
Jun 11
Not all PDF barcodes are stored the same way.
Dynamsoft Barcode Reader 11.6 automatically chooses the fastest extraction path for each PDF page.
Up to 58× faster PDF barcode reading. No code changes required.
dynamsoft.com/blog/product-f…
#BarcodeScanning #PDFProcessing

18

Apr 21
Printing PDFs to sign them is the digital equivalent of faxing yourself.
Don't be silly. Use SimplePDF.
#automatedpdfs #fillablepdf #pdfform #simplepdf #pdfprocessing #embedpdf
2
68

Need help with text extraction, annotations, or rendering in PyMuPDF? We have a dedicated forum for all your how-to questions. Start learning & contributing today: forum.pymupdf.com
#Python #PyMuPDF #PDFprocessing
3
175

SmolDocling is a powerful tool for processing complex PDFs, though some languages may need fine-tuning. Check out how it works! #AI #NLP #PDFprocessing
medium.com/@speaktoharisudha…
2
45

27 Nov 2024
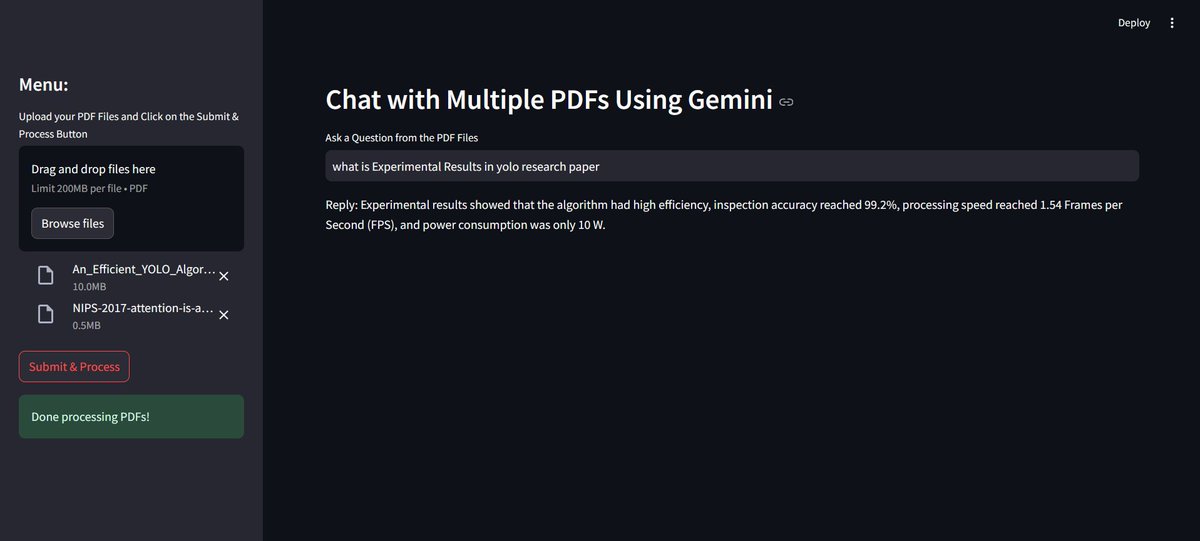
📢 GeminiLLMApp: Revolutionizing how you interact with PDFs!
✨ Features:
Ask questions across multiple PDFs & get answers instantly!
Powered by:Streamlit
LangChain
Google Generative AI
ChromaDB, FAISS-CPU, & more!
🌐 Check it out MyGitHub Repo
#AI #LangChain #PDFProcessing

2
75

6 Nov 2024
Worked my ass off to develop an app using streamlit
Its basically a QnA app where u load the pdf, ask questions and get answers!
I used Watsonx, Llama 3.1 70b and langchain to make it work
#AI #NLP #MachineLearning #LangChain #WatsonX #PDFProcessing #LLM #QnAApp
1
5
122

18 Oct 2024
This is the best Transcription Tool I've seen! 🤩
Our clients often use documents with complicated diagrams, tables and scanned in docs.
To pass it to an LLM or use RAG, you often need to extract the text.
I tried for extraction 😮💨
- PyMuPDF4llm
- AWS Textract
- Unstructured
- Tesseract
But none of them cut it for complicated documents, and I solved it for now by passing images to sonnet-3.5 to transcribe them.
Now Zerox is the first tool that can handle those weird diagrams (almost) perfectly, and I didn't have to engineer a prompt, or write any python code cause they you can try it on their page for free 🔥
#textextraction #pdfprocessing
17 Oct 2024

launching our open source OCR tool today!
try it out with some terrible pdfs and let me know how it goes: getomni.ai/ocr-demo
1
5
662

