
1 Apr 2025
Multimodal machine learning with large language embedding model for polymer property prediction
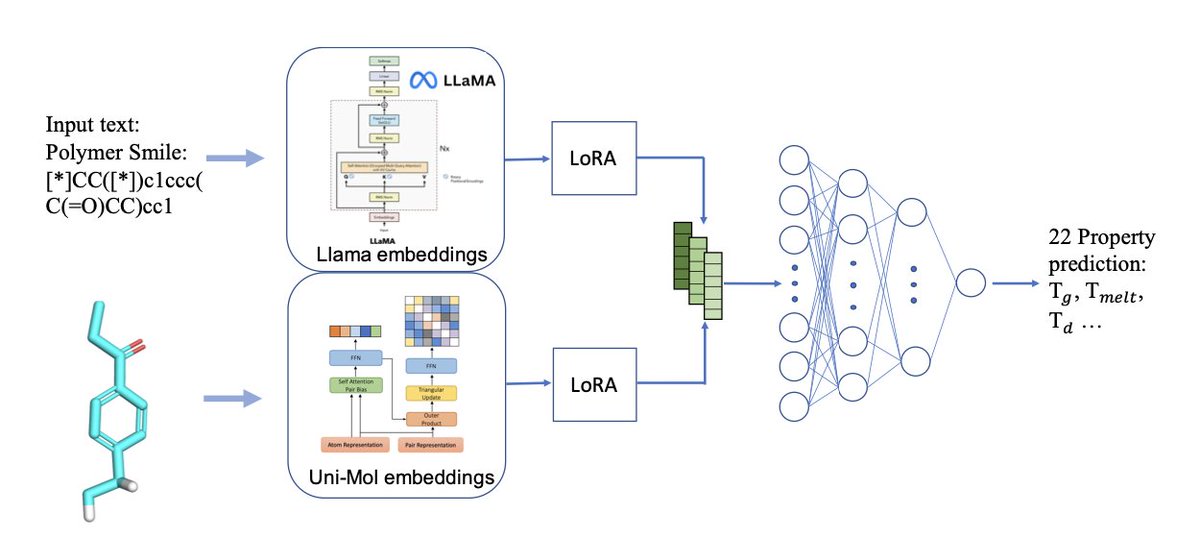
1. PolyLLMem introduces a multimodal framework that combines Llama 3-based textual embeddings from polymer SMILES with Uni-Mol-based structural embeddings to predict 22 diverse polymer properties, delivering high accuracy with minimal data.
2. Despite being trained on a relatively small dataset (29,639 data points), PolyLLMem performs comparably or better than advanced transformer and graph-based models like PolymerBERT, TransPolymer, and PolyGNN, which typically require millions of polymer samples for pretraining.
3. A key innovation is the use of Low-Rank Adaptation (LoRA) layers, which fine-tune both textual and structural embeddings during prediction, enhancing chemical relevance without retraining large models from scratch.
4. The architecture employs a gated fusion mechanism that dynamically balances text and structure embeddings, followed by a refinement block and a regression head, enabling robust single-task prediction across a wide range of polymer properties.
5. PolyLLMem achieves superior R² scores in predicting glass transition temperature (Tg), bandgaps (Egc and Egb), density, and atomization energy, and remains competitive in challenging tasks like conductivity and mechanical properties.
6. Visualization with UMAP shows that Llama 3 embeddings capture chemically meaningful clusters from polymer SMILES, and cosine similarity heatmaps reveal that token-level embeddings distinguish structural motifs like aromatic rings and fluorinated groups.
7. Integrated Gradients attribution confirms that the model focuses on chemically relevant substructures during prediction—for example, identifying trifluoromethyl groups as key contributors to high Tg.
8. Comparative analysis shows that the combined LLM Uni-Mol model outperforms models using either modality alone, and even classical ML pipelines using Morgan fingerprints or RDKit descriptors.
9. The model’s simplicity, lack of pretraining requirement, and adaptability make it a strong candidate for rapid, data-efficient polymer property screening, particularly in settings with limited experimental data.
10. While the model underperforms slightly on mechanical and gas permeability predictions, likely due to dataset limitations and single-task formulation, it offers a scalable and interpretable solution for polymer informatics.
💻Code: github.com/zhangtr10/PolyLLM…
📜Paper: arxiv.org/abs/2503.22962
#PolymerInformatics #LLMs #MultimodalLearning #MaterialsScience #DeepLearning #ChemInformatics #PolymerDesign #MachineLearning #Llama3 #UniMol #PolyLLMem
3
15
1,155