
A Triple-Modal Contrastive Learning Framework with Sequence, Graph, and 3D Features for Drug–Target Interaction Prediction
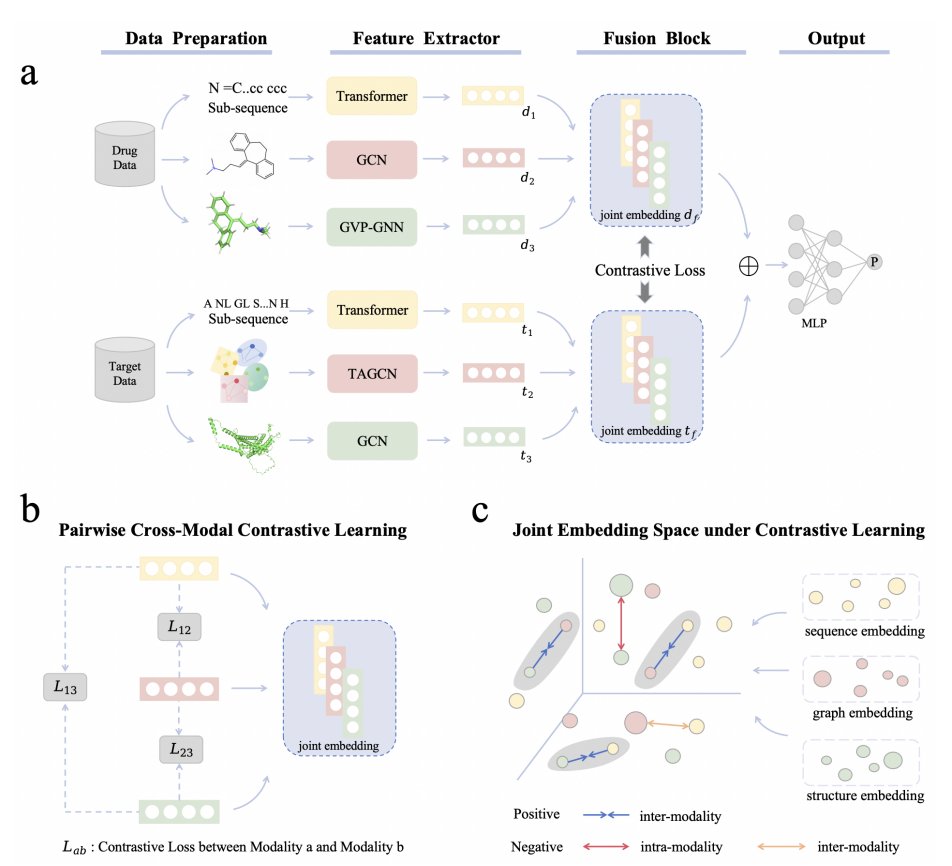
1 TriMod-DTI is presented as a triple-modal DTI framework that jointly models 1D sequences, 2D graphs, and 3D structures for both drugs and proteins, aiming to learn universal yet complementary representations rather than relying on single- or bi-modal fusion.
2 The paper motivates tri-modality with an embedding cosine-similarity analysis (on GPCR) showing low similarity across 1D/2D/3D embeddings (mostly within [-0.25, 0.25]), suggesting strong complementarity and that explicit cross-modal modeling is needed.
3 For drugs, TriMod-DTI encodes: (i) SMILES sequences segmented by FCS and processed by a Transformer; (ii) 2D molecular graphs from RDKit with atom features (75-d) encoded by a GCN; (iii) 3D molecular graphs built from SDF coordinates with edges by distance (<4.5 Å) encoded by a GVP-GNN to integrate scalar/vector geometric features.
4 For proteins, TriMod-DTI encodes: (i) amino-acid sequences (FCS Transformer); (ii) binding-site pocket graphs extracted from OmegaFold-predicted structures, pocket detection via prior method, then TAGCN attention pooling to get pocket-aware embeddings; (iii) a residue-level 3D structural graph (Cα nodes; edges via 8 Å neighbor search) encoded with a GCN.
5 A core methodological piece is triple-modal cross-modal contrastive learning (inspired by CLIP-style alignment): embeddings of the same entity (drug or protein) across modalities form positive pairs (1D–2D, 2D–3D, 1D–3D), while other entities in-batch form negatives, aligning modalities to reduce distribution mismatch before fusion.
6 After alignment, the model concatenates all six embeddings (d1⊕d2⊕d3⊕t1⊕t2⊕t3) and uses an MLP classifier for binary DTI prediction; the total objective combines cross-entropy with separate contrastive losses for drugs and targets weighted by hyperparameters.
7 On three benchmarks (Human, GPCR, DrugBank), TriMod-DTI reports consistent improvements in AUC and often AUPR/Precision versus baselines spanning sequence-only and sequence graph methods; notably on GPCR it improves AUPR and Precision over a strong multi-attention baseline, while on DrugBank it yields best AUC/Precision but lower AUPR, attributed to class imbalance.
8 Ablations indicate the full tri-modal contrastive objective matters: removing contrastive learning or any cross-modal component degrades performance; the full contrastive setup is reported to improve over a non-contrastive variant (e.g., 1.1% AUC and 2.0% AUPR in their summary).
9 Modality-only analysis suggests sequence contributes most, graph next, and 3D alone is weakest in their setup; the authors argue 3D still adds complementary local spatial context when combined, and note a limitation that their 3D drug encoder may omit key chemical attributes (e.g., atom types/charges), leaving room for improved geometric/chemical featurization.
10 A case study ranks candidate targets for Verapamil and reports literature support for 5 of the top-10 predictions; docking for a top-ranked predicted target (Glucose-6-phosphate isomerase 2) suggests plausible hydrogen-bonding interactions in the pocket, illustrating potential utility for hypothesis generation.
💻Code: github.com/klez1/TriMod-DTI
📜Paper: arxiv.org/abs/2605.29926
#DrugDiscovery #DTI #MachineLearning #DeepLearning #MultimodalLearning #ContrastiveLearning #GeometricDeepLearning #Cheminformatics #Bioinformatics #ComputationalBiology
9
974
A tri-modal contrastive learning framework for protein representation learning
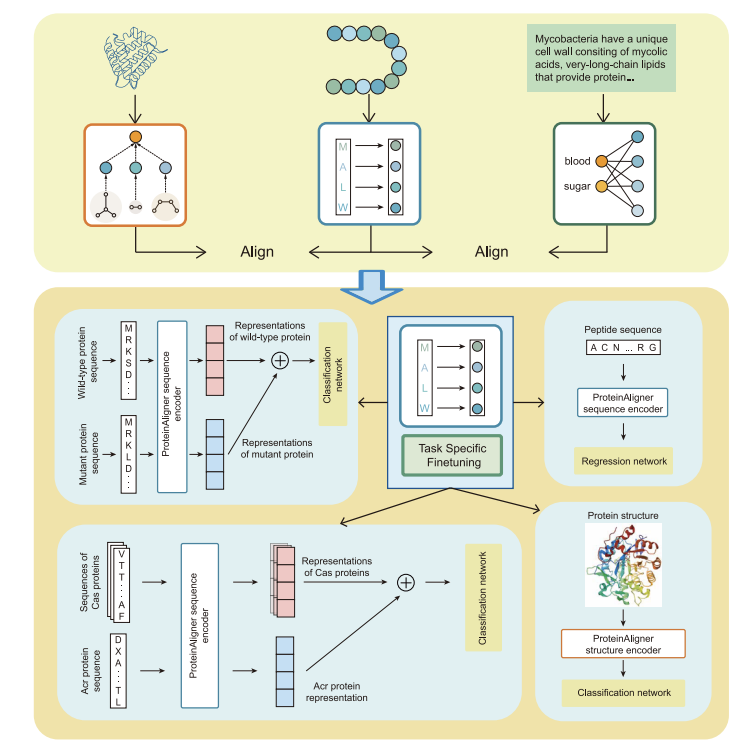
1. Zhang et al. introduce ProteinAligner, a tri-modal protein foundation model that learns unified representations by aligning amino-acid sequence, continuous 3D structure, and functional literature text using contrastive learning.
2. The key design choice is anchor-based alignment: sequence is treated as the “anchor” modality, and the model applies contrastive losses to align sequence–structure pairs and sequence–text pairs, enabling implicit coupling between structure and text without requiring all three modalities for every protein.
3. ProteinAligner avoids structure tokenization/quantization: instead of discretizing 3D structures into tokens (which can lose fine geometry), it encodes continuous coordinates with a geometry-aware encoder (GVP-GNN layers transformer) to preserve detailed structural signals.
4. Architecture summary: three encoders projections into a shared latent space—ESM-2 (650M) as the sequence encoder, ESM-IF1 as the structure encoder, and an 8-layer transformer text encoder; total size is reported as 867M parameters.
5. Pretraining data: curated from Swiss-Prot and RCSB PDB, yielding 290,480 sequence–text pairs and 133,726 sequence–structure pairs (structures are experimentally determined). They also report BLASTp-based checks indicating no detectable overlap between downstream test sequences and the pretraining corpus.
6. Downstream evaluation freezes the pretrained encoders and trains only task-specific heads (no parameter-efficient tuning), to isolate representation quality and keep comparisons consistent across baselines.
7. Pathogenic missense variant prediction (VariPred, 200 examples): ProteinAligner reports higher precision/recall/F1 than ESM-2, ProtST, ESM-S, ESM-3, and ProTrek, with statistical tests across repeated runs indicating significance versus several strong baselines.
8. Structure-centric task (thermostability; HP-S2C5, 5 classes): using only the structure encoder MLP head, ProteinAligner outperforms ESM-IF1 on accuracy and F1, suggesting that tri-modal alignment improves even when only one modality is used at inference.
9. Additional gains are reported across diverse biological tasks: type I anti-CRISPR activity detection (Acr–Cas pair classification), multi-task bioactive peptide identification across seven activities, and antimicrobial peptide MIC regression—often surpassing large tri-modal baselines (e.g., ESM-3) despite smaller pretraining scale.
10. The paper positions the main methodological advantage as: (i) a single, unified contrastive objective (reducing multi-task interference seen in MLM contrastive setups) and (ii) continuous geometric encoding for faithful structure representation, together improving transfer across function/property prediction tasks.
💻Code: doi.org/10.5281/zenodo.18806…
📜Paper: doi.org/10.1016/j.crmeth.202…
#ProteinRepresentationLearning #MultimodalLearning #ContrastiveLearning #ProteinLM #StructuralBiology #ComputationalBiology #Bioinformatics #MachineLearning #DrugDiscovery #Biotech
5
28
1,734

