
I am still not fully convinced you need more architectures, MLA compresses key value pairs into a single latent, why not compress them further along the time dimension? Maybe PerceiverIO, or maybe after having read enough tokens you compress them into few latents decoder only.
1
4
255

10 Jan 2025
PerReg : New prediction method from Valeo. Claims SOTA on nuScenes, Argo, and Waymo.
Uses a PerceiverIO arch. Adds registers for scene-level information. Combines self distillation and reconstruction losses. Pretraining on all datasets fine tuning the decoder only works best.

1
2
187

16 Dec 2024
Maybe because of the architectural differences?
The base video models:
- infer all output tokens at once, instead of auto-regressively
- progressively iterates on the output instead of one-shotting it
Maybe a better text archi would be something like PerceiverIO diffusion
2
39

18 Jun 2024
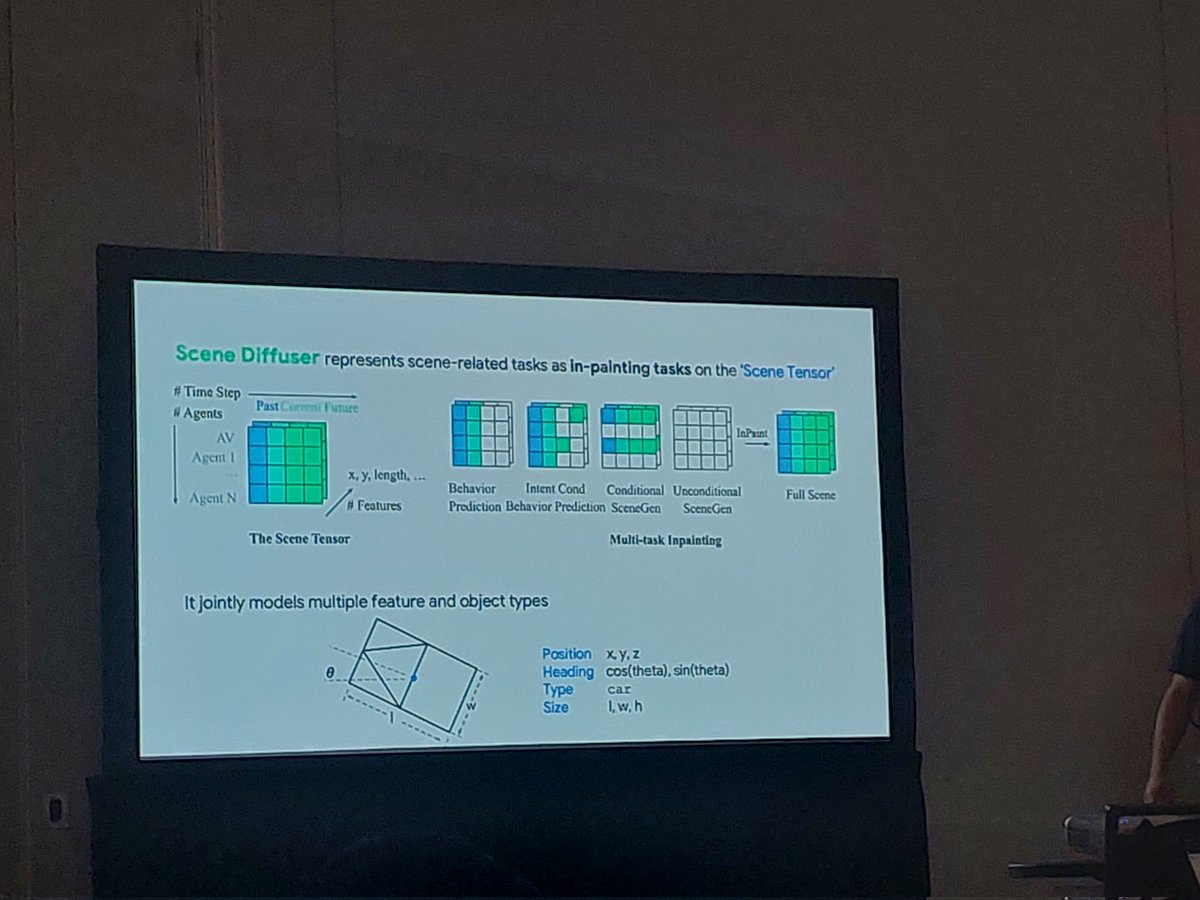
SceneDiffuser: neat idea from @Waymo using diffusion to simulate traffic: cast scene-related tasks as in-painting. Runs with PerceiverIO, transformer backbone, AdaLN denoising, L2 denosing loss.
Perks: easy to inject constraints, controllability, good results #CVPR2024 #DDADS



