
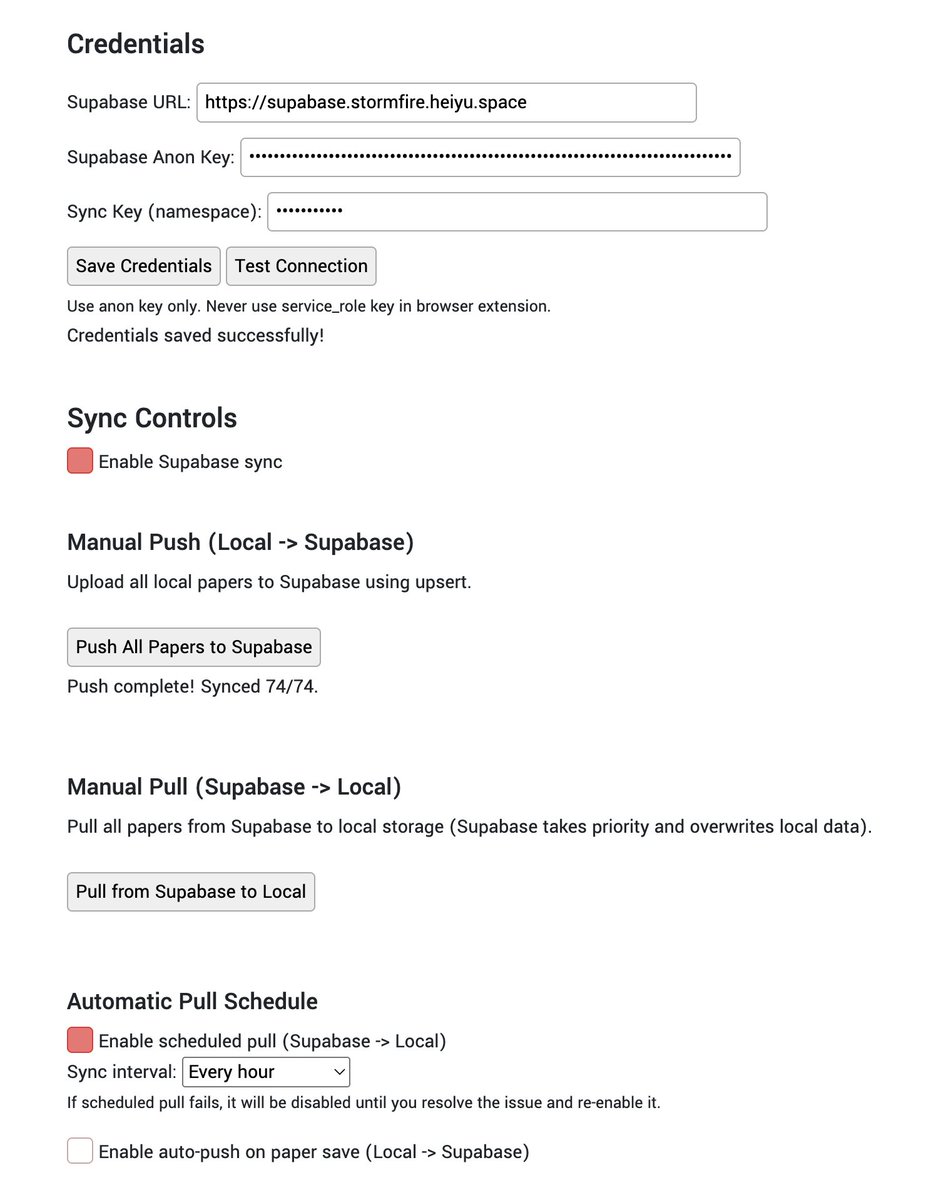
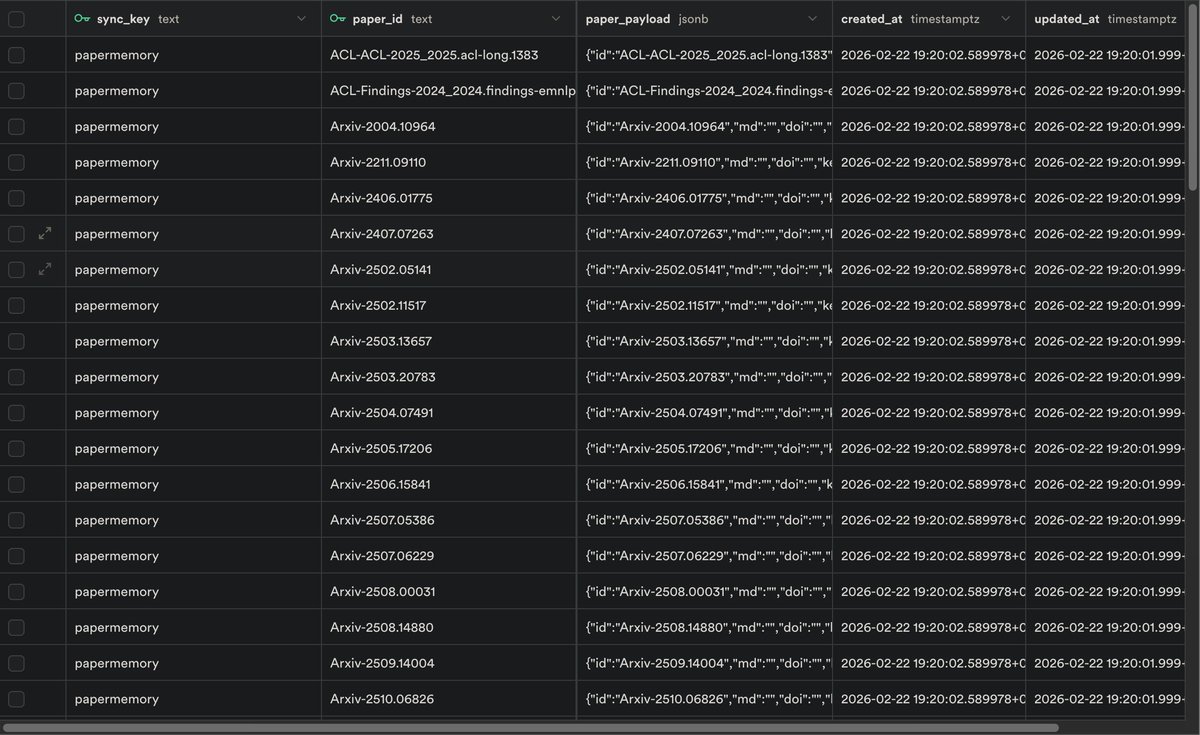
昨天春运回家,在车上堵了 12 个小时,干脆拿出来折腾了一件早就想做的事:基于 PaperMemory 二次开发,把我历史上读过的论文内容同步到本地数据库。
PaperMemory 是个浏览器插件,会自动记录我读过的论文。以前我让它把数据同步到 Notion,用起来还算顺手。但我后来想明白了一件事:跟 AI 最搭配的其实是 Obsidian,因为本地 markdown 文件,它可以直接去读。与其费劲把 Notion 同步到本地,不如我直接就保存到我本地的数据库上,我可以写个脚本直接导成 Markdown。
所以这次用 Codex 把同步逻辑整个重写了一遍,直接落到本地数据库。跑通之后,我就可以让 AI 帮我做论文层面的检索和分析了。哪些论文在谈同一个问题,某个方法的演进脉络是什么,这些以前要靠自己一篇一篇翻。
这里有意思的地方在于:这件事以前我根本不会动手做,因为开发成本太高,光是折腾数据库 schema 和 API 对接就能把人劝退。但现在有 Codex,我在堵车的 12 个小时里就把它搞定了。
这只是第一步。我的计划是把所有属于我的信息都收进来:读过的书、发过的推文、收藏的内容,最终喂给一个专属于我的 AI 助手。未来所有软件都需要有一个同步到本地的能力,这样才能接入个人的 AI,如果他们不做的话,那我就要自己做一个了。
3
8
51
8,592