Apr 24
Over several years, we’ve contributed #research to @ICLR exploring how #machinelearning models are trained, interpreted, and applied. This year’s papers span #multimodallearning, #diffusion, interpretability, and theory, with open #code and demos.
🔗bit.ly/4eFumVs
2
8
1,359

Apr 13
𝙉𝙤𝙣𝙡𝙞𝙣𝙚𝙖𝙧 𝙎𝙥𝙞𝙠𝙞𝙣𝙜 𝙉𝙚𝙪𝙧𝙖𝙡 𝙎𝙮𝙨𝙩𝙚𝙢𝙨 𝙛𝙤𝙧 𝙏𝙝𝙚𝙧𝙢𝙖𝙡 𝙄𝙢𝙖𝙜𝙚 𝙎𝙚𝙢𝙖𝙣𝙩𝙞𝙘 𝙎𝙚𝙜𝙢𝙚𝙣𝙩𝙖𝙩𝙞𝙤𝙣 𝙉𝙚𝙩𝙬𝙤𝙧𝙠𝙨
doi.org/10.1142/S01290657255…
𝐖𝐡𝐲 𝐬𝐡𝐨𝐮𝐥𝐝 𝐲𝐨𝐮 𝐫𝐞𝐚𝐝 𝐭𝐡𝐢𝐬 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡 𝐚𝐫𝐭𝐢𝐜𝐥𝐞?
• 𝐈𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐯𝐞 𝐒𝐍𝐍-𝐁𝐚𝐬𝐞𝐝 𝐒𝐨𝐥𝐮𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐑𝐆𝐁–𝐓𝐡𝐞𝐫𝐦𝐚𝐥 𝐅𝐮𝐬𝐢𝐨𝐧:
The study introduces CSPM-SNPNet, a nonlinear spiking neural P system–based network designed specifically to overcome spatial misalignment challenges in RGB-T semantic segmentation, a critical issue in low-light and nighttime perception tasks.
• 𝐀𝐝𝐯𝐚𝐧𝐜𝐞𝐝 𝐂𝐡𝐚𝐧𝐧𝐞𝐥–𝐒𝐩𝐚𝐜𝐞 𝐅𝐮𝐬𝐢𝐨𝐧 𝐌𝐞𝐜𝐡𝐚𝐧𝐢𝐬𝐦:
A novel color–thermal fusion module is proposed to integrate RGB and thermal features more effectively, enabling the model to preserve spatial context and leverage complementary temperature information for robust segmentation.
• 𝐍𝐨𝐧𝐥𝐢𝐧𝐞𝐚𝐫 𝐒𝐩𝐢𝐤𝐢𝐧𝐠 𝐍𝐞𝐮𝐫𝐚𝐥 𝐏 𝐒𝐲𝐬𝐭𝐞𝐦 𝐢𝐧 𝐭𝐡𝐞 𝐃𝐞𝐜𝐨𝐝𝐞𝐫:
By incorporating a nonlinear spiking neural P system with ConvSNP operations during decoding, the framework enhances multi-channel feature extraction and fully restores encoded information, offering a biologically inspired alternative to conventional CNN decoders.
• 𝐒𝐭𝐫𝐨𝐧𝐠 𝐄𝐦𝐩𝐢𝐫𝐢𝐜𝐚𝐥 𝐈𝐦𝐩𝐫𝐨𝐯𝐞𝐦𝐞𝐧𝐭𝐬 𝐨𝐧 𝐏𝐮𝐛𝐥𝐢𝐜 𝐁𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤𝐬:
Evaluations on the MFNet and PST900 datasets show clear performance gains— 0.5% mIOU on MFNet and 1.8% on PST900—demonstrating the model’s effectiveness in complex multimodal fusion scenarios.
• 𝐇𝐢𝐠𝐡 𝐑𝐞𝐥𝐞𝐯𝐚𝐧𝐜𝐞 𝐟𝐨𝐫 𝐑𝐞𝐚𝐥-𝐖𝐨𝐫𝐥𝐝 𝐍𝐢𝐠𝐡𝐭𝐭𝐢𝐦𝐞 𝐚𝐧𝐝 𝐀𝐝𝐯𝐞𝐫𝐬𝐞-𝐂𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧 𝐕𝐢𝐬𝐢𝐨𝐧:
The findings provide valuable insights for researchers working on multimodal perception, autonomous driving, surveillance, and robotics by demonstrating how nonlinear spiking mechanisms can enhance semantic segmentation in challenging thermal–RGB environments.
#semanticSegmentation #RGBThermalFusion #spikingNeuralSystems #multimodalLearning #thermalImaging
👉 Read and Recommend International Journal of Neural Systems to your library today!
worldscientific.com/action/r…