1
2
18
1,907

25 Oct 2023
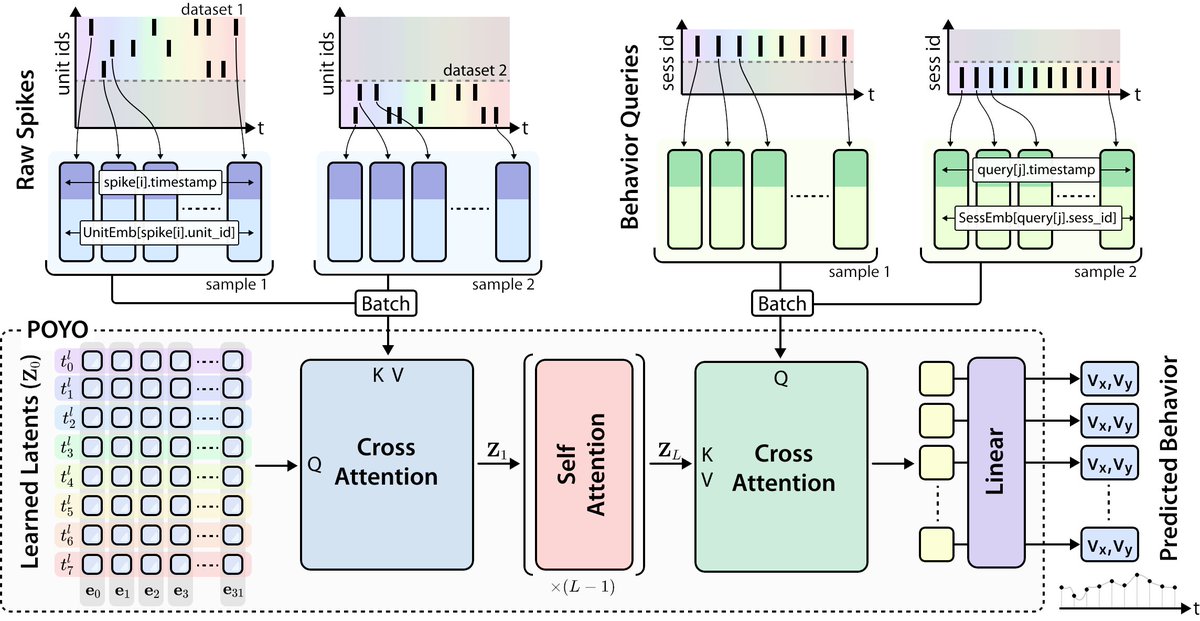
To compress our high-dimension input sequence of spike-level tokens, we use a PerceiverIO backbone to map a sequence of spikes to a sequence of behavior outputs.
1
1
18
2,158

30 Sep 2023
many kind of architectures that could deal with abritrary data. like PerceiverIO or my transflower model
1
25

1 Aug 2023
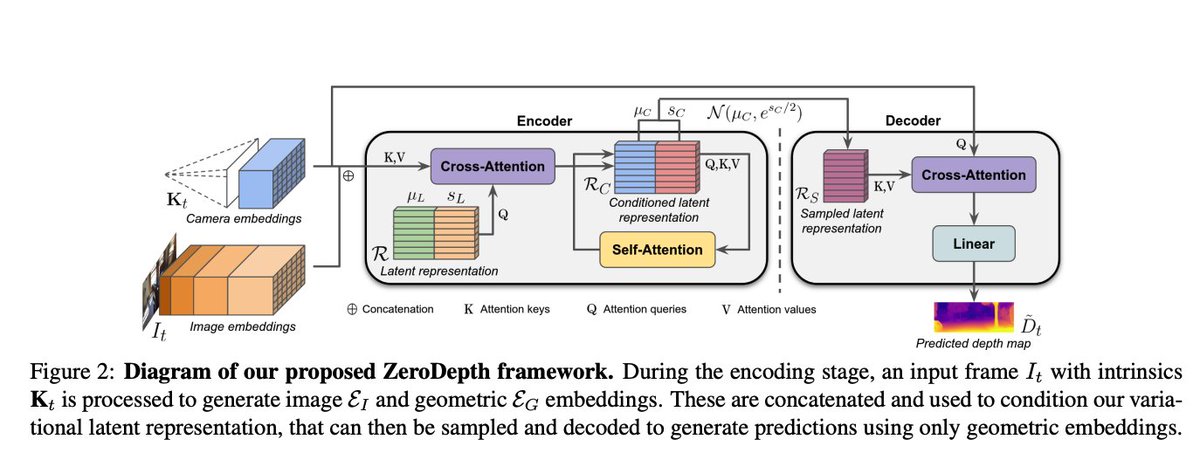
Taking lessons from our DeFiNe (sites.google.com/view/tri-de…) work, we find that camera embeddings ( a PerceiverIO-like architecture) allow for generalizable scale transfer. ZeroDepth has strong metric zero-shot results on KITTI and NYUv2, despite a large domain (and depth scale) gap
2
3
677

