
22 Oct 2025
Unifying Polymer Modeling and Design via a Conformation-Centric Generative Foundation Model
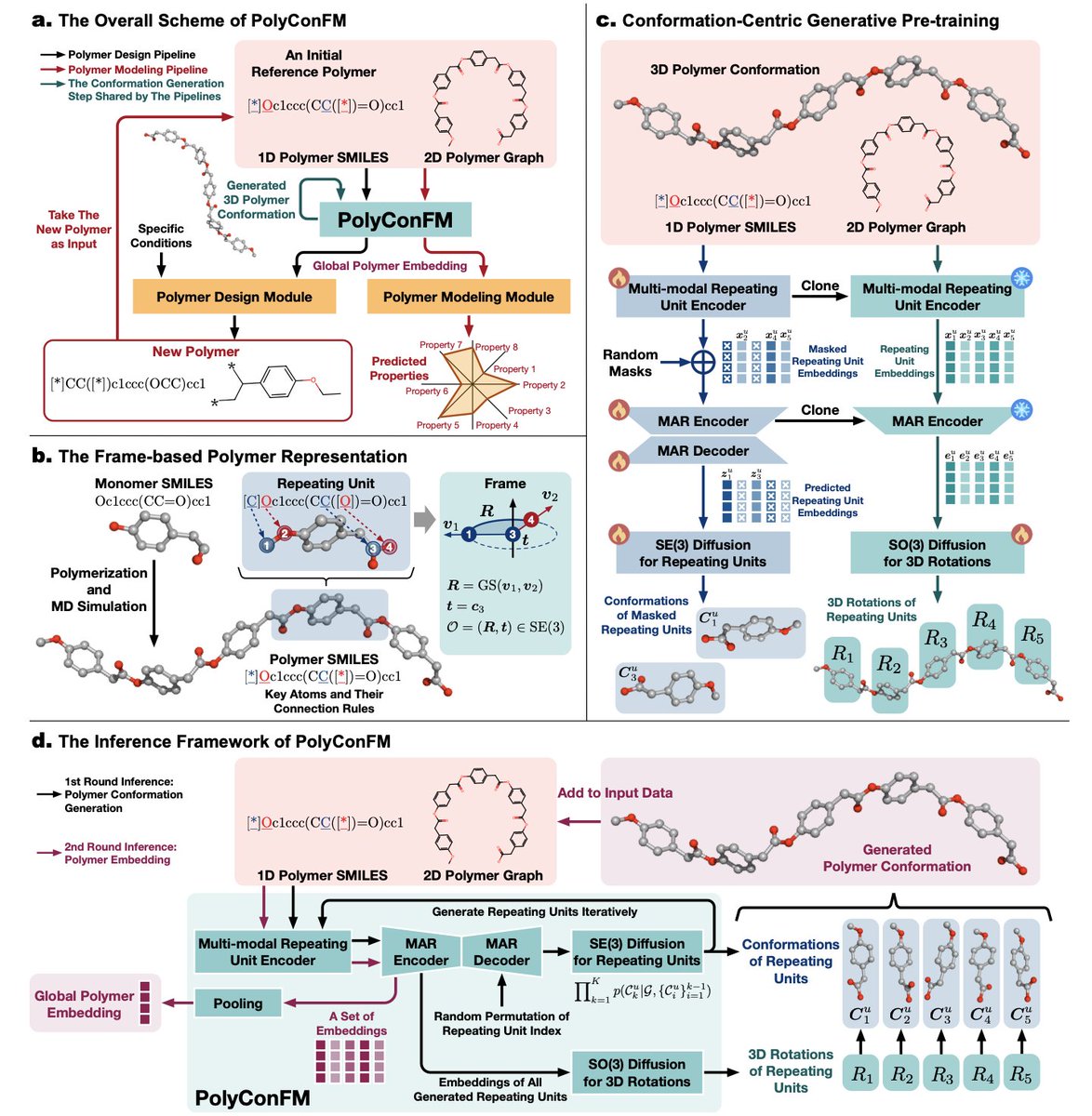
1. The article introduces PolyConFM, a novel polymer foundation model that integrates polymer modeling and design through a novel conformation-centric generative pretraining approach. This model addresses the limitations of existing methods by capturing global structural information inherent in polymer conformations, which is crucial for accurate polymer modeling and design.
2. PolyConFM innovatively decomposes polymer conformations into sequences of local conformations (repeating units) and uses masked autoregressive modeling to reconstruct these local conformations. It further generates orientation transformations to recover the complete polymer conformation, effectively capturing complex dependencies among repeating units.
3. A significant contribution of this work is the construction of a high-quality dataset of over 50,000 polymers with conformations obtained through molecular dynamics simulations. This dataset not only enables conformation-centric pretraining but also provides a valuable resource for future research in polymer science.
4. Experiments demonstrate that PolyConFM significantly outperforms state-of-the-art methods in polymer conformation generation, property prediction, and design tasks. It achieves state-of-the-art performance by providing accurate global structural information and effectively supporting diverse downstream tasks, thereby bridging the gap between polymer structure, property, and design.
5. The conformation-centric generative pretraining approach of PolyConFM is particularly noteworthy. It leverages the inherent 3D structures of polymers to generate informative representations that are essential for both property prediction and design. This method sets a new standard for polymer foundation models by incorporating global structural features that are often overlooked in existing methods.