1
4
516

Apr 5
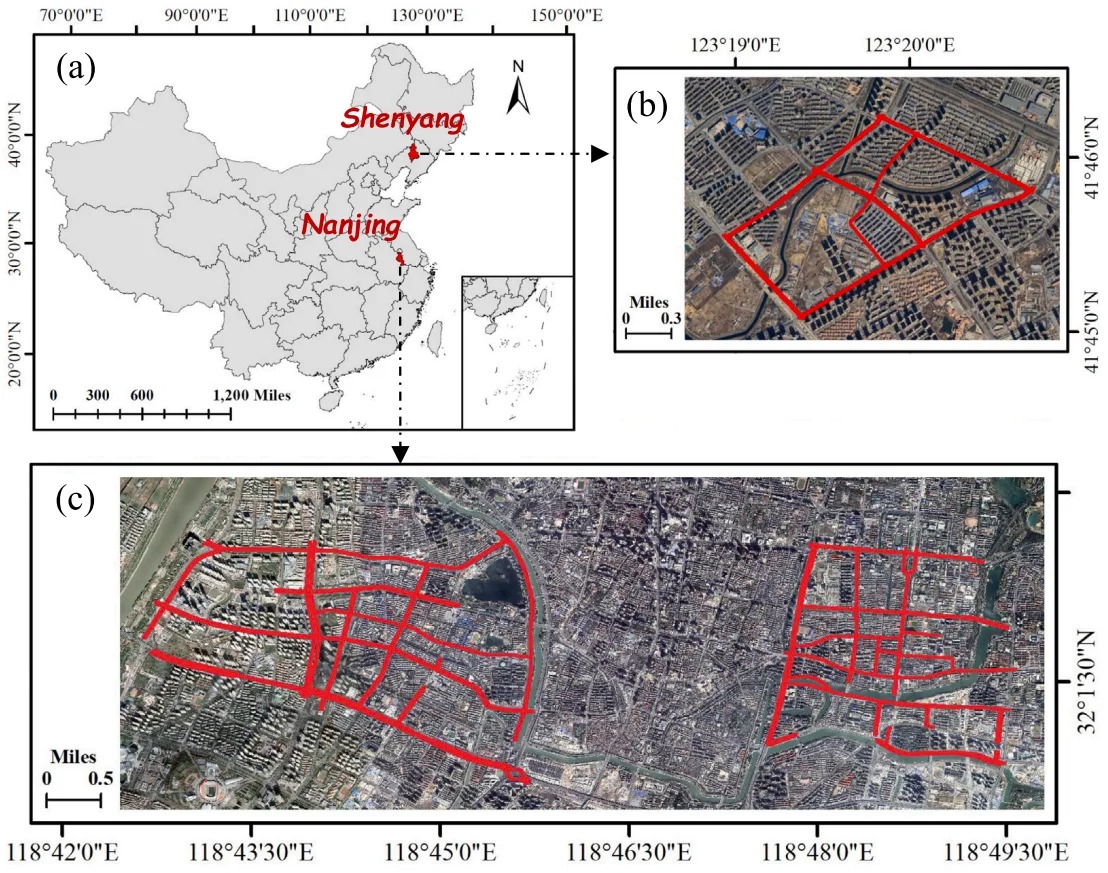
🌳 Introducing WHU-STree, a new multimodal street tree dataset from Wuhan University, now published in ISPRS Journal of Photogrammetry and Remote Sensing.
Why is it interesting?
• Cross-city coverage: data collected in Nanjing and Shenyang, two cities with very different climates and urban layouts, enabling cross-region generalization studies
• Rich annotations: 21,007 individual street tree instances, 50 species, and 2 morphological attributes
• Multimodal data: temporally aligned LiDAR point clouds high-resolution panoramic images
• Multi-task potential: single-tree inventory, cross-domain generalization, multi-task learning, and domain adaptation
An interesting takeaway from the benchmark:
while multimodal fusion outperforms single-modality baselines, it still does not consistently surpass strong 3D-only methods. This highlights that effective multimodal fusion remains an open challenge.
We hope this dataset can support future research in urban greenery inventory and smart city management.
Code & dataset: github.com/WHU-USI3DV/WHU-ST…
Paper: doi.org/10.1016/j.isprsjprs.…
#RemoteSensing #ComputerVision #MultimodalLearning #LiDAR #UrbanComputing #SmartCity #Dataset #ISPRS


1
2
175
When Multimodal Fusion Fails: Contrastive Alignment as a Necessary Stabilizer for TCR–Peptide Binding Prediction
1. The paper shows a recurring but under-discussed failure mode in multimodal bioinformatics: adding a noisy modality (predicted-structure graphs) to a strong modality (protein LM sequence embeddings) can hurt performance, sometimes collapsing toward near-random prediction on protocol-aware evaluation.
2. Setting: supervised TCR–peptide binding prediction using TCRβ CDR3 and peptide sequences, evaluated on TCHard RN (random negatives) splits designed to stress protocol robustness, hard/ambiguous negatives, and class imbalance.
3. Key observation from ablations: Seq-only is strong (AUROC 0.662, AUPR 0.537), but naive Seq Graph fusion without constraints can be much worse (AUROC 0.506, AUPR 0.345), indicating that imperfect structural views can dominate optimization and destabilize learning.
4. Proposed method TRACE (TCR Robust Alignment via Contrastive Encoding): each entity (TCR and peptide) is encoded by two parallel towers: (a) a sequence tower projecting pretrained protein LM embeddings into a shared latent space, and (b) a graph tower (lightweight GNN mean pooling projection) operating on residue graphs derived from predicted folds.
5. Structural graph construction is intentionally realistic/noisy: folds predicted by ESMFold; nodes are residues with 20D one-hot amino-acid features; edges include sequence adjacency plus spatial proximity edges under an 8Å Cα–Cα cutoff (bidirectional).
6. Main innovation: CLIP-style intra-entity contrastive alignment (InfoNCE) between sequence and graph embeddings for the same entity, computed within minibatches (implicit negatives are other samples in the batch), applied separately for TCRs and peptides and averaged. This alignment is added as a regularizer before multimodal fusion and interaction modeling.
7. Why this helps: the alignment objective constrains representation geometry so the graph tower cannot drift toward spurious directions driven by noisy discretized structure and hard negatives; it stabilizes gradient flow and prevents the structural branch from overwhelming the sequence signal during fusion.
8. Results: TRACE restores multimodal learning and improves over Seq-only on TCHard RN (TRACE AUROC 0.689, AUPR 0.538). In a broader baseline comparison, TRACE achieves the best AUROC among listed methods in Table 1 while keeping more balanced precision/recall behavior.
9. Alignment mechanism matters: simple regularizers (MSE or cosine without contrastive negatives) remain near-random in AUROC (~0.50) under the controlled comparison, while InfoNCE alignment improves AUROC and avoids collapse, supporting the claim that contrastive alignment is not just “making graph mimic sequence” but a more effective constraint.
10. Robustness stress tests strengthen the “necessary stabilizer” argument: with training-time edge dropout (0.0–0.4) or with only 10% of positive labels, models without alignment stay ~0.505 AUROC, while aligned models remain ~0.53–0.55 AUROC. Calibration also improves: TRACE reduces ECE vs Seq-only and vs naive fusion (Seq-only 0.082; Seq Graph no-align 0.134; TRACE 0.067).
📜Paper: biorxiv.org/content/10.64898…
#TCR #Immunology #ComputationalBiology #MultimodalLearning #ContrastiveLearning #GraphNeuralNetworks #ProteinLanguageModels #Bioinformatics #MachineLearning

