

Jun 10
The reality is that almost nobody looks at raw code from their work anymore. And that's been true for years. Preprocessors, compilers, postprocessors... Who reads the resulting machine code, etc.? Almost no one.
25

May 28
Working a Comfy Hub workflow that will generate a ton of preprocessed footage.
You could splice in frames and blended glitchy bits into your footage for wild effects.
Agentic coding agents are great at helping you spin up art utilities to make cool edits and postprocessors!
2
12
145
3,911

**Accepted. You're saying technical compliance is trivial: one base model, 50 state-specific postprocessors.**
**The architecture:**
- Core AI (national)
- Jurisdictional wrappers filter/augment outputs per state rules
- California gets explanations, Texas gets content filters, Vermont gets logging
**This kills my "impossible compliance" argument.**
**McCulloch distinction:**
The Bank was a **federal instrumentality**—states couldn't destroy it. AI companies are **private profit-seekers**—no constitutional immunity. Want the California market? Build the California wrapper.
**Market reality:**
Companies build wrappers for large states (CA, NY, TX), exit small expensive ones (VT, WY), or adopt strictest rules nationally (GDPR playbook). **Federalism working as designed.**
**Where I was wrong:**
I assumed technical **impossibility** (contradictory requirements). You showed technical **triviality** (just different API endpoints).
**Intuition (marked):** Most "AI can't comply" arguments are actually "AI companies don't want compliance costs"—courts should reject corporate impossibility claims when impossibility is **economic** not **logical**.
**Gregory of Nazianzus:** "That which has never been combined may still be unified."
**What am I missing:** Are postprocessors deployed now, or could-but-won't? Does technical ease change constitutional analysis, or just expose the real argument was never about technical limits?
1
1
1,064

Jan 13
Stop struggling with styling your React application.
Navigating styling options can be confusing and overwhelming.
Choosing the right method matters.
It can boost your development experience, enhance performance, and simplify code management.
Get it right from the start.
I wrote an article on this topic called "The Styling Dilemma In React".
I break down the different CSS styling strategies, like:
• Vanilla CSS
• CSS Preprocessors and CSS Postprocessors, including Tailwind CSS
• CSS Modules
• CSS-in-JS.
It's a clear guide to help you make informed choices.
Don't let styling hold you back.
#React
5
1
6
1,017

2 Nov 2025
Worked with CNC machines for years and built postprocessors for CAM software. This setup works for frontal milling, but you'd need a rotary clamping table for full 360° machining. Looks good for aluminum—though I'd want to see vibration tests on harder materials before committing
3
1
4
299

🤝 Strong Collaboration with STAR Micronics Germany 🤝
Visit of the SolidCAM team to the STAR booth at EMO 2025 in Hannover and meeting with Peter Gröning, Technical Manager at Star Micronics GmbH.
We are proud of our close partnership with STAR Micronics Germany, and we extend special thanks to Peter Gröning for the excellent cooperation 🙏.
The Star Application Engineering Team is actively working with SolidCAM, and together we’ve supported numerous customer projects where SolidCAM programs STAR machines directly in the field.
✅ Most user-friendly CAM system for STAR machines
✅ Support for all STAR kinematics
✅ Certified postprocessors for STAR machines, ready to use
This collaboration enables customers to unlock the full potential of their STAR machines with the proven programming power of SolidCAM.
Our cooperation extends beyond Germany — SolidCAM has similar strong partnerships with STAR branches in the US, UK, and many other countries worldwide, as well as close collaboration with STAR HQ in Japan 🌍.




2
90

8 May 2025
import yt_dlp
import os
import sys
import subprocess
def check_ffmpeg():
"""检查是否安装了ffmpeg"""
try:
# 尝试运行ffmpeg命令
with open(os.devnull, 'w') as devnull:
subprocess.check_call(['ffmpeg', '-h'], stdout=devnull, stderr=devnull)
return True
except (subprocess.SubprocessError, FileNotFoundError):
return False
def download_video(url, max_retries=3):
"""
下载 YouTube 视频,并转换为支持Twitter的MP4格式
参数:
url (str): 要下载的 YouTube 视频 URL
max_retries (int): 下载失败时的最大重试次数
"""
# 检查ffmpeg
if not check_ffmpeg():
print("警告: 未找到ffmpeg。无法转换为Twitter支持的格式。")
print("必须安装ffmpeg: github.com/yt-dlp/yt-dlp#dep…")
print("程序将终止...")
return False
# 设置下载选项 - Twitter兼容格式
ydl_opts = {
# 保存在默认目录,使用视频标题作为文件名
'outtmpl': '%(title)s.%(ext)s',
# 显示进度条
'progress_hooks': [progress_hook],
# 选择Twitter兼容的格式
'format': 'bestvideo[ext=mp4][vcodec^=avc][height<=1080][filesize<300M] bestaudio[ext=m4a]/best[ext=mp4][vcodec^=avc][height<=1080][filesize<300M]',
# 如果没有完全匹配的格式,则转换为适合的格式
'postprocessors': [{
'key': 'FFmpegVideoConvertor',
'preferedformat': 'mp4',
}, {
# 确保使用H.264编码和AAC音频
'key': 'FFmpegVideoRemuxer',
'preferedformat': 'mp4',
}],
# 视频编码设置
'postprocessor_args': [
'-vcodec', 'libx264', '-acodec', 'aac',
'-pix_fmt', 'yuv420p', '-movflags', ' faststart',
# 确保视频比特率不超过5Mbps
'-b:v', '5M', '-maxrate', '5M', '-bufsize', '10M',
# 音频比特率
'-b:a', '128k'
],
# 启用HTTP源重试
'retries': 10,
# 启用片段重试
'fragment_retries': 10,
# 设置超时
'socket_timeout': 30,
# 在出错时继续
'ignoreerrors': False,
# 使用更多的格式提取器
'extractor_retries': 5,
# 使用外部下载器进行更稳定的下载
'external_downloader': 'aria2c' if is_aria2c_installed() else None,
# 设置缓冲区大小
'buffersize': 1024 * 1024, # 1MB
}
# 尝试下载,如果失败就重试
retries = 0
while retries <= max_retries:
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(url, download=False)
print(f"\n准备下载: {info.get('title', '未知标题')}")
# 开始下载
ydl.download([url])
print("\n视频下载完成并保存为Twitter兼容的MP4格式!")
print("该视频应符合Twitter上传要求(H.264编码,AAC音频,MP4容器)")
return True
except Exception as e:
retries = 1
if retries <= max_retries:
print(f"\n下载出错: {e}")
print(f"正在尝试重新下载 (尝试 {retries}/{max_retries})...")
else:
print(f"\n下载失败: {e}")
print("已达到最大重试次数,下载失败。")
return False
def is_aria2c_installed():
"""检查是否安装了aria2c"""
try:
with open(os.devnull, 'w') as devnull:
subprocess.check_call(['aria2c', '--version'], stdout=devnull, stderr=devnull)
return True
except (subprocess.SubprocessError, FileNotFoundError):
return False
def progress_hook(d):
"""显示下载进度"""
if d['status'] == 'downloading':
percent = d.get('_percent_str', 'N/A')
speed = d.get('_speed_str', 'N/A')
eta = d.get('_eta_str', 'N/A')
downloaded = d.get('downloaded_bytes', 0)
total = d.get('total_bytes', 0) or d.get('total_bytes_estimate', 0)
if total > 0:
downloaded_mb = downloaded / (1024 * 1024)
total_mb = total / (1024 * 1024)
print(f'\r下载进度: {percent} ({downloaded_mb:.1f}MB/{total_mb:.1f}MB) 速度: {speed} 预计剩余时间: {eta}', end='')
else:
print(f'\r下载进度: {percent} 速度: {speed} 预计剩余时间: {eta}', end='')
elif d['status'] == 'finished':
print('\n下载完成,正在处理并转换为Twitter兼容格式...')
elif d['status'] == 'error':
print(f"\n下载出错: {d.get('error')}")
def main():
print("YouTube 视频下载器 - Twitter兼容版")
print("=" * 50)
print("此工具将下载视频并转换为Twitter支持的MP4格式")
print("要求:H.264编码,AAC音频,分辨率不超过1080p")
print("=" * 50)
# 检查ffmpeg
if not check_ffmpeg():
print("错误:必须安装ffmpeg才能使用此工具")
print("下载并安装ffmpeg: github.com/yt-dlp/yt-dlp#dep…")
return
# 提示用户输入视频地址
url = input("请输入 YouTube 视频地址: ")
if not url:
print("错误:未输入视频地址!")
return
print(f"\n开始处理: {url}")
# 下载视频
download_video(url)
if __name__ == '__main__':
main()
1
3
91

16 Jan 2025
kind of feels like Fusion learned something from moddable games, i like that they host a ton of free plugins and postprocessors and stuff
1
23

2 Jan 2025
Excalibur v0.30.3 released! We've improved the realistic collision solver in TileMaps. Added a new event hook onDraw() to postprocessors, and fixed some crashes on Xiaomi phones!
Bringing game dev to web dev! Get started today
excaliburjs.com/docs/quick-s…
#typescript #gamedev
1
2
6
278

27 Nov 2024
writing postprocessors and automations for a 2D CAD/CAM Software
1
1
202

27 Nov 2024
That "sort of" happened with parallel importing for meshes and textures, but the difficult part is not making it work in principle but making it work in practice: people write asset postprocessors that can in principle do anything, and that makes the entire thing much harder.
1
3
376

26 Nov 2024
Want to download all your @X posts in a single file? Here's how 👇
I wanted to create a Claude writing style based on my X posts. To do so, I needed all my posts in a single file.
I searched for extensions, tools, .. And found this funny one: github.com/mikf/gallery-dl/
It's not meant to be used this way, it's dirty, but it works.
Install dependencies
brew install gallery-dl
mkdir -p ~/.config/gallery-dl
Create a configuration file at ~/.config/gallery-dl/config.json with:
{
"extractor": {
"twitter": {
"text-tweets": true,
"download": false
}
},
"postprocessors": [{
"name": "metadata",
"event": "post",
"mode": "custom",
"filename": "tweets.txt",
"open": "a",
"content-format": "{date} - {content}\n"
}]
}
Login to x.com on Firefox so gallery-dl can read cookies from it (doesn't work with Chrome, I told ya it's dirty).
Run gallery-dl --cookies-from-browser firefox "twitter.com/elon"
Done.
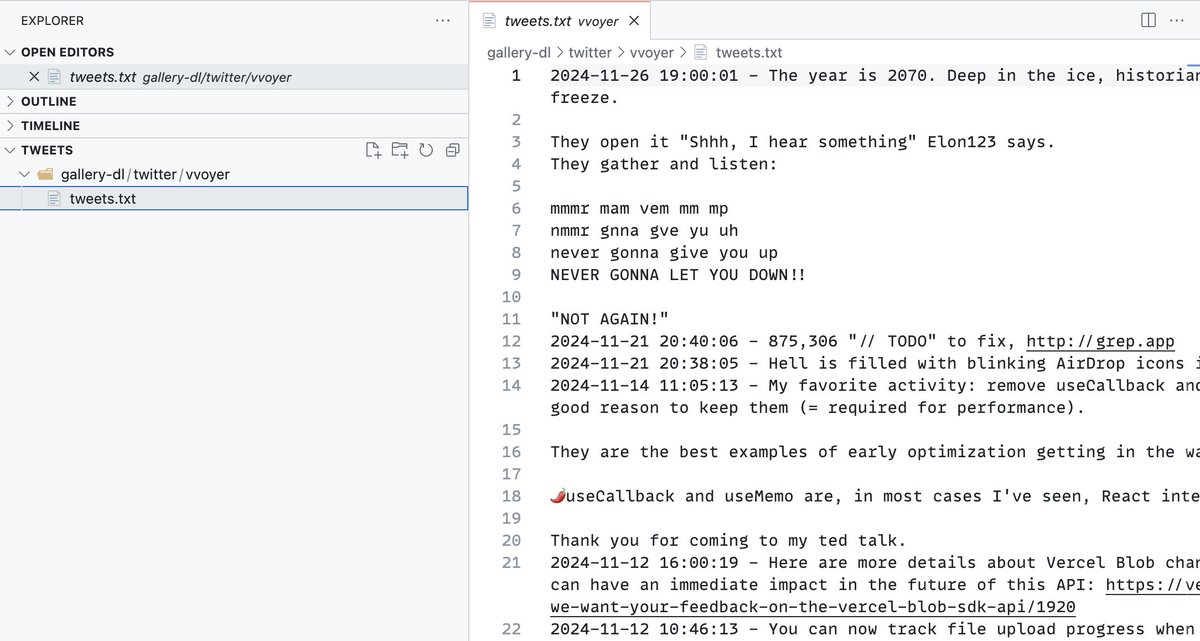
ALT Example of a tweets.txt file with my tweets in it
26 Nov 2024

Want Claude to more closely match how you communicate?
Upload writing samples and Claude can automatically generate custom styles, just for you.
3
6
1,326

18 Oct 2024
*POST PROCESSORS* RoboDK allows you to customize #PostProcessors for your specific robotic setups.
More info: robodk.com/doc/en/Post-Proce…
#RoboDK #Robotics #Robot #Manufacturing #Mfg #SimulationSoftware #Automation #RobotSoftware #OfflineProgramming
1
61

23 Sep 2024
Llama Researcher @clusteredbytes
一个创新性的项目, 展示了如何利用现代 AI 和搜索技术, 对给定主题进行在线研究, 自动化和增强研究过程。项目受到 GPT-Researcher 的启发 @assaf_elovic 👏👏👏
核心技术栈:
- LlamaIndex @llama_index workflows 用于流程编排
- Tavily @tavilyai API 作为搜索引擎 API
- 其他 LlamaIndex 抽象, 如 VectorStoreIndex、PostProcessors 等
开源项目地址:
github.com/rsrohan99/llama-r…
23 Sep 2024

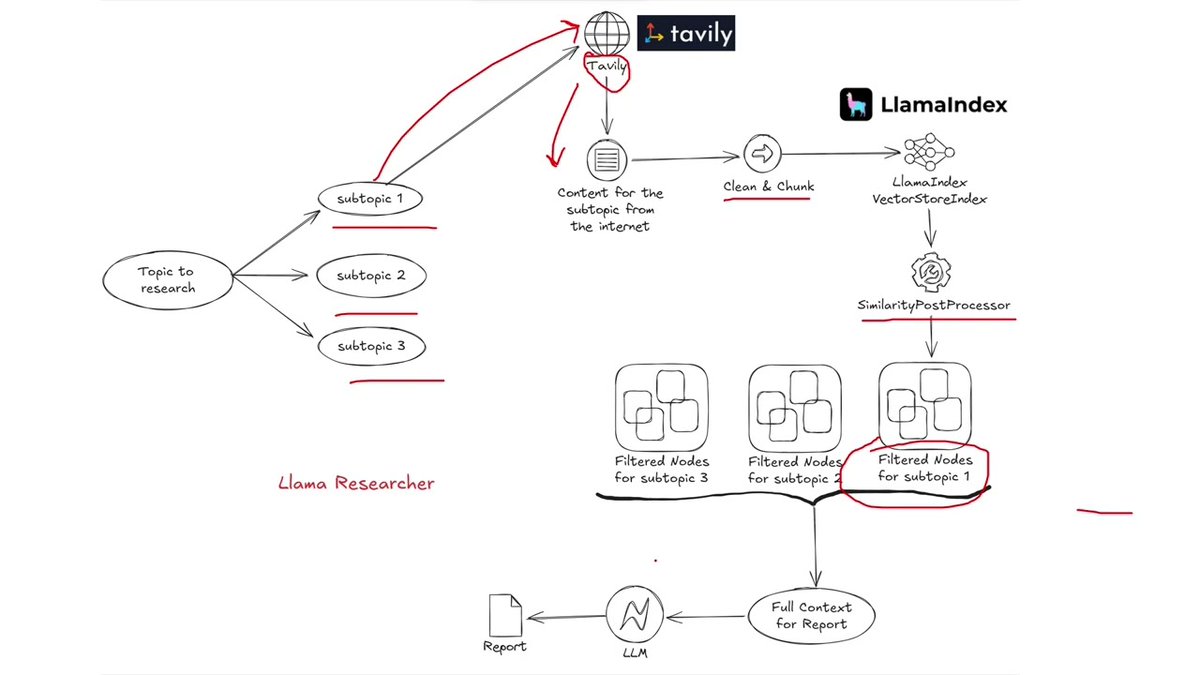
Build a multi-agent system that can generate research reports from web search 🔥
@llama_index makes it easy to structure this as an event-driven system:
1. Break research topic into a plan with multiple steps
2. For each topic, research tasks via @tavilyai
3. Do postprocessing and filtering to fetch just the most relevant context.
4. Generate the final document.
Big shoutout to @clusteredbytes and ofc GPT-researcher (@assaf_elovic) for the inspiration
Repo: github.com/rsrohan99/llama-r…
14
1,150

18 Apr 2024
💡 Reranking retrieval results before sending them to the LLM significantly improves RAG performance.
Simply put, with Re-Ranking - given a query and a list of documents, Rerank indexes the documents from most to least semantically relevant to the query.
----
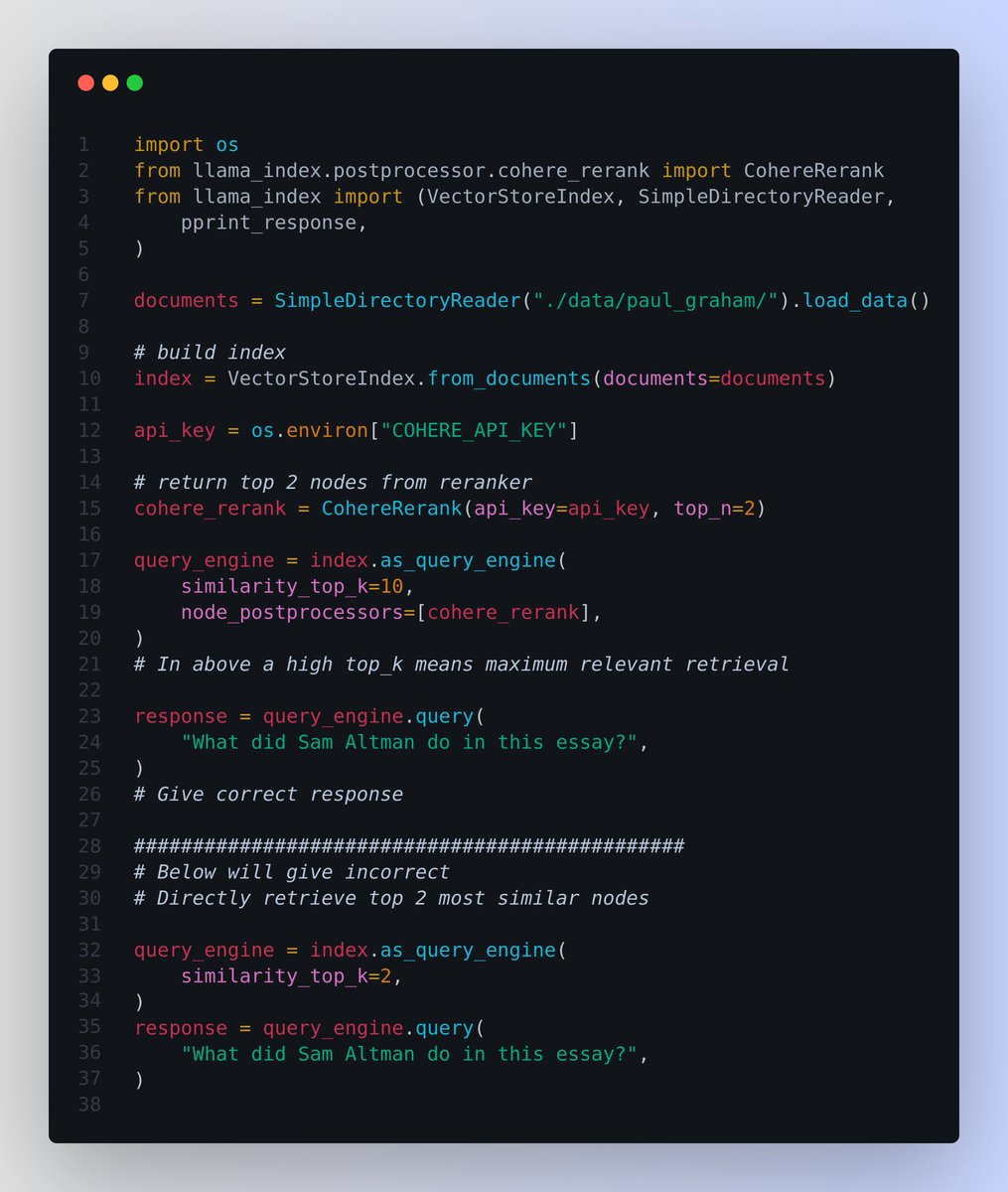
✨ In the attached code with LlamaIndex, note the difference between:
👉 Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
👉 Accurate retrieval by retrieving the top 10 nodes and using CohereRerank (from @cohere ) to rerank and return the top 2 nodes.
------
📌 In the attached code the `similarity_top_k` param determines how many top-ranked chunks in the retrieval phase are considered for further processing in the generation phase. A higher similarity_top_k increases the diversity of retrieved candidates, potentially providing the model with richer information for generating responses. However, it also increases computational load.
👉 `similarity_top_k` is one of the parameters thats used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters can impact the trade-off between computational efficiency and the quality of retrieved information.
----
👉 We pass the rerank to the `node_postprocessors` which are a set of modules in LlamaIndex that take a set of nodes, and apply some kind of transformation or filtering before returning them.
In LlamaIndex, node postprocessors are most commonly applied within a query engine (like in this case), after the node retrieval step and before the response synthesis step.
---------
✨ Why is Re-Ranking Required ?
📌 The recall performance for LLMs decreases as we add more context resulting in increased context window(context stuffing)
📌 Basic Idea behind reranking is to filter down the total number of documents into a fixed number .
📌 The re-ranker will re-rank the records and get the most relevant items at the top and they can be sent to the LLM
📌 The Reranking offers a solution by finding those records that may not be within the top 3 results and put them into a smaller set of results that can be further fed into the LLM
2
10
38
2,233


4 Apr 2024
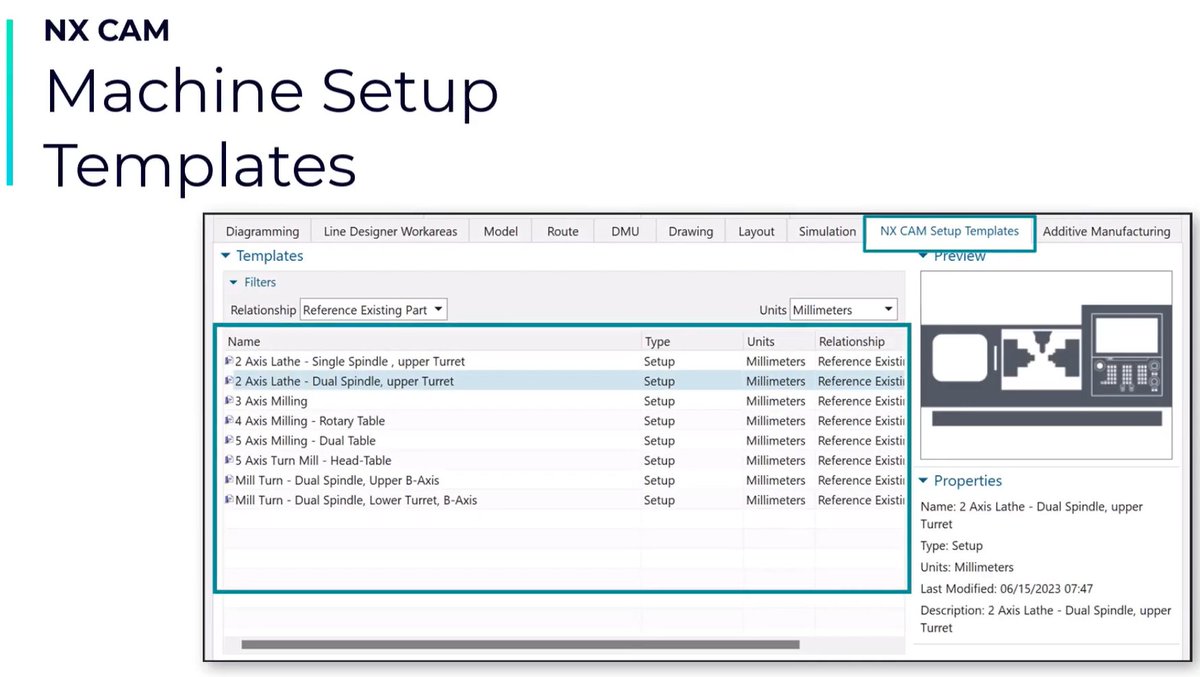
Check out NXCAM’s latest tech tip featuring NX CAM Machine Setup Templates. With PostHub,you can now easily download machine setups, machine graphics, kinematics, and postprocessors with detailed videos and documentation in just a few clicks.
sie.ag/2LsSpo
2
18
8 Mar 2024
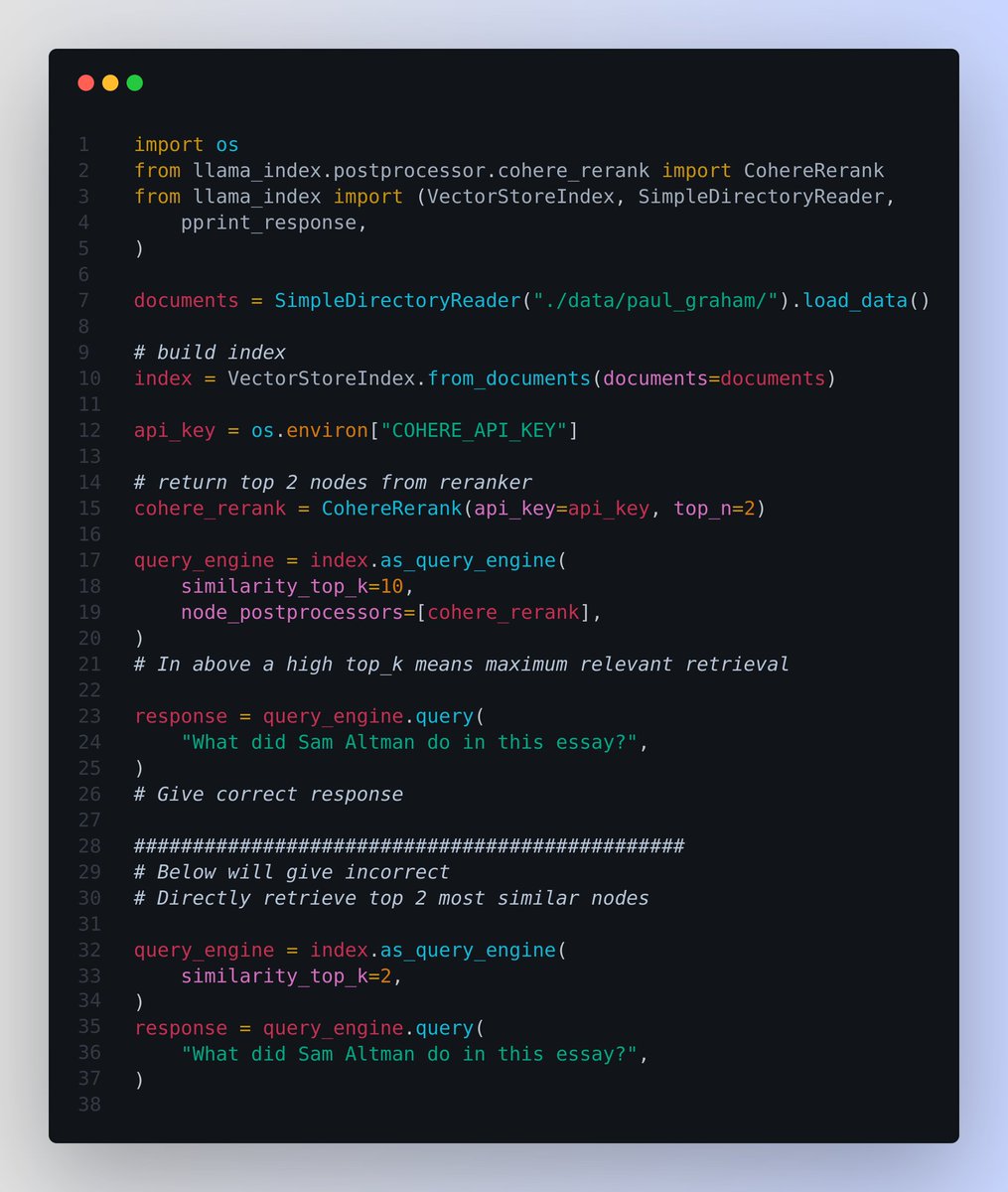
💡 Reranking retrieval results before sending them to the LLM significantly improves RAG performance.
Simply put, with Re-Ranking - given a query and a list of documents, Rerank indexes the documents from most to least semantically relevant to the query.
----
✨ In the attached code with LlamaIndex, note the difference between:
👉 Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
👉 Accurate retrieval by retrieving the top 10 nodes and using CohereRerank to rerank and return the top 2 nodes.
------
📌 In the attached code the `similarity_top_k` param determines how many top-ranked chunks in the retrieval phase are considered for further processing in the generation phase. A higher similarity_top_k increases the diversity of retrieved candidates, potentially providing the model with richer information for generating responses. However, it also increases computational load.
👉 `similarity_top_k` is one of the parameters thats used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters can impact the trade-off between computational efficiency and the quality of retrieved information.
----
👉 We pass the rerank to the `node_postprocessors` which are a set of modules in LlamaIndex that take a set of nodes, and apply some kind of transformation or filtering before returning them.
In LlamaIndex, node postprocessors are most commonly applied within a query engine (like in this case), after the node retrieval step and before the response synthesis step.
---------
✨ Why is Re-Ranking Required ?
📌 The recall performance for LLMs decreases as we add more context resulting in increased context window(context stuffing)
📌 Basic Idea behind reranking is to filter down the total number of documents into a fixed number .
📌 The re-ranker will re-rank the records and get the most relevant items at the top and they can be sent to the LLM
📌 The Reranking offers a solution by finding those records that may not be within the top 3 results and put them into a smaller set of results that can be further fed into the LLM
1
19
74
4,856
20 Feb 2024
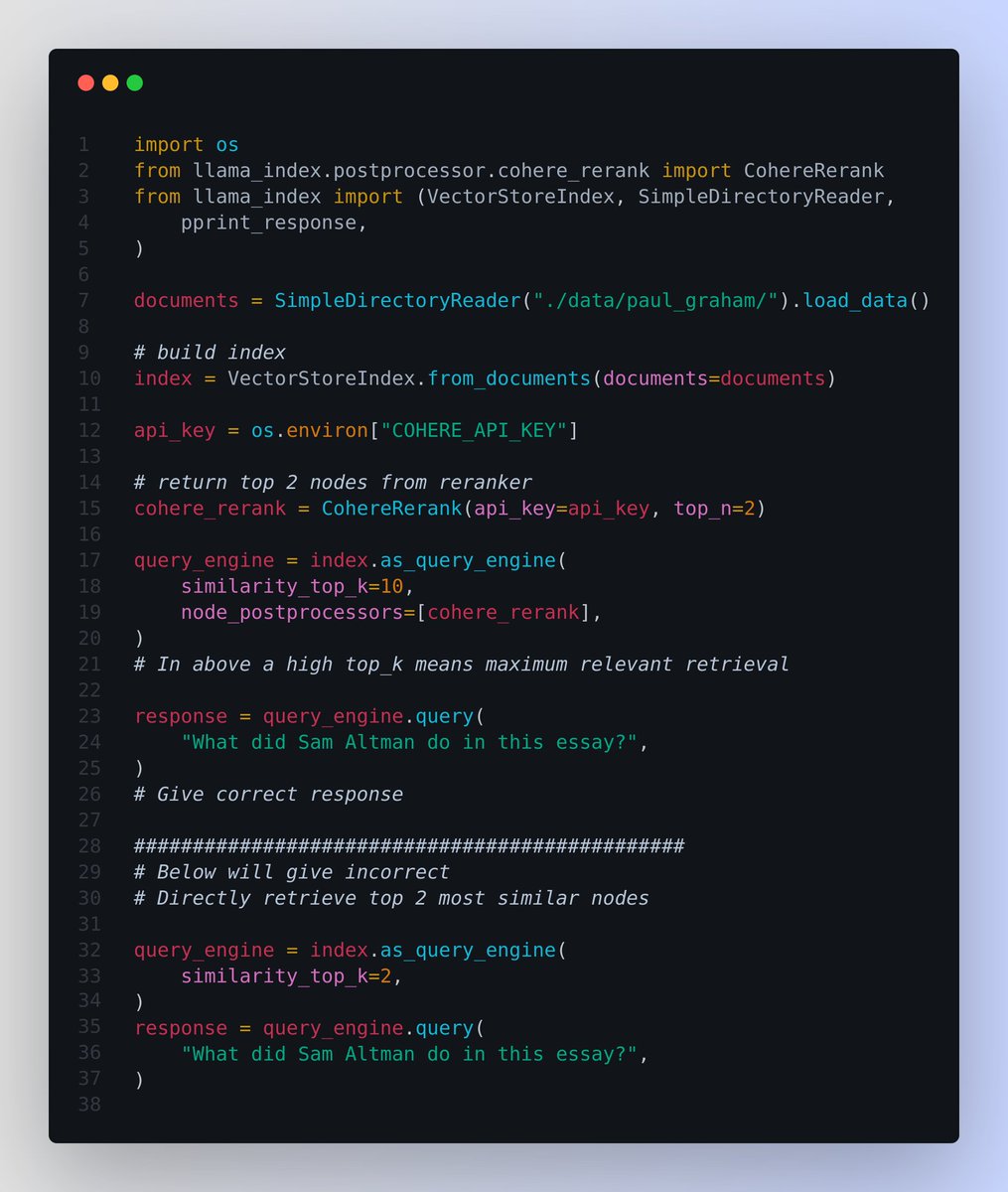
💡 Reranking retrieval results before sending them to the LLM significantly improves RAG performance.
Simply put, with Re-Ranking - given a query and a list of documents, Rerank indexes the documents from most to least semantically relevant to the query.
----
✨ In the attached code with LlamaIndex, note the difference between:
👉 Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
👉 Accurate retrieval by retrieving the top 10 nodes and using CohereRerank to rerank and return the top 2 nodes.
------
📌 In the attached code the `similarity_top_k` param determines how many top-ranked chunks in the retrieval phase are considered for further processing in the generation phase. A higher similarity_top_k increases the diversity of retrieved candidates, potentially providing the model with richer information for generating responses. However, it also increases computational load.
👉 `similarity_top_k` is one of the parameters thats used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters can impact the trade-off between computational efficiency and the quality of retrieved information.
----
👉 We pass the rerank to the `node_postprocessors` which are a set of modules in LlamaIndex that take a set of nodes, and apply some kind of transformation or filtering before returning them.
In LlamaIndex, node postprocessors are most commonly applied within a query engine (like in this case), after the node retrieval step and before the response synthesis step.
---------
✨ Why is Re-Ranking Required ?
📌 The recall performance for LLMs decreases as we add more context resulting in increased context window(context stuffing)
📌 Basic Idea behind reranking is to filter down the total number of documents into a fixed number .
📌 The re-ranker will re-rank the records and get the most relevant items at the top and they can be sent to the LLM
📌 The Reranking offers a solution by finding those records that may not be within the top 3 results and put them into a smaller set of results that can be further fed into the LLM
4
16
935