📜Paper: arxiv.org/abs/2510.16023v1
#PolymerScience #DeepLearning #GenerativeModeling #Conformation #PolymerDesign #FoundationModel
1
8
871
16 Sep 2025
Descriptor and Graph-based Molecular Representations in Prediction of Copolymer Properties Using Machine Learning
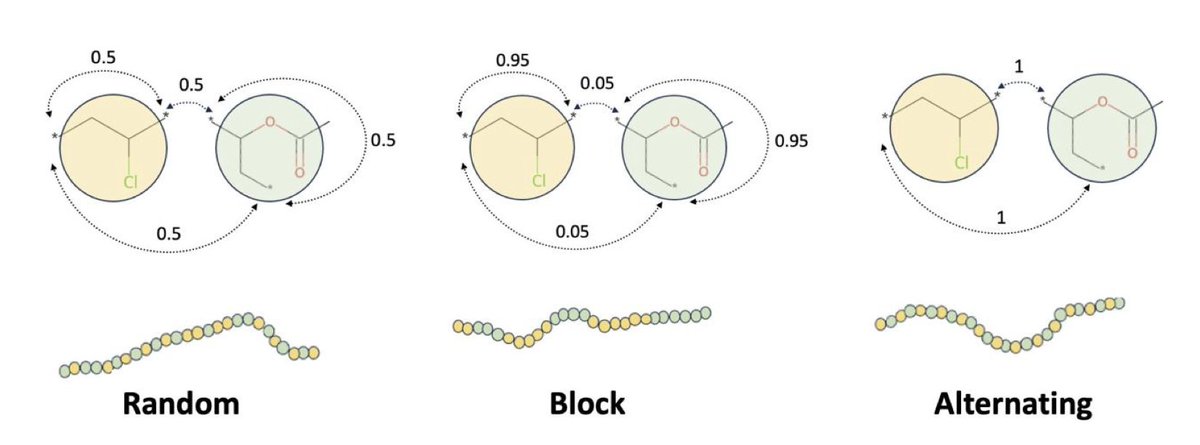
1. This study explores the use of machine learning to predict copolymer properties, leveraging both descriptor-based and graph-based molecular representations to enhance prediction accuracy.
2. The researchers utilized a random forest model to predict properties from molecular descriptors and a graph neural network to predict properties from 2D polymer graphs, demonstrating the strengths of each approach.
3. The study highlights that descriptor-based random forests excel at predicting properties like density and heat capacities, which are closely tied to specific molecular features.
4. In contrast, graph representations better predict expansion coefficients and bulk modulus, which depend more on complex structural interactions captured by graph-based models.
5. The study underscores the importance of choosing appropriate molecular representations based on the underlying structure-property relationships for effective machine learning model performance.
6. The researchers constructed a dataset from molecular dynamics simulations for 140 binary copolymers, providing a robust foundation for training and evaluating the machine learning models.
7. The results show that multi-task machine learning models generally outperform single-task methods for most properties, highlighting the benefits of shared information across tasks.
8. The study concludes that integrating both descriptor-based and graph-based approaches offers a comprehensive framework for copolymer design, balancing accuracy and interpretability.
📜Paper: arxiv.org/abs/2509.11874
#MachineLearning #CopolymerProperties #MaterialsScience #PolymerDesign #GraphNeuralNetworks
1
2
8
1,167
7 Jun 2025
PolyRL: Reinforcement Learning-Guided Polymer Generation for Multi-Objective Polymer Discovery
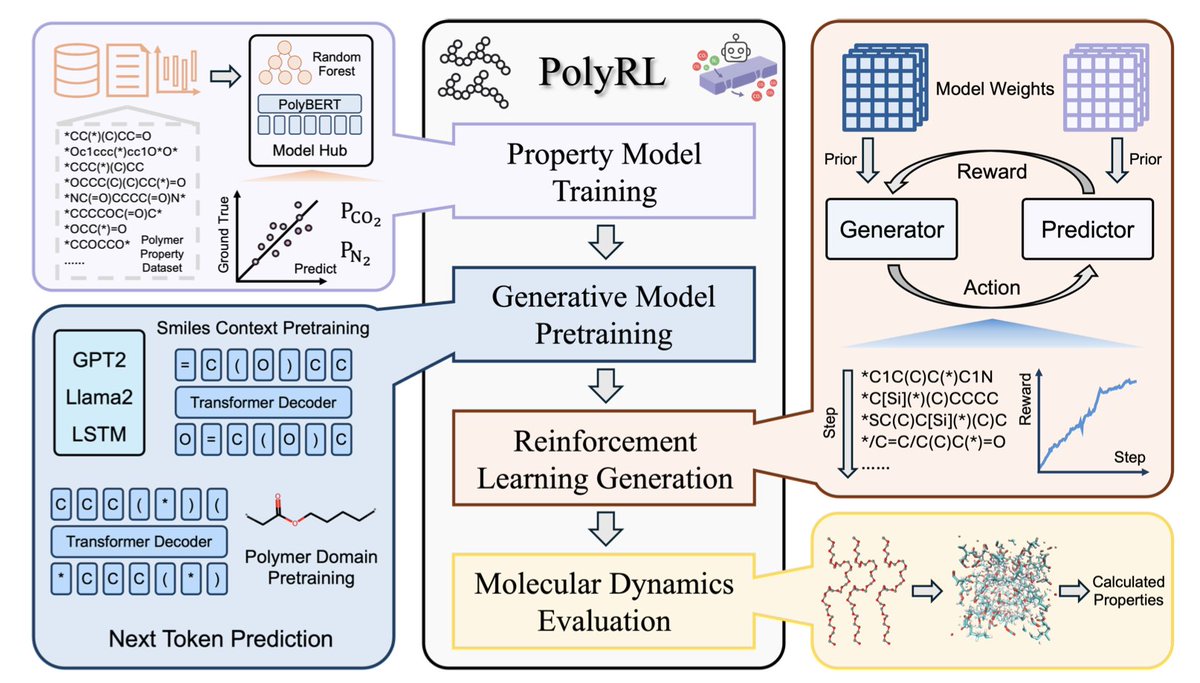
1.This study introduces PolyRL, the first reinforcement learning framework designed for inverse design and multi-objective optimization of gas separation polymers, integrating reward model training, generative pre-training, RL fine-tuning, and theoretical validation into a closed-loop system.