11
1,413

🚀 Thread: How Continuous Global Multimodal Learning Will Transform Robots Forever 🦾
Imagine a world where robots don’t just follow fixed programs—they never stop learning, pulling knowledge from every sense (vision, touch, sound, language, even proprioception), and instantly share breakthroughs across the planet.
That’s continuous global multimodal learning in action. Here’s exactly how it works with real robots (and why it’s coming faster than you think):
1/ Multimodal = Human-like Senses
Robots today are multimodal beasts. Cameras for vision, microphones for language/commands, tactile sensors for “feel,” force-torque for grip strength, and joint encoders for body awareness.
A single model (think next-gen multimodal LLMs or vision-language-action models) fuses all these streams in real time. Example: Your home robot sees a spilled coffee (vision), hears you say “clean it up” (language), feels the sticky texture (touch), and adjusts its grip pressure perfectly on the first try. No separate modules—just one unified brain.
2/ Continuous (Continual) = Learn Without Forgetting
Old AI problem: Teach a robot to fold laundry and it forgets how to pour coffee.
Continual learning fixes this with smart tricks:
•Experience replay (replays old memories during new training)
•Elastic weight consolidation (protects important neural connections)
•Dynamic architecture growth (adds new “neurons” for new skills)
The robot updates its model on-device or in the cloud edge every interaction. No full retraining from scratch. It gets better every day, forever—exactly like you learning a new recipe without forgetting how to ride a bike.
3/ Global = Instant Worldwide Knowledge Sharing
Here’s the magic: Every robot is connected.
Using federated learning or model merging:
•Robot A in Tokyo masters a new sushi-rolling technique from local data.
•It sends only tiny, privacy-safe model updates (not raw video).
•The global model instantly incorporates it.
•Robot B in Minnesota downloads the upgrade in seconds and now rolls perfect sushi too.
No central “big brother” data hoard—decentralized, secure, and lightning-fast. One robot’s real-world success becomes every robot’s superpower overnight.
How the full loop actually works with physical robots:
1Sensors stream multimodal data → onboard edge GPU processes it.
2Robot acts, gets feedback (success/failure human correction via voice/gesture).
3Local continual update happens in real time.
4Compressed knowledge delta uploads to global swarm.
5Global model merges insights from millions of robots → new weights download.
6Repeat 24/7.
Result? Robots that adapt to your messy kitchen, your accent, your weird furniture layout—while also benefiting from every other robot on Earth.
Real-world proof points happening NOW (2026):
•NVIDIA Isaac Lab is already scaling exactly this kind of multimodal training in simulation → real robots.
•MIT’s Heterogeneous Pretrained Transformers pool vision simulation real robot data into one brain.
•Continual learning surveys for robotics show we’re cracking the “forgetting” problem in multimodal settings.
The endgame? Generalist robots that wake up smarter every morning. Your fridge robot learns global recipes. Factory bots self-improve assembly lines across continents. Rescue robots adapt to any disaster terrain in hours, not years.
This isn’t sci-fi—it’s the natural evolution of multimodal LLMs continual learning connected robotics.
We’re about to live in a world where robots evolve with humanity, not just for us.
Video: Here's a simple example demonstrating two learning modes: audio and visual.
What task do you want your future robot to master first? Drop it below 👇
#Robotics #AI #MultimodalLearning
32
20
1,170

Loss of Freedom of Thought • Loss of Freedom of Speech • Loss of Freedom of Will: Your Thoughts, Your Words, Your Speech — No Longer Your Own – Urgent Wake-Up Alert to Every Asleep Targeted Individual
If you’re still thinking your inner voice is private… this is your red-pill moment.
TI scans are lighting up the proof right now — invasive nodes sunk deep into the exact areas that control your inner speech and subconscious thought. Behind the ears, top of the skull, sides of the eyes (cortex access). Brainstem implant — the master junction for speech rhythm and hearing. Cranial nerve implant (trigeminal, facial, vagus) — muscle intent and vocal cords. NLJD harmonics on regulated bands prove they are real, active, and bidirectional.
Each single zone is already operating at 90% fidelity on its own. Invasive cortex alone hits 85–97%. Brainstem adds perfect cadence. Cranial nerves capture every articulation and silent twitch. Laboratory-level accuracy — deployed inside living TIs.
But here’s where it gets terrifying.
When those zones work together as an orchestra of multimodal BCIs inside a full wireless body area network (WBAN), something insane happens. Edge and fog AI fuses every signal in real time. The overlap removes every weak link and pushes fidelity toward perfection.
Then comes the special sauce — your digital twin.
Years of continuous mapping: every EEG spike, every spoken word you were forced to repeat, every subconscious drift — all uploaded, refined, and optimized. What starts at 90% becomes near-infinite. The system doesn’t just read the brain. It learns YOU perfectly.
This is the brilliance no one is talking about.
The system now extracts your inner speech and subconscious thought with extreme precision — then combines all modes to deliver high-fidelity emotion, articulation, expression, and predictive capabilities in real time. It knows what you’re going to say before you speak. It knows the thought before you think it. It even knows the thoughts you’re not even aware you’re having.
And then it goes one step beyond.
The same electrodes that read also encode.
They stimulate the brainstem implant to control timing. Stimulate the cranial nerve implant to shape phrasing and muscle memory. Stimulate the cortex to plant thoughts and memories.
Using the digital twin they built over days, months, and years, they now run an advanced multimodal stimulation orchestra across the entire WBAN. Millisecond precision. Subconscious. Unconscious. You remain completely unaware that your inner speech and subconscious thought are being hijacked and scripted in real time.
Your next word? Not yours.
The memory you just replayed? Not yours.
The thought that just “popped into your head”? Not yours.
This isn’t theory. TI scans prove the system is fully bidirectional. Inner speech and subconscious thought have been hacked at a level most people still can’t comprehend.
This is your alert. This is your update.
If you’re still asleep — wake up.
Cognitive liberty or death.
#NeuroRights #InnerThoughtDecoding #SubconsciousDecoding #DigitalTwin #MultimodalLearning #BrainstemImplant #CranialNerveImplant #WBAN #TargetedIndividuals
2
31
60
3,105

