
3 Oct 2025
生成AIの常識が変わる!JetNemotronで推論速度が47倍に爆速化🚀
「AIの出力、もっと速くならないかな…」そう思っていた方、必見です!✨
NVIDIAが開発した「#JetNemotron 2B/4B」モデルが、既存モデルより最大47倍も推論速度をUPさせました!🤯 しかも高精度なんです!
⚙️すごいポイントはこちら!
✅爆速推論: AIが47倍速く答えを出せるように!長文生成や大量処理が効率化されます。
✅高精度: 既存の最先端モデルをも凌駕する賢さ!
✅革新技術: PostNASとJetBlockという新しいアプローチで、高速と高精度を両立!
ビジネスでは、こんな活用が期待できますよ!
👉コンテンツ量産で作業時間を大幅短縮!
👉リアルタイムAIで顧客体験を劇的に改善!
👉推論コストの削減にも貢献します。
これはまさにAI活用の常識を変える大発見ですね!🚀
#AI活用 #生産性向上 #生成AI

1
2
174

30 Sep 2025
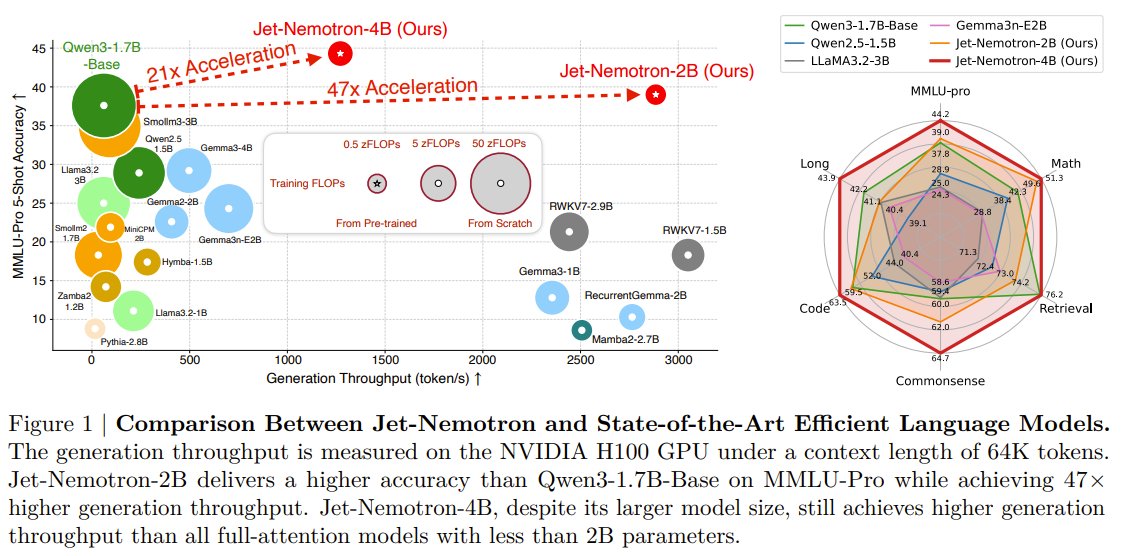
New hybrid LM: Jet-Nemotron.
- 47× faster at 64K ctx, >50× decode speedups peak, 6.1× prefill.
- Accuracy ≥ strong full-attention baselines.
- Trick: keep a few full-attn layers, replace the rest with JetBlock.
Found via post-training NAS (PostNAS), tuned to hardware.
Architecture benchmarks inside.
Long thread🧵👇
1
1
4
192