29 May 2023
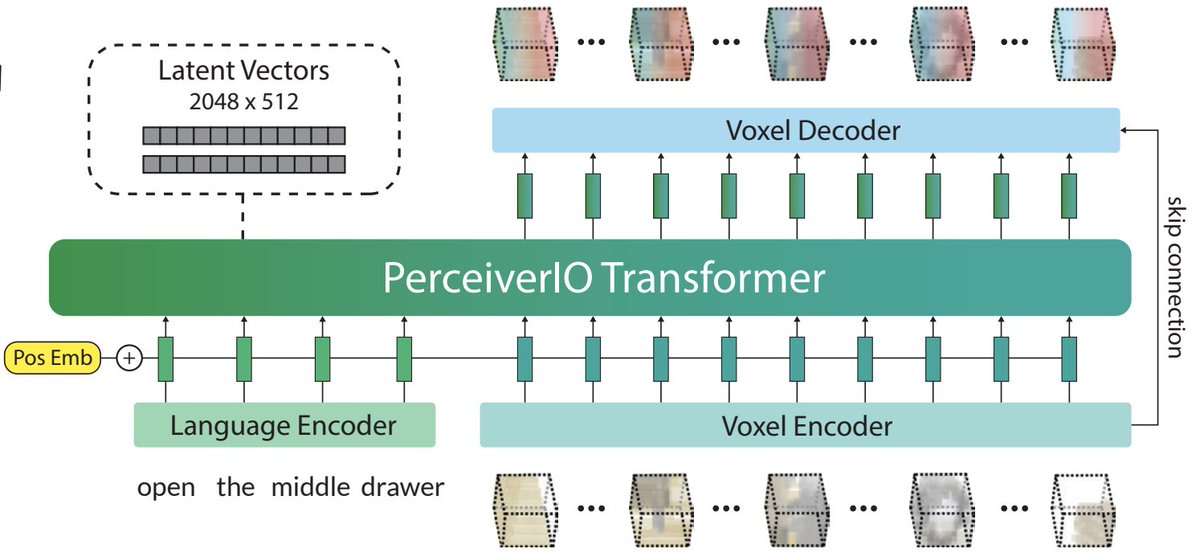
Dieter Fox showed @mohito1905's "Perceiver-Actor" at #ICRA2023 today. It produces voxelspace action outputs from RGBD language input, using PerceiverIO for the backbone. I was thinking a 3D CNN would be a strong backbone too, but actually the exps show Perceiver winning by a lot
1
5
41
4,820

6 Apr 2023
Muy interesante este trabajo, similar a la idea del PerceiverIO (sensiocoders.com/blog/079_pe…) en el que se le puede pedir "cosas" a las características calculadas por una red neuronal usando mecanismos de atención (como no), pero enfocado a la segmentación de imágenes.
5 Apr 2023

Today we're releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation.
SAM is capable of one-click segmentation of any object from any photo or video zero-shot transfer to other segmentation tasks ➡️ bit.ly/433YuBI
3
232

25 Nov 2022
弊社リサーチャーのAli Cevahirの論文が、データマイニングの国際会議「22nd IEEE International Conference on Data Mining」で行われるワークショップに採択されました。
詳しくはこちらをご覧ください。
stockmark.co.jp/news/2022112…
#PerceiverIO #論文
4
6

I like DeepMind's Perceiver (and PerceiverIO) architecture, with the tweaks described in DeepMind's Flamingo paper
6