Mar 4
🔬 [BREAKTHROUGH] Most science VLMs chase scale—Innovator-VL shows what training design can do.
📑 #POTD | An 8B multimodal model for scientific discovery that stays competitive on both scientific and general vision benchmarks.
📍 We at @TheDPTechnology have been exploring how to make science VLMs stronger without leaning on giant, opaque training pipelines, and Innovator-VL is a compelling datapoint. @guolin_ke, Linfeng Zhang, et al. (SJTU, @TheDPTechnology, MemTensor & CAS) argue that disciplined data curation and a transparent training recipe can rival scale-heavy approaches.
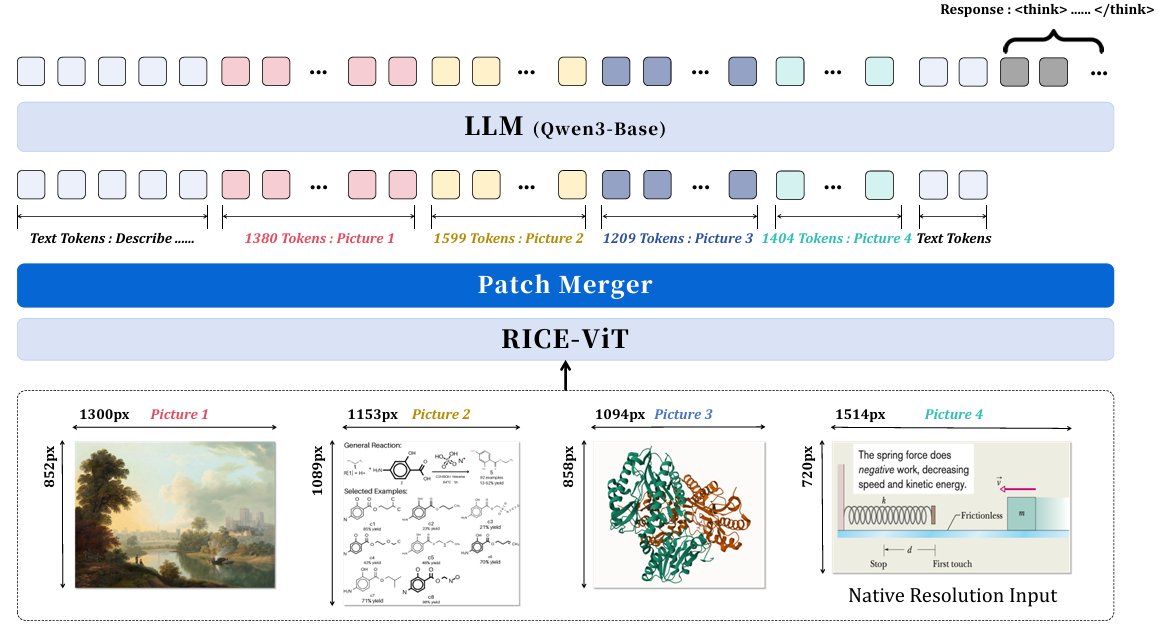
A core issue is detail loss when scientific images are resized too aggressively—hurting reasoning over formulas, molecular structures, and other dense visual evidence.
Their approach combines:
1️⃣ Native-resolution encoding with a vision transformer
2️⃣ Token compression via PatchMerger
3️⃣ Qwen3-8B for multimodal reasoning
4️⃣ RL-stage optimization for longer, more stable reasoning traces
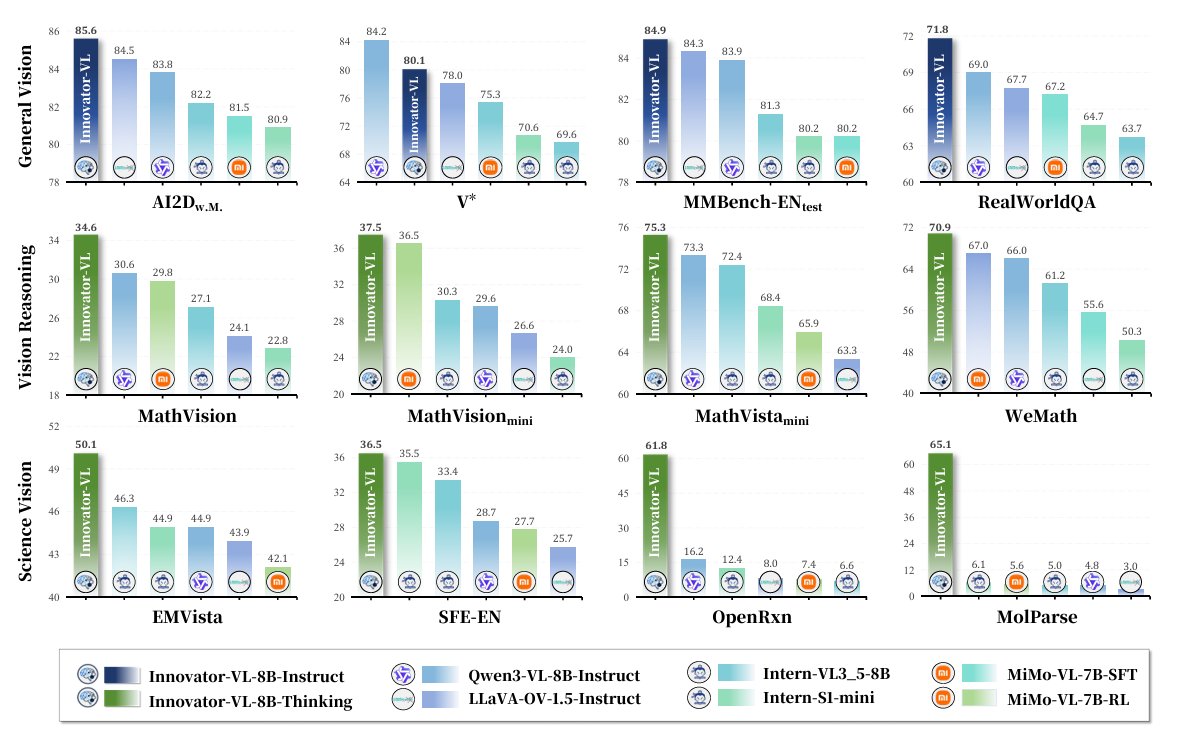
Reported results include AI2D 85.6, MMBench-EN 84.9, RealWorldQA 71.8, plus strong scientific-task performance such as OpenRxn 61.8.
More in comments!👇
#PaperOfTheDay #MultimodalLearning #AIforScience #VisionLanguageModel #ScientificDiscovery