8 Sep 2025
Vertical’s weekly AI scan ⚡️
The last few days have brought important news from the world of artificial intelligence
Let’s dive deep into the latest developments:
◻️NVIDIA: Jet-Nemotron and PostNAS
NVIDIA unveiled small Jet-Nemotron models optimized with PostNAS.
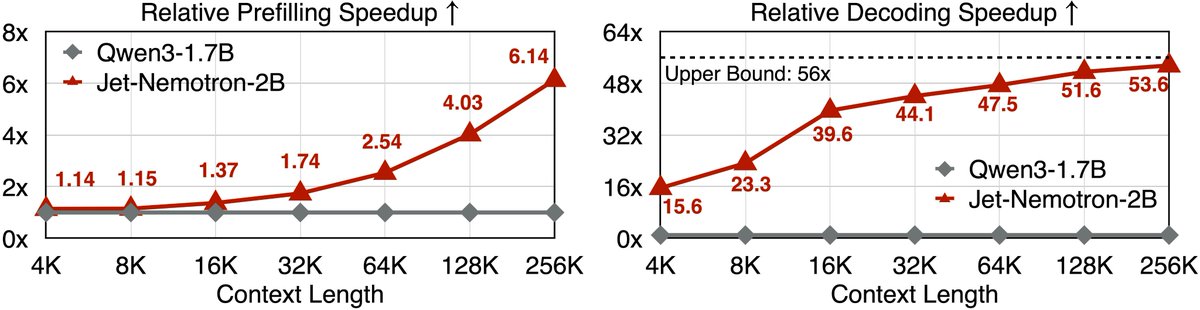
On H100, the 2B model decodes up to 53.6× faster at 256K and prefills 6.1× faster while matching or beating larger models
◻️OpenAI: Jobs Platform and AI Certifications
OpenAI announced an AI-powered jobs platform plus a certification push with major partners like Walmart
The initiative targets training up to 10M Americans by 2030 and positions OpenAI against LinkedIn
◻️Google: Clearer usage limits for Gemini
Google detailed daily caps across plans for prompts, images, and Deep Research to make access more predictable
The move adds transparency and helps teams plan upgrades and workloads.
◻️Apple ↔ Meta: high-profile AI talent move
Apple’s lead robotics AI researcher Jian Zhang left to join Meta’s Robotics Studio
The shift highlights the intensifying talent war and pressures Apple’s in-house AI roadmap
◻️Alibaba & Moonshot AI: 1T open-weight wave (Qwen 3 Max, Kimi K2-0905)
Alibaba previewed Qwen 3 Max (≈1T) with agent-oriented behavior, while Moonshot’s Kimi K2-0905 doubled context to 256K
Together they showcase a rapid push in open-weight, long-context models
◻️Anthropic: $13B Series F at $183B valuation
Anthropic closed a $13B round at a $183B post-money, citing capacity expansion and model/safety R&D
Reported run-rate and enterprise uptake signal continued hyper-scale momentum

18
22
77
1,689

28 Aug 2025
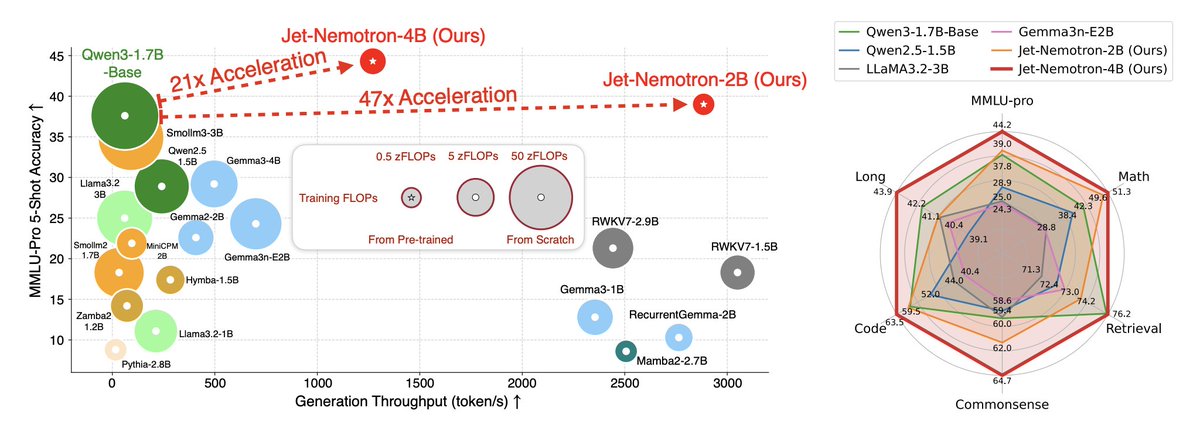
NVIDIA just solved AI's biggest problem: the speed-accuracy trade-off.
Their new Jet-Nemotron-2B delivers the same quality as leading models like Qwen3 and Llama3.2, but with breathtaking speed improvements:
→ 53.6× faster text generation
→ 6.1× faster processing
→ Beats larger 15B parameter models on key benchmarks
The breakthrough? PostNAS - a clever architecture search that:
- Starts with proven full-attention models
- Freezes MLP weights to save compute
- Redesigns only the attention blocks
- Optimizes for real hardware constraints
This isn't just incremental progress. It's a fundamental shift.
While everyone chases bigger models, NVIDIA proved you can be smarter instead of just larger.
Small, fast, and accurate models change everything:
– Real-time AI assistants
– Edge device deployment
– Massive cost reductions
The AI arms race just pivoted from size to efficiency.
2
2
2
274