2.PolyRL effectively optimizes gas permeability and selectivity simultaneously by using custom reward functions, addressing the challenge of directional multi-objective polymer design under data scarcity.
3.The framework benchmarks six RL algorithms for polymer generation, showing that policy gradient methods like REINVENT and REINFORCE outperform actor-critic methods by efficiently discovering polymer candidates surpassing established performance bounds.
4.Transformer-based generative models GPT2 and LLaMA2 significantly enhance the quality, novelty, and diversity of generated polymers compared to RNN-based models, demonstrating the advantage of global attention mechanisms in polymer sequence modeling.
5.Pre-training dataset size strongly influences generation performance; larger datasets improve molecular scores, uniqueness, and novelty but also increase synthetic complexity, highlighting a trade-off for practical polymer synthesis.
6.Molecular dynamics simulations validate the RL-generated polymers, confirming high performance and revealing that silicon-containing and cyclic backbone structures promote free volume and microporosity, key to superior gas separation properties.
7.PolyRL establishes a robust benchmark for future AI-driven polymer discovery, emphasizing reinforcement learning’s potential to accelerate goal-directed materials design beyond conventional machine learning or genetic algorithms.
💻Code: github.com/Knitua/PolyRL
📜Paper: doi.org/10.26434/chemrxiv-20…
#PolymerDesign #ReinforcementLearning #MaterialsDiscovery #GasSeparation #MachineLearning #GenerativeModels #PolymerInformatics
6
1,072
7 Jun 2025
PolyRL: Reinforcement Learning-Guided Polymer Generation for Multi-Objective Polymer Discovery
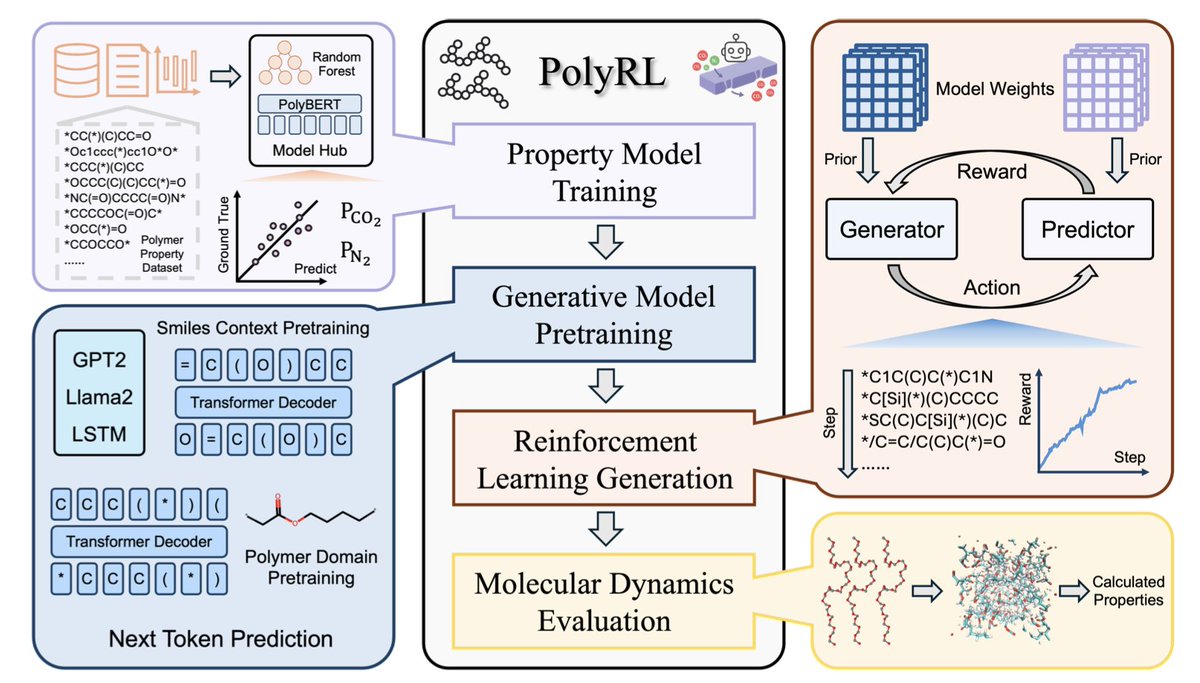
1.This study introduces PolyRL, the first reinforcement learning framework designed for inverse design and multi-objective optimization of gas separation polymers, integrating reward model training, generative pre-training, RL fine-tuning, and theoretical validation into a closed-loop system.
2.PolyRL effectively optimizes gas permeability and selectivity simultaneously by using custom reward functions, addressing the challenge of directional multi-objective polymer design under data scarcity.
3.The framework benchmarks six RL algorithms for polymer generation, showing that policy gradient methods like REINVENT and REINFORCE outperform actor-critic methods by efficiently discovering polymer candidates surpassing established performance bounds.
4.Transformer-based generative models GPT2 and LLaMA2 significantly enhance the quality, novelty, and diversity of generated polymers compared to RNN-based models, demonstrating the advantage of global attention mechanisms in polymer sequence modeling.