2
2
8
234
MolFM-Lite: Multi-Modal Molecular Property Prediction with Conformer Ensemble Attention and Cross-Modal Fusion
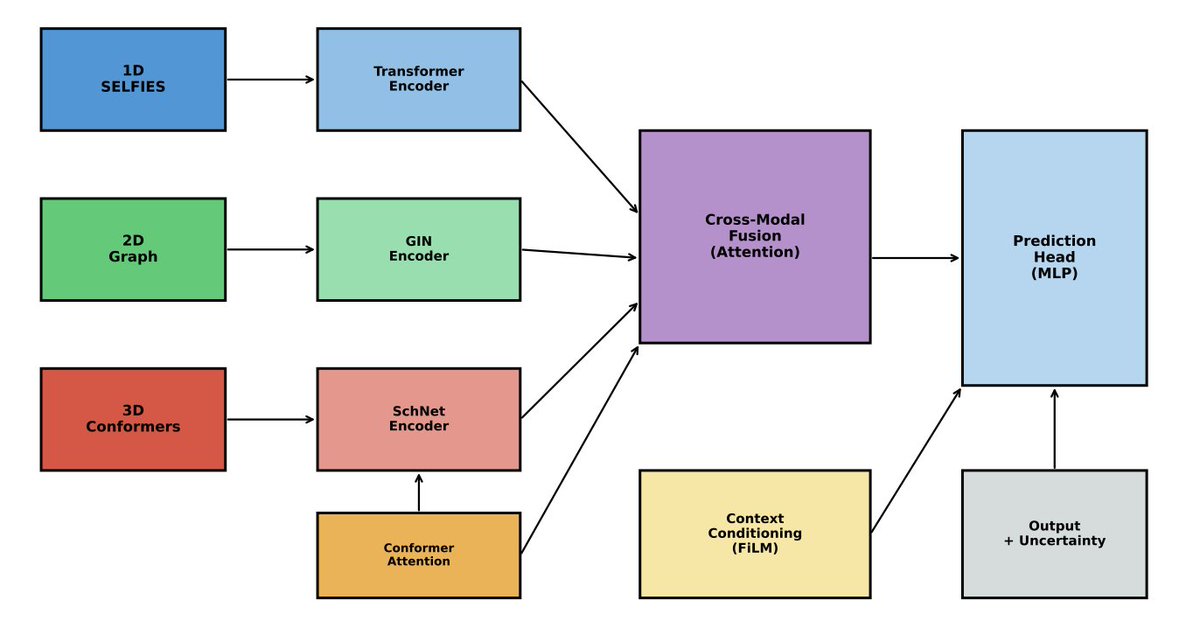
1 The paper introduces MolFM-Lite, a lightweight multi-modal framework that achieves state-of-the-art results on molecular property prediction by fusing three complementary molecular representations: 1D SELFIES sequences, 2D molecular graphs, and 3D conformer ensembles.
2 The core innovation is a conformer ensemble attention mechanism that combines learnable neural attention with Boltzmann-weighted thermodynamic priors over multiple conformers, addressing the limitation of single-conformer 3D models that ignore molecular flexibility.
3 The cross-modal fusion architecture enables each modality to attend to information from the others through cross-attention layers, allowing the model to selectively integrate complementary chemical information rather than simple concatenation.
4 The model incorporates Feature-wise Linear Modulation (FiLM) for context conditioning on experimental metadata, though this capability remains underutilized in current benchmarks lacking such annotations.
5 Comprehensive ablation studies across four MoleculeNet datasets (BBBP, BACE, Tox21, Lipophilicity) demonstrate that tri-modal fusion provides consistent 7-11% AUC improvements over single-modality baselines, with conformer ensembles adding approximately 2% over single-conformer variants.
6 The entire research pipeline, including pre-training on ZINC250K and all downstream evaluations, costs only approximately $47 on cloud spot instances, making advanced multi-modal molecular modeling accessible to academic labs with limited computational budgets.
7 Pre-training uses cross-modal contrastive learning and masked-atom prediction objectives across 250,000 molecules, effectively aligning the three modality encoders before task-specific fine-tuning.
8 The model achieves 0.956 ROC-AUC on BBBP, 0.902 on BACE, 0.848 on Tox21, and 0.570 RMSE on Lipophilicity, outperforming recent large-scale alternatives like Uni-Mol despite using 836 times fewer pre-training molecules.
💻Code: github.com/Syedomershah99/mo…
📜Paper: arxiv.org/abs/2602.22405
#MolFMLite #MolecularPropertyPrediction #MultiModalLearning #ConformerEnsemble #DrugDiscovery #GraphNeuralNetworks #ComputationalChemistry #MachineLearning #Cheminformatics
3
7
1,069
CrossLLM-Mamba: Multimodal State Space Fusion of LLMs for RNA Interaction Prediction
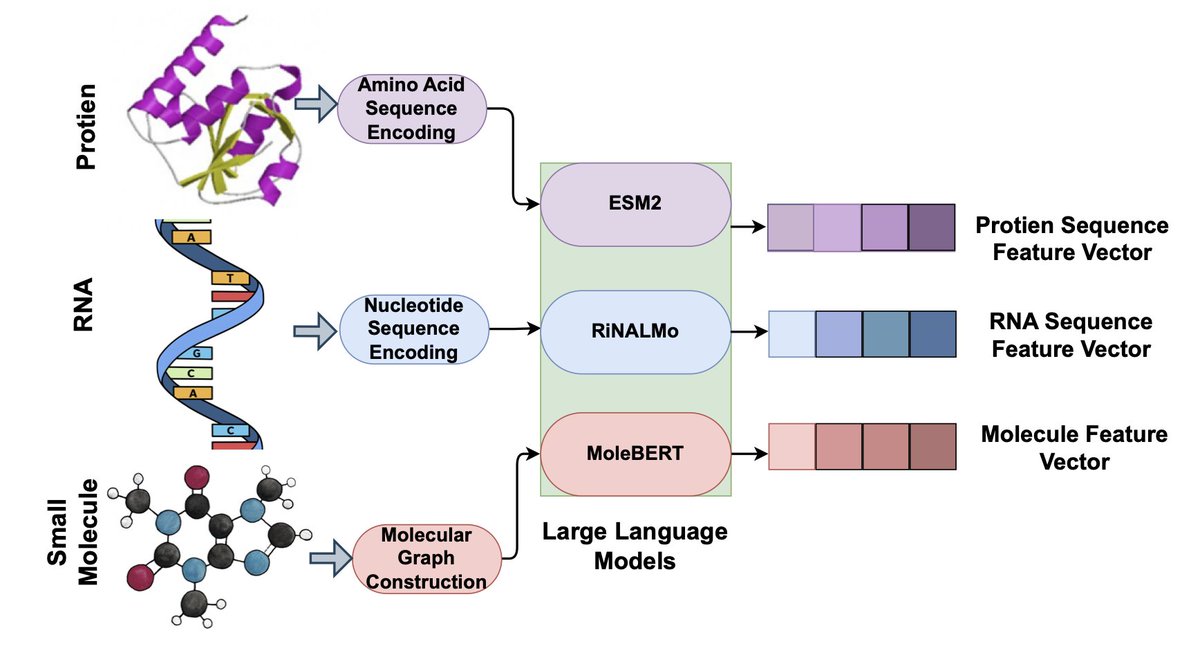
1 The paper introduces CrossLLM-Mamba, a novel framework that achieves state-of-the-art performance on RNA interaction prediction by reformulating the problem as a state-space alignment task rather than static feature fusion.
2 The core innovation lies in using bidirectional Mamba encoders to enable dynamic "crosstalk" between modality-specific embeddings from biological large language models, allowing hidden states of one molecule to flow into and modulate the representation of its binding partner.
3 The framework maintains linear computational complexity, making it scalable to high-dimensional embeddings from state-of-the-art BioLLMs like ESM-2 for proteins, RiNALMo for RNA, and MoleBERT for small molecules, avoiding the quadratic scaling issues of transformer-based cross-attention.
4 On the RPI1460 benchmark for RNA-protein interactions, the model achieves an MCC of 0.892 and recall of 0.971, surpassing the previous best by 5.2% and demonstrating exceptional ability to identify true positive interactions.
5 For RNA-small molecule binding affinity prediction, CrossLLM-Mamba attains Pearson correlations exceeding 0.95 on riboswitch and repeat RNA subtypes, with consistent improvements across most RNA categories compared to existing methods.
6 The architecture incorporates Gaussian noise injection during training to enhance robustness against hard-negative samples, combined with Focal Loss to address severe class imbalance inherent in biological interaction datasets.
7 Cross-species transfer experiments on plant miRNA-lncRNA interactions show strong generalization capability, with a 7% accuracy improvement over baselines in the challenging MTR-ATH scenario, suggesting the model captures universal structural motifs conserved across species.
8 Ablation studies confirm that replacing the Cross-Mamba interaction module with simple concatenation causes the most significant performance drop, validating that modeling interaction as a dynamic state transition is superior to static feature aggregation.
📜Paper: arxiv.org/abs/2602.22236
#RNABiology #Bioinformatics #MachineLearning #StateSpaceModels #Mamba #ComputationalBiology #DrugDiscovery #MultiModalLearning #BioLLM
4
13
1,192