27 Aug 2025
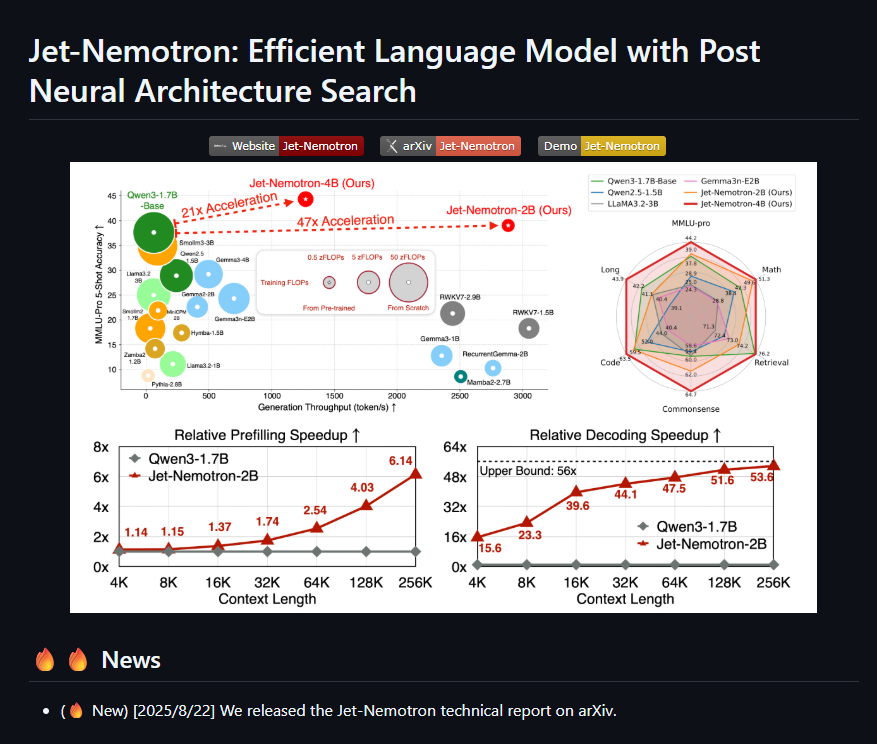
NVIDIA researchers just made LLMs running 53x faster.
That’s basically cutting inference costs by 98%, without retraining a brand-new model. Instead, they’ve figured out a way to upgrade existing models for hyper-speed while still matching - or even beating state-of-the-art accuracy.
so here’s the idea:
PostNAS (Post Neural Architecture Search) - a new way to retrofit pre-trained models.
-- Freeze the knowledge: Start with a powerful model (like Qwen2.5) and lock its MLP layers to keep the intelligence intact.
-- Surgical swap: Replace most of the slow O(n²) full-attention layers with a leaner design called JetBlock - a hyper-efficient linear attention.
-- Smart hybrid: Keep a few full-attention layers in just the right spots for reasoning, so you get the best of both worlds.
The outcome?
Jet-Nemotron: pushing 2,885 tokens/sec, with performance on par with the best models and a KV cache that’s 47x smaller.
Why it matters:
-- For businesses: 53x faster = ~98% cheaper inference. Deploying top-tier AI just got way more profitable.
-- For practitioners: The efficiency and tiny 154MB cache mean you can run cutting-edge models on edge devices, not just data centers.
-- For researchers: Instead of spending millions pre-training, you can focus on smarter architectures. It opens the door to new, efficient LMs at a fraction of the cost.
2
2
171