15 May 2023
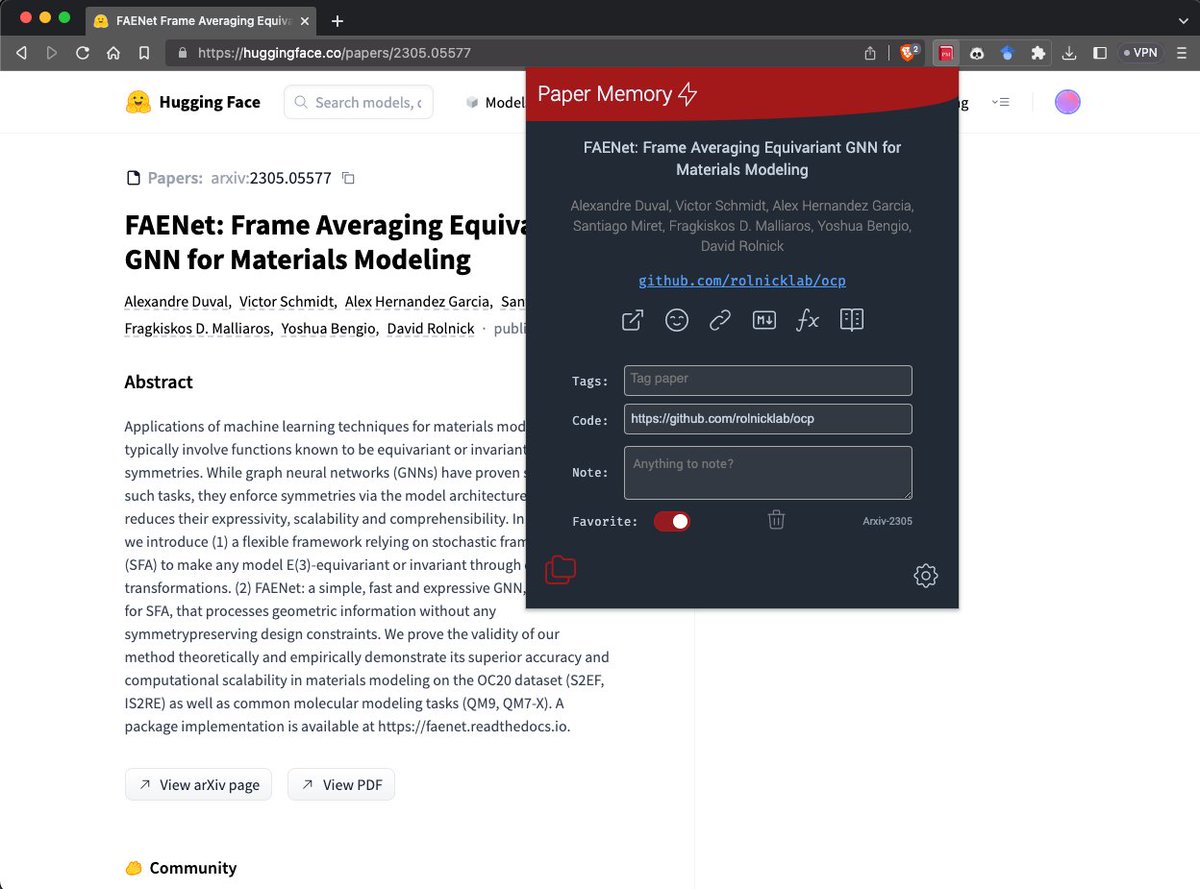
I'm working on a PR to #PaperMemory to include @HuggingFace papers as a source (and destination) to automatically parse papers and save them.
Anyone knows about a good single color SVG HF icon? I've used a smiley face from Tabler Icons but it's not great
github.com/vict0rsch/PaperMe…
1
3
311
20 Feb 2023
I took that screenshot ⬆️ today as I was going over issues of #PaperMemory.
Please be that person.
Building this isn't my job, I'm doing this because I like to share. Genuine acts of kindness like this make me want to continue 💪
1
2
188