5.Pre-training dataset size strongly influences generation performance; larger datasets improve molecular scores, uniqueness, and novelty but also increase synthetic complexity, highlighting a trade-off for practical polymer synthesis.
6.Molecular dynamics simulations validate the RL-generated polymers, confirming high performance and revealing that silicon-containing and cyclic backbone structures promote free volume and microporosity, key to superior gas separation properties.
7.PolyRL establishes a robust benchmark for future AI-driven polymer discovery, emphasizing reinforcement learning’s potential to accelerate goal-directed materials design beyond conventional machine learning or genetic algorithms.
💻Code: github.com/Knitua/PolyRL
📜Paper: doi.org/10.26434/chemrxiv-20…
#PolymerDesign #ReinforcementLearning #MaterialsDiscovery #GasSeparation #MachineLearning #GenerativeModels #PolymerInformatics
7
939
6 Jun 2025
polyBART: A Chemical Linguist for Polymer Property Prediction and Generative Design
1. polyBART is a new polymer foundation model developed using a novel polymer representation called PSELFIES. This model leverages existing molecular language models to predict and generate polymers for specific applications.
2. PSELFIES ensures 100% syntactic validity in polymer strings, making it compatible with molecular language models. This allows polyBART to solve both forward (property prediction) and inverse (generative design) problems in polymer informatics.
3. The model achieves state-of-the-art results in predicting polymer properties, such as thermal and electronic characteristics, and can generate new polymer structures tailored to specific property requirements.
4. polyBART's predictive power was validated through experiments, including the first successful synthesis and testing of a polymer designed by a language model, confirming the accuracy of predictions for thermal properties.
5. A key innovation of polyBART is its generative capability. The model can generate novel polymers conditioned on desired properties, such as high thermal stability or specific electronic characteristics, opening up new avenues for polymer design.
6. The model is also able to generate polymers with synthetic accessibility in mind, filtering out compounds that would be difficult or impossible to synthesize.
7. Experimental synthesis of a polymer predicted by polyBART validated its predictions, particularly in terms of thermal stability, demonstrating the model's potential to drive real-world polymer design.
8. polyBART represents a major step forward in the use of machine learning for polymer informatics, combining property prediction and generative design into a unified framework.
📜Paper: arxiv.org/abs/2506.04233
#polymerdesign #AIinMaterials #machinelearning #materialsengineering #polymerinformatics
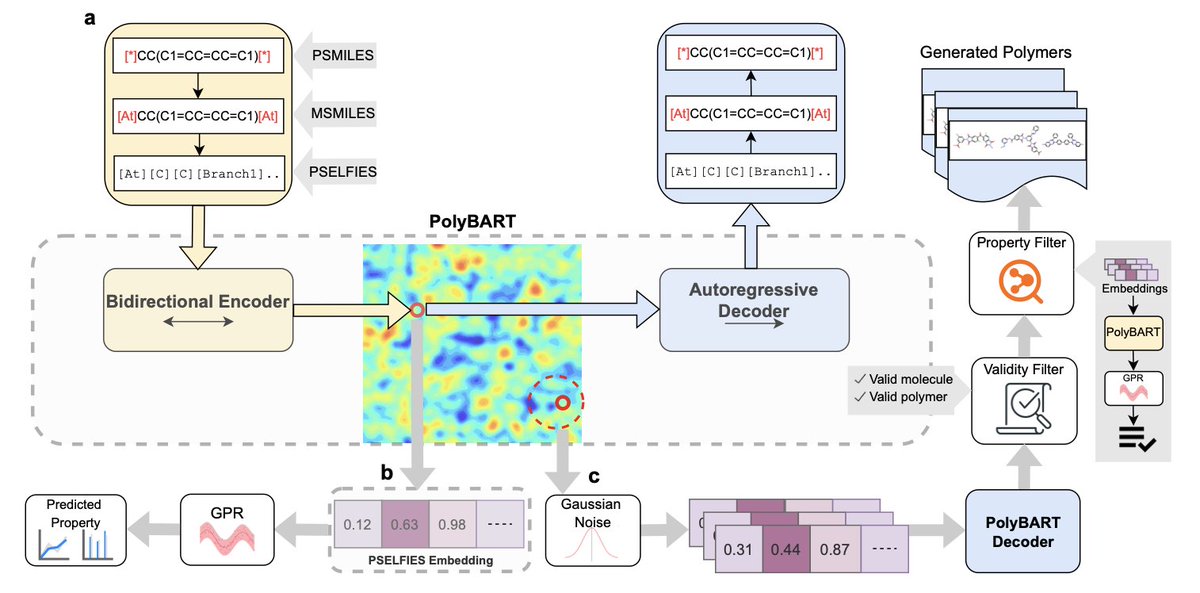
2
21
1,243
6 Jun 2025
polyBART: A Chemical Linguist for Polymer Property Prediction and Generative Design
1. polyBART is a new polymer foundation model developed using a novel polymer representation called PSELFIES. This model leverages existing molecular language models to predict and generate polymers for specific applications.
2. PSELFIES ensures 100% syntactic validity in polymer strings, making it compatible with molecular language models. This allows polyBART to solve both forward (property prediction) and inverse (generative design) problems in polymer informatics.
3. The model achieves state-of-the-art results in predicting polymer properties, such as thermal and electronic characteristics, and can generate new polymer structures tailored to specific property requirements.
4. polyBART's predictive power was validated through experiments, including the first successful synthesis and testing of a polymer designed by a language model, confirming the accuracy of predictions for thermal properties.