27 Mar 2024
Breaking the silence with an article! 📢Check out my last piece on Unstructured PDF Text Extraction – a crucial pre-processing task for all those working on LLM for PDFs. #TextExtraction #PDFProcessing link.medium.com/diTkLKFViIb
2
80

Powered by @pdfRest, @pdfAssistant is an AI chatbot that understands your PDF challenges and executes processing tasks for you.
Learn more: pdfassistant.ai/
#PDFprocessing #AIchatbot #pdfAssistant #documentmanagement #techsolution
1
13
97,294

26 Jun 2020
The #WPF team is merging PdfViewer and PdfProcessing engines. To all our users, please share any feedback. telerik.com/blogs/unifying-t…
2

8 Aug 2019
#PDFtools - #POCARAC - How to organize your electronic #companymemory in 7 steps with focus on #DocumentQuality and #PDFprocessing bit.ly/pocarac
#recordsmanagement #legaltech #digitaltransformation #compliance

3

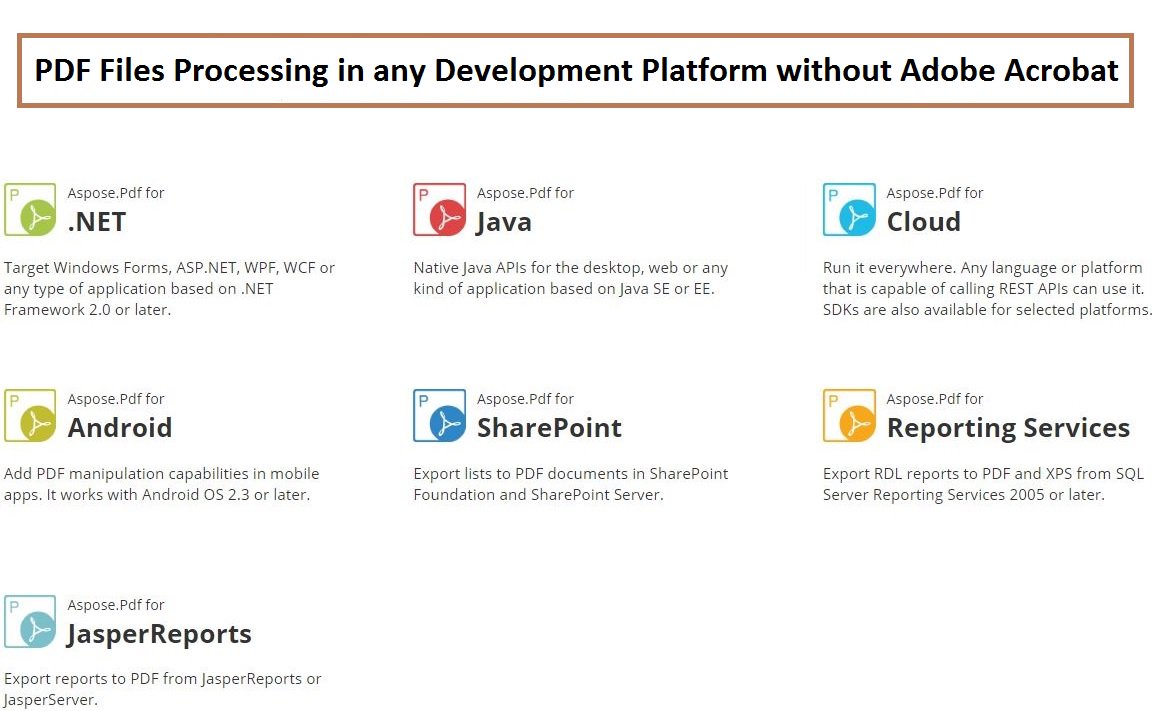
#PDFProcessing APIs – Create #Read Modify #Convert PDF files in #DotNET #Java #Android and #CloudApps. goo.gl/iPm3O0 #PDF #PDFAPI
5
4