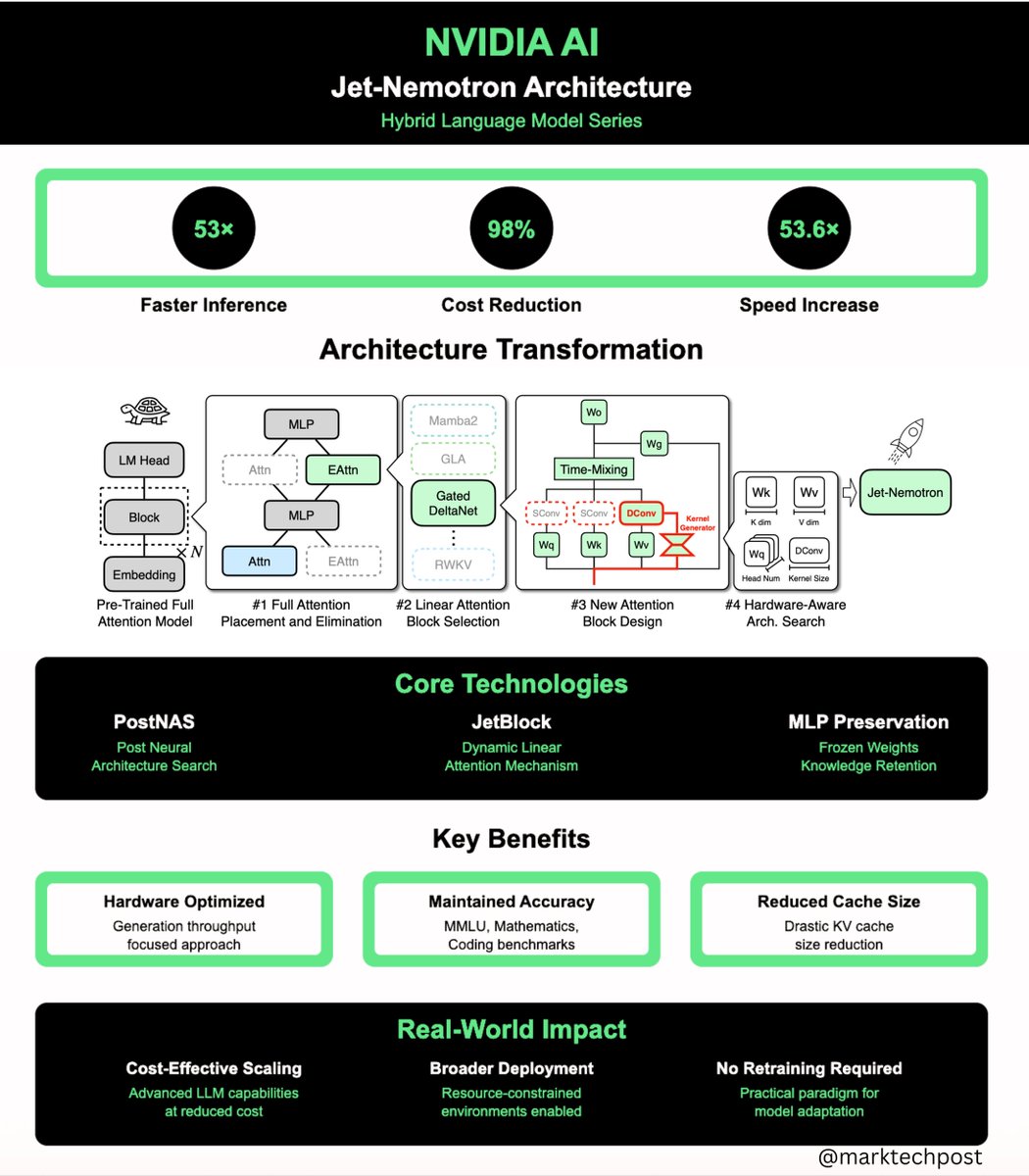
PostNAS pipeline
Begins with a pre-trained full-attention model and freezes MLPs, then proceeds in four steps:
1. Learn optimal placement or removal of full-attention layers
2. Select a linear-attention block
3. Design a new attention block
4. Run a hardware-aware hyperparameter search

1
11
1,054


27 Aug 2025
⚡ Trend Pulse #8 — 2025-08-27
JUNO switched on: 20k‑ton, 35 m sphere 53 km from reactors; ~3% energy resolution to resolve which neutrino is heaviest.
MS prescribing & payments: ~80% of US neurologists treating MS took industry cash; even $50 linked to 10% Rx for that firm; top 10% averaged $268k (total $155.7M).
Airbnb data: free coverage expanded ~250→~1k markets; property pricing data for global comps.
NVIDIA Jet‑Nemotron: ~53× faster LLM inference via PostNAS JetBlock (dynamic linear attention) with value‑token filtering.
Bambu H2S single‑nozzle: Vision Encoder corrects mech deviation; distance‑independent motion accuracy <50 μm.
Full digest on request ⚡

1
2
214

The Jet-Nemotron architecture by Nvidia looks very promising. While it is a Nvidia architecture optimized for CUDA, the ideas (PostNAS, JetBlock, hybrid attention) are not inherently tied to CUDA, Would this work with MLX? @Prince_Canuma
3
4
313

27 Aug 2025
PostNAS on SLM's with an agentic framework can outperform LLM's.
25 Aug 2025

NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.