5. A key innovation of polyBART is its generative capability. The model can generate novel polymers conditioned on desired properties, such as high thermal stability or specific electronic characteristics, opening up new avenues for polymer design.
6. The model is also able to generate polymers with synthetic accessibility in mind, filtering out compounds that would be difficult or impossible to synthesize.
7. Experimental synthesis of a polymer predicted by polyBART validated its predictions, particularly in terms of thermal stability, demonstrating the model's potential to drive real-world polymer design.
8. polyBART represents a major step forward in the use of machine learning for polymer informatics, combining property prediction and generative design into a unified framework.
📜Paper: arxiv.org/abs/2506.04233
#polymerdesign #AIinMaterials #machinelearning #materialsengineering #polymerinformatics
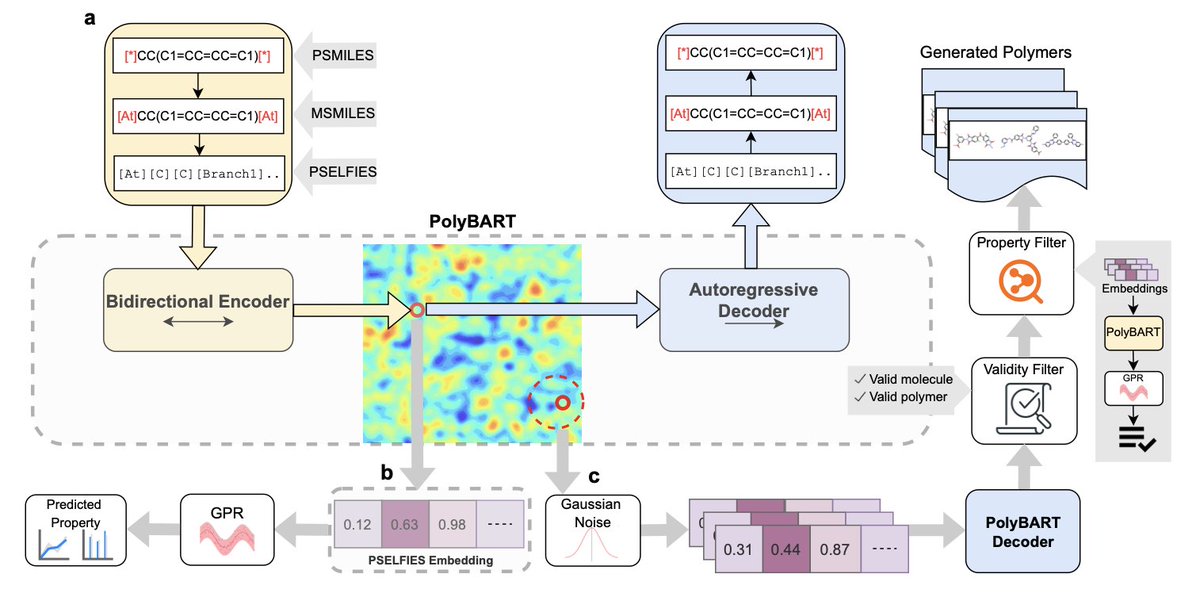
3
5
675
1 Apr 2025
Multimodal machine learning with large language embedding model for polymer property prediction
1. PolyLLMem introduces a multimodal framework that combines Llama 3-based textual embeddings from polymer SMILES with Uni-Mol-based structural embeddings to predict 22 diverse polymer properties, delivering high accuracy with minimal data.
2. Despite being trained on a relatively small dataset (29,639 data points), PolyLLMem performs comparably or better than advanced transformer and graph-based models like PolymerBERT, TransPolymer, and PolyGNN, which typically require millions of polymer samples for pretraining.
3. A key innovation is the use of Low-Rank Adaptation (LoRA) layers, which fine-tune both textual and structural embeddings during prediction, enhancing chemical relevance without retraining large models from scratch.
4. The architecture employs a gated fusion mechanism that dynamically balances text and structure embeddings, followed by a refinement block and a regression head, enabling robust single-task prediction across a wide range of polymer properties.
5. PolyLLMem achieves superior R² scores in predicting glass transition temperature (Tg), bandgaps (Egc and Egb), density, and atomization energy, and remains competitive in challenging tasks like conductivity and mechanical properties.
6. Visualization with UMAP shows that Llama 3 embeddings capture chemically meaningful clusters from polymer SMILES, and cosine similarity heatmaps reveal that token-level embeddings distinguish structural motifs like aromatic rings and fluorinated groups.
7. Integrated Gradients attribution confirms that the model focuses on chemically relevant substructures during prediction—for example, identifying trifluoromethyl groups as key contributors to high Tg.
8. Comparative analysis shows that the combined LLM Uni-Mol model outperforms models using either modality alone, and even classical ML pipelines using Morgan fingerprints or RDKit descriptors.
9. The model’s simplicity, lack of pretraining requirement, and adaptability make it a strong candidate for rapid, data-efficient polymer property screening, particularly in settings with limited experimental data.
10. While the model underperforms slightly on mechanical and gas permeability predictions, likely due to dataset limitations and single-task formulation, it offers a scalable and interpretable solution for polymer informatics.
