码实价,不搞这些引发人民内部矛盾的幺蛾子。

我一直不理解墙国低端人口莫名其妙的中产感。。。明明四五亿自由职业送外卖开滴滴,非要学着中产反对小费制度。。。明明失业率快四成了,非要学着中产吹捧搞大下岗的朱镕基。。。并不是谁对谁错的问题,而是没有认清自己底层的角色。。。每次在外边吃饭,想到马上被AI淘汰去端盘子,我都会多给些小费
1
1
3
856
灰域所映射的可能是资本现实主义(Capitalist Realism),英国理论家马克·费舍(Mark Fisher)说,“(资本现实主义)更像是一种无孔不入的氛围,不仅制约着文化的生产,也制约着工作和教育的规范,并作为一种无形的屏障制约着思想和行动。”
费舍被西方中心主义入脑入魂,看不到其他可能性,废了。

在《极乐迪斯科》里,一群人试图在无线电时代开发一款超越时代的网络游戏,可能因为灰域的诅咒,他们失败了。同样超越时代的《极乐迪斯科》成功发售了,但好景不长,公司和IP都被资本窃取了,甚至可以说,ZA/UM已经预言了自己会被灰域打败。灰域是人类毁灭性的欲望,是《神圣而可怖的空气》。
1
500



Datou retweeted

Jun 12
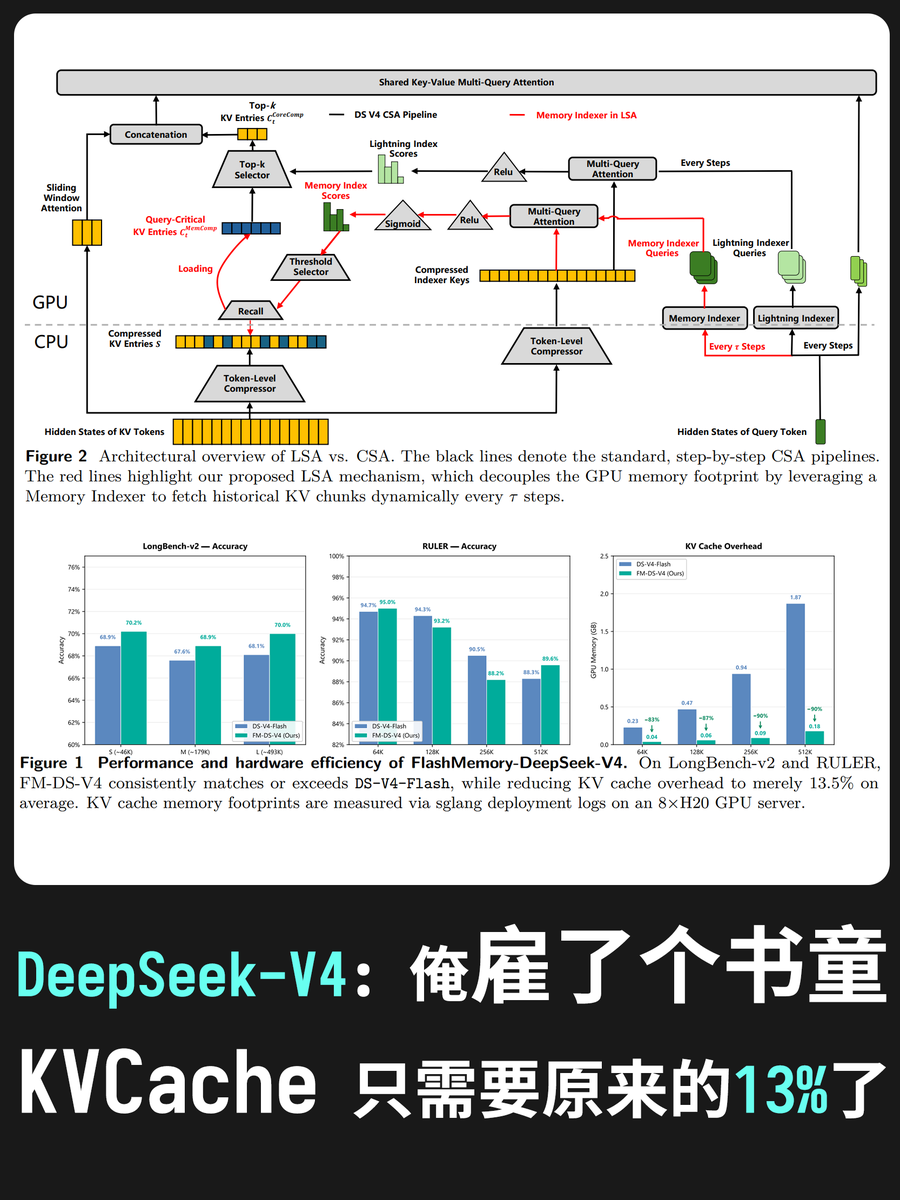
魔法! DeepSeekV4 上下文内存压缩到1/10!
大家都知道 DeepSeekV4 是支持1M上下文的, 而且经过了极度优化, 如果要真的用到1M上下文, 显存占用只需要10G左右, (对比之下 DeepSeek-V3.2 大概需要84G显存). 然后我刚看到了FlashMemory这个论文, 直接能把显存占用压到 1.3GB! 甚至输出效果不降反升!
哥们你骗兄弟可以, 骗自己就没意思了, 真的吗? 压缩后反而性能上升? 我赶紧看了论文细节:
咱们先复习一下传统做法: 模型每吐出一个字,都要把之前的几十万字重新看一遍(这就是全局注意力).
FlashMemory 的做法是: 预测未来需要什么, 它内置了一个神经内存索引器(Neural Memory Indexer, 其实就是个小模型了),能够主动预判接下来生成内容时需要用到历史文本里的哪些片段. 然后预先准备好这些片段, 接下来只要做到命中率超高, 那么这个提升就绝对有效. 即它的假设是, KVCache里面的东西并不是生成每个字的时候全都需要的, 只需要按需提前加载即可.
很像做作业的时候, 把参考资料摊满桌子, 然后优化了一下就是把参考资料需要用到的部分直接拍照, 用的时候看照片就行了.