10 Nov 2022
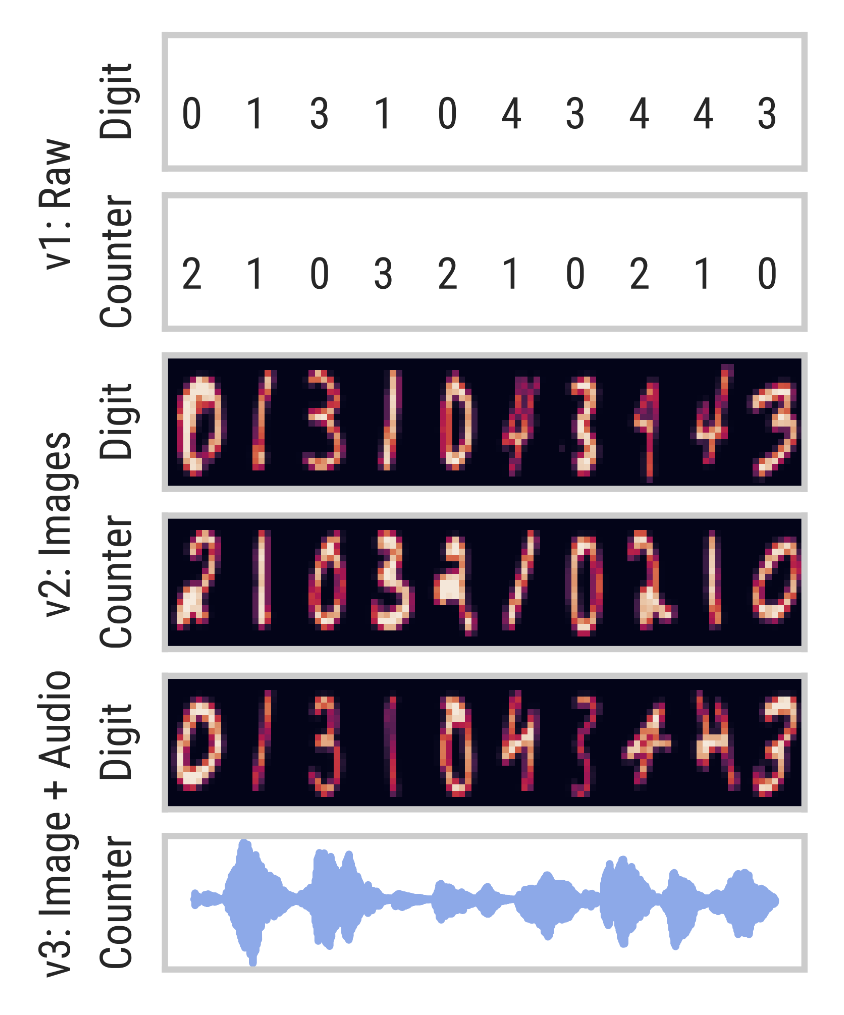
Our paper proposes a PerceiverIO-based approach and applies it to synthetic scenarios and audio-visual datasets.
A2MT is a challenging task with many practical applications, and we would be excited for the community to join our efforts!

1
5

13 Sep 2022
16/17
Special thanks to @stepjamUK for open-sourcing C2FARM, which inspired this work! Also lucidrains for the lucid PerceiverIO implementation 🙏
1
1
6
13 Sep 2022
6/17
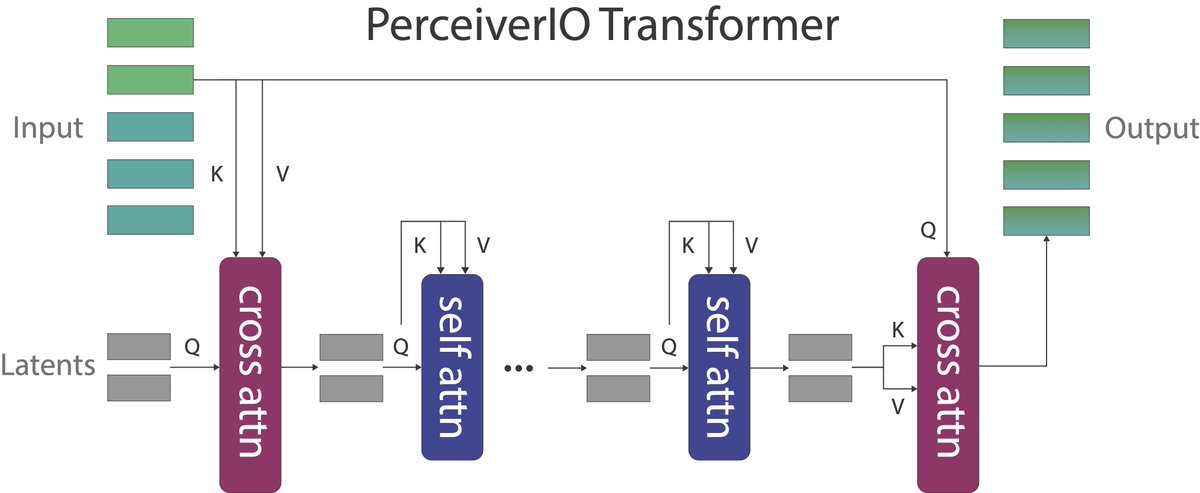
To deal with high-dimensional inputs, we adapt PerceiverIO by @drew_jaegle et al (Deepmind). PerceiverIO uses a small set of latent vectors that are cross-attended with the input. These latent vectors are randomly initialized and trained end-to-end.
1
1
10