💻Code: github.com/zhangtr10/PolyLLM…
📜Paper: arxiv.org/abs/2503.22962
#PolymerInformatics #LLMs #MultimodalLearning #MaterialsScience #DeepLearning #ChemInformatics #PolymerDesign #MachineLearning #Llama3 #UniMol #PolyLLMem
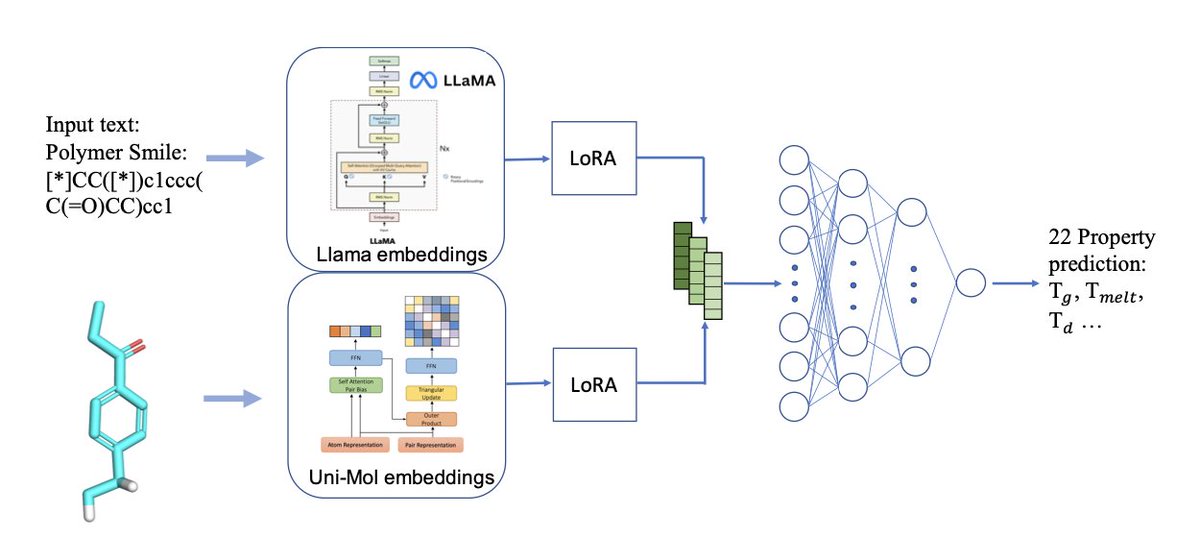
3
15
1,155
29 Mar 2025
Toward Sustainable Polymer Design: A Molecular Dynamics-Informed Machine Learning Approach for Vitrimers
1. This study presents a novel integrated MD-ML virtual screening framework for discovering high-performance vitrimers, aiming to address data scarcity and broaden the property space of sustainable polymers.
2. The framework combines molecular dynamics (MD) simulations and machine learning (ML) to predict glass transition temperatures (Tg) for vitrimers, offering an efficient tool for designing polymers with desirable properties.
3. Seven ML models (LASSO, RF, SVR, XGBoost, FFNN, GNN, Transformer) were trained on 8,424 vitrimers with MD-calculated Tg values, leveraging six molecular representations: molecular fingerprints, Mol2vec embeddings, RDKit descriptors, Mordred descriptors, graphs, and SMILES.
4. The ensemble learning approach, averaging predictions from XGBoost, GNN, Transformer, and LASSO models, demonstrated the highest accuracy (R2 = 0.78, RMSE = 15.19 K) for Tg prediction.
5. SHAP analysis provided valuable insights into molecular features influencing Tg, highlighting the significance of aromaticity, chain rigidity, and hydrogen bonding in elevating Tg.
6. The trained ensemble model was used to screen approximately 1 million hypothetical vitrimers, identifying candidates with Tg values significantly higher or lower than those in the training set.
7. Two novel vitrimers composed of commercially available acids and epoxides were synthesized and experimentally validated, achieving Tg values of 348 K and 395 K, surpassing existing bifunctional transesterification vitrimers.
8. The proposed framework effectively integrates MD simulations with ML to enhance the efficiency of vitrimer discovery, providing an interpretable, generalizable, and scalable approach to polymer design.
9. Future work will focus on extending the framework to other types of vitrimers and enhancing the interpretability of the model’s predictions for broader applications.
10. The research demonstrates the potential of integrating computational approaches for accelerating polymer discovery and designing sustainable materials with tailored properties.