那么听上去很简单, 但实际的难点在于, 训练一个专用的索引器小模型, 需要把 DeepSeek-V4模型加载到显存里一起炼. 相当耗费算力.
于是这篇论文第二个亮点来了, 它搞了个解耦训练. 他们把这个索引器当成一个标准的"双编码器(Dual-encoder,类似做搜索推荐的模型)"来单独训练. 在这个过程中,根本不需要把庞大的 DeepSeek-V4 基座模型加载到显存中. 这让训练成本断崖式下降,且兼容标准的检索(Retrieval)训练框架. (简单来讲就是它是通用方法训练的, 通过query预测需要检索哪些长句子. 所以其实是个通用模型)
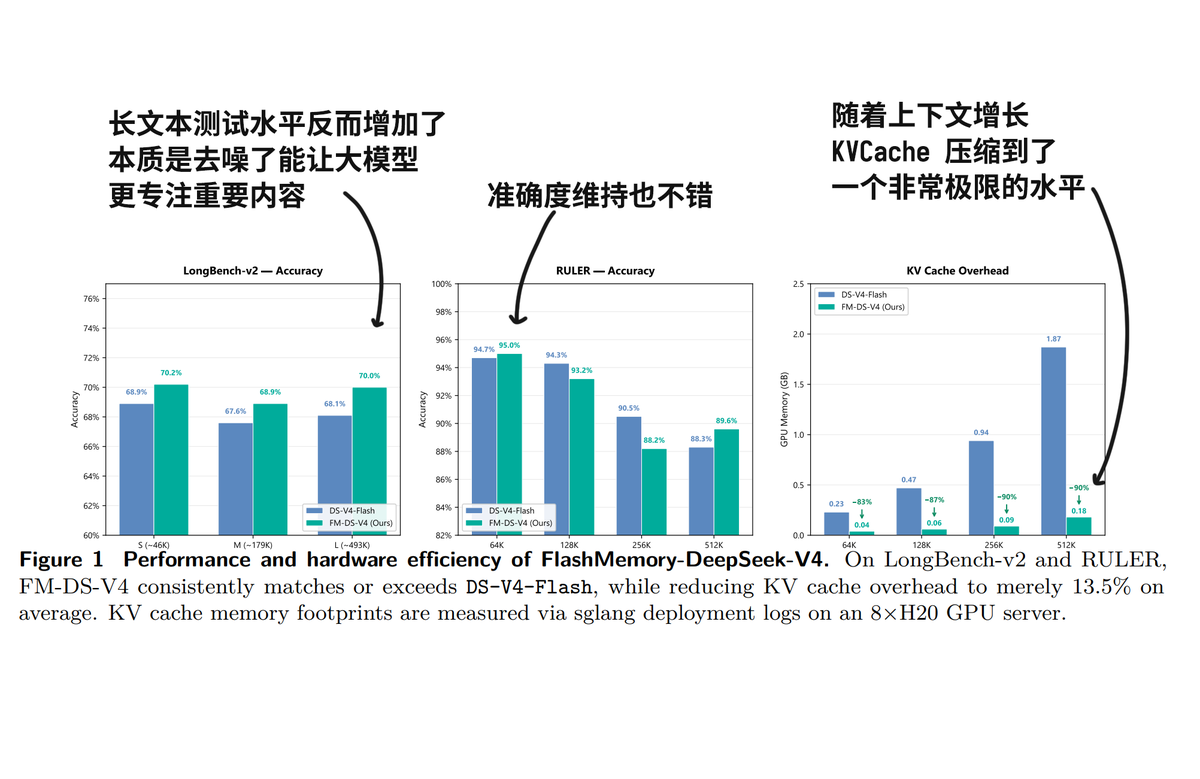
听上去靠谱, 那也只是显存占用少了, 怎么就性能还提高了呢? 答案是注意力降噪. 因为每次只提取和当前生成最相关的记忆块(Chunks)放入显存,模型在运算时就看不见那些无关的冗余信息了.天然地起到了一种"去噪"作用,这也是为什么显存占用少了,模型准确率反而略微提升的原因.官方测试在长文本评测集(如 LongBench-v2 等)上的准确率平均最终提升了 0.6%.
(其实还有数据如何逐出显存和如何预测数据实现预加载, 这部分也很棒, 很有启发性. 建议看原论文, 篇幅原因写不下了)
论文地址: arxiv.org/abs/2606.09079
项目地址: github.com/libertywing/Flash…
#FlashMemory #DeepSeekV4 #FlashMemoryDeepseekV4

17
18
223
27,830
这么说的话,生产环境中没人用裸模型,得先看“模型 harness”能解决哪种水平的问题,再看解决同样的问题需要多少金钱和时间,至于是一次搞定还是 agent 雕花,用户没那么关心。能力 sota 重要,某个能力层级内的性价比 sota 也重要。
Jun 11

我的使用经验是, one-pass 能力越强(且能在较少的思考下one-pass) 模型才是SOTA的. 要用 agentic coding 才能修复第一次犯的错反而是模型拉夸的表现, 再不济也要在Interleaved thinking过程中修复. agentic coding 是用来解决工程量和运行时问题的. 不是用来修静态检查就行发现的bug的.更简单的说, 你有bug不在thinking中修, 反而非要在n 1次上下文中修复, 是不是骗我买coding plan(x)?
3
8
3,532