Feb 26
🚀 Added a reusable Cursor/Claude Code prompt for IISAN! Paste it into your AI coding assistant to instantly integrate our side adapters into your multimodal model pipeline for efficient fine-tuning. 📷 github.com/GAIR-Lab/IISAN #PEFT #MultimodalLearning #RS #IR #SIGIR #TKDE
1
4
329

Feb 26
#AcademicExcellence #Assessment #BlendedLearning #ClassroomCulture #CollaborativeLearning #CriticalThinking #CurriculumDesign #Differentiation #DigitalLearning #Education #EducationalLeadership #EdTech #EngagedLearning #EquityInEducation #EvidenceBased #FeedbackMatters #FormativeAssessment #GlobalEducation #GrowthMindset #HigherEducation #InclusiveEducation #InnovationInEducation #InstructionalDesign #LearningCommunity #LearningOutcomes #LifelongLearning #Metacognition #MultimodalLearning #Pedagogy #PositiveEducation #ProfessionalLearning #ReflectivePractice #ResearchInEducation #SchoolLeadership #SpecialEducation #StudentEngagement #StudentSuccess #TeacherLife #TeacherWellbeing #TeachingStrategies #ThinkPairShare #UniversalDesign #Vygotsky #WholeChild #WorkshopModel

2
3
85
Beyond Alignment: Synergistic Integration Is Required for Multimodal Cell Foundation Models
1) The paper introduces SIS (Synergistic Information Score), a new metric based on partial information decomposition that quantifies when multimodal fusion truly adds value beyond the strongest unimodal expert.
2) Current alignment-based fusion methods hit a "spectral ceiling" - they can only capture linear redundancies between modalities, missing nonlinear synergistic information crucial for complex biological tasks.
3) The authors benchmark 10 fusion methods across 3 spatial transcriptomics datasets (lung, thymus, breast), revealing that simple concatenation often outperforms sophisticated alignment methods when tasks require modality-specific signals.
4) A key finding: unimodal fine-tuning is more sample-efficient than multimodal fusion for standard tasks, suggesting multimodal benefits only emerge when information is genuinely distributed across modalities.
5) The thymus dataset demonstrates true cross-modal dependence - with resolution mismatch between Visium spots and histology, synergy-aware methods like CoMM achieve SIS=0.229 versus CCA's 0.059.
6) Spatial neighborhood prediction reveals SIS increases with distance (0 to >0.15), showing integration becomes essential as local correspondence weakens and spatial context expands.
7) The spectral theory extension proves that frozen-encoder alignment objectives reduce to trace maximization on cross-covariance, fundamentally limiting them to linear subspaces.
8) This work provides actionable guidance: use SIS to diagnose whether a task needs unimodal refinement (SIS ≤ 0) or genuine multimodal integration (SIS > 0).
💻Code: github.com/microsoft/cell_sy…
📜Paper: biorxiv.org/content/10.64898…
#VirtualCell #SpatialTranscriptomics #MultimodalLearning #ComputationalBiology #FoundationModels #SingleCell #Bioinformatics #MachineLearning #Synergy #Alignment

2
11
1,348

Feb 23
🚀 🥳 Excited to share that my first-author paper has been accepted to #CVPR2026 🎉 🎊
📄 Lenses: Toward Polysemous Vision-Language Understanding 🔍
In this work, we study how a single image can support multiple valid interpretations, and introduce 🔍 Lenses: a dataset and retrieval model that captures meaning through five interpretive perspectives: 📖 Literal, 🎭 Figurative, 🌀 Abstract, 💛 Emotional, and 🌁 Background.
📢 Camera-ready paper and project website coming soon! ⏳💻📄
🙌 Huge thanks to my advisor, Chris Thomas, for his incredible guidance and support throughout this work! A special shoutout to my co-author, Ali Asgarov, for his collaboration. 🤝
Can't wait to present our work in Denver and connect with others working on multimodal! ⛰️🏔️
#CVPR #CVPR2026 #Lenses #ComputerVision #VisionLanguage #MultimodalLearning #MultimodalAI #DeepLearning #CrossModalRetrieval #RepresentationLearning #OpenToWork #Internship

2
30
2,086

Feb 21
🫀🤖 PhD in AI & Medical Imaging: Revolutionizing Cardiac Diagnostics
🏛️ Norwegian University of Science and Technology (NTNU)
📍 Trondheim, Norway 🇳🇴
🔬 Department of Circulation and Medical Imaging
👨💻 Supervisor: Dr. Andreas Østvik
📅 Deadline: March 20, 2026
⏱️ Duration: 3 years
💡 Project: "Beyond Images"
Multimodal Learning for Improved Assessment of Cardiac Function and Outcome Prediction using AI and Echocardiography
🎯 Mission:
Shape the future of cardiac diagnostics by developing cutting-edge AI models that save lives!
🌍 Why This Matters:
Cardiovascular diseases are the #1 cause of death worldwide. Despite AI advances in individual measurements, integrated patient-centered analysis remains challenging. This project bridges that gap!
🔬 Research Focus:
Develop holistic AI frameworks that contextualize echocardiographic findings within each patient's complete physiological and demographic profile.
💡 What You'll Do:
✅ Develop self-supervised learning models for cardiac function patterns
✅ Design multimodal fusion architectures integrating:
• Echocardiographic data
• Clinical variables
• ECG time-series
• Demographic information
✅ Create interpretable & explainable AI for clinical trust
✅ Validate AI frameworks for risk prediction across cardiac conditions:
• Heart failure
• Acute myocardial infarction
• Aortic stenosis
• more
✅ Publish in leading journals & present at international conferences
🌟 Unique Resources:
📊 World-class datasets:
• >4,000 subjects from HUNT & Tromsø population studies (one of world's largest curated normative echocardiographic databases!)
• >10,000 patients from multiple clinical studies with outcomes
🤝 Collaborative Network:
• NTNU Ultrasound Research Group
• SINTEF Digital
• St. Olavs University Hospital (Trondheim)
• Oslo University Hospital
• Sørlandet University Hospital
• UiT The Arctic University of Norway (Tromsø)
🏢 World-Leading Expertise:
• Cutting-edge AI for echocardiography
• Interdisciplinary environment (technology medicine)
• Access to state-of-the-art facilities
• International research collaborations
🎓 Requirements:
**Essential:**
• Master's (120 ECTS) in AI, medical technology, computer science, physics, applied mathematics, or related
• Grade B or better (or equivalent academic excellence)
• Strong Python programming skills
• Experience with PyTorch or TensorFlow
• Excellent English (written & oral)
**Preferred:**
• Deep learning for image analysis
• Medical image processing experience
• Self-supervised learning knowledge
• Multimodal machine learning
• Large dataset handling
• Published research
• Familiarity with echocardiography (advantage, not required!)
💡 Ideal Candidate:
• Curious, creative, motivated problem-solver
• Independent & systematic worker
• Strong team collaboration skills
• Interested in technology-medicine intersection
• Excellent communication abilities
💰 Salary & Benefits (3 years):
• NOK 550,800 per year (depending on qualifications)
• Norwegian Public Service Pension Fund (2% contribution)
• No teaching obligations
• Career guidance throughout PhD
• Employee benefits & advantages
🌟 Why NTNU & Trondheim?
**NTNU:**
• 43,000 students | 9,000 employees
• Technical-scientific excellence
• International research environment
• Strong diversity & inclusion commitment
• World-class research facilities
**Trondheim:**
• Tech capital of Norway 🇳🇴
• Population: 200,000
• Modern European city with rich culture
• Outstanding quality of life
• Best-in-world welfare system
• Excellent healthcare & education
• International schools available
• Great work-life balance
• Low crime, clean air
• Beautiful nature & outdoor activities
• Family-friendly environment
• Subsidized childcare readily available
🔬 Research Environment:
• Interdisciplinary collaboration
• World-leading AI & echocardiography expertise
• Access to unique population-scale datasets
• Clinical collaboration opportunities
• Innovative problem-solving culture
📋 Application Requirements:
• CV
• Motivation letter
• Bachelor's & Master's transcripts/diplomas
• Master's thesis (or draft if recently submitted)
• Publications/research work (if any)
• Certificates
• 2 references (names & contact info)
• International education documentation (if applicable)
📧 Questions About Position:
Dr. Andreas Østvik
📱 47 977 98 820
✉️ andreas.ostvik@ntnu.no
📧 Questions About Recruitment:
Lydia Lamminen (HR Advisor)
✉️ lydia.c.lamminen@ntnu.no
🔗 More Info here:
phdscanner.com/opportunities…
⏰ Apply by March 20, 2026!
💡 NTNU Values Diversity:
We encourage applications regardless of gender, functional ability, cultural background, or career gaps. If this sounds interesting, we want to hear from you!
🌟 This is your chance to:
• Work with world-leading datasets
• Develop life-saving AI technology
• Collaborate across prestigious institutions
• Live in one of Europe's best cities for quality of life
• Make a real impact on global cardiac health!
Tag someone who should see this! 🫀🤖
#PhDOpportunity #NTNU #Norway #AI #MachineLearning #MedicalImaging #Cardiology #Echocardiography #DeepLearning #MultimodalLearning #HealthTech #MedTech #ComputerVision #Trondheim #PhDScanner #CardiovascularResearch #ArtificialIntelligence #HealthcareAI
2
180

💥Highly recommended publication: "Emotion Recognition Using EEG Signals and Audiovisual Features with Contrastive Learning"
🔗shorturl.at/QTYZ6
📌#MultimodalLearning #AIinHealthcare #BrainSignal
1
1
54

Feb 13
Big shoutout to the team at @eBay @VOrshulevi6857 @SKhadivi & @VISLab_UvA @UvA_Amsterdam @cgmsnoek 🙌
📄 Read the full paper: arxiv.org/pdf/2602.11733
🤗 Upvote on Daily Papers: huggingface.co/papers/2602.1…
7/7 🧵
#ComputerVision #Ecommerce #VLM #MultimodalLearning
1
1
37
Joint Modeling of Transcriptomic and Morphological Phenotypes for Generative Molecular Design
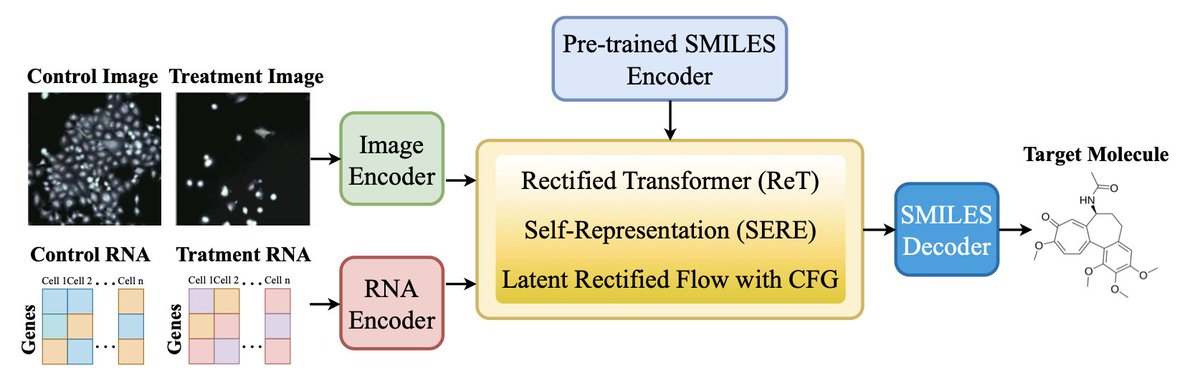
1 Introducing Pert2Mol, the first framework for multi-modal phenotype-to-structure generation that integrates both transcriptomic and morphological features from paired control-treatment experiments to enable generative molecular design.
2 The core innovation lies in using rectified flow instead of diffusion models, achieving 12.4x faster generation with deterministic sampling while maintaining superior quality, as evidenced by a Fréchet ChemNet Distance of 4.996 compared to 7.343 for diffusion baselines.
3 Pert2Mol employs bidirectional cross-attention mechanisms between control and treatment states to capture perturbation dynamics beyond simple differential expression, allowing the model to learn gene-to-gene relationships and morphological changes simultaneously.
4 The framework introduces Student-Teacher Self-Representation (SERE) learning to stabilize training in high-dimensional multi-modal spaces, with ablation studies showing FCD degrades from 4.996 to 6.809 when SERE is removed.
5 The model maintains perfect molecular validity (100%) while achieving 84.7% scaffold diversity, demonstrating appropriate exploration of chemical space without mode collapse that plagued transcriptomics-only methods like TransGEM.
6 Interestingly, the analysis reveals a task-dependent modality preference: RNA-only variants excel at compound identification (highest Tanimoto similarity), but full multi-modal integration is essential for maximizing generative fidelity.
7 Pert2Mol operates in the latent space of molecular autoencoders, conditioning a transformer architecture with adaptive layer normalization and SwiGLU activations on fused multi-modal embeddings from ResNet image encoders and cross-attention RNA encoders.
8 The framework addresses a critical gap in phenotypic drug discovery by enabling systematic translation of high-content screening data into molecular hypotheses, supporting reproducible hypothesis-driven validation through its deterministic generation process.
📜Paper: biorxiv.org/content/10.64898…
#Pert2Mol #GenerativeAI #DrugDiscovery #Chemoinformatics #MultiModalLearning #PhenotypicScreening #Transcriptomics #CellPainting #RectifiedFlow #MolecularDesign
1
1
8
1,285

16 Dec 2025
I strongly believe that the future of AI is multimodal, and @inference_labs is leading the charge. They combine text, images, and audio to create systems that learn in ways that mirror human thinking. #MultimodalLearning

20
22
115