💻Code: github.com/vashisth-lab/Vitr…
📜Paper: arxiv.org/abs/2503.20956
#MachineLearning #MolecularDynamics #PolymerDesign #SustainablePolymers #Vitrimers #ArtificialIntelligence #MaterialScience #Bioinformatics
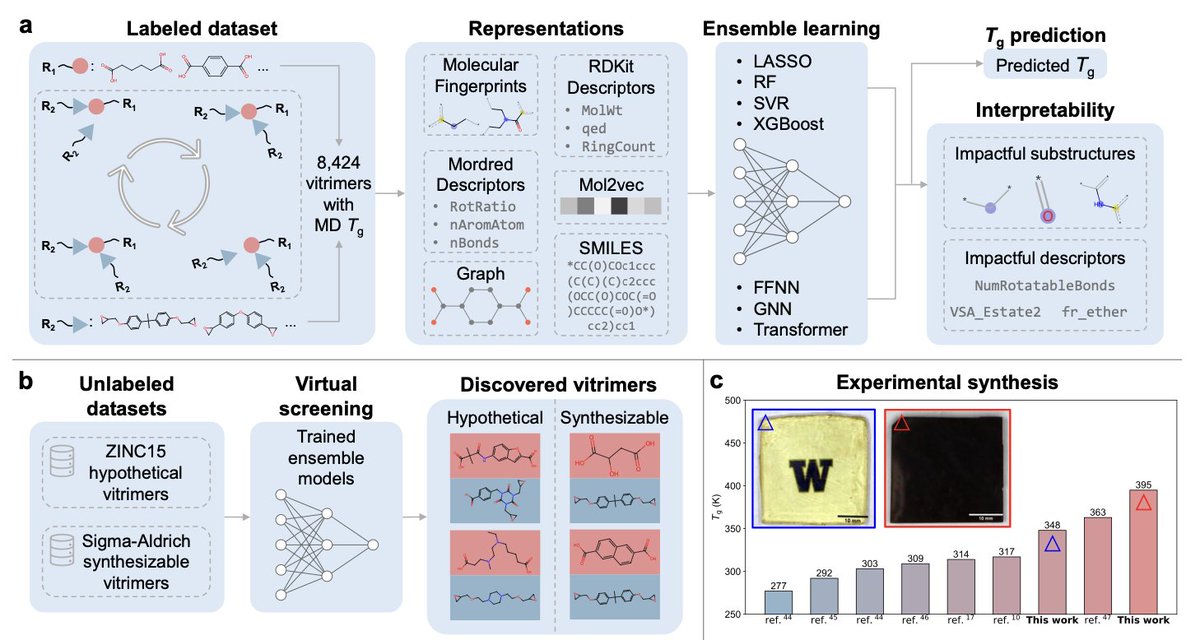
2
12
1,411
16 Feb 2025
Harnessing large language models for data-scarce learning of polymer properties @NatComputSci
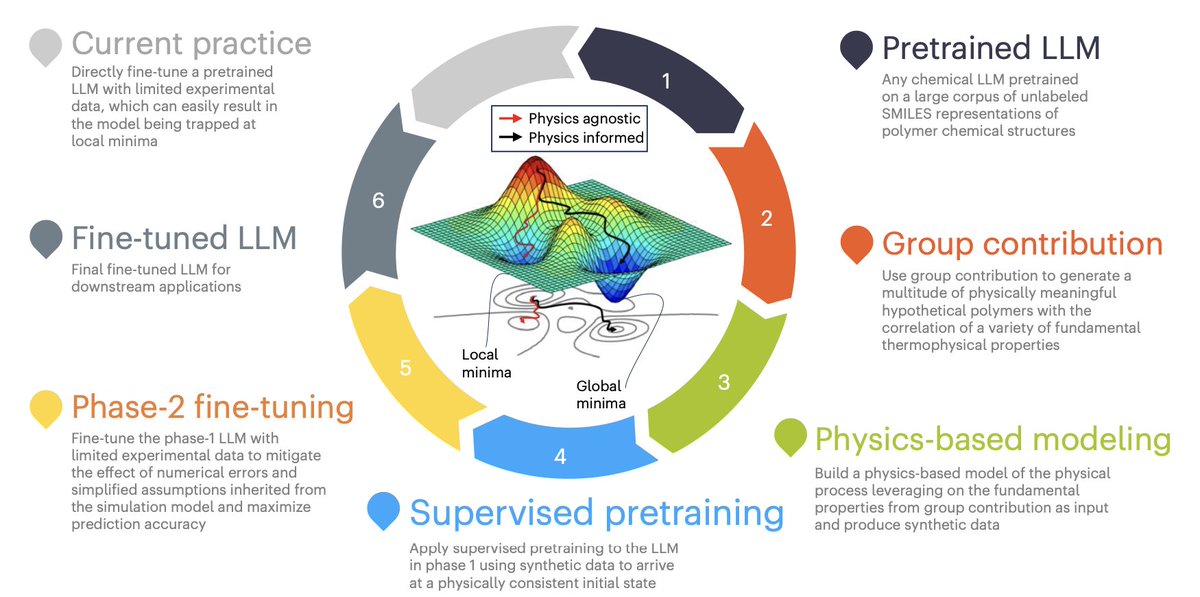
1/ This paper presents a new framework that combines physics-based modeling and large language models (LLMs) to predict polymer properties in data-scarce situations. The approach leverages synthetic data generated through physics models to effectively pretrain LLMs before fine-tuning them with limited experimental data.
2/ The two-phase training strategy starts with supervised pretraining using synthetic data that captures the physical behavior of polymers, such as flammability. This phase helps LLMs learn the underlying physical principles before transitioning to phase 2, where the model is fine-tuned with real-world experimental data.
3/ By incorporating physics-informed group contribution methods, the framework generates physically meaningful polymer data, even in the absence of large experimental datasets. This allows for the creation of synthetic polymers with associated thermophysical and pyrolysis properties, crucial for fire performance prediction.
4/ Results demonstrate that this hybrid model significantly enhances predictive accuracy, outperforming baseline LLMs by up to 50% in the prediction of key polymer properties like time to ignition and peak heat release rate, even when experimental data is limited.
5/ The framework also quantifies uncertainty in synthetic data generation, providing confidence intervals for predictions, which is vital for practical applications in material design and safety assessments, such as fire performance in polymeric materials.
6/ This approach shows promise for expanding the potential of LLMs in materials science, especially in situations where obtaining large-scale experimental data is not feasible. It opens new avenues for efficient polymer property prediction and optimization.