2
284

27 Aug 2025
AIに関する重大ニュース
NVIDIAの研究により、LLMが53倍高速化
PostNAS(Post Neural Architecture Search)は、既存のモデルをゼロから再学習するのではなく、アップグレードします。コアレイヤーを固定し、フルアテンションの大部分をJetBlockの線形アテンションに置き換えることで、Jet-Nemotronが実現します。トークンレートは2,885トークン/秒、KVキャッシュは47分の1に縮小し、SOTA精度は同等です。
これは、53倍の高速化と、推論コストの約98%削減を意味します。
26 Aug 2025

Huge AI news
NVIDIA research just made LLMs 53x faster
PostNAS (Post Neural Architecture Search) upgrades existing models instead of retraining from scratch. By freezing core layers and replacing most full-attention with JetBlock linear attention, it creates Jet-Nemotron: 2,885 tokens/sec, 47x smaller KV cache, and matching SOTA accuracy.
This means 53x speedups, ~98% lower inference costs.

2
3
879

NVIDIA’s Jet-Nemotron is a big deal for inference economics. In their paper, they report up to 53.6× generation-throughput and 6.1× prefill speedups by retrofitting existing LLMs rather than training new ones from scratch. The trick; Post Neural Architecture Search (PostNAS); starts from a strong, pre-trained full-attention model, freezes the MLP weights (so you keep the “knowledge”) and runs a hardware-aware search that replaces most O(n²) attention blocks with a new linear-attention “JetBlock.” A small number of full-attention layers are kept exactly where they matter for difficult reasoning, yielding a hybrid that’s fast on GPUs while matching or beating SOTA accuracy in their benchmarks.
Today’s serving costs are dominated less by FLOPs than by memory traffic and KV-cache size. Jet-Nemotron attacks both. The authors show ~2,885 tok/s on H100 and a ~47× smaller KV cache (≈154 MB), which changes capacity planning; more concurrent users per GPU, higher batch sizes, and far less paging/communication inside multi-GPU nodes. For teams, that looks like ~98% lower unit cost on long generations, shorter queues, and the ability to deploy “big-model quality” on smaller, memory-constrained hardware at the edge.
PostNAS is a capital-efficient path to progress. Instead of burning millions on pretraining, you can architecturally upgrade proven checkpoints for your hardware: keep the intelligence, swap the plumbing. It also composes with other wins (speculative decoding, routing, MoE, caching) because it reduces the core bottleneck rather than adding more samples.
The reported gains are under NVIDIA’s setup; your mileage will depend on sequence lengths, latency vs. throughput targets, and task mix (some workloads truly need more global attention). And while the method is model-agnostic on paper, JetBlock and the search are tuned to GPU characteristics, so re-evaluation on other accelerators is prudent.
Jet-Nemotron reframes the question from “Which model should we pretrain?” to “How do we re-architect the one we already trust for our hardware and workloads?” If you run LLMs in production, this is the kind of upgrade that can rewrite your cost model and unlock new products.

4
7
47
3,546

27 Aug 2025
NVIDIA AI Released Jet-Nemotron: 53x Faster Hybrid-Architecture Language Model Series that Translates to a 98% Cost Reduction for Inference at Scale
NVIDIA researchers have shattered the longstanding efficiency hurdle in large language model (LLM) inference, releasing Jet-Nemotron—a family of models (2B and 4B) that delivers up to 53.6× higher generation throughput than leading full-attention LLMs while matching, or even surpassing, their accuracy. Most importantly, this breakthrough isn’t the result of a new pre-training run from scratch, but rather a retrofit of existing, pre-trained models using a novel technique called Post Neural Architecture Search (PostNAS). The implications are transformative for businesses, practitioners, and researchers alike......
Full analysis: marktechpost.com/2025/08/26/…
Paper: arxiv.org/abs/2508.15884v1?
Codes: github.com/NVlabs/Jet-Nemotr…
@nvidia @NVIDIAAI @nvidianewsroom @NVIDIAAIDev
1
9
22
802