18 Aug 2022
Great implementation of DeepMinds PerceiverIO Architecture, really clean and hackable codebase:
github.com/krasserm/perceive…
1
2

15 Jan 2022
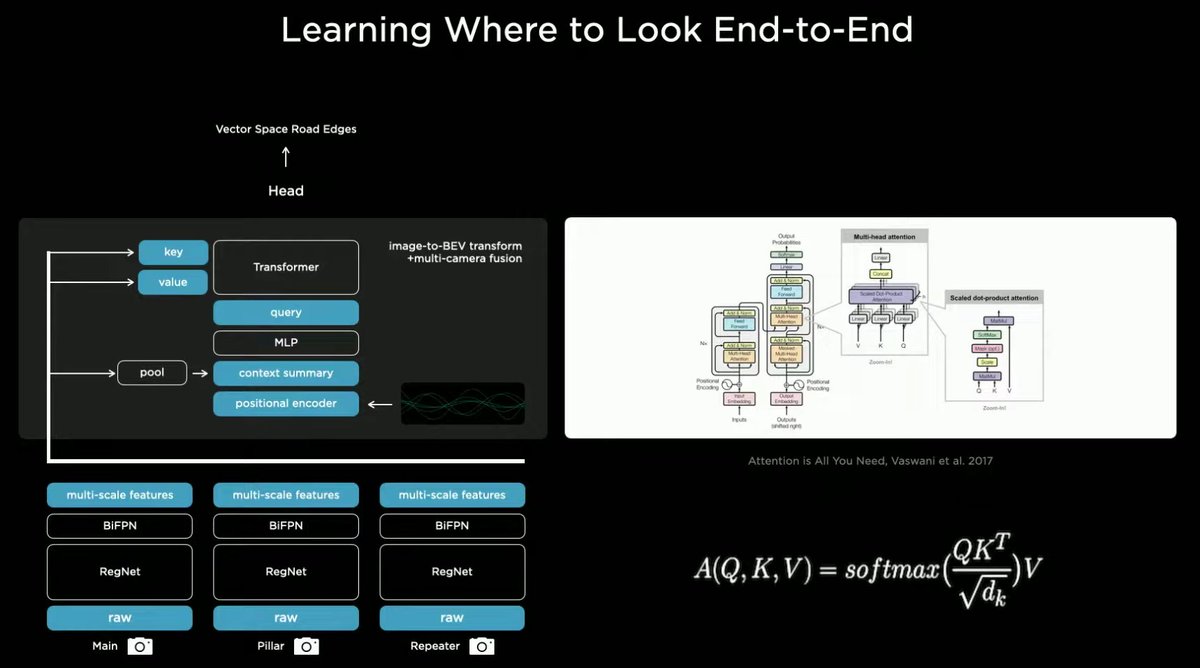
Rewatched @Tesla's AI day recently, and when @karpathy introduced the Transformer used in AutoPilot, it immediately reminded me of @DeepMind's #PerceiverIO which I recently contributed @huggingface. Wonder whether Tesla's approach was inspired by it...
5
46
329

5 Jan 2022
Ok now the new #PerceiverIO deserves my attention…pardon! My self-attention!
Let’s start from these wonderful jupyter notebooks: mlm (masked language modeling), image and text classification just to begin!
github.com/NielsRogge/Transf…
5 Jan 2022

👀 Amazing thread and happy to have made this one more easily accessible! huggingface.co/docs/transfor…
1
2

9 Dec 2021
DeepMind is doing a lot of interesting stuff this year, with AlphaFold, PerceiverIO, more recently with applying AI to pure math, and now Gopher! Looking forward to seeing what other advances DeepMind makes in the field of AI!
1
7


26 Aug 2021
Our brain can take any kind of input: video, audio, text. So can we have one single architecture that can handle all these types of input? @DeepMind has come out with this new model: #PerceiverIO that can do that!
1
1
3