💻Code: github.com/ningliu-iga/Trini…
📜Paper: nature.com/articles/s43588-0…
#MaterialsScience #MachineLearning #PolymerProperties #AIinScience #PhysicsGuidedML #DataScarcity #PolymerDesign #MachineLearningForMaterials #FireSafety #MaterialPrediction
2
26
1,875
16 Feb 2025
Harnessing large language models for data-scarce learning of polymer properties @NatComputSci
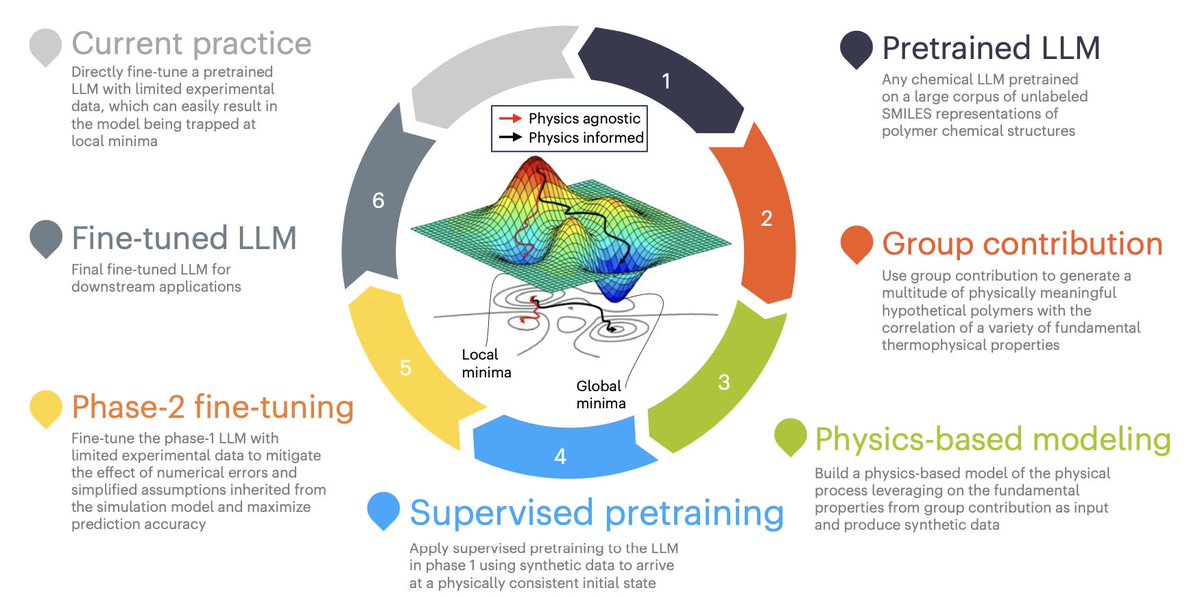
1/ This paper presents a new framework that combines physics-based modeling and large language models (LLMs) to predict polymer properties in data-scarce situations. The approach leverages synthetic data generated through physics models to effectively pretrain LLMs before fine-tuning them with limited experimental data.
2/ The two-phase training strategy starts with supervised pretraining using synthetic data that captures the physical behavior of polymers, such as flammability. This phase helps LLMs learn the underlying physical principles before transitioning to phase 2, where the model is fine-tuned with real-world experimental data.
3/ By incorporating physics-informed group contribution methods, the framework generates physically meaningful polymer data, even in the absence of large experimental datasets. This allows for the creation of synthetic polymers with associated thermophysical and pyrolysis properties, crucial for fire performance prediction.
4/ Results demonstrate that this hybrid model significantly enhances predictive accuracy, outperforming baseline LLMs by up to 50% in the prediction of key polymer properties like time to ignition and peak heat release rate, even when experimental data is limited.
5/ The framework also quantifies uncertainty in synthetic data generation, providing confidence intervals for predictions, which is vital for practical applications in material design and safety assessments, such as fire performance in polymeric materials.
6/ This approach shows promise for expanding the potential of LLMs in materials science, especially in situations where obtaining large-scale experimental data is not feasible. It opens new avenues for efficient polymer property prediction and optimization.
💻Code: github.com/ningliu-iga/Trini…
📜Paper: nature.com/articles/s43588-0…
#MaterialsScience #MachineLearning #PolymerProperties #AIinScience #PhysicsGuidedML #DataScarcity #PolymerDesign #MachineLearningForMaterials #FireSafety #MaterialPrediction
1
912

19 Feb 2024
Webinar: Advancing Molecular-Scale Modeling: A Novel Approach for #Semicrystalline #Polymers bit.ly/49l7NzO #mechanicalproperties #semicrystalline #polymer #LAMMPS #compchem #materialsdesign #materialsproperties #polymerdesign #polymersimulation #polymerindustry

2
81

27 Jan 2023
Happy to share my recent work published in ACS Appl. Mater. Interfaces. Title: “Effect of Chlorine Substituents on the Photovoltaic Properties of Monocyanated Quinoxaline-Based D–A-Type Polymers” pubs.acs.org/doi/10.1021/acs… #OrganicSolarCells #PolymerDesign
4
45
3,325

25 Oct 2022
Making complex #polymers with precisely #controlled structures becomes much simpler thanks to a new ‘one-pot-and-one-step’ #synthesis procedure.
Read more on our website 👇
#polymersynthesis #polymerdesign #catalysis #chemistry #science #research #HokkaidoUniversity #北海道大学

2
6

26 Dec 2019
Join us with #PolymerChemistry polymerchemistry.euroscicon.… Participate in 5th Edition of International Conference and Exhibition on #PolymerChemistry #PolymerEngineering #Polymernanotechnology #Polymerscience #PolymerDesign #Plastics #Bioplastics #Biomaterials #PolymerCatalysis
2

26 Oct 2019
It's out! Check out our latest paper @DDTReMedia
on how to tune the PEG surface density of PEG-PGA enveloped Octaarginine-peptide Nanocomplexes by using structurally diverse PEG-PGA shells #polymerdesign #oralproteindelivery
link.springer.com/article/10…
3
11