Jun 13
Un agente de código que lanza workflows de LLM en paralelo. opendev coordina varias ramas de trabajo a la vez, cada una con su propio contexto, y une los resultados. Ideal cuando tu prompt se vuelve demasiado grande para un solo modelo. github.com/opendev-to/opende…
57

We are LIVE! Zuul maintainers and users from OpenDev, Volvo Cars, and Acme Gating are discussing proven lessons for building trusted AI systems on OpenInfra Live. Tune in now.
youtube.com/watch?v=b_Q_Hp6-…

855


May 31
Sunday is supposed to be a quiet day... unless you're part of the swarm getting absolutely deleted. 💥
#DarkSwarm #Gamedev #OpenDev #IndieDev
1
6
51

opendev turns a tx signature into a fully decoded execution profile: per-instruction CU breakdown, CPI tree, account state changes, token transfers, and AI insights explaining failures and inefficiencies. CLI web, and better: open source.
arena.colosseum.org/projects…
5
43



Mar 18
OpenDev Weekly Update — March 17, 2026
A supply chain attack hit the bittensor-wallet PyPI package. Coldkey swaps got a major security overhaul. MEV Shield and 10x fee increase deployed to mainnet.
Here's everything you need to know.
Thread below 🧵

ALT Two hands reach towards a glowing grid of vertical lights, symbolizing security measures and updates in a tech context.
1
1
6
428

Mar 17
很多人还不知道,AI 编程助手正在经历一场安静的范式迁移——
从 IDE 插件,迁移到终端命令行。
Claude Code 率先证明了这条路可行。现在每个大厂都在做 CLI agent。
但有一篇论文刚刚把整个工程架构掰开讲清楚了,是我今年读到最有价值的 AI 系统设计文章之一。
作者 Nghi D.Q. Bui 花了很长时间把 OPENDEV(用 Rust 写的开源编程 agent)做出来,然后把踩过的坑全写成了技术报告。
以下是最值得记住的几个工程洞见:
1. 上下文不是缓冲区,是预算
一个典型 session 里,工具输出(文件内容、命令结果、搜索)会占掉 70-80% 的 context。
所以正确做法是渐进式压缩,而不是"等溢出了再一次性清掉":
• token 压力 >80%:把旧观察替换成引用占位符
• 85%:快速剪枝旧工具输出
• 99%:才触发 LLM 全量压缩
工具输出超过 8000 字符?直接写文件,context 里只留 500 字预览 路径。
把"上下文消耗问题"变成"检索问题"——检索只花一次工具调用,但 context 消耗是每次 LLM 调用都在付费的。
2. 指令会随对话衰减,解法不是"多写"
超过 15 次工具调用后,模型对 system prompt 里的指令遵从率会显著下降——它们还在 context 里,但注意力已经漂移了。
很多人的直觉是"把 prompt 写得更长更详细",这反而更差。
正确做法:在决策点前注入短小的 role: user 提醒,而不是在 system prompt 堆砌所有内容。
user 角色比 system 角色有效,因为模型对最近的用户消息权重更高。但每种提醒必须有频率上限——注入太频繁会被模型当噪音忽略。
3. 把思考和行动拆成两次 LLM 调用
当工具 schema 存在于调用上下文中,模型倾向于快速行动而非深度思考。
解法不是告诉它"先想清楚再做",而是在 thinking 阶段完全不传工具 schema。
没有行动选项,模型才会真正推理。这比任何 prompt 指令都管用——改变的是 API 调用结构,不是自然语言描述。
4. 让危险工具不可见,而不是被拦截
在 schema 里直接移除某个工具,远比运行时权限检查更安全。
模型无法推理它不知道存在的能力,无法论证为何该被允许,也无法探测权限边界。
"没有路"比"有护栏"更可靠。
5. LLM 输出是近似正确的,系统要为此设计
文件编辑失败的最大原因不是 agent 意图错误,而是它复现目标文本时有细微偏差——多一个空格、换行符不同。
所以工具应该内置渐进松弛匹配链:精确匹配 → 去首尾空格 → 标准化空白 → 模糊匹配。每一级返回文件中实际存在的内容。
把"近似正确"变成成功,而不是让 agent 进入错误恢复循环。
───
这篇论文最有价值的地方不是算法突破,而是把大量工程权衡和失败案例全部公开了——而 Claude Code、Cursor 这些商业系统全都是黑盒。
如果你在做任何 AI agent 系统,值得全文读一遍。
arxiv.org/abs/2603.05344
2
35
158
17,374

Mar 16
【長時間動くCLI型AIコーディングエージェントの設計】
OpenDevを題材に、長時間動くCLI型AIコーディングエージェントの設計を整理したプレプリント(査読前公開研究)が公開された。論文の主眼は新規アルゴリズムの提案ではなく、実装設計と運用上の教訓の共有にある。
中核は、計画と実行を分ける構成、役割ごとに別モデルを割り当てる構成、古い文脈を段階的に圧縮する仕組み、セッションをまたぐメモリ、安全制御。長いセッションで文脈が膨らみやすいCLI型エージェントを、どう破綻しにくく設計するかを示した。文脈圧縮では、観測情報のピークのコンテキスト消費を約54%削減したとする。

1
4
40
4,510


The Top AI Papers of the Week (March 9 - March 15)
- KARL
- OpenDev
- SkillNet
- Memex(RL)
- AutoHarness
- FlashAttention-4
- The Spike, the Sparse, and the Sink
Read on for more:

13
59
341
78,241


Mar 13
最先端のAIエージェントでも、CLIタスクの解決率は65%以下で、長期タスクになると20%を下回るというベンチマーク結果がある。「ターミナルでAIを長時間動かし続ける」のは、思っているより難しい。
そこに向き合った論文が「OpenDev: Building Effective AI Coding Agents for the Terminal」。GitHub Copilotが1,500万人の開発者に使われ、Claude CodeがIDEからターミナルへのシフトをリードし始めた今、次の課題は「ターミナルで自律的・長時間に動くエージェントをどう設計するか」になっている。著者たちは「CLIネイティブなエージェントについて、ここまで詳細な技術レポートを公開したオープンソースは初めて」と述べていて、Claude Codeのような商用ツールが設計を非公開にしているだけに、確かに珍しい。
読んでいくと、3つの根本問題に対してどう向き合ったかが分かる。
【問題1:コンテキストの枯渇】
長いセッションでは、ツール実行の結果(ファイルの中身やコマンド出力)がコンテキスト全体の70〜80%を占める。AIと会話しているようで、実は作業ログを読ませているだけという状態になる。30ターンあたりから最初に与えた指示をモデルが無視し始めることも判明した。
これへの回答が「Adaptive Context Compaction(ACC)」で、古い情報を軽い処理から重い処理へと5段階で段階的に圧縮していく仕組み。この設計で観察結果のピーク消費量を約54%削減でき、通常の30ターンセッションでは緊急圧縮が不要になることが多い。圧縮してもアーカイブには残るので、必要なら引き出せる。
【問題2:ツールの増大】
MCPで外部ツールを追加できるようにしたら、全スキーマを起動時に読み込む方式だとコンテキストの40%が消えてしまった。必要なときだけロードする「Lazy Discovery」に切り替えたら5%未満に下がった。
【問題3:指示の減衰】
30ターン超でルールが守られなくなる問題は、システムプロンプトに繰り返し書いても解決しない。判断タイミングに合わせてルールを再注入する「Event-driven System Reminder」を実装することで対処した。
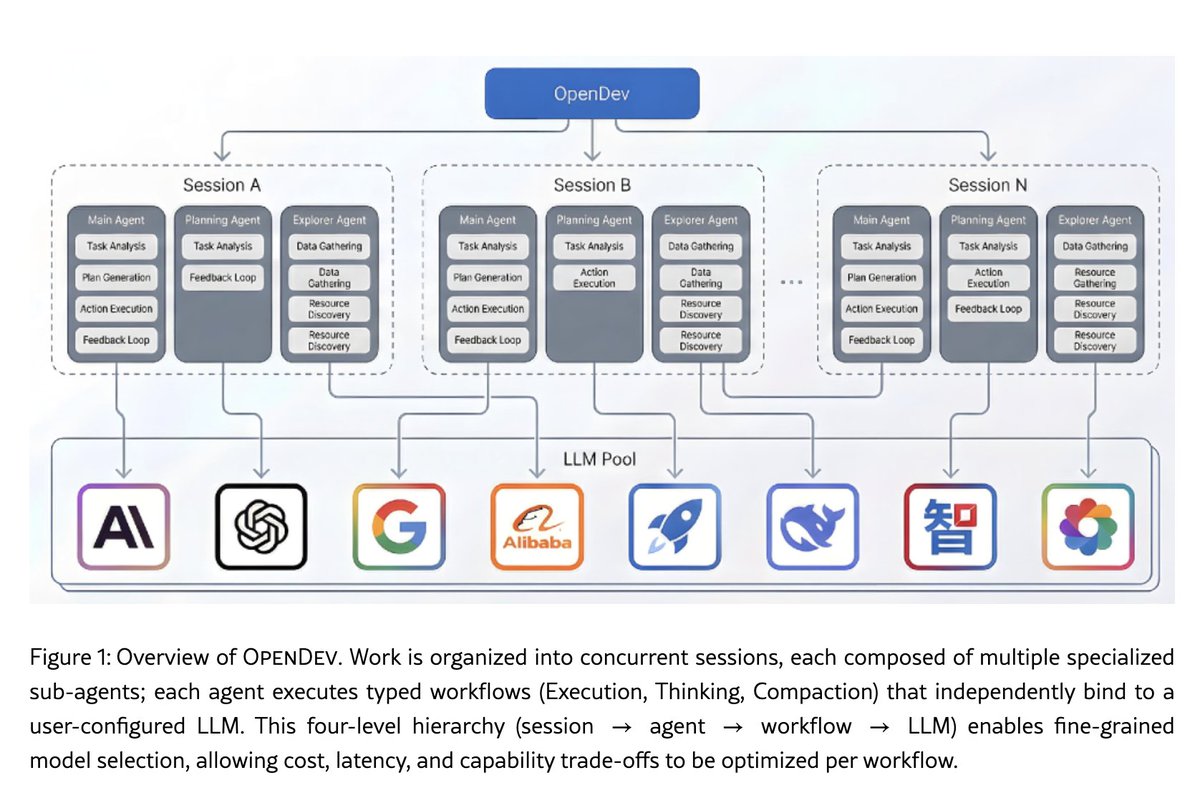
設計で面白いのがモデルの使い分けで、実行・推論・自己評価・画像処理・コンパクション用と5つの役割に別々のモデルを割り当てる。高い推論が必要なフェーズには高いモデルを、圧縮のような単純作業には安いモデルを使う。安全性も「スキーマレベルで道をなくす」設計が印象的で、計画モードにはファイル書き込みのツール自体が存在しない。ガードレールを設けるのではなく、構造的に不可能にする発想。
LLMエージェントを自分で作っている人、あるいは作りたい人にとっては、設計判断のリファレンスとして読める一本かもしれない。
1
5
493
Mar 11
OpenDev Weekly Update - March 10, 2026
This week: release delayed one week after a community member caught a critical staking bug, new testnet/mainnet release cadence, and hotkey swap gets upgraded to hotkey merge.
Plus a major community push for coldkey-based stake weight.
Thread below 🧵

1
3
6
449