21 Apr 2022
Check out the browser extension #PaperMemory by @vict0rsch!
21 Apr 2022

Aaand it's a 100 ⭐️ I've been working on #PaperMemory with 1 goal: automate the recording of papers I read on @arxiv_org or @openreviewnet and the discovery code w/ @paperswithcode. It's a simple browser extension that changed my #research workflow github.com/vict0rsch/PaperMe…
9
21 Apr 2022
Venues that #PaperMemory can parse papers from also include #CVF (@CVPR, @eccvconf etc.), #PMLR (@aistats_conf, @icmlconf etc.) @aclmeeting (@emnlpmeeting, @naaclmeeting etc.), @Nature (@NatureClimate, @NatureComms etc.), @biorxivpreprint but also #PubMedCentral and more!
1
3
21 Apr 2022
Aaand it's a 100 ⭐️ I've been working on #PaperMemory with 1 goal: automate the recording of papers I read on @arxiv_org or @openreviewnet and the discovery code w/ @paperswithcode. It's a simple browser extension that changed my #research workflow github.com/vict0rsch/PaperMe…
5
29
189

28 Nov 2020
If you're in the #Vancouver area, you can enjoy a 'Brent' or 'Craig' pizza courtesy of @AnthemPizza. Pizzas come in limited edition boxes designed by @papermemory, and are available thru Dec 26. Order for delivery or pick-up at: anthempizza.ca/
#CornerGas #FridayPizza

3
2
35

22 Feb 2017
shout outs and thanks @BojanSackmore @dionness881 @RockinSlap
@VegasGhostTurd
@chucknasi @papermemory
@DigitalTrends


1 Feb 2016
Day one of #PaperMemory IG take over is a wrap. Will be at again tomorrow. For more details visit my IG page.