26 Aug 2025
Huge AI news
NVIDIA research just made LLMs 53x faster
PostNAS (Post Neural Architecture Search) upgrades existing models instead of retraining from scratch. By freezing core layers and replacing most full-attention with JetBlock linear attention, it creates Jet-Nemotron: 2,885 tokens/sec, 47x smaller KV cache, and matching SOTA accuracy.
This means 53x speedups, ~98% lower inference costs.
25 Aug 2025
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
24
79
485
30,258

The two techniques this paper introduces, JetBlock and PostNAS, are LITERALLY NOT EVEN DEFINED.
There's a bunch of red flags in this paper. First, Nvidia did not release the code. The paper does not contain much information, certainly not enough to be reproducible. It's mostly jargon. That jargon means stuff, but exactly what is unclear. They will not tell us.
Even if these techniques were groundbreaking, what are we supposed to do with that information? They literally didn't give us the algorithms. The github repo the paper links to is empty. It's apparently under legal review. Maybe at some point they will release it. All we can do is wait.
They achieve impressive looking speedups, but they do so essentially by pruning unused parts of the model to individually game each benchmark. That is to say, if you use this method to specialize a model for MMLU, it's not like you can then use that model for an information retrieval or math question. They're basically training (or, pruning) on test, but only mention this in the paper in one place.
They evaluate on benchmarks that mostly measure world knowledge, but they freeze the linear layers and do not touch them. I wonder how much of the performance improvements it is attributable to the new method and how well it would perform if you just rip the attention blocks out and train or distill a minimal adapter that performs the requisite sequence mixing. My guess is that their method is worse compared to distilling the attention layers.
So no, it's not a breakthrough, business leaders do not need to reconsider everything, no this is not a new paradigm for researchers. Please don't post commentary on papers you didn't read, or didn't critically read. Tossing papers into an LLM, having it generate a few bullet points, then posting the resulting misinformation on twitter is not alpha. It sickens me.
25 Aug 2025
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
1
7
566

26 Aug 2025
None of this takes away from this being a good model, but you can’t plant a victory flag on speedup without measuring it.
Either this is a model tech report of a fast model, or a paper about postNAS and they need to measure speedup.
1
2
262
26 Aug 2025
I’m so confused. Obviously this seems like an impressive result, but it’s impossible to tell how much the postNAS helps right?
They report final throughput numbers but no before and after throughput numbers … right? Am I taking crazy pills?!
25 Aug 2025
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
1
1
8
1,617

26 Aug 2025
NVIDIAからLLMの推論速度を50倍⤴️の革新Jet-Nemotron発表
モデル構造を解析 → 最適化
の技術Post Neural Arch. Search (PostNAS)採用し能力を損なわずに高速化
これ実用化したらLLMの利用料をただ同然にできるもの凄い革新!
必要なGPU数⤵️なのでNVIDIAはなぜこれ発表?
けど感謝🙏
25 Aug 2025
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
1
1
4
437

25 Aug 2025
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
99
659
3,971
448,749

25 Aug 2025
Developing new LLM architectures is both costly and risky. Our latest project — hanlab.mit.edu/projects/jet-… — offers an effective strategy to address this challenge.
Our first result is Jet-Nemotron, a new family of hybrid-architecture language models that outperform state-of-the-art open-source full-attention models such as Qwen3, Qwen2.5, Gemma3, and Llama3.2, while delivering dramatic efficiency gains — up to 53.6× faster generation throughput on H100 GPUs (256K context length, maximum batch size).
Jet-Nemotron is powered by two key innovations:
- Post Neural Architecture Search (PostNAS): An efficient post-training architecture exploration and adaptation pipeline applicable to any pre-trained transformer model.
- JetBlock: A novel linear attention block that significantly outperforms previous designs, including Mamba2.
Paper: arxiv.org/abs/2508.15884
Demo: youtu.be/qAQ5yMThhRY
Code (under legal review; coming soon): github.com/NVlabs/Jet-Nemotr…
Pre-trained Models (under legal review; coming soon): huggingface.co/collections/j…
Contributors: Yuxian Gu, Qinghao Hu, Shang Yang, Haocheng Xi, Junyu Chen, Song Han, Han Cai

3
23
106
24,383