𝐒𝐨 𝐦𝐚𝐧𝐲 𝐢𝐧𝐭𝐞𝐫𝐞𝐬𝐭𝐢𝐧𝐠 𝐮𝐩𝐝𝐚𝐭𝐞𝐬 𝐟𝐨𝐫 𝐏𝐨𝐰𝐞𝐫 𝐐𝐮𝐞𝐫𝐲
I sat down with Miguel Angel Escobar — Principal Program Manager on the Data Integration team at Microsoft — and we went deep.
Not surface level. Deep.
Here's what we unpacked in this episode of Fabric Insider:
🔹 Power Query explained for someone who has never touched it
🔹 Web vs Desktop vs Excel — and what the unification plan actually looks like
🔹 What Power Query Online can do that the desktop version simply can't
🔹 The performance enhancements you should know about — and what's happening under the hood
🔹 The big question: Dataflow vs SQL vs Python — which one should you actually use for data transformation?
🔹 Dataflow CU consumption — yes, it's been a pain point. Has it been fixed? Miguel answers directly.
🔹 My Queries — a feature most people haven't explored yet
🔹 What's coming on the roadmap
This is the kind of conversation you don't get from documentation.
Straight from the people building it.
🎥 Watch the full episode → youtu.be/mgxEYGKgYis
🔗 Connect with Miguel Escobar → linkedin.com/in/escobarmigue…
💡 Share your ideas for Microsoft Fabric → ideas.fabric.microsoft.com
💬 Join the Fabric community on Reddit → reddit.com/r/MicrosoftFabric…
📺 Fabric Insider full playlist → youtube.com/watch?v=PDEYc37V…
#PowerQuery #PowerBI #MicrosoftFabric #Dataflows #DataEngineering #ETL #DataTransformation #DataIntegration #FabricInsider #PowerBICommunity #FabricCommunity #DataPlatform #DataAnalytics #BusinessIntelligence #PowerBITips #MQuery #PowerQueryOnline #Microsoft #DataProfessionals #LearningDataEngineering

3
7
478

19 Apr 2025
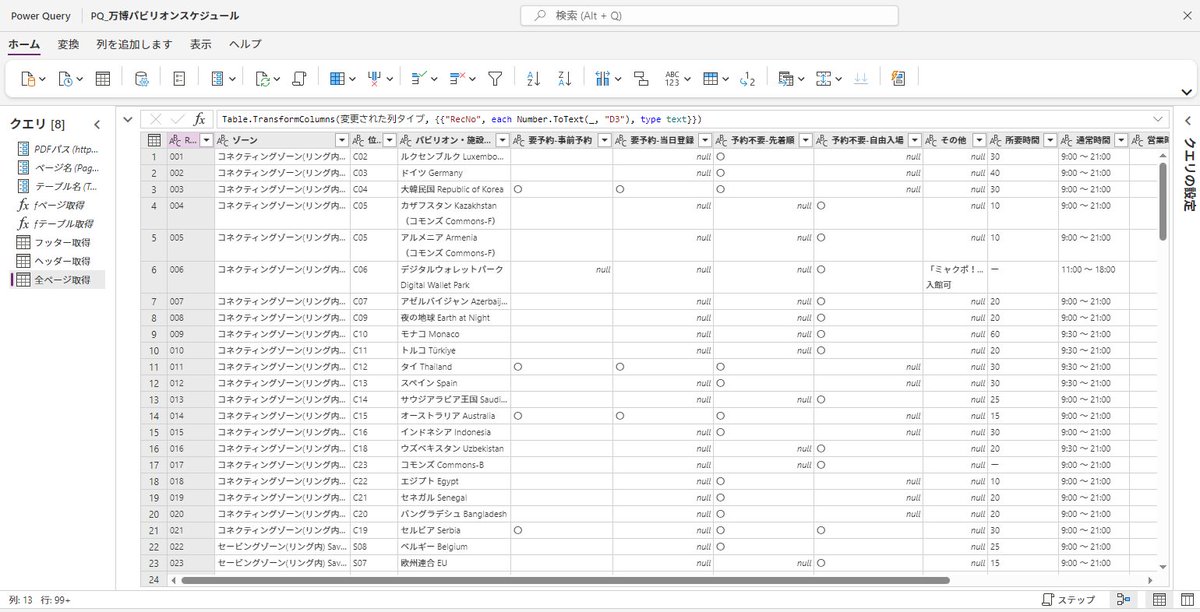
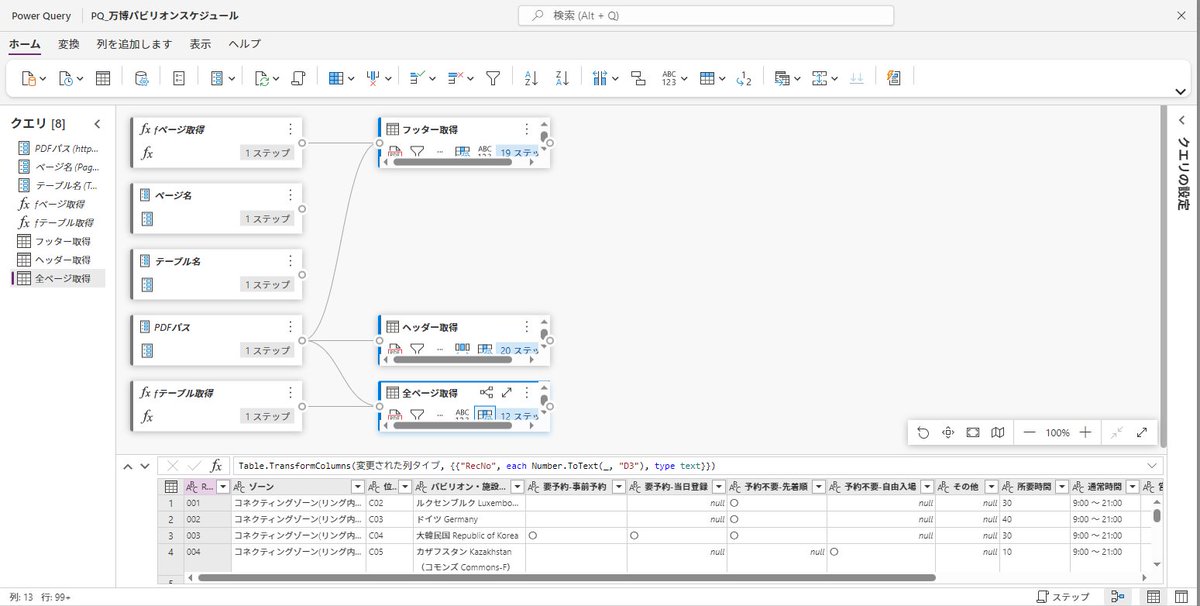
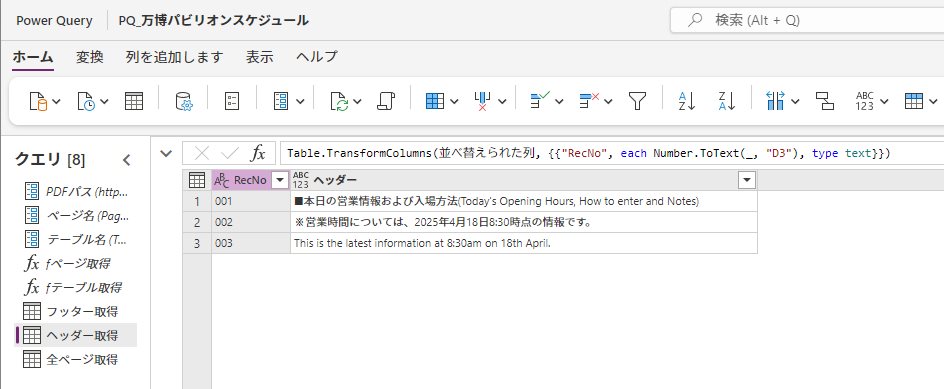
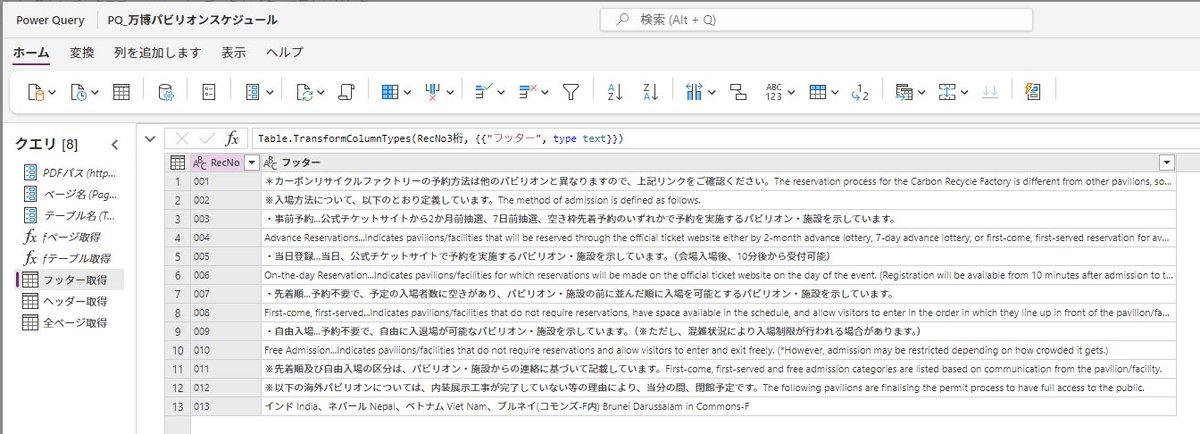
大阪万博のパビリオンの情報が「PDFで提供」されていると聞いて、PowerQueryで読み取ってみた。
PowerQueryOnlineに実装できたので、PowerAutomateによりOneDrive上のPDFからデータフローを通じてDataverseに入れてしまえば、あとは煮るなり焼くなり。
しかし問題は、元のPDFが「データ」としてあまりよろしくなくて、対応のためのM言語が複雑になりすぎていること。PDFは毎日更新されるので、この処理がどこまで対応しきれるか。
また、PDFのファイル名(すなわちダウンロードURL)も毎日変化するので、ダウンロードする処理も一苦労。
今はその部分をPythonで書いていて、もしここをPowerAutomateでやれれば全部をクラウド上で自動化できるけど、PowerAutomateにPDFの内部の情報(本文の文字列)を覗く機能が提供されているのかな?
このPDFのダウンロードリンクのあるページには別のPDFへのリンクもあって、これと特定できる情報はサイト(のソース)にはなく、結局「中」を覗くしかない。
なお、自分には万博に行く予定がない
1
2
8
4,969
20 Mar 2025
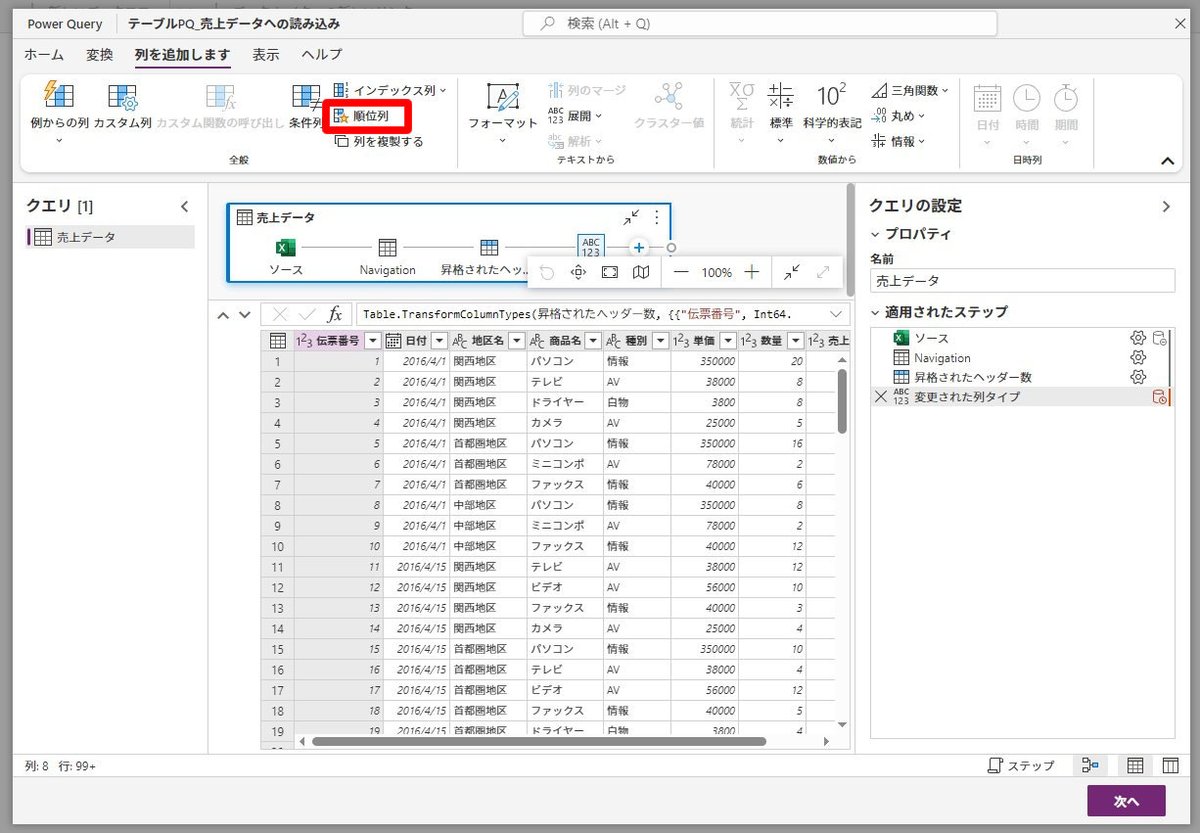
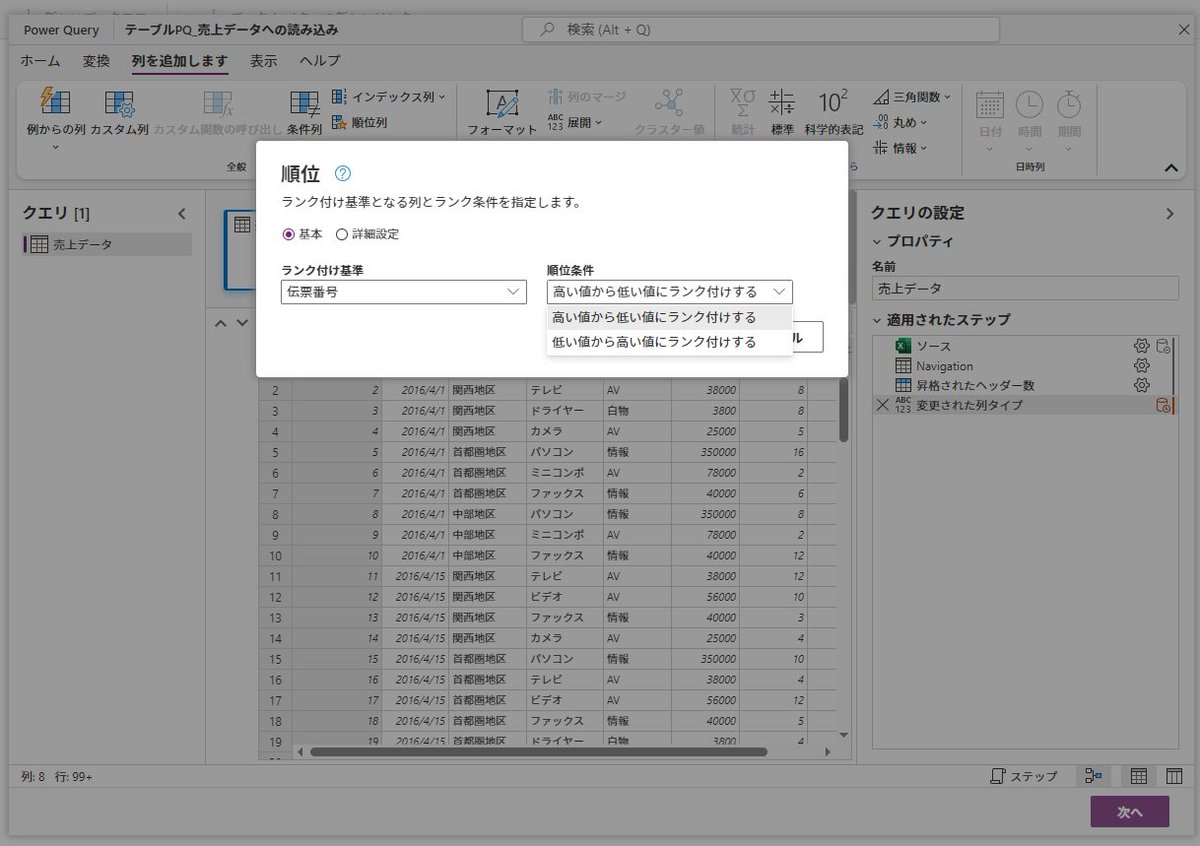
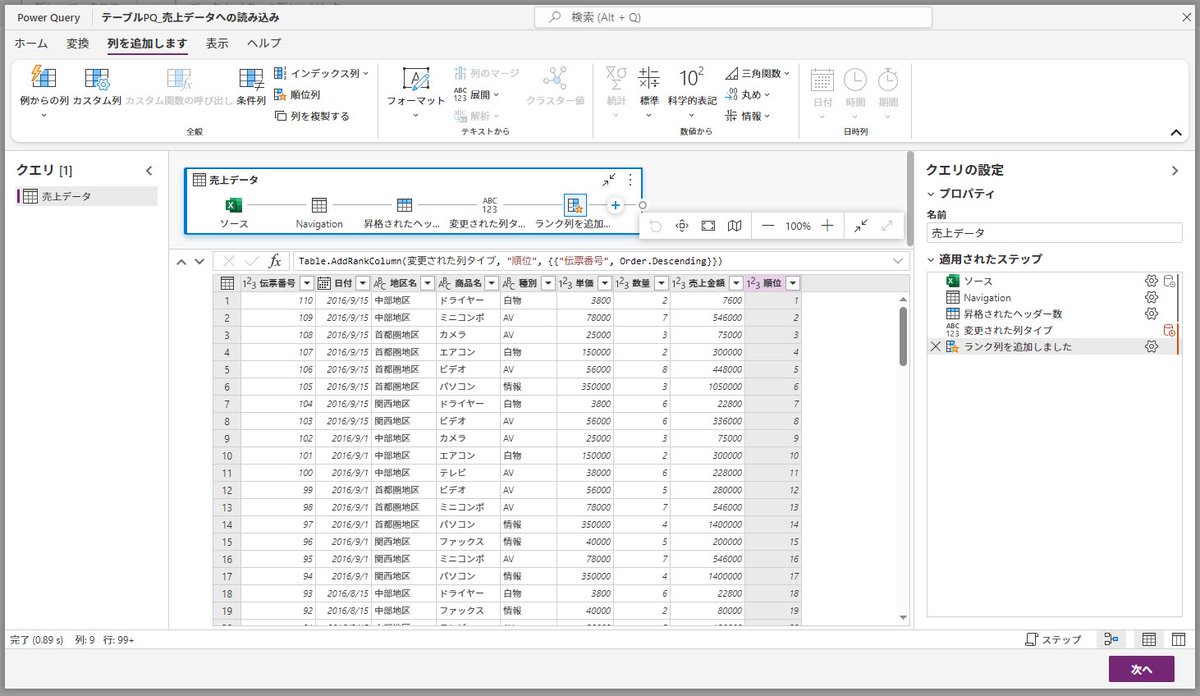
PowerQueryOnlineのツールバーにあってExcelのPowerQueryのツールバーにない「順位列」のメニュー。
Window関数のような処理ができる。
これがなくても、カスタム列で「AddRankColumn」と直接M言語を書けばいいのだけど、これがツールバーのメニューにあることで少なくとも
「並べ替えをしてインデックス列を付ける」
のような処理が行われることは減るのでは、と思ってみたり。

2
531
16 Mar 2025
このPowerQueryOnlineは、処理結果をDataverseに出力して分析に供する、という意味で、(ETLなどの)前処理として利用するものだろうし、そこで活かせる技術として「データサイエンス100本ノック」で取り上げられているテクニックを追求することには意味がある、などと思ってはいたけれど、自分自身がそういう形態で実践できる環境を失った以上は、とりあえずこの話は凍結。
16 Mar 2025

開発者プログラムで作成したonmicrosoftのアカウントではすでにPowerAppsは使えなくなっていたけれど、そのままこのアカウントで「試用」を始めたら、作ってあったものが読み込めた。ただアカウント自体がまもなく終了する。
1
3
293

15 Oct 2024
Did you know that there are two ways to do many of the #data #transformations in #PowerQuery in #PowerBI or #Microsoft #Fabric?
One is using Add Column, and the other one is using Transform.
both options are available in #PowerBIDesktop and #Dataflow #PowerQueryOnline
Learn their difference using a real-world demo in my latest video here:
youtu.be/vwA4Ed92Ne8

2
21
1,066



14 Mar 2023
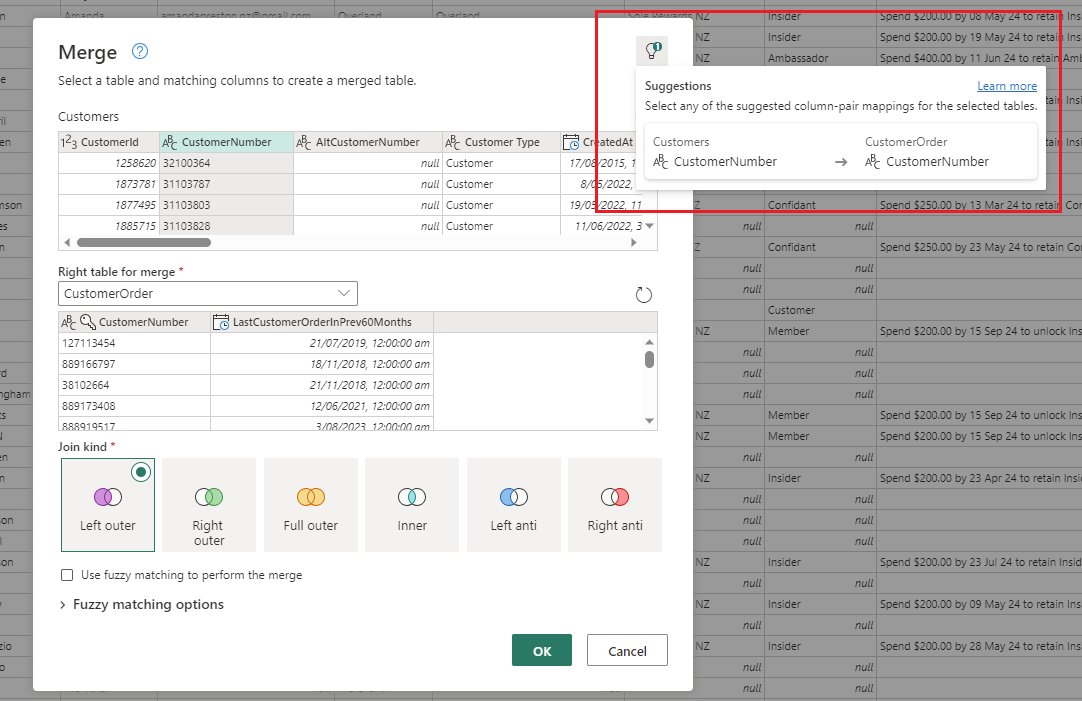
もとのテーブルが一旦PowerQueryOnlineに読み込まれててそれを読みに行ってるから
作業するときは上位側で必要な行のみにフィルターかけておいて、作業が終わったらフィルターを外してデータを更新し直す
というテクニックを身に着けた
2
163

4 Apr 2022
#Dataflows #PowerBI #PowerQueryOnline
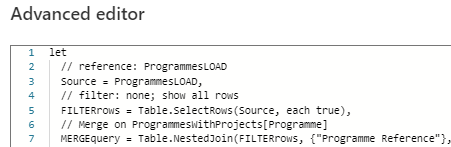
Sometimes the M-code is formatted (i.e. colour format is maintained).
Most of the time, it isn't formatted, for unknown reasons. Feels like a game of chance with a 90% lose rate 🥺
Refresh doesn't resolve the issue. Bug or feature?
1
1
5


19 Nov 2020
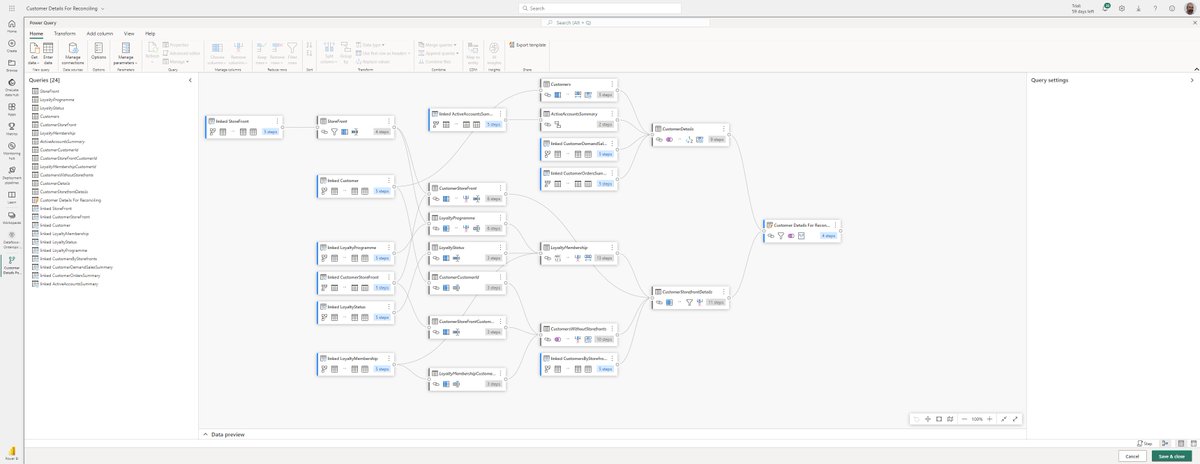
I really like this diagram view for #PowerQueryOnline. Can’t wait for @Microsoft to bring this to Power Query desktop.
mckcons.co/n67

2

12 Dec 2019
Use #PowerBI and take the #powerqueryonline courses.. they are frickin amazing!!! @EscobarMiguel90 @kpuls
powerquery.training
2

If you are going to the Power Platform World Tour in London, England check out Laura Graham-Brown's (@Laura_GB) session "Power Query and Flow".
#PowerQueryOnline #MicrosoftFlow #OData #SQL.
@pbiusergroup #PowerplatformWT @MSPowerBI